目录
编辑
一,创建RDD
二,常用Action操作
三,常用Transformation操作
一,创建RDD
创建RDD主要有两种方式,一个是textFile加载本地或者集群文件系统中的数据,
第二个是用parallelize方法将Driver中的数据结构并行化成RDD。
#从本地文件系统中加载数据
file = "./data/hello.txt"
rdd = sc.textFile(file,3)
rdd.collect()
['hello world',
'hello spark',
'spark love jupyter',
'spark love pandas',
'spark love sql']
#从集群文件系统中加载数据
#file = "hdfs://localhost:9000/user/hadoop/data.txt"
#也可以省去hdfs://localhost:9000
#rdd = sc.textFile(file,3)
#parallelize将Driver中的数据结构生成RDD,第二个参数指定分区数
rdd = sc.parallelize(range(1,11),2)
rdd.collect()
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]二,常用Action操作
Action操作将触发基于RDD依赖关系的计算。
collect
rdd = sc.parallelize(range(10),5)
#collect操作将数据汇集到Driver,数据过大时有超内存风险
all_data = rdd.collect()
all_data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]take
#take操作将前若干个数据汇集到Driver,相比collect安全
rdd = sc.parallelize(range(10),5)
part_data = rdd.take(4)
part_data
[0, 1, 2, 3]takeSample
#takeSample可以随机取若干个到Driver,第一个参数设置是否放回抽样
rdd = sc.parallelize(range(10),5)
sample_data = rdd.takeSample(False,10,0)
sample_data
[7, 8, 1, 5, 3, 4, 2, 0, 9, 6]first
#first取第一个数据
rdd = sc.parallelize(range(10),5)
first_data = rdd.first()
print(first_data)
0count
#count查看RDD元素数量
rdd = sc.parallelize(range(10),5)
data_count = rdd.count()
print(data_count)
10reduce
#reduce利用二元函数对数据进行规约
rdd = sc.parallelize(range(10),5)
rdd.reduce(lambda x,y:x+y)
45foreach
#foreach对每一个元素执行某种操作,不生成新的RDD
#累加器用法详见共享变量
rdd = sc.parallelize(range(10),5)
accum = sc.accumulator(0)
rdd.foreach(lambda x:accum.add(x))
print(accum.value)
45countByKey
#countByKey对Pair RDD按key统计数量
pairRdd = sc.parallelize([(1,1),(1,4),(3,9),(2,16)])
pairRdd.countByKey()
defaultdict(int, {1: 2, 3: 1, 2: 1})saveAsTextFile
#saveAsTextFile保存rdd成text文件到本地
text_file = "./data/rdd.txt"
rdd = sc.parallelize(range(5))
rdd.saveAsTextFile(text_file)
#重新读入会被解析文本
rdd_loaded = sc.textFile(text_file)
rdd_loaded.collect()
['2', '3', '4', '1', '0']三,常用Transformation操作
Transformation转换操作具有懒惰执行的特性,它只指定新的RDD和其父RDD的依赖关系,只有当Action操作触发到该依赖的时候,它才被计算。
map
#map操作对每个元素进行一个映射转换
rdd = sc.parallelize(range(10),3)
rdd.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
rdd.map(lambda x:x**2).collect()
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]filter
#filter应用过滤条件过滤掉一些数据
rdd = sc.parallelize(range(10),3)
rdd.filter(lambda x:x>5).collect()
[6, 7, 8, 9]flatMap
#flatMap操作执行将每个元素生成一个Array后压平
rdd = sc.parallelize(["hello world","hello China"])
rdd.map(lambda x:x.split(" ")).collect()
[['hello', 'world'], ['hello', 'China']]
rdd.flatMap(lambda x:x.split(" ")).collect()
['hello', 'world', 'hello', 'China']sample
#sample对原rdd在每个分区按照比例进行抽样,第一个参数设置是否可以重复抽样
rdd = sc.parallelize(range(10),1)
rdd.sample(False,0.5,0).collect()
[1, 4, 9]distinct
#distinct去重
rdd = sc.parallelize([1,1,2,2,3,3,4,5])
rdd.distinct().collect()
[4, 1, 5, 2, 3]subtract
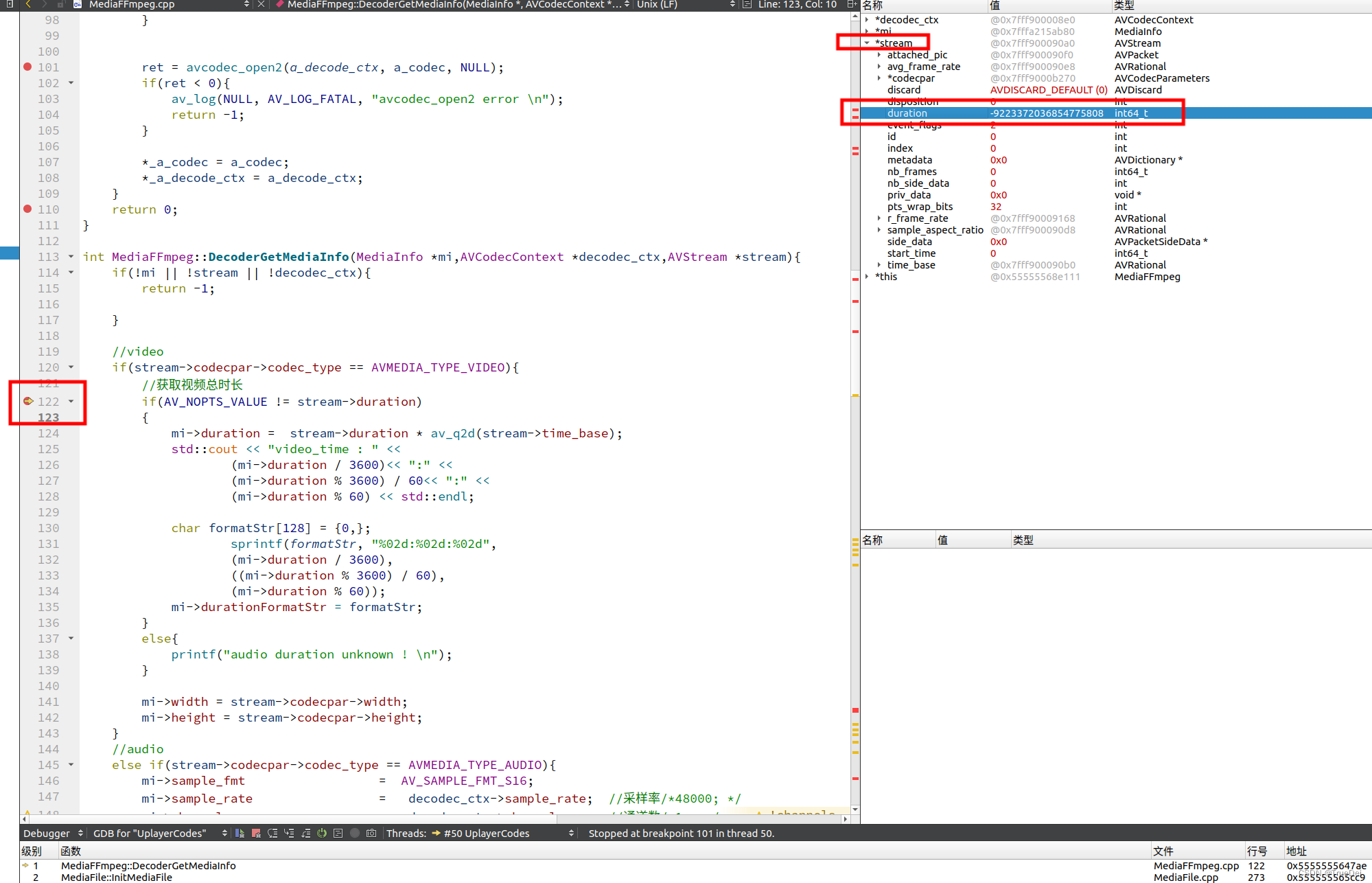
#subtract找到属于前一个rdd而不属于后一个rdd的元素
a = sc.parallelize(range(10))
b = sc.parallelize(range(5,15))
a.subtract(b).collect()
[0, 1, 2, 3, 4]union
#union合并数据
a = sc.parallelize(range(5))
b = sc.parallelize(range(3,8))
a.union(b).collect()
[0, 1, 2, 3, 4, 3, 4, 5, 6, 7]intersection
#intersection求交集
a = sc.parallelize(range(1,6))
b = sc.parallelize(range(3,9))
a.intersection(b).collect()
[3, 4, 5]cartesian
#cartesian笛卡尔积
boys = sc.parallelize(["LiLei","Tom"])
girls = sc.parallelize(["HanMeiMei","Lily"])
boys.cartesian(girls).collect()
[('LiLei', 'HanMeiMei'),
('LiLei', 'Lily'),
('Tom', 'HanMeiMei'),
('Tom', 'Lily')]sortBy
#按照某种方式进行排序
#指定按照第3个元素大小进行排序
rdd = sc.parallelize([(1,2,3),(3,2,2),(4,1,1)])
rdd.sortBy(lambda x:x[2]).collect()
[(4, 1, 1), (3, 2, 2), (1, 2, 3)]zip
#按照拉链方式连接两个RDD,效果类似python的zip函数
#需要两个RDD具有相同的分区,每个分区元素数量相同
rdd_name = sc.parallelize(["LiLei","Hanmeimei","Lily"])
rdd_age = sc.parallelize([19,18,20])
rdd_zip = rdd_name.zip(rdd_age)
print(rdd_zip.collect())
[('LiLei', 19), ('Hanmeimei', 18), ('Lily', 20)]zipWithIndex
#将RDD和一个从0开始的递增序列按照拉链方式连接。
rdd_name = sc.parallelize(["LiLei","Hanmeimei","Lily","Lucy","Ann","Dachui","RuHua"])
rdd_index = rdd_name.zipWithIndex()
print(rdd_index.collect())
[('LiLei', 0), ('Hanmeimei', 1), ('Lily', 2), ('Lucy', 3), ('Ann', 4), ('Dachui', 5), ('RuHua', 6)]



![[Linux] 进程概念](https://img-blog.csdnimg.cn/direct/040aee4f663046de874543a9b993dcd4.png)