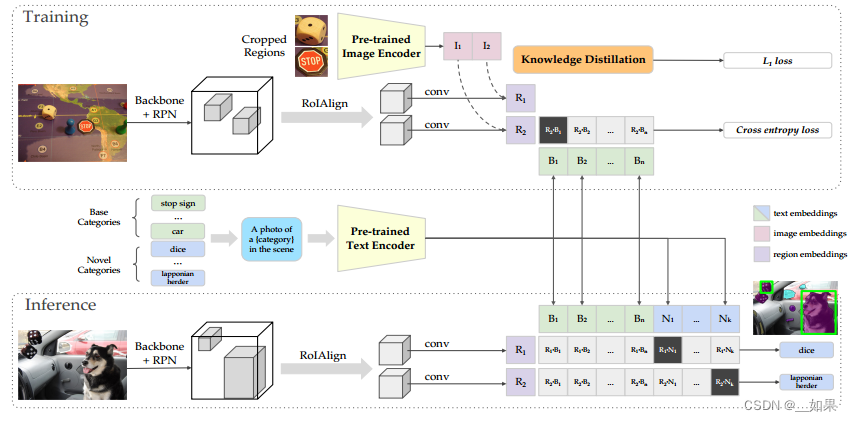
现在的目标检测数据集,标注的类别都很有限,如图中的base categories,只能检测出toy而不能检测出细分类别,能不能在现有数据集的基础上,不额外打标注,就能直接检测细分物体?
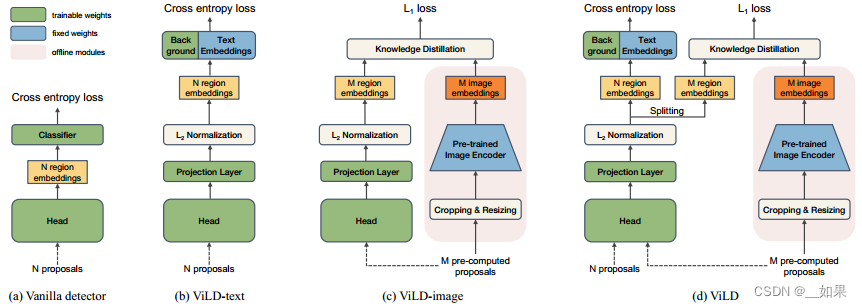
(a)有监督的baseline方法:mask RCNN,第一阶段出一些region proposal,第二阶段根据N个proposal,经过一个detection head得到embeddings,最好通过分类头得到这些bonding box是什么类
(b)ViLD的text部分:利用CLIP处理文本的方法(冻结)得到文本特征,其中文本的标签是基础类也就是base categories,最后图像特征和文本特征点乘算相似度当作logits,back ground是背景类,有专门的网络进行embedding
(c)ViLD的image部分:CLIP已经够好了,所以希望这边图像编码器输出的region embedding能尽可能的跟CLIP输出的图像embedding一致就好了。利用知识蒸馏,把图像编码器得到的bonding box做一些resize操作,扔给CLIP预训练好的image encoder(冻结),得到图像特征,当作teacher网络,student则是mask RCNN。值得注意的是为了节省开销,ViLD-image中的proposal是预训练好的,可以放在内存中训练时直接用,而text中的proposal是实时出来的