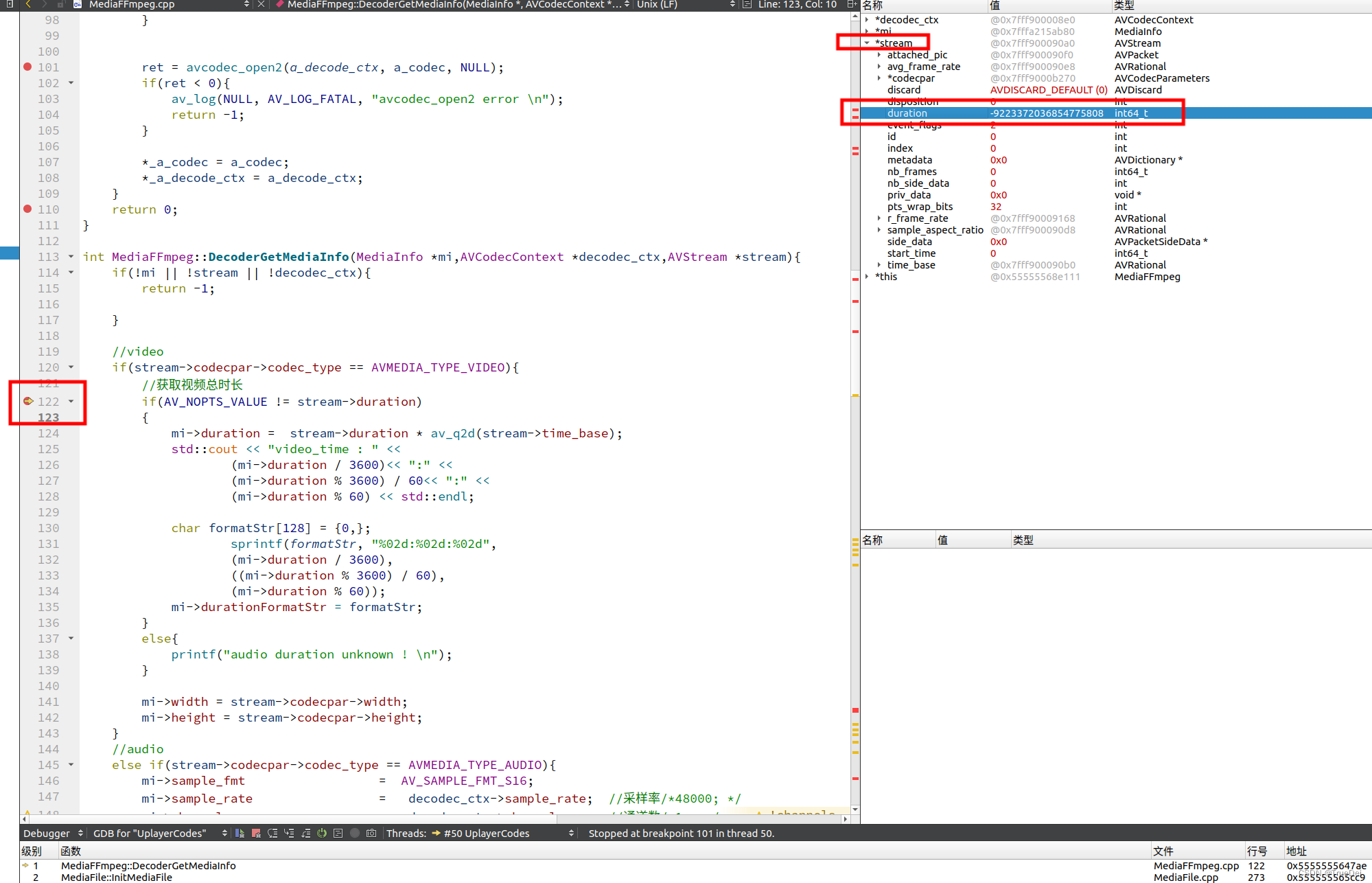
代码例子:
using namespace lf;
int main()
{
CString s1 = _t("http://www.csdn.net");
_string s2 = s1;
CString s3 = s2;
_pcn(s1);
_pcn(s2);
_pcn(s3);
return 0;
}
输出:
_Str.h
/*******************************************************************************************
文件名 : _Str<T>.h
功能 : 模拟std::string C# _Str<T> Java._Str<T>
程序字体 : Consolas,11
作者 : 李锋
手机 : 13828778863
Email : ruizhilf@139.com
创建时间 : 2016年07月06日
------------------------------最后一次修改时间:2024年04月25日
***********************************************************************************************/
#ifndef __STR_H_
#define __STR_H_
#include "global_c_str.h"
#include "_Memory.h"
#include "_Math.h"
//#define _STR_DEBUG_
#ifndef _CLR_
#else
using namespace System;
#endif
_LF_BEGIN_
template<class T1, class T2>
class _Pair;
template<class T>
class _Array;
template<class T>
class _iterator;
template<class T>
class _reverse_iterator;
/*
template<class T>
class charIterator
{
private:
T* _pChar;
public:
/// <summary>
/// 构造函数,传值迭代器管理的值
/// </summary>
/// <param name="pNode"></param>
inline charIterator(T* pChar) { _pChar = pChar; }
/// <summary>
/// 比较实现
/// </summary>
/// <param name="that"></param>
/// <returns></returns>
bool operator != (const charIterator& that) { return _pChar != that._pChar; }
/// <summary>
/// 自增实现
/// </summary>
/// <returns></returns>
inline charIterator& operator ++ () { ++_pChar; return *this; }
/// <summary>
/// 解引用,取值
/// </summary>
/// <returns></returns>
inline T& operator * () { return *_pChar; }
//LDIterator(const LDIterator&) = delete;
//LDIterator& operator=(const LDIterator&) = delete;
//~LDIterator() = default;
};
*/
/// <summary>
/// 字符串类
/// </summary>
/// <typeparam name="T"></typeparam>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-11-13
template<typename T>
class _Str //不要继承任何类
{
protected:
T* _pData; //指针,指向第一个元素
int _nLength; //无素个数
int _nBuffer; //剩余缓冲区大小
int _nDefaultBuffer = 8; //每次分配内容多分配缺省缓冲区大小
int _nAutoBufferCount = 0; //自动设置缓冲次数的计数器
public:
static const int npos = -1;
public://-----------------------------------------------------------------------------属性
/// <summary>
/// 返回以零为结尾的字符串指针,相当于 c_str()
/// </summary>
/// <returns></returns>
inline const T* GetData() const { return _pData; }
/// <summary>
/// 返回以零为结尾的字符串指针,相当于 c_str()
/// </summary>
__declspec(property(get = GetData)) const T* Data;
/// <summary>
/// 字符串长度
/// </summary>
/// <returns></returns>
inline const int GetLength() const { return _nLength; }
/// <summary>
/// 字符串长度
/// </summary>
__declspec(property(get = GetLength)) const int Length;
/// <summary>
/// 返回内存使用的长度,以 Byte 计数。
/// </summary>
/// <returns></returns>
inline const int GetMemoryLength()const { return sizeof(T) * (_nLength + _nBuffer + 1); }
/// <summary>
/// 返回内存使用的长度,以 Byte 计数。
/// </summary>
/// <returns></returns>
__declspec(property(get = GetMemoryLength)) const int MemoryLength;
/// <summary>
/// 返回字符串所占用的内存,以 Byte 计数。
/// </summary>
/// <returns></returns>
inline const int GetDataMemoryLength()const { return sizeof(T) * (_nLength); }
/// <summary>
/// 返回字符串所占用的内存,以 Byte 计数。。
/// </summary>
/// <returns></returns>
__declspec(property(get = GetDataMemoryLength)) const int DataMemoryLength;
/// <summary>
/// 获取默认缓冲数量
/// </summary>
/// <returns></returns>
inline int GetDefaultBuffer() const { return _nDefaultBuffer; }
/// <summary>
/// 设置默认缓冲数量
/// </summary>
/// <param name="nDefaultBuffer"></param>
inline void SetDefaultBuffer(const int& nDefaultBuffer) { _nDefaultBuffer = nDefaultBuffer; }
/// <summary>
/// 获取默认缓冲数量
/// </summary>
__declspec(property(get = GetDefaultBuffer, put = SetDefaultBuffer)) const int DefaultBuffer;
/// <summary>
/// 获取当前缓冲数量
/// </summary>
/// <returns></returns>
inline int GetBuffer() const { return _nBuffer; }
/// <summary>
/// 获取当前缓冲数量
/// </summary>
__declspec(property(get = GetBuffer)) const int Buffer;
/// <summary>
/// 是否为空
/// </summary>
/// <returns></returns>
inline bool IsEmpty() { return _nLength == 0; }
/// <summary>
/// 返回自动设置的缓冲次数
/// </summary>
/// <returns></returns>
inline int GetAutoBufferCount()const { return _nAutoBufferCount; }
public:
//---------------------------------------------------------------------------------构造与析构
/// <summary>
/// 缺省构造,默认为15个字符的缓冲大小
/// </summary>
inline _Str<T>()
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t _Str<T>()\n");
#endif
InitData(_nDefaultBuffer);
}
inline explicit _Str<T>(const int& nBuffer)
{
InitData(nBuffer);
}
inline explicit _Str<T>(const T& ch)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>::_Str<T>(const T& ch);\n");
#endif
InitData(1);
_pData[0] = ch;
_pData[1] = 0;
_nBuffer = 0;
_nLength = 1;
}
/// <summary>
/// std::string result(maxLen + 1, '0');
/// </summary>
/// <param name="nLength"></param>
/// <param name="ch"></param>
/// 创建时间: 2024-04-21 最后一次修改时间:2024-04-21
inline explicit _Str<T>(const size_t& nLength, const T& ch){
InitData(nLength,ch,true);
}
inline _Str<T>(const _Str<T>& rhs)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t _Str<T>(const _Str<T>& rhs)\n");
#endif // _STR_DEBUG_
if (rhs._nLength == 0)
InitData(0);
else
{
InitData(rhs._nLength);
Add(rhs._pData, rhs._nLength);
}
}
/// <summary>
/// 拷贝构造,默认为0个字符的缺省缓冲
/// </summary>
/// <param name="pStr"></param>
/// <param name="nBuffer">缓冲区个数</param>
/// <param name="bZeroBuffer">是否实始化 buffer</param>
/// 创建时间: ????-??-?? 最后一次修改时间:2023-02-08
inline _Str<T>(const T* pStr, const int& nBuffer = 0, bool bZeroBuffer = false)
{
// 定义: int _Str<T>::CSharp_IndexOf(const _Str<T>& sSub) const
// _Str<T> s = L"abc";
// s.CSharp_IndexOf( null ); 此时编译时会把 null 转换为 _Str<T>,用的就是这个构造涵数。
#ifdef _STR_DEBUG_
//_cout << _t("调用函数:_Str<T>::_Str<T>(const T *pStr,const int nBuffer)\t 参数为:") << _getc(pStr) << _geti(nBuffer) << _t("\n");
#endif
//错不能用这个,当_Str<T> aStr = null 时,先调用_Str<T>::StrLen_t<T>(pStr)
//_Str<T>::_Str<T>(const T *pStr) : _Array<T>(pStr,_Str<T>::StrLen_t<T>(pStr))
//并且构造函数中的子类虚函数是无效的,例如:当构造_Array时,_Str<T>还未构造出来
int nTrueBuffer = nBuffer >= 0 ? nBuffer : 0;
if (pStr != null)
{
int nLength = _Math::strLen_t<T>(pStr);
InitData(nLength + nTrueBuffer);
this->Add(pStr, nLength);
}
else
{
InitData(nTrueBuffer);
}
if (bZeroBuffer)
{
ZeroBuffer();
}
}
/// <summary>
/// 拷贝构造函数
/// </summary>
/// <param name="pstr">要拷贝的字符串</param>
/// <param name="nStrLength">要拷贝的字符串长度</param>
/// <param name="nCopyStart">从那里开始拷贝,索引从零开始</param>
/// <param name="nCopyLength">要拷贝的长度</param>
/// <param name="nBuffer">字符串区缓冲区长度</param>
/// 创建时间: ????-??-?? 最后一次修改时间:2021-11-02
inline explicit _Str<T>(const T* pstr, const int& nStrLength, const int& nCopyStart, const int& nCopyLength, const int& nBuffer = 0)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t _Str<T>(const T* pstr, const int& nStrLength, const int& nCopyStart, const int& nCopyLength, const int& nBuffer)\n");
#endif
if (pstr == null || nCopyLength == 0 || nCopyStart >= nStrLength)
{
InitData(nBuffer);
return;
}
if (nCopyLength + nCopyStart <= nStrLength)
{
_nLength = nCopyLength;
}
else
{
_nLength = nStrLength - nCopyStart;
}
_nDefaultBuffer = 0;
_nBuffer = nBuffer;
_pData = _Memory::New<T>(_nLength + _nBuffer + 1);
_Memory::Copy(_pData, pstr + nCopyStart, _nLength);
_pData[_nLength] = 0;
}
inline _Str<T>(const _stdstr& sText)
{
InitData(sText.length() + _nDefaultBuffer);
Add(sText.c_str(), sText.length());
}
#if _CLR_
/**
inline _Str<T>(String^ sText)
{
if (sText->Length > 0)
{
int nLength = sText->Length;
InitData(nLength + _nDefaultBuffer);
for (int i = 0; i < nLength; ++i) {
_pData[i] = sText[i];
}
_nLength = nLength;
_nBuffer -= nLength;
_pData[nLength] = 0;
}
else
{
InitData(_nDefaultBuffer);
}
}
*/
/// <summary>
///
/// </summary>
/// <param name="sText"></param>
/// <param name="nBuffer"></param>
/// <param name="bZeroBuffer"></param>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-02-08
inline _Str<T>(String^ sText, const int& nBuffer = 0, bool bZeroBuffer = false)
{
if (nBuffer >= 0)
InitData(sText->Length + nBuffer);
else
InitData(sText->Length);
//拷贝sText
if (sText->Length > 0)
{
int nLength = sText->Length;
for (int i = 0; i < nLength; ++i) {
_pData[i] = sText[i];
}
_nLength = nLength;
_nBuffer -= nLength;
_pData[nLength] = 0;
}
if (bZeroBuffer)
{
ZeroBuffer();
}
}
inline operator String ^ () const { return gcnew String(_pData); }
#endif
T* First()const { return _pData; }
T* last()const { return _pData + _nLength - 1; }
//inline charIterator begin()const { return charIterator(_pData); }
//inline charIterator end()const { return charIterator(_pData + _nLength); }
// C++用for遍历自定义类
inline T* begin()const { return _pData; }
inline T* end()const { return _pData + _nLength; }
inline ~_Str<T>()
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline ~_Str<T>()\n");
#endif
ClearMemory();
}
public://-----------------------------------------------------------------------------运算符重载
inline _Str<T>& operator=(const T* pStr)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t _Str<T>& _Str<T>::operator=(const T *pStr)\n");
#endif
if (_pData != pStr)
{
Clear();
Add(pStr);
}
return *this;
}
//重载的下标操作符
inline T& operator[](const int& nIndex)const
{
#ifdef _STR_DEBUG_
assert(nIndex < _nLength && nIndex >= 0);
#endif
return _pData[nIndex];
}
//_Str<T> s1,s2;
// s1 = s2; //此时设用这个函数,如果没写这个函数,
// 则调用基类_Array<T>& _Array<T>::operator=(const _Array<T> &rhs)
inline _Str<T>& operator=(const _Str<T>& rhs)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t _Str<T>& _Str<T>::operator=(const _Str<T>& rhs)\n");
#endif
if (&rhs != this)
{
Clear();
if (rhs._nLength > 0)
Add(rhs.Data, rhs._nLength);
}
return *this;
}
inline _Str<T>& operator+=(const _Str<T>& rhs)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t _Str<T>& _Str<T>::operator+=(const _Str<T>& rhs)\n");
#endif
Add(rhs.Data, rhs._nLength);
return *this;
}
/// <summary>
/// 如果不定义operator+=(const const T* psz)
/// _Str<T> s;
/// s+=L"abc"; =>> tmp = _Str<T>(L"abc") => s += tmp;
/// 编译器会把L"abc" 用构造函数转换成_Str<T>再用加,多了中间环节,缺少效率,
/// 而用explicit禁止隐式转换时,又为很麻烦! 例如: _Str<T> fun(); return L"abc" 编译不了。
/// </summary>
/// <param name="psz"></param>
/// <returns></returns>
inline _Str<T>& operator+=(const T* psz)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t _Str<T>& _Str<T>::operator+=(const T* psz)\n");
#endif
Add(psz);
return *this;
}
/// <summary>
/// 强制类型转换 char_ *p = (char_ *) this;
/// 或在函数调用中参数类型为 const char_ *p 时 ,而当你传入的类型为 str_时,编译器自动会把 str_ 类型转换为 str_._pData ;
/// </summary>
inline operator const T* () const { return _pData; }
friend _Str<T> operator + (const _Str<T>& sLeft, const _Str<T>& sRight) {
_Str<T> sResult(sLeft._nLength + sRight._nLength);
sResult.Add(sLeft);
sResult.Add(sRight);
return sResult;
}
//如果没有下面两个友元函数,语句: _Str<T> s = "0" + _Str<T>("1") + "2" + "3"; 产生 10 _Str<T> 对象, 有则只产生 7 个 _Str<T> 对象
friend _Str<T> operator + (const _Str<T>& sLeft, const int& iRigth)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline friend _Str<T> operator + (const _Str<T>& sLeft, const T* sRigth)\n");
#endif
_Str<T> sResult(sLeft.Data, 15);
sResult.Add(_Str<T>::Java_valueOf(iRigth));
return sResult;
}
/// <summary>
/// 为了提交效率,否则这个友无涵数可以不能写,只用
/// friend _Str<T> operator + (const _Str<T>& sLeft, const _Str<T>& sRigth);
/// 就可以了
/// </summary>
/// <param name="sLeft"></param>
/// <param name="sRigth"></param>
/// <returns></returns>
/// 创建时间: 2022-11-10 最后一次修改时间:2022-11-10
inline friend _Str<T> operator + (const T* sLeft, const _Str<T>& sRigth)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline friend _Str<T> operator + (const T* sLeft, const _Str<T>& sRigth)\n");
#endif
if (sLeft == null) { return sRigth; }
int n = _Math::strLen_t<T>(sLeft);
if (n == 0) return sRigth;
_Str<T> sResult(sLeft, sRigth.Length);
sResult.Add(sRigth);
return sResult;
}
inline friend _Str<T> operator + (const _Str<T>& sLeft, const T* pszRight)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline friend _Str<T> operator + (const _Str<T>& sLeft, const T* pszRight)\n");
#endif
if (pszRight == null) { return sLeft; }
int n = _Math::strLen_t<T>(pszRight);
if (n == 0) return sLeft;
_Str<T> sResult(sLeft.Length + n + 15);
sResult.Add(sLeft);
sResult.Add(pszRight, n);
return sResult;
}
#ifdef _CLR_
inline friend _Str<T> operator + (const _Str<T>& sLeft, String^ sRight)
{
_Str<T> sResult(sLeft.Data, sRight->Length);
sResult.Add(sRight);
return sResult;
}
inline friend _Str<T> operator + (String^ sLeft, const _Str<T>& sRight)
{
_Str<T> sResult(_t(""), sLeft->Length + sRight._nLength);
sResult.Add(sLeft);
sResult.Add(sRight);
return sResult;
}
inline friend bool operator==(const _Str<T>& sLeft, String^ sRight)
{
return sLeft == _Str<T>(sRight);
}
inline friend bool operator==(String^ sLeft, const _Str<T>& sRight)
{
return _Str<T>(sLeft) == sRight;
}
#endif
/// <summary>
/// 为了提交效率,否则这个友无涵数可以不能写,只用
/// friend _Str<T> operator + (const _Str<T>& sLeft, const _Str<T>& sRigth);
/// 就可以了
/// </summary>
/// <param name="sLeft"></param>
/// <param name="sRigth"></param>
/// <returns></returns>
/// 创建时间: 2022-11-10 最后一次修改时间:2022-11-10
friend bool operator > (const _Str<T>& sLeft, const _Str<T>& sRigth)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t bool operator > (const str_& sLeft, const str_& sRigth)\n");
#endif // _STR__DEBUG_
return _Math::strCmp_t<T>(sLeft.Data, sRigth.Data) > 0;
}
friend bool operator < (const _Str<T>& sLeft, const _Str<T>& sRigth)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t bool operator > (const _Str<T>& sLeft, const _Str<T>& sRigth)\n");
#endif
return _Math::strCmp_t<T>(sLeft.Data, sRigth.Data) < 0;
}
friend bool operator == (const _Str<T>& sLeft, const _Str<T>& sRigth)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t bool operator < (const _Str<T>& sLeft, const _Str<T>& sRigth)\n");
#endif
return _Math::strCmp_t<T>(sLeft.Data, sRigth.Data) == 0;
}
friend bool operator != (const _Str<T>& sLeft, const _Str<T>& sRigth)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t bool operator < (const _Str<T>& sLeft, const _Str<T>& sRigth)\n");
#endif
return _Math::strCmp_t<T>(sLeft.Data, sRigth.Data) != 0;
}
/// <summary>
///
/// </summary>
/// <param name="sLeft"></param>
/// <param name="sRigth"></param>
/// <returns></returns>
/// 创建时间: 2021-10-27 最后一次修改时间:2021-10-27
friend bool operator == (const _Str<T>& sLeft, const T* sRigth)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t bool operator == (const _Str<T>& sLeft, const T* sRigth)\n");
#endif
return _Math::strCmp_t<T>(sLeft.Data, sRigth) == 0;
}
/// <summary>
///
/// </summary>
/// <param name="sLeft"></param>
/// <param name="sRigth"></param>
/// <returns></returns>
/// 创建时间: 2024-04-19 最后一次修改时间:2024-04-19
friend bool operator != (const _Str<T>& sLeft, const T* sRigth)
{
return _Math::strCmp_t<T>(sLeft.Data, sRigth) != 0;
}
friend bool operator >= (const _Str<T>& sLeft, const T* sRigth)
{
int n = _Math::strCmp_t<T>(sLeft.Data, sRigth);
return (n > 0 || n == 0);
}
friend bool operator <= (const _Str<T>& sLeft, const T* sRigth)
{
int n = _Math::strCmp_t<T>(sLeft.Data, sRigth);
return (n < 0 || n == 0);
}
public://-----------------------------------------------------------------------------重写
/// <summary>
/// 添加字符串,充许pData == null 或者 nLength = 0
/// </summary>
/// <param name="pData"></param>
/// <param name="nLength"></param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-10-30 2023-03-21
inline const _Str<T>& Add(const T* pData, const int nLength)
{
//_pin(pData);
//_cout << _t("_Str<T>:\t inline const T* Add(const T* pData, const int nLength) 参数:") << _geti(nLength) << _t("\n");
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline const T* Add(const T* pData, const int nLength) 参数:") << _geti(nLength) << _t("\n");
#endif
//要判断 *pData == 0 防止 str_.Add(L"\0",1);
if (pData == null || nLength <= 0 || *pData == 0) { return *this; }
if (_nBuffer >= nLength)
{
_Memory::Copy<T>(_pData + _nLength, pData, nLength);
_nBuffer -= nLength;
_nLength += nLength;
}
else
{
/*
T* pNew = _Memory::New<T>(this->_nDefaultBuffer + _nLength + nLength + 1, false);
if (_nLength > 0)
_Memory::Copy<T>(pNew, _pData, _nLength); //拷贝原来的数据
_Memory::Copy<T>(pNew + _nLength, pData, nLength); //拷贝新的内存
_Memory::Delete<T>(_pData, _nLength + _nBuffer + 1); //释放内存
_nLength += nLength;
_nBuffer = this->_nDefaultBuffer;
_pData = pNew;
*/
//SetBuffer(nLength + _nDefaultBuffer); //旧版本
SetBuffer(nLength + _nDefaultBuffer * _Math::pow(2, _nAutoBufferCount)); //自动设置缓冲次数加
if (_nBuffer >= nLength)
{
_Memory::Copy<T>(_pData + _nLength, pData, nLength);
_nBuffer -= nLength;
_nLength += nLength;
}
else
{
throw _t("设置缓冲区失败!");
}
++_nAutoBufferCount; //设置缓冲次数加1
}
_pData[_nLength] = 0;
return *this;
}
inline const _Str<T>& Add(const T* pStr) { return Add(pStr, _Math::strLen_t<T>(pStr)); }
inline const _Str<T>& Add(const _Str<T>& rs) { return Add(rs._pData, rs._nLength); }
/// <summary>
/// 添加一个字符,此函数会忽略 T == 0 的字符结束标志。
/// </summary>
/// <param name="aChar"></param>
/// <returns></returns>
/// 创建时间: 2022-12-08 最后一次修改时间:2022-12-08
inline const _Str<T>& Add(const T& aChar)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline const _Str<T>& Add(const T& aChar) 参数:") << _geti(aChar) << _t("\n");
#endif
//要判断 *pData == 0 防止 str_.Add(L"\0",1);
if (aChar == 0) { return *this; }
if (_nBuffer >= 1)
{
_pData[_nLength] = aChar;
_nBuffer -= 1;
_nLength += 1;
_pData[_nLength] = 0;
}
else
{
SetBuffer(1 + _nDefaultBuffer * _Math::pow(2, _nAutoBufferCount)); //自动设置缓冲次数加
if (_nBuffer >= 1)
{
_pData[_nLength] = aChar;
_nBuffer -= 1;
_nLength += 1;
_pData[_nLength] = 0;
}
else
{
throw _t("设置缓冲区失败!");
}
++_nAutoBufferCount;
}
return *this;
}
inline const _Str<T>& del(const int& nStartPos, const int& nLength)
{
if (nStartPos + nLength > _nLength)
{
_nBuffer = _nBuffer + _nLength - nStartPos;
_nLength = nStartPos + 1;
}
else if (nStartPos + nLength >= _nLength)
{
_nLength -= nLength;
_nBuffer += nLength;
}
else
{
for (int n = nStartPos + nLength; n < _nLength; ++n)
{
_pData[n - nLength] = _pData[n];
}
_nLength -= nLength;
_nBuffer += nLength;
}
return *this;
}
/// <summary>
/// 初始化数据,并设置缓冲区大小,如果设置bInitValue == true,
/// 则所有缓冲都会用 tValue填充,这时长度是:nBuffer。
/// </summary>
/// <param name="nBuffer"></param>
/// <param name="tValue"></param>
/// <param name="bInitValeu"></param>
/// 创建时间: ????-??-?? 最后一次修改时间:2024-04-21
inline void InitData(const int& nBuffer,const T& tValue = 0, const bool bInitValue = false)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline void InitData(const int& nBuffer) 参数:") << _geti(nBuffer) << _t("\n");
#endif
if (nBuffer < 0) {
throw _t("_Str<T>::InitData错误: nBuffer < 0");
}
if (bInitValue){
_nLength = nBuffer;
_nBuffer = 0;
_pData = _Memory::New<T>(_nLength + 1);
for (int i = 0; i < _nLength; ++i){
_pData[i] = tValue;
}
_pData[_nLength] = 0;
}else{
_nLength = 0;
_nBuffer = nBuffer;
_pData = _Memory::New<T>(_nBuffer + 1);
_pData[0] = 0;
}
}
/// <summary>
/// 清空内容,但并不释放内存,所有数据变缓冲。
/// </summary>
inline void Clear()
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T> : void ClearData()\n");
#endif
//不充许出现null指针
_nBuffer = _nLength + _nBuffer;
_nLength = 0;
if(_nBuffer > 0)
_pData[0] = 0;
}
inline void ClearMemory()
{
_Memory::Delete<T>(_pData, _nLength + _nBuffer + 1);
_pData = null;
_nLength = 0;
_nBuffer = 0;
}
/// <summary>
/// 设置缓冲数量
/// </summary>
/// <typeparam name="T"></typeparam>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-11-17
inline void SetBuffer(const int& nBuffer)
{
#ifdef _STR_DEBUG_
_cout << _t("_Str<T>:\t inline void SetBuffer(const int& nBuffer)参数:") << _geti(nBuffer) << "\n";
#endif
if (nBuffer <= 0 || nBuffer <= _nBuffer) return;
T* pNew = _Memory::New<T>(_nLength + nBuffer + 1); //分配新内存,这里分配内存时注意要加 1
if (_nLength > 0)//拷贝旧数据
{
_Memory::Copy(pNew, _pData, _nLength);
}
_Memory::Delete<T>(_pData, _nLength + _nBuffer + 1); //空字符点一位
_pData = pNew;
_nBuffer = nBuffer;
_pData[_nLength] = 0; //设置一下结束字符
}
/// <summary>
/// 重新设置字符串长度,这个长度不能大于原字符长度加上缓冲数量之和
/// </summary>
/// <param name="nNewLength"></param>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-05-12
inline void SetNewLength(const int& nNewLength)
{
assert(nNewLength <= _nLength + _nBuffer && nNewLength >= 0);
_nBuffer = _nBuffer - nNewLength + _nLength;
_nLength = nNewLength;
_pData[nNewLength] = 0;
}
/// <summary>
/// 补位4,用0替代,返回一个副本,例如:
/// 1 => 0001
/// 10 => 0010
/// 99999 => 9999
/// </summary>
/// <param name="nCount"></param>
/// <returns></returns>
_Str<T> intStrFillUp(int nCount = 4) const
{
if (nCount <= 0) return _t("");
if (nCount > _nLength)
{
_Str<T> sResult(_t(""), nCount);
for (int i = 1; i <= nCount - _nLength; ++i) {
sResult.Add(_t('0'));
}
for (int i = 0; i < _nLength; ++i) {
sResult.Add(_pData[i]);
}
return sResult;
}
else
{
return _Str<T>(_pData, _nLength, _nLength - nCount, nCount);
}
}
public:
/// <summary>
/// 保留小数位,四舍五入
/// </summary>
/// <param name="dNumber">保留小数位的数字</param>
/// <param name="nDigitsCount">保留小数的位数</param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2021-11-02
static _Str<T> KeepSmallDigits(const double& dNumber, const int nDigitsCount)
{
assert(nDigitsCount < 30);
_Str<T> sResult(50);
_Mem<T> m(50);
__int64 iNumber = (__int64)dNumber;
//取整数部分
sResult.Add(_Math::IntToStr(iNumber, m.Data));
if (nDigitsCount == 0)
return sResult;
else
{
sResult.Add(_t("."));
iNumber = (__int64)((dNumber - iNumber) * _Math::pow(10, nDigitsCount + 1)); //取小数部份+1位
//四舍五入
if (_Math::digitsOf(iNumber, 1) >= 5)
iNumber = (iNumber / 10 + 1) * 10;
iNumber = iNumber / 10;
if (iNumber == 0) //小数部分==0
{
for (int n = 0; n < nDigitsCount; ++n)
{
sResult.Add(_t('0'));
}
}
else
{
sResult.Add(_Math::intToStr(iNumber, m.Data));
}
}
return sResult;
}
//----------------------------------------------------------------------------------------------------功能函数
/// <summary>
/// 除例外字符串的长度
/// </summary>
/// <param name="pCharArray"></param>
/// <returns></returns>
inline int Length_except(const T* pCharArray)const
{
int n = 0;
for (int i = 0; i < _nLength; ++i) {
T ch = _pData[i];
if (_Math::strChr(pCharArray, ch) == -1) {
++n;
}
}
return n;
}
/// <summary>
/// 子字符串是从字符位置 iStart 开始并跨越 iLength 个字符(或直到字符串末尾,以先到者为准)的对象部分。
/// </summary>
/// <typeparam name="T"></typeparam>
/// 创建时间: ????-??-?? 最后一次修改时间:2024-05-13
inline _Str<T> SubStr(const int iStart, const int iLength) const {
if (iStart >= _nLength || iLength <= 0)
return _Str<T>();
int nTrueStart = iStart > 0 ? iStart : 0;
int nTrueLength = (nTrueStart + iLength <= _nLength) ? iLength : _nLength - nTrueStart;
return _Str<T>(_pData, _nLength, nTrueStart, nTrueLength);
}
/// <summary>
/// 返回全是大写字母的拷贝
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-03-25 最后一次修改时间:2023-03-25
inline _Str<T> Upper()const
{
_Str<T> sResult;
sResult.SetBuffer(_nLength);
for (int i = 0; i <= _nLength; ++i)
{
sResult._pData[i] = gs.c_ToUpper(_pData[i]);
}
sResult._nLength = _nLength;
sResult._nBuffer = 0;
return sResult;
}
/// <summary>
/// 返回全是小写字母的持由
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-03-25 最后一次修改时间:2023-03-25
inline _Str<T> Lower()const
{
_Str<T> sResult;
sResult.SetBuffer(_nLength);
for (int i = 0; i <= _nLength; ++i)
{
sResult._pData[i] = gs.c_ToLower(_pData[i]);
}
sResult._nLength = _nLength;
sResult._nBuffer = 0;
return sResult;
}
//添加换行符
inline void Newline() { Add('\n'); }
//添加水平制表键
inline void HorizontalTab() { Add('\t'); }
//添加垂直制表键
inline void VerticalTab() { Add('\v'); };
//添加退格键
inline void Backspace() { Add('\b'); }
//添加回车键
inline void CarriageReturn() { Add('\r'); }
//添加进纸键
inline void Formfeed() { Add('\f'); }
//添加响铃符
inline void Alert() { Add('\a'); }
//添加反斜杠键
inline void Backslash() { Add('\\'); }
//添加问号
inline void QuestionMark() { Add('\?'); }
//添加单引号
inline void SingleQuote() { Add('\''); }
//添加双引号
inline void DoubleQuote() { Add('\"'); }
public://---------------------------------------------------------------------------------- C++ Std:string 方法
/// <summary>
/// 返回数据指针
/// </summary>
/// <returns></returns>
inline const T* std_c_str() const { return _pData; }
/// <summary>
///
/// </summary>
/// <returns></returns>
inline size_t std_size() const { return _nLength; }
/// <summary>
/// 返回在不重新分配内存时可存储字符的最大个数
/// </summary>
/// <returns>返回string分配的存储容量</returns>
inline int std_capacity()const { return _nLength + _nBuffer; }
/// <summary>
/// 字符串长度
/// </summary>
/// <returns></returns>
inline int std_Length()const { return _nLength; }
/// <summary>
/// 添加 nCount 个字符串
/// </summary>
/// <param name="str"></param>
/// <param name="nCount"></param>
/// 创建时间: 2022-12-08 最后一次修改时间:2022-12-08
inline const _Str<T>& AppendCount(const _Str<T> &str, const int nCount)
{
if (nCount >= 0 && str._nLength > 0)
{
SetBuffer(str._nLength * nCount + _nDefaultBuffer);
for (int i = 0; i < nCount; ++i) { Add(str); }
}
return *this;
}
inline const _Str<T>& std_append(const T& aChar) { return Add(aChar); }
inline const _Str<T>& std_append(const T* pStr) { return Add(pStr); }
inline const _Str<T>& std_append(const T* pStr, const int nCount) { return Add(pStr, nCount); }
inline const _Str<T>& std_append(const _Str<T>& rs) { return Add(rs); }
/// <summary>
/// 返回一个新构造的字符串对象,其值初始化为此对象的子字符串的副本,相当于区间 [pos1,pos2] 相当于 SubStr(pos1,pos2-pos1+1)
/// 子字符串是从字符位置 pos 开始并跨越 len 个字符(或直到字符串末尾,以先到者为准)的对象部分。
/// </summary>
/// <typeparam name="T"></typeparam>
inline _Str<T> std_substr(const int iStart, const int iLength) const { return SubStr(iStart, iLength); }
/*
a) =, assign() //赋以新值
b) swap() //交换两个字符串的内容
c) +=, append(), push_back() //在尾部添加字符
d) insert() //插入字符
e) erase(int nStart, int nEnd) //删除nStart—nEnd位置字符
f) clear() //删除全部字符
g) replace() //替换字符
h) + //串联字符串
i) == , != , <, <= , >, >= , compare() //比较字符串
j) size(), _nLength //返回字符数量
k) Maxsize() //返回字符的可能最大个数
l) empty() //判断字符串是否为空
m) capacity() //返回重新分配之前的字符容量
n) reserve() //保留一定量内存以容纳一定数量的字符
o)[], at() //存取单一字符
p) >> , getline() //从stream读取某值
q) << //将谋值写入stream
r) copy() //将某值赋值为一个C_string
s) c_str() //将内容以C_string返回
t) data() //将内容以字符数组形式返回
u) SubStr() //返回某个子字符串
v)查找函数
w)begin() end() //提供类似STL的迭代器支持
x) rbegin() rend() //逆向迭代器
y) get_allocator() //返回配置器
*/
//从nStart开始向后查找字符c在当前字符串的位置
inline int std_find(const T& c, const int& nStart = 0) const { return _Math::find<T>(&c, nStart, 1); }
//从nStart开始向后查找字符串s在当前串中的位置
inline int std_find(const T* pFindStr, const int& nStart = 0) const { return _Math::find<T>(pFindStr, nStart, _Math::strLen_t<T>(pFindStr)); }
//从nStart开始向后查找字符串s中前nFindLength个字符在当前串中的位置
inline int std_find(const T* pFindStr, const int& nStart, const int& nFindLength) const { return find_(pFindStr, nStart, nFindLength); }
//从pos开始向后查找字符串s在当前串中的位置
inline int std_find(const _Str<T>& s, const int& nStart = 0) const { return _Math::find<T>(_pData,_nLength,s._pData,s._nLength, nStart); }
/// <summary>
/// std::string::rfind是一个字符串类成员函数,用于搜索字符串中任何字符的最后出现。
/// 如果字符存在于字符串中,则它返回该字符在字符串中最后一次出现的索引,否则它将返
/// 回string::npos,它指示指针位于字符串的末尾。
/// </summary>
/// <param name="c"></param>
/// <param name="nStart"></param>
/// <returns></returns>
inline int std_rfind(T c, const int& rStart = 0) const { return _Math::rfind<T>(_pData, _nLength, &c, 1, rStart); }
inline int std_rfind(const T* pFindStr, const int& rStart = 0) const { return _Math::rfind<T>(_pData,_nLength,pFindStr, _Math::strLen_t<T>(pFindStr), rStart);}
inline int std_rfind(const T* pFindStr, const int& nLength, const int& rStart = 0) const { return _Math::RFind<T>(_pData, _nLength, pFindStr, nLength, rStart); }
inline int std_rfind(const _Str<T>& s, const int& rStart = 0) const { return _Math::rfind<T>(_pData, _nLength, s._pData,s._nLength, rStart); }
//从nStart开始向后查找字符c第一次出现的位置
inline int std_find_First_of(T c, const int& nStart = 0) const { return std_find_First_of_(c, nStart); }
int std_find_First_of(const T* pStr, const int& nStart = 0) const { return std_find_First_of_(pStr, nStart, _Math::strLen_t<T>(pStr)); }
int std_find_First_of(const T* pStr, const int& nStart, const int& nFindLength) const { return std_find_First_of_(pStr, nStart, nFindLength); }
int std_find_First_of(const _Str<T>& s, const int& nStart = 0) const { return std_find_First_of_(s, nStart); }
//从nStart开始向后查找字符c第一次没有出现的位置
inline int std_find_First_not_of(T c, const int& nStart = 0) const { return std_find_First_not_of_(c, nStart); }
int std_find_First_not_of(const T* pStr, const int& nStart = 0) const { return std_find_First_not_of_(pStr, nStart, _Math::strLen_t<T>(pStr)); }
int std_find_First_not_of(const T* pStr, const int& nStart, const int& nFindLength) const { return std_find_First_not_of_(pStr, nStart, nFindLength); }
int std_find_First_not_of(const _Str<T>& s, const int& nStart = 0) const { return std_find_First_not_of_(s, nStart); }
//从nStart开始向前查找字符c第一次出现的位置
inline int std_find_last_of(const T& c, const int& nStart = this->npos) const { return std_find_last_of_(c, nStart); }
int std_find_last_of(const T* pStr, const int& nStart = this->npos) const { return std_find_last_of_(pStr, nStart, _Math::strLen_t<T>(pStr)); }
int std_find_last_of(const T* pStr, const int& nStart, const int& nFindLength) const { return std_find_last_of_(pStr, nStart, nFindLength); }
int std_find_last_of(const _Str<T>& s, const int& nStart = this->npos) const { return std_find_last_of_(s, nStart); }
//从nStart开始向前查找字符c第一次没有出现的位置
inline int std_find_last_not_of(T c, const int& nStart = this->npos) const { return std_find_last_not_of_(c, nStart); }
int std_find_last_not_of(const T* pStr, const int& nStart = this->npos) const { return std_find_last_not_of_(pStr, nStart, _Math::strLen_t<T>(pStr)); }
int std_find_last_not_of(const T* pStr, const int& nStart, const int& nFindLength) const { return std_find_last_not_of_(pStr, nStart, nFindLength); }
int std_find_last_not_of(const _Str<T>& s, const int& nStart = this->npos) const { return std_find_last_not_of_(s, nStart); }
/// <summary>
/// std::string::erase 是 C++ 标准库中的一个成员函数,用于删除字符串中指定范围的字符。
/// 其中,pos 是要删除字符的起始位置,count 是要删除的字符数。如果不提供 count 参数,
/// 则默认删除从 pos 开始到字符串末尾的所有字符。函数返回对修改后的字符串的引用。
/// </summary>
/// <param name="pos"></param>
/// <param name="count"></param>
/// <returns></returns>
/// 创建时间: 2024-04-21 最后一次修改时间:2024-04-21
_Str<T>& std_erase(const size_t& pos = 0, const size_t& count = npos) {
if (pos < _nLength)
{
if (pos + count < _nLength){
for (size_t n = pos; n < pos + count; n++) {
_pData[n] = 0;
}
_nLength -= count;
_nBuffer += count;
}
else {
for (size_t n = pos; n < _nLength; n++) {
_pData[n] = 0;
}
_nLength = pos;
_nBuffer = _nLength - pos;
}
}
return *this;
}
/// <summary>
/// 模拟std::string::erase
/// </summary>
/// <param name="first"></param>
/// <param name="last"></param>
/// <returns></returns>
/// 创建时间: 2024-04-21 最后一次修改时间:2024-04-22
_Str<T>& std_erase(const _iterator<T>& first, const _iterator<T>& last) {
/*
std::string s1 = "0abc023030000";
s1.erase(std::find_if(s1.rbegin(), s1.rend(),
[](char ch) { return ch != '0'; }).base(), s1.end());
std::cout << "s1=" << s1 << "\n";
_string s2 = _t("0abc023030000");
s2.std_erase(lf::_find_if(s2.std_rbegin(), s2.std_rend(),
[](wchar_t ch) { return ch != _t('0'); }).std_base(), s2.std_end());
std::wcout << _t("s2=") << s2 << _t("\n");
*/
_Str<T> tmp(_t(""), _nLength);
const T* pf = first;
T* pl = (T*)(const T*)last;
int n = pf - _pData;
//拷贝前半部分
if (n > 0){
for (int i = 0; i < n; ++i){
tmp.Add(*(_pData + i));
}
}
++pl;
//拷贝后半部分
while (*pl) {
tmp.Add(*pl);
++pl;
}
//清除字符,注意,在这里不要清除内存
this->Clear();
this->Add(tmp); //拷贝进来
return *this;
}
/// <summary>
/// std::string::begin() 是 C++ 标准库中的一个成员函数,
/// 用于返回指向字符串中第一个字符的迭代器
/// </summary>
/// <returns></returns>
/// 创建时间: 2024-04-21 最后一次修改时间:2024-04-21
const _iterator<T> std_begin() const noexcept { return _pData; }
/// <summary>
/// std::string::end() 是 C++ 标准库中的一个成员函数,用于返回指
/// 向字符串中最后一个字符之后的迭代器
/// </summary>
/// <returns></returns>
/// 创建时间: 2024-04-21 最后一次修改时间:2024-04-21
const _iterator<T> std_end() const noexcept { return _pData + _nLength; }
/// <summary>
/// std::string::rbegin() 是 C++ 标准库中的一个成员函数,用于返回指
/// 向字符串中最后一个字符的逆向迭代器,指针指向最后一个 T 的 下一位置,
/// 即是字符串结束符的 #0。
/// </summary>
/// <returns></returns>
/// 创建时间: 2024-04-21 最后一次修改时间:2024-04-22
const _reverse_iterator<T> std_rbegin() const noexcept { return (_reverse_iterator<T>)(_pData + _nLength); }
/// <summary>
/// std::string::rend() 是 C++ 标准库中的一个成员函数,用于返回指向字符串中
/// 第一个字符之前的逆向迭代器。它的原型如下
/// </summary>
/// <returns></returns>
const _reverse_iterator<T> std_rend() const noexcept { return (_reverse_iterator<T>)(_pData); }
public://--------------------------------------------------------------------------------模似CSharp字符串_Str<T>
//
// 摘要:
// 报告指定字符在此实例中的第一个匹配项的从零开始的索引。 搜索从指定字符位置开始,并检查指定数量的字符位置。
//
// 参数:
// value:
// 要查找的 Unicode 字符。
//
// startIndex:
// 搜索起始位置。
//
// count:
// 要检查的字符位置数。
//
// 返回结果:
// 如果找到该字符,则为从字符串的起始位置开始的 value 从零开始的索引位置;否则为 -1。
//
// 异常:
// T:System.ArgumentOutOfRangeException:
// count 或 startIndex 为负数。 - 或 - startIndex 大于此字符串的长度。 - 或 - count 大于此字符串的长度减 startIndex。
/// <summary>
///
/// </summary>
/// <param name="value"></param>
/// <param name="startIndex"></param>
/// <param name="count"></param>
/// <returns></returns>
/// 创建时间: 2021-10-28 最后一次修改时间:2021-10-28 优化测式: 否
//inline int CSharp_IndexOf(const T& value, const int& startIndex, const int& count) const
//{
//return _Math::find<T>(&value, 1, _pData, count, startIndex);
//return -1;
//}
//
// 摘要:
// 报告指定 Unicode 字符在此字符串中的第一个匹配项的从零开始的索引。 该搜索从指定字符位置开始。
//
// 参数:
// value:
// 要查找的 Unicode 字符。
//
// startIndex:
// 搜索起始位置。
//
// 返回结果:
// 如果找到该字符,则为从字符串的起始位置开始的 value 从零开始的索引位置;否则为 -1。
//
// 异常:
// T:System.ArgumentOutOfRangeException:
// startIndex 小于 0(零)或大于此字符串的长度。
int CSharp_IndexOf(const T& value, const int& startIndex) const { return CSharp_indexOf(value, startIndex, this->_nLength - startIndex - 1);}
//
// 摘要:
// 报告指定字符串在此实例中的第一个匹配项的从零开始的索引。
//
// 参数:
// value:
// 要搜寻的字符串。
//
// 返回结果:
// 如果找到该字符串,则为 value 的从零开始的索引位置;如果未找到该字符串,则为 -1。 如果 value 为 System._Str<T>.Empty,则返回值为
// 0。
//
// 异常:
// T:System.ArgumentNullException:
// value 为 null。
inline int CSharp_IndexOf(const _Str<T>& value) const{ return std_find(value); }
//
// 摘要:
// 报告指定字符串在此实例中的第一个匹配项的从零开始的索引。 该搜索从指定字符位置开始。
//
// 参数:
// value:
// 要搜寻的字符串。
//
// startIndex:
// 搜索起始位置。
//
// 返回结果:
// 如果找到该字符串,则为从当前实例的起始位置开始的从零开始的 value 的索引位置;否则为 -1。 如果 value 为 System._Str<T>.Empty,则返回值为
// startIndex。
//
// 异常:
// T:System.ArgumentNullException:
// value 为 null。
//
// T:System.ArgumentOutOfRangeException:
// startIndex 小于 0(零)或大于此字符串的长度。
inline int CSharp_IndexOf(const _Str<T>& value, const int& startIndex) const{ return std_find(value, startIndex); }
//
// 摘要:
// 报告指定字符串在此实例中的第一个匹配项的从零开始的索引。 搜索从指定字符位置开始,并检查指定数量的字符位置。
//
// 参数:
// value:
// 要搜寻的字符串。
//
// startIndex:
// 搜索起始位置。
//
// count:
// 要检查的字符位置数。
//
// 返回结果:
// 如果找到该字符串,则为从当前实例的起始位置开始的从零开始的 value 的索引位置;否则为 -1。 如果 value 为 System._Str<T>.Empty,则返回值为
// startIndex。
//
// 异常:
// T:System.ArgumentNullException:
// value 为 null。
//
// T:System.ArgumentOutOfRangeException:
// count 或 startIndex 为负数。 - 或 - startIndex 大于此字符串的长度。 - 或 - count 大于此字符串的长度减 startIndex。
inline int CSharp_IndexOf(const _Str<T>& value, const int& startIndex, const int& count) const
{
assert(startIndex + count <= this->_nLength);
return -1;
}
//int indexOf(const _Str<T>& value, StringComparison comparisonType) const;
//int indexOf(const _Str<T>& value, const int& startIndex, StringComparison comparisonType) const;
//
// 摘要:
// 报告指定 Unicode 字符在此字符串中的第一个匹配项的从零开始的索引。
//
// 参数:
// value:
// 要查找的 Unicode 字符。
//
// 返回结果:
// 如果找到该字符,则为 value 的从零开始的索引位置;如果未找到,则为 -1。
inline int CSharp_IndexOf(const T& value) const { return _Math::strChr_t<T>(_pData, value); }
//int indexOf(const _Str<T>& value, const int& startIndex, const int& count, StringComparison comparisonType) const;
//int indexOfAny(char[] anyOf, const int& startIndex, const int& count) const;
//int indexOfAny(char[] anyOf, const int& startIndex) const;
//int indexOfAny(char[] anyOf) const;
inline _Str<T> CSharp_Substring(const int& startIndex, const int& length) const
{
return _Str<T>(_pData, _nLength, startIndex, length);
}
inline _Str<T> CSharp_Substring(const int& startIndex)const
{
return _Str<T>(_pData, this->_nLength, startIndex, _nLength);
}
/// <summary>
/// 返回除去两边的空格和控制字符
/// </summary>
/// <returns></returns>
/// 创建时间: 2022-10-06 最后一次修改时间: 2022-10-06 已测试
inline _Str<T> CSharp_Trim()const
{
int nStart = 0; int nEnd = 0;
bool bFind = false;
for (nStart = 0; nStart < _nLength; ++nStart)
{
T c = _pData[nStart];
if (!gcf.gcf_iscntrl(c) && c != _t(' ')) { bFind = true; break; }
}
//if (nStart == _nLength - 1) return _string(); //错,当字符是 1 个是时,任何情况 nStart == 0 成立
if (nStart == _nLength - 1)
{
if (bFind) {
return *this;
}
else {
return _Str<T>();
}
}
bFind = false;
for (nEnd = _nLength - 1; nEnd >= nStart; --nEnd)
{
T c = _pData[nEnd];
if (!gcf.gcf_iscntrl(c) && c != _t(' ')) { break; }
}
int nCopyLength = nEnd - nStart + 1;
if (nCopyLength <= 0) return _Str<T>();
return CSharp_Substring(nStart, nCopyLength);
}
/// <summary>
/// 除去右边连续的tChar字符,例 :
/// abcaa.TrimRight('a') == abc
/// abcaaba.TrimRight('a') = abcaab
/// </summary>
/// <param name="tChar"></param>
/// <returns></returns>
/// 创建时间: 2024-04-25 最后一次修改时间: 2024-04-25 已测试
inline _Str<T> TrimRight(const T& tChar)
{
int n = 0;
for(int i = _nLength - 1; i >= 0; --i){
if (_pData[i] == tChar){
_pData[i] = 0;
++n;
}
else{
break;
}
}
_nBuffer += n;
_nLength -= n;
return *this;
}
/// <summary>
/// 返回小写副本
/// </summary>
/// <returns></returns>
/// 创建时间: 2022-10-06 最后一次修改时间: 2022-10-06
inline _Str<T> CSharp_ToLower() const
{
_Str<T> sResult(_t(""), _nLength + 1);
for (int i = 0; i < _nLength; ++i) { sResult._pData[i] = gs.c_ToLower(_pData[i]); }
sResult._nBuffer = 0;
sResult._nLength = _nLength;
sResult._pData[_nLength] = 0;
return sResult;
}
/// <summary>
/// 返回大写副本
/// </summary>
/// <returns></returns>
inline _Str<T> CSharp_ToUpper()const
{
_Str<T> sResult(_t(""), _nLength + 1);
for (int i = 0; i < _nLength; ++i) { sResult._pData[i] = gs.c_ToUpper(_pData[i]); }
sResult._nBuffer = 0;
sResult._nLength = _nLength;
sResult._pData[_nLength] = 0;
return sResult;
}
/*
/// <summary>
///
/// </summary>
/// <param name="sSub"></param>
/// <returns></returns>
/// 创建时间: 2022-10-06 最后一次修改时间: 2022-10-06 已测试
int CSharp_IndexOf(const _Str<T>& sSub)const
{
if (_nLength == 0 || sSub._nLength == 0) return -1;
const int nEnd = _nLength - sSub._nLength;
if (nEnd < 0) return -1;
for (int i = 0; i <= nEnd; ++i) {
bool bFind = true;
for (int j = 0; j < sSub._nLength; ++j)
{
if (_pData[i + j] != sSub._pData[j])
{
bFind = false;
break;
}
}
if (bFind) return i;
}
return -1;
}
*/
/// <summary>
/// 返回一个新字符串,其中当前实例中出现的所有指定字符串都替换为另一个指定的字符串。
/// </summary>
/// <param name="oldValue"></param>
/// <param name="newValue"></param>
/// <returns></returns>
/// 创建时间: 2022-12-04 最后一次修改时间: 2022-12-04 已测试
_Str<T> CSharp_Replace(const _Str<T>& oldValue,const _Str<T>& newValue)
{
_Str<T> sResult(_t(""), _nLength + newValue._nLength);
int iCopyStart = 0;
int i = std_find(oldValue);
while (i != -1)
{
if (i - iCopyStart > 0)
sResult.Add(SubStr(iCopyStart, i - iCopyStart));
sResult.Add(newValue);
iCopyStart = i + oldValue._nLength;
i = std_find(oldValue, i + oldValue._nLength);
}
if(_nLength - iCopyStart > 0)
sResult.Add(SubStr(iCopyStart, _nLength - iCopyStart));
return sResult;
}
/// <summary>
/// 字符串长度
/// </summary>
__declspec(property(get = GetLength)) const int CSharp_Length;
//--------------------------------------------------------------------------------模似Java字符串方法
/// <summary>
///
/// </summary>
/// <param name="nValue"></param>
/// <returns></returns>
/// 创建时间: 2021-10-04 最后一次修改时间:2021-10-04
inline static _Str<T> Java_valueOf(const __int64& iNumber)
{
_Mem<T> m(50);
_Math::intToStr_t<T>(iNumber, m.Pointer, &m.DataLength);
return _Str<T>(m.Pointer, m.DataLength, 0, m.DataLength);
}
//---------------------------------------------------------------------------------模拟Python字符串方法
/// <summary>
/// 实现 Python String::title()
/// 方法title()以首字母大写的方式显示每个单词,即将每个单词的首字母都改为大写,其它改为小写。
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-03-25 最后一次修改时间:2023-03-25
inline _Str<T> Python_title()const
{
_Str<T> sResult = _pData;
bool bBegin = false;
int iStart = -1;
for (int i = 0; i < _nLength; ++i)
{
if (gs.c_IsEnglishLetters(_pData[i]))
{
if (!bBegin)
{
bBegin = true;
iStart = i;
}
}
else
{
if (bBegin)
{
sResult._pData[iStart] = gs.c_ToUpper(_pData[iStart]);
bBegin = false;
}
}
}
//最后一个字符 例 One of Python's 中的 s
if(iStart != -1)
sResult._pData[iStart] = gs.c_ToUpper(_pData[iStart]);
return sResult;
}
//--------------------------------------------------------------------------------------------String扩展
/// <summary>
/// 返回不包含空格的可打印字符
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-02-07 最后一次修改时间:2022-02-07
inline _Str<T> RemoveUnprintableAndWhitespace()const
{
//StringBuilder^ sbReulst = gcnew StringBuilder(sText->Length);
//for each (wchar_t c in sText)
//{
// if (c_IsPrintable(c) && (!c_IsWhiteSpace(c)))
// sbReulst->Append(c);
//}
//return sbReulst->ToString();
_Str<T> sResutl(_t(""),_nLength);
int i = 0;
for(int i = 0; i < _nLength; ++i)
{
_char c = _pData[i];
if (gcf.gcf_isprint(c) && (!gcf.gcf_isblank(c)))
sResutl.Add(c);
}
return sResutl;
}
/// <summary>
/// 返回不包含空格和标点符号的可打印字符
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-02-25 最后一次修改时间:2022-02-25
inline _Str<T> RemovePunctuationAndWhitespace()
{
_Str<T> sResutl(_t(""), _nLength);
for(_char c : *this)
{
if (gcf.gcf_isprint(c) && (! gcf.gcf_isblank(c)) && (! gcf.gcf_IsPunctuation(c)))
sResutl.append(c);
}
return sResutl;
}
/// <summary>
/// 检查是否包含可打印字符
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-01-21 最后一次修改时间:2022-01-21
inline bool IsHavePrintableChar()
{
_char* p = _pData;
while (*p)
{
if (gcf.gcf_isprint(*p)) return true;
++p;
}
return false;
}
/// <summary>
/// 返回清除所有不可打印的字符串的拷贝
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-01-21 最后一次修改时间:2022-01-21
inline _Str<T> CleanUpNnprintable() const
{
_Str<T> sResult(_t(""), _nLength);
_char* pText = (_char*)_pData;
while (*pText)
{
if (gcf.gcf_isprint(*pText))
{
sResult.Add(*pText);
}
++pText;
}
return sResult;
}
/// <summary>
/// 在sText计算有多少个字符串sSub
/// </summary>
/// <param name="sText"></param>
/// <param name="sSub"></param>
/// <returns></returns>
inline int StrCount(const _Str<T>& sSub)
{
int n = 0;
int i = CSharp_IndexOf(sSub);
while (i != -1)
{
n += 1;
i = CSharp_IndexOf(sSub, i + sSub._nLength);
}
return n;
}
/// <summary>
/// 计算有多少个相同的字符
/// </summary>
/// <param name="c"></param>
/// <returns></returns>
inline int StrCount(const _char c)
{
int n = 0;
for (int i = 0; i < _nLength; ++i)
{
if (_pData[i] == c) { ++n; }
}
return n;
}
/// <summary>
/// 在字符串[iFindStart,iFindEnd] 区间内查找字符串第一次出现的位置。
/// </summary>
/// <param name="sFindString">要查找的字符串</param>
/// <param name="iFindStart">查找开始位置</param>
/// <param name="iFindEnd">查找结束位置</param>
/// <param name="bMatchCase">是否大小字匹配</param>
/// <returns>如果找到,返回第一次出现的位置,否则返回-1</returns>
/// 创建时间: 2022-12-11 最后一次修改时间:2022-12-11 已测试(2022-12-11)
int IndexOf(const _Str<T>& sFindString, const int iFindStart, const int iFindEnd, bool bMatchCase = true) const
{
return _Math::StrFindFirst_t<T>(_pData, iFindEnd + 1, sFindString, sFindString._nLength, iFindStart, bMatchCase);
}
/// <summary>
/// 查找字符串第一次出现的位置
/// </summary>
/// <param name="sFindString">要查找的字符串</param>
/// <param name="iFindStart">查找开始处</param>
/// <param name="bMatchCase">是否大小写匹配</param>
/// <returns>找到返回第一次出现的位置,没找到返回-1</returns>
/// 创建时间: 2022-12-06 最后一次修改时间:2022-12-06 已测试(2022-12-06)
int IndexOf(const _Str<T>& sFindString, const int iFindStart = 0, bool bMatchCase = true) const
{
return _Math::strFindFirst_t<T>(_pData, _nLength, sFindString, sFindString._nLength, iFindStart, bMatchCase);
}
/// <summary>
/// 返回右边配对字符的位置
/// </summary>
/// <param name="sText"></param>
/// <param name="nLeftPos"></param>
/// <param name="cLeft"></param>
/// <returns></returns>
/// 创建时间: 2022-12-18 最后一次修改时间:2022-12-18 已测试(2022-12-18)
int IndexOfRightPairChar(const int nLeftPos, const _char cLeft, const _char cRight)const
{
return gs.s_FindRightPairChar_t<T>(_pData, nLeftPos, cLeft, cRight);
}
/// <summary>
/// 查找sFindCharArray任意一个字符在字符串中第一次出现的位置,找到返回位置和找到的字符,找不到第一个结果为-1,第二个为'\0';
/// </summary>
/// <param name="sFindCharArray"></param>
/// <returns></returns>
/// 创建时间: 2022-03-01 最后一次修改时间:2023-03-18 已测试(2023-03-18)
_Pair<int, T> IndexOfAnyChar(const T* sFindCharArray) const
{
_Pair<int, T> lpResult(-1, _t('\0'));
T* pFind = (T*)sFindCharArray;
while (*pFind)
{
int i = 0;
T* pText = (T*)_pData; //重置 pText
while (*pText)
{
if (*pText == *pFind)
{
lpResult.First = i;
lpResult.Second = *pFind;
return lpResult;
}
++pText;
++i;
}
++pFind;
}
return lpResult;
}
/// <summary>
/// 查找sFindCharArray任意一个字符在字符串中最后一次出现的位置,找到返回位置和找到的字符,找不到第一个结果为-1,第二个为'\0';
/// </summary>
/// <param name="sFindCharArray"></param>
/// <returns></returns>
/// 创建时间: 2023-04-22 最后一次修改时间:2023-04-22 已测试(2023-04-22)
_Pair<int, T> LastIndexOfAnyChar(const T* sFindCharArray) const
{
_Pair<int, T> lpResult(-1, _t('\0'));
for (int i = _nLength - 1; i >= 0; --i)
{
if ( _Math::strChr_t<T>(sFindCharArray, _pData[i]) != -1)
{
lpResult.First = i;
lpResult.Second = _pData[i];
return lpResult;
}
}
return lpResult;
}
/// <summary>
/// 查找单个字符
/// </summary>
/// <param name="c"></param>
/// <param name="iFindStart"></param>
/// <param name="bMatchCase"></param>
/// <returns></returns>
/// 创建时间: 2022-12-07 最后一次修改时间:2022-12-07 已测试(2022-12-07)
int IndexOf(const T c, const int iFindStart = 0, bool bMatchCase = true) const
{
return _Math::strFindFirst_t<T>(_pData, _nLength, &c, 1, iFindStart, bMatchCase);
}
/// <summary>
/// 向函数传递一个ch,这个函数参数为_char,返回为bool。
/// </summary>
/// <typeparam name="fun"></typeparam>
/// <param name="iFindStart"></param>
/// <param name="f"></param>
/// <returns></returns>
/// 创建时间: 2024-04-28 最后一次修改时间:2024-04-28 已测试(2024-04-28)
template<class fun>
int IndexIf(fun f, const int& iFindStart = 0)const
{
for (int i = iFindStart; i < _nLength; ++i) {
if (f(_pData[i]))
return i;
}
return -1;
}
/// <summary>
/// 查找第一个不是ch的字符。
/// </summary>
/// <param name="ch"></param>
/// <param name="iFindStart"></param>
/// <returns></returns>
/// 创建时间: 2024-04-28 最后一次修改时间:2024-04-28 已测试(2024-04-28)
int IndexNotOf(const T& ch, const int& iFindStart = 0)const
{
//无法访问ch
//return IndexIf([](const _char& c)->bool { return c != ch; }, iFindStart);
for (int i = iFindStart; i < _nLength; ++i) {
if (_pData[i] != ch)
return i;
}
return -1;
}
int IndexOf(const T c, const int iFindStart, const int iFindEnd, bool bMatchCase = true) const
{
return _Math::strFindFirst_t<T>(_pData, iFindEnd + 1, &c, 1, iFindStart, bMatchCase);
}
/// <summary>
/// 在字符串[iFindStart,iFindEnd] 区间内查找字符串最后一次出现的位置。
/// </summary>
/// <param name="sFindString">要查找的字符串</param>
/// <param name="iFindStart">查找开始位置</param>
/// <param name="iFindEnd">查找结束位置</param>
/// <param name="bMatchCase">是否大小字匹配</param>
/// <returns>如果找到,返回最后一次出现的位置,否则返回-1</returns>
/// 创建时间: 2022-12-11 最后一次修改时间:2022-12-11 已测试(2022-12-11)
int LastIndexOf(const _Str<T>& sFindString, const int iFindStart, const int iFindEnd, bool bMatchCase = true) const
{
return _Math::strFindLast_t<T>(_pData, iFindEnd + 1, sFindString, sFindString._nLength, iFindStart, bMatchCase);
}
/// <summary>
/// 查找最后一次出现的字符串位置
/// </summary>
/// <param name="sFindString">要查找的字符串</param>
/// <param name="iFindStart">查找开始位置</param>
/// <param name="bMatchCase">是否大小配置</param>
/// <returns></returns>
/// 创建时间: 2022-12-07 最后一次修改时间:2022-12-07 已测试(2022-12-07)
int LastIndexOf(const _Str<T> &sFindString, const int iFindStart = 0, bool bMatchCase = true) const
{
return _Math::strFindLast_t<T>(_pData, _nLength, sFindString,sFindString._nLength, iFindStart, bMatchCase);
}
int LastIndexOf(const T c, const int iFindStart, const int iFindEnd, bool bMatchCase = true) const
{
return _Math::strFindLast_t<T>(_pData, iFindEnd + 1, &c, 1, iFindStart, bMatchCase);
}
int LastIndexOf(const T c, const int iFindStart = 0, bool bMatchCase = true) const
{
return _Math::strFindLast_t<T>(_pData, _nLength, &c, 1, iFindStart, bMatchCase);
}
/// <summary>
/// 从某个位置开始查找一个单词,这个单司是第一次出现,找到即返回,区分大小写。
/// </summary>
/// <param name="sText"></param>
/// <param name="sWord"></param>
/// <param name="nFindStart"></param>
/// <returns></returns>
/// 创建时间: 2022-08-08 最后一次修改时间:2022-12-07 已测试(2022-12-07)
int IndexOfWord(const _Str<T>& sWord, int iFindStart = 0, bool bMatchCase = true) const
{
if (_nLength == 0 || sWord._nLength == 0) return -1; // 不加上这名,IndexWord("") 会进入死循环
if (iFindStart <= 0) iFindStart = 0;
if (_nLength - iFindStart < sWord._nLength) return -1;
int nPos = IndexOf(sWord, iFindStart,bMatchCase);
while (nPos != -1)
{
bool bPrev = false;
bool bNext = false;
int nPrev = nPos - 1;
int nNext = nPos + sWord._nLength;
if (nPrev > 0)
{
_char chPrev = _pData[nPrev];
if (gs.s_Syntax_IsWordSeparator(chPrev))
{
bPrev = true;
}
}
else
{
bPrev = true;
}
if (nNext > 0 && nNext < _nLength)
{
_char chNext = _pData[nNext];
if (gs.s_Syntax_IsWordSeparator(chNext))
{
bNext = true;
}
}
else
{
bNext = true;
}
if (bNext && bPrev) return nPos; //正确,是单词
//不正确,继续查找
nPos = IndexOf(sWord, nPos + sWord._nLength,bMatchCase);
}
return nPos;
}
/// <summary>
/// 查找sFind第几次出现的位置
/// </summary>
/// <param name="sFindString">查找内容</param>
/// <param name="nCount">第几个</param>
/// <param name="iFindStart">开始位置</param>
/// <param name="bMatchCase">是否大小写匹配</param>
/// <returns>找到返回第nCount次出现的位置,没找到返回-1</returns>
/// 创建时间: 2022-12-06 最后一次修改时间:2022-12-06 已测试(2022-12-06)
int IndexOf_n(const _Str<T> &sFindString, const int nCount = 1, const int iFindStart = 0, bool bMatchCase = true) const
{
assert(nCount >= 1);
int n = 0;
int iStart = iFindStart;
int i = IndexOf(sFindString, iStart, bMatchCase);
while (i != -1)
{
++ n;
iStart = i + sFindString._nLength;
if (n == nCount) return i;
i = IndexOf(sFindString, iStart, bMatchCase);
}
return i;
}
/// <summary>
/// 截取字符串s1,s2中间的字符串,失败返回空的字符串,s1为第一次出现的字符串。
/// 注意: Intercept_First(s1,s2,false) = Intercept_First(s1,s2,0)
/// </summary>
/// <param name="s1"></param>
/// <param name="s2"></param>
/// <param name="nStart"></param>
/// <param name="bMatchCase"></param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-12-06 已测试(2022-12-06)
_Str<T> Intercept_First(const _Str<T>& s1, const _Str<T> &s2, const int iStart = 0, bool bMatchCase = true) const
{
int ipos1, ipos2;
ipos1 = IndexOf(s1,iStart,bMatchCase);
if (ipos1 == -1) return _t("");
ipos2 = IndexOf(s2, ipos1 + s1._nLength,bMatchCase);
if (ipos2 == -1)
{
return _t("");
}
else
{
return SubStr(ipos1 + s1._nLength, ipos2 - ipos1 - s1._nLength);
}
}
/*
*示例:
String^ str = "深圳市盈基实业有限公司国际通邓事文*深圳市盈基实业有限公司国际通邓事文";
Label1.Text = str.LastIndexOf("邓文").ToString();//返回-1
Label1.Text = str.LastIndexOf("邓").ToString();//返回32
Label1.Text = str.LastIndexOf("邓",8).ToString();//返回-1
Label1.Text = str.LastIndexOf("邓",20).ToString();//返回14
Label1.Text = str.LastIndexOf("邓",33).ToString();//返回32
说明:在指定的范围内查找字符,这个范围是上面的输入的参数,理解为,从索引0开始到指定的数
值位置范围内查找最后一个匹配的的字符串的位置。示例中,0-8中没有“邓”字,所以返回-1,0-20范围
中,有一个“邓”字在索引14位置上,0-33范围中有两个“邓”字,因为LastIndexOf是返回最后一个匹配项索引位置,
所以返32,而不是14。
*/
/// <summary>
/// 截取字符串s1,s2中间的字符串,失败返回空的字符串,s1,s2为均为最后一次出现的索引
/// </summary>
/// <param name="sText">字符串</param>
/// <param name="s1">子串1</param>
/// <param name="s2">子串2</param>
/// <param name="bMatchCase">是否大小写匹配</param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-12-11 已测试
inline _Str<T> Intercept_last(const _Str<T>& s1, const _Str<T>& s2,const int iStart = 0, bool bMatchCase = true)
{
int istart, iend;
//算法: 要先查第二个字符串,然后从第二个字符串向前查找第一个字符串
iend = LastIndexOf(s2, iStart, bMatchCase);
if (iend == -1) return _t("");
istart = LastIndexOf(s1, 0, iend - s2._nLength, bMatchCase);
if (istart == -1)return _t("");
int nInterceptLength = iend - istart - s1._nLength;
int nStartIndex = istart + s1._nLength;
return SubStr(nStartIndex, nInterceptLength);
}
/// <summary>
/// 返回文件名
/// _string s1 = _t("data"); => data
/// _string s2 = _t("data.txt"); => data
/// _string s3 = _t("c:\\data.txt"); => data
/// _string s4 = _t("data.txt.txt"); => data.txt
/// </summary>
/// <param name="sFullPathName"></param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-12-11 已测试
inline _Str<T> FileNameOnly()const
{
int iStart = LastIndexOf(_t('\\'));
int iEnd = LastIndexOf(_t('.'));
if (iStart == -1)
{
if (iEnd != -1)
{
if (iEnd > 0)
return SubStr(0, iEnd);
}
}
else
{
if (iEnd != -1)
{
if(iEnd - iStart - 1 > 0)
return SubStr(iStart + 1, iEnd - iStart - 1);
}
}
return *this;
}
/// <summary>
/// 返回文件名,包括扩展名
/// _string s1 = _t("data"); => data
/// _string s2 = _t("data.txt"); => data.txt
/// _string s3 = _t("c:\\data.txt"); => data.txt
/// _string s4 = _t("data.txt.txt"); => data.txt.txt
/// </summary>
/// <param name="sFullPathName"></param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-12-11 已测试
inline _Str<T> FileName() const
{
int iStart = LastIndexOf(_t('\\'));
if (iStart != -1)
{
if( _nLength - iStart - 1 > 0)
return SubStr(iStart + 1, _nLength - iStart -1);
}
return *this;
}
/// <summary>
/// Z:\Temp\迅雷下载\jtds-1.2.7-dist\CHANGELOG //没有文件扩展名的文件
/// _string s1 = _t("data"); =>
/// _string s2 = _t("data.txt"); => txt
/// _string s3 = _t("c:\\data.txt"); => txt
/// _string s4 = _t("data.txt.txt"); => txt
/// </summary>
/// <param name="sFileName">带扩展名的文件名</param>
/// <returns></returns>
/// 获取文件扩展名(创建时间:2014-06-13 最后一次修改时间:2020-01-11) 已测试
inline _Str<T> FileNameExt()const
{
//Z:\Temp\迅雷下载\jtds-1.2.7-dist\CHANGELOG
int n = LastIndexOf(_t("."));
if (n != -1)
{
if(_nLength - n - 1 > 0)
return SubStr(n + 1, _nLength - n - 1);
}
return _t("");
}
/// <summary>
/// 返回文件夹目录
/// </summary>
/// <returns></returns>
inline _Str<T> FileDir()const
{
int n = LastIndexOf(_t("\\"));
return n != -1 ? std_substr(0, n) : _t("");
}
/// <summary>
/// 返回文件路径,包括 反斜杠"\\",如果没有,就返回空。
/// C:\\data.txt => C:\\
/// </summary>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-12-11 已测试
inline _Str<T> FileNamePath() const
{
int n = LastIndexOf(_t('\\'));
return (n != -1 ? SubStr(0, n + 1) : _Str<T>());
}
/// <summary>
/// 把路径中的文件名用sNewName替代
/// </summary>
/// <param name="sNewFileName">新文件名</param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-12-11 已测试
inline _Str<T> FileNameReplace(const _Str<T>& sNewFileName)
{
//return FileNamePath() + sNewFileName + _t(".") + FileNameExt();
_Str<T> sResult(_t(""), _nLength + sNewFileName._nLength);
sResult.Add(FileNamePath());
sResult.Add(sNewFileName);
sResult.Add(_t('.'));
sResult.Add(FileNameExt());
return sResult;
}
/// <summary>
///C:\Program Files\Common Files\Oracle\Java\javapath\java.exe 返回 javapath
///C:\Program Files\Common Files\Oracle\Java\javapath 返回 Java
///C:\Program Files\Common Files\Oracle\Java\javapath\ 返回 javapath
///C: 返回 C:
/// 返回最后一个文件夹名
/// </summary>
/// <param name="sFullPathName"></param>
/// <param name="IsDirectoryPath">此路径是否文件夹名</param>
/// <returns></returns>
/// 创建时间: 2021-10-09 最后一次修改时间:2022-12-11 已测试
inline _Str<T> FileDirectoryNameOnly()
{
int n1 = LastIndexOf(_t('\\'));
if (n1 != -1)
{
int n2 = LastIndexOf(_t('\\'), 0,n1 - 1);
if (n2 != -1)
{
return SubStr(n2 + 1, n1 - n2 -1);
}
else
{
return SubStr(0, n1 - 1);
}
}
return *this;
}
/// <summary>
/// 把字符串翻转
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-12-11 已测试
inline _Str<T>& Reversal()
{
_Math::reverse<T>(_pData, _nLength);
return *this;
}
/// <summary>
/// 获取以nIndex为中心的单词或者词语,以左边光标为准。
/// </summary>
/// <param name="sText"></param>
/// <param name="nMiddleIndex">中间字符在文本中的索引</param>
/// <returns></returns>
/// 创建时间:2022-12-12 最后一次修改时间:2022-12-12 (已测试)
inline _Str<T> GetWord(int nMiddleIndex) const
{
if (_nLength == 0 || nMiddleIndex < 1 || nMiddleIndex >= _nLength) return _t("");
_char cLeft = _pData[nMiddleIndex - 1];
_Str<T> sLeft(_t(""), 20);
_Str<T> sRight(_t(""), 20);
if(gs.c_IsChineseCharacter(cLeft)) //光标左边的字符是英文
{
for (int i = nMiddleIndex - 1; i >= 0; --i)
{
_char c = _pData[i];
if (gs.s_Syntax_IsWordSeparator(c))
{
break;
}
else
{
if (!gs.c_IsChineseCharacter(c))
{
break;
}
else
{
sLeft.Add(c);
}
}
}
for (int i = nMiddleIndex; i < _nLength; ++i)
{
_char c = _pData[i];
if (gs.s_Syntax_IsWordSeparator(c))
{
break;
}
else
{
if (!gs.c_IsChineseCharacter(c))
{
break;
}
else
{
sRight.Add(_pData[i]);
}
}
}
}
else
{
for (int i = nMiddleIndex - 1; i >= 0; --i)
{
_char c = _pData[i];
if (gs.s_Syntax_IsWordSeparator(c))
{
break;
}
else
{
if (!gs.c_IsAscii(c))
{
break;
}
else
{
sLeft.Add(_pData[i]);
}
}
}
for (int i = nMiddleIndex; i < _nLength; ++i)
{
_char c = _pData[i];
if (gs.s_Syntax_IsWordSeparator(c))
{
break;
}
else
{
if (!gs.c_IsAscii(c))
{
break;
}
else
{
sRight.Add(_pData[i]);
}
}
}
}
return sLeft.Reversal() + sRight;
}
/// <summary>
/// 根据字符位置,返回行号,从0开始的索引。
/// </summary>
/// <param name="nPos"></param>
/// <returns></returns>
/// 创建时间:2022-12-21 最后一次修改时间: 2022-12-21 (已测试)
inline int GetLineIndexForCharIndex(const int nPos)const
{
int nLineCount = 0;
for (int i = 0; i <= nPos; ++i)
{
if (_pData[i] == '\n')
{
++nLineCount;
}
}
return nLineCount;
}
/// <summary>
///
/// </summary>
/// <param name="nPos"></param>
/// <returns></returns>
/// 创建时间:2022-12-28 最后一次修改时间: 2022-12-28
inline _Str<T> GetLineForCharIndex(const int nPos)const
{
int j = nPos,k = nPos + 1;
while (j > 0)
{
if (_pData[j] == _t('\n'))
{
break;
}
--j;
}
while (k < _nLength)
{
if (_pData[k] == _t('\n'))
{
break;
}
++k;
}
if ( k < _nLength && k -j - 1 > 0)
{
return SubStr(j + 1, k - j - 1);
}
else
{
return _t("");
}
}
/// <summary>
/// 是否邮件地址
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间:2022-01-20 最后一次修改时间:2022-01-20
inline bool IsEmailAddress()const { return gs.s_IsEmailAddress(_pData); }
/// <summary>
/// 判断字符串是否全部是空格或者是控制字符。
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-03-01 最后一次修改时间:2022-03-01
inline bool IsWhiteSpaceOrNotPrintable() const { return gs.s_IsWhiteSpaceOrNotPrintable(_pData); }
/// <summary>
/// 查找除空格以外第一次出现的可打印字符,sExcept字符除外。
/// </summary>
/// <param name="sText"></param>
/// <param name="sExcept"></param>
/// <returns></returns>
/// 创建时间: 2022-03-01 最后一次修改时间:2022-03-01
inline int FindFirstPrintable(const _char* sExcept = _t("")) const { return gs.s_FindFirstPrintable(_pData, sExcept); }
/// <summary>
/// 查找除空格以外最后一次出现的可打印字符,sExcept字符除外。
/// </summary>
/// <param name="sText">文本</param>
/// <param name="sExcept">例外字符</param>
/// <returns></returns>
/// 创建时间: 2022-04-09 最后一次修改时间:2022-04-09
inline int FindLastPrintable(const _char* sExcept = _t("")) const { return gs.s_FindLastPrintable(_pData, _nLength, sExcept); }
/// <summary>
/// 返回可打印的字符
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-02-07 最后一次修改时间:2022-02-07
inline _Str<T> PrintableCharacter()const
{
_Str<T> sResult(_t(""), _nLength);
for (int i = 0; i < _nLength; ++i)
{
_char c = _pData[i];
if (gcf.gcf_isprint(c))
sResult.Add(c);
}
return sResult;
}
/// <summary>
/// 拷贝字符串前面的控制字符和空格,遇到其它可见字符马上停止。
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-03-27 最后一次修改时间:2022-03-27
inline _Str<T> CopyControlAndWhiteSpace()const
{
_Str<T> sResult(_t(""), _nLength);
for (int i = 0; i < _nLength; ++i)
{
_char c = _pData[i];
if (gcf.gcf_IsControl(c) || gcf.gcf_isblank(c))
{
sResult.Add(c);
}
else
{
break;
}
}
return sResult;
}
/// <summary>
/// 判断是否序号标记,注意,最后一个字符必须是 "." 英文句号,注意,序号前面的空格和不可打印字符也会复制。
/// 1. ab 返回:1.
/// 1. ab 返回: 1.
/// 序号定义:
/// (1)如果句号不在最后,则句号后面一定是空格
/// (2) 句号前面是连续的数字,且数字前面可以有空格或者不可打印字符
///
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间:2022-03-06 最后一次修改时间:2022-10-03
inline _Str<T> GetBook_序号标记()const
{
//1.
// 1.
// 11.
//4.24 class aa
// 1.2. 1. text ok
//
int nPos = LastIndexOf(_t(". "));
if (nPos != -1)
{
_Str<T> sLeft = SubStr(0, nPos);
bool bFind = false;
for(_char c : sLeft)
{
if ( gcf.gcf_isdigit(c) || gcf.gcf_isalpha(c) || gcf.gcf_IsControl(c) || gcf.gcf_isblank(c) || c == _t('.'))
{
}
else
{
bFind = true;
}
}
if (!bFind)
{
return sLeft + _t(". ");
}
}
return GetBook_序号标记2();
}
/// <summary>
/// (1) 或 (1)
/// (2) 或 (2)
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间:2022-10-01 最后一次修改时间:2022-10-01
inline _Str<T> GetBook_序号标记2()const
{
int nPos = IndexOf(_t(")")); //英文括号
if (nPos == -1)
nPos = IndexOf(_t(")")); //中文括号
if (nPos == -1) return _t("");
_Str<T> sSub = SubStr(0, nPos + 1);
for(_char c : sSub)
{
if (gcf.gcf_isdigit(c) || gcf.gcf_IsControl(c) || c == _t('(') || c == _t(')') || c == _t('(') || c == _t(')'))
{
//如果要严谨一些,还要判断括号是否配对
}
else
{
return _t("");
}
}
return sSub + _t(" ");
}
/// <summary>
/// 格式 特殊符号 ch + 空格
///
/// □ 为新的对象分配内存空间;
/// □ 调用构造函数初始化对象的值
/// □ 返回该对象的一个引用。
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
inline _Str<T> GetBook_特殊符号标记(const _Str<T>& sSpecificSymbol)const
{
int n = -1;
for(_char c : sSpecificSymbol)
{
n = IndexOf(c);
if (n != -1)
{
break;
}
}
if (n == -1) return _t("");
if (n + 1 >= _nLength) return _t("");
if (_pData[n + 1] != _t(' ')) return _t("");
_Str<T> sSub = SubStr(0, n);
if (sSub._nLength > 0)
{
if ( !sSub.IsWhiteSpaceOrNotPrintable() ) return _t("");
}
else //序号前面没有字符
{
}
return SubStr(0, n + 2);
}
/// <summary>
/// 检查字符串中是否有阿拉伯数字,如果有,返回直,否则返回假。
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: ????-??-?? 最后一次修改时间:2023-31-19
inline bool IsHaveArabicDigit()const
{
for (int i = 0; i < _nLength; ++i)
{
if (gcf.gcf_isdigit(_pData[i])) return true;
}
return false;
}
/// <summary>
/// 返回所有的数字
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-02-18 最后一次修改时间:2023-31-19
inline _Str<T> GetAllArabicDigit()const
{
_Str<T> sResult;
sResult.SetBuffer(_nLength);
for (int i = 0; i < _nLength; ++i)
{
T c = _pData[i];
if (gcf.gcf_isdigit(c))
{
sResult.Add(c);
}
}
return sResult;
}
/// <summary>
/// 返回所有不可打印的字符串
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-01-21 最后一次修改时间:2022-12-13
inline _Str<T> Unprintable()const
{
_Str<T> sResult(_t(""), _nLength);
for (int i = 0; i < _nLength; ++i)
{
_char c = _pData[i];
if ( !gcf.gcf_isprint(c) ) sResult.Add(c);
}
return sResult;
}
/// <summary>
/// 截取字符串前面的数字和小数点,遇到空格忽略,遇到小数点,数字,空格外的任何字停止截取。
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间:2021-12-27 最后一次修改时间:2021-12-27
inline _Str<T> Intercept_Head_number_RadixPoint_Space()const
{
_Str<T> sResult(_t(""), _nLength);
for(int i = 0; i < _nLength; ++i)
{
_char c = _pData[i];
if (c == _t(' '))
{
}
else if (c >= _t('0') && c <= _t('9'))
{
sResult.Add(c);
}
else if (c == _t('.'))
{
sResult.Add(_t('.'));
}
else
{
break;
}
}
return sResult;
}
/// <summary>
/// 返回: 如果nOrder=1,返回倒数第一位数字;如果nOrder=2,返回倒数第二位数字。
/// </summary>
/// <param name="sText"></param>
/// <param name="nOrder"></param>
/// <returns></returns>
/// 创建时间:2021-12-27 最后一次修改时间:2021-12-27
inline int LastNumberIndex(int nLastOrder = 1)const { return gs.s_LastNumberIndex(_pData, _nLength, nLastOrder); }
/// <summary>
/// 把字符串的最后第nOrder数字加1,如果最后第nOrder数字是9,则进一位,最后第nOrder+1数字再加1,如此循环,
/// 但如果第nOrder+1找不到,则结束循环。
/// </summary>
/// <param name="sText"></param>
/// <param name="nOrder">倒数第oOrder序列</param>
/// <returns></returns>
/// 创建时间:2021-12-27 最后一次修改时间:2022-03-06
inline _Str<T> TryNumberAddOne(const int nLastOrder = 1)const
{
if (nLastOrder <= 0) return *this;
_Str<T> sResult(_pData, 1);
int i = LastNumberIndex(nLastOrder);
if (i != -1)
{
if (_pData[i] == _t('9'))
{
sResult[i] = _t('0');
//如果9前面有数字
if (SubStr(0,i).IsHaveNumber())
return sResult.TryNumberAddOne(nLastOrder + 1);
else
{
return _t("1") + sResult;
}
}
else
{
sResult[i] = (_char)( (int)_pData[i] + 1);
return sResult;
}
}
return sResult;
}
/// <summary>
/// 把字符串的数字或者字母加一位,其它非数字或者字母忽略,例: a1 -> a2 , 1ab -> 1ac 19 -> 20, 99-> 100
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间:2022-09-11 最后一次修改时间:2022-09-11
inline _Str<T> TryStrAndOne()const
{
if (_nLength == 0 ) return _t("1");
int nLast = _nLength - 1;
_char c = _pData[nLast];
if (gcf.gcf_isdigit(c))
{
if (c != _t('9'))
{
return SubStr(0, nLast).Add((_char)((int)c + 1)); // 1->2
}
else //进位,前面字符加1
{
return SubStr(0, nLast).TryStrAndOne().Add(_t("0"));
}
}
else if (gcf.gcf_isalpha(c))
{
if (c != _t('z') && c != _t('Z') )
{
return SubStr(0, nLast).Add((_char)((int)c + 1));
}
else //进位,前面字符加1
{
if (c == _t('z'))
return SubStr(0, nLast).TryStrAndOne().Add(_t('a'));
else
return SubStr(0, nLast).TryStrAndOne().Add(_t('Z'));
}
}
else
{
return SubStr(0, nLast).TryStrAndOne().Add(c);
}
}
/// <summary>
/// 把字符串中的数字连起来,凑成整数,然后给这个数字减去1,再返回减去1的字符串。
/// 例如:
/// 1.3.9 小节 => 1.3.8 小节
/// 9.9.9 小节 => 9.9.8 小节
/// 0.0.0 小节 => 9.9.9 小节
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-02-11 最后一次修改时间:2022-05-25
inline _Str<T> TryNumberMinusOne()
{
_Str<T> sResult(_pData, 1);
bool bFind = false;
_char* p = (_char*)sResult._pData;
for (int i = sResult._nLength - 1; i >= 0; i--)
{
if (p[i] >= _t('0') && p[i] <= _t('9') )
{
if (!bFind)
{
if (p[i] != _t('0'))
{
p[i] = (_char)((int)p[i] - 1);
return sResult;
}
else
{
p[i] = _t('9');
}
bFind = true;
}
else
{
if (p[i] != _t('0'))
{
p[i] = (_char)((int)p[i] - 1);
return sResult;
}
else
{
p[i] = _t('9');
}
}
}
}
return sResult;
}
/// <summary>
/// 添加nCount个相同的字符sAppend。
/// </summary>
/// <param name="sText"></param>
/// <param name="sAppend"></param>
/// <param name="nCount"></param>
/// <returns></returns>
inline _Str<T>& AppendString(const _Str<T>& sAppend, int nCount)
{
if (nCount > 0)
{
SetBuffer(sAppend._nLength * nCount + _nDefaultBuffer);
for (int i = 0; i < nCount; ++i)
{
Add(sAppend);
}
}
return *this;
}
/// <summary>
/// 返回用cSplit隔开的字符串。
/// </summary>
/// <param name="sText"></param>
/// <param name="cSplit"></param>
/// <returns></returns>
/// 创建时间: 2021-11-08 最后一次修改时间:2021-11-08
inline _Str<T> SeparateWith(const _char cSplit) const
{
if (_nLength < 2) return *this;
_Str<T> sResult(_t(""), _nLength * 2);
for (int i = 0; i < _nLength - 1; ++i)
{
sResult.Add(_pData[i]);
sResult.Add(cSplit);
}
sResult.Add(_pData[_nLength - 1]);
return sResult;
}
/// <summary>
/// 所截取字符串的信息
/// </summary>
struct Intercept_info
{
/// <summary>
/// 所截取的文本
/// </summary>
_Str<T> sIntercept = _t("");
/// <summary>
/// 第一个字符串开始出现的位置
/// </summary>
int iFindStart = -1;
/// <summary>
/// 第二个字符串开始出现的位置
/// </summary>
int iFindEnd = -1;
/// <summary>
/// 所截取的文本字符串开始处
/// </summary>
int iTextStart = -1;
/// <summary>
/// 所截击的文本结束处
/// </summary>
int iTextEnd = -1;
};
/// <summary>
/// 截取字符串s1,s2中间的字符串,失败返回空的字符串。
/// </summary>
/// <param name="s1">第一次出现的字符串s1</param>
/// <param name="s2">第一次出现的字符串s2</param>
/// <param name="iStart">开始位置</param>
/// <param name="bMatchCase">是否区大小写</param>
/// <returns>如果成功,返回所截取的字符串,否则返回空</returns>
/// 创建时间: ????-????-???? 最后一次修改时间:2022-08-26
Intercept_info Intercept(const _Str<T>& s1, const _Str<T>& s2, const int iStart = 0, bool bMatchCase = true) const
{
Intercept_info iInfo;
iInfo.iFindStart = -1;
iInfo.iFindEnd = -1;
iInfo.iTextStart = -1;
iInfo.iTextEnd = -1;
iInfo.sIntercept = _t("");
iInfo.iFindStart = IndexOf(s1, iStart, bMatchCase);
if (iInfo.iFindStart == -1)
{
return iInfo;
}
iInfo.iFindEnd = IndexOf(s2, iInfo.iFindStart + s1._nLength, bMatchCase);
if (iInfo.iFindEnd != -1)
{
iInfo.iTextStart = iInfo.iFindStart + s1._nLength;
iInfo.iTextEnd = iInfo.iFindEnd - s2._nLength - 1;
iInfo.sIntercept = SubStr(iInfo.iFindStart + s1._nLength, iInfo.iFindEnd - iInfo.iFindStart - s1._nLength);
}
return iInfo;
}
/// <summary>
/// 检查字符串是否全都是阿拉伯数字,如果是,则返回真,否则返回假。
/// </summary>
/// <returns>如查全是数字,返回真</returns>
inline bool IsAllArabicDigitString() const
{
if( _nLength == 0) return false;
for (int i = 0; i < _nLength; ++i)
{
_char c = _pData[i];
if (c < _t('0') || c > _t('9')) return false;
}
return true;
}
/// <summary>
/// 检查字符串是否数字
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-05-22 最后一次修改时间:2023-05-22
inline bool IsNumber() const
{
if (_nLength == 0) return false;
int n = StrCount(_t('.'));
if (n > 1) return false;
if (n == 0)
{
int iStart = 0;
if (_pData[0] == _t('-') || _pData[0] == _t('+'))
{
iStart = 1;
}
for (int i = iStart; i < _nLength; ++i)
{
_char c = _pData[i];
if (c < _t('0') || c > _t('9')) return false;
}
}
else
{
int iStart = 0;
if (_pData[0] == _t('-') || _pData[0] == _t('+'))
{
iStart = 1;
}
for (int i = iStart; i < _nLength; ++i)
{
_char c = _pData[i];
if (c != _t('.'))
{
if (c < _t('0') || c > _t('9')) return false;
}
}
}
return true;
}
/// <summary>
/// 是否整数字符串
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-05-22 最后一次修改时间:2023-05-22
inline bool IsIntNumber() const
{
if (_nLength == 0) return false;
int iStart = 0;
if (_pData[0] == _t('-') || _pData[0] == _t('+'))
{
iStart = 1;
}
for (int i = iStart; i < _nLength; ++i)
{
_char c = _pData[i];
if (c < _t('0') || c > _t('9')) return false;
}
return true;
}
/// <summary>
/// 是否浮点数字符串
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-05-22 最后一次修改时间:2023-05-22
inline bool IsDoubleNumber() const
{
if (_nLength == 0) return false;
int n = StrCount(_t('.'));
if (n != 1) return false;
int iStart = 0;
if (_pData[0] == _t('-') || _pData[0] == _t('+'))
{
iStart = 1;
}
for (int i = iStart; i < _nLength; ++i)
{
_char c = _pData[i];
if (c != _t('.'))
{
if (c < _t('0') || c > _t('9')) return false;
}
}
return true;
}
/// <summary>
/// 检查字符串是否数字,包括中文大写数字和中文小写数字
/// </summary>
/// 创建时间: 2023-03-19 最后一次修改时间:2023-03-19 已测试(2023-03-19)
inline bool IsNumberString()const
{
bool bOk = true;
for (int i = 0; i < _nLength; ++i)
{
if (!gs.c_IsChineseLowerCaseDigit(_pData[i]))
{
bOk = false;
break;
}
}
if (bOk) return true; //全是中文小写
bOk = true;
for (int i = 0; i < _nLength; ++i)
{
if (!gs.c_IsChineseUpperCaseDigit(_pData[i]))
{
bOk = false;
break;
}
}
if (bOk) return true; //全是中文d大写
bOk = true;
for (int i = 0; i < _nLength; ++i)
{
if (!gs.c_IsArabicDigit(_pData[i]))
{
bOk = false;
break;
}
}
if (bOk) return true; //全是阿们伯数字
return false;
}
/// <summary>
/// 在sText中的字符是否都能在CharElementsCollection中找到,如果是,返回真。
/// </summary>
/// <param name="sText"></param>
/// <param name="CharElementsCollection"></param>
/// <returns></returns>
/// 创建时间: 2022-04-06 最后一次修改时间:2022-12-07 已测试(2022-12-06)
inline bool IsElementsCollection(const _char *CharElementsCollection, bool bMatchCase = true) const
{
if (CharElementsCollection == null) return false;
_char* p = (_char*)CharElementsCollection;
int i = -1;
while (*p)
{
i = IndexOf(*p,0,bMatchCase);
if (i == -1) return false;
++p;
}
return i != -1;
}
/// <summary>
/// 是否全是控制字符
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-09-17 最后一次修改时间:2022-09-17
inline bool IsAllControl() const
{
if (_nLength == 0) return false;
for(int i = 0; i < _nLength; ++i)
{
if (!gcf.gcf_iscntrl(_pData[i])) return false;
}
return true;
}
/// <summary>
/// 检查是否存在任何字符
/// </summary>
/// <param name="sAny"></param>
/// <returns></returns>
/// 创建时间: 2022-12-30 最后一次修改时间:2022-12-30
inline bool IsHaveAnyChar(const _char* sAny)const
{
_char* p = (_char*)sAny;
while (*p)
{
if (IndexOf(*p) != -1)
{
return true;
}
++p;
}
return false;
}
/// <summary>
/// 检查是否有中文字符
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-02-08 最后一次修改时间:2023-02-08
inline bool IsHaveChineseCharacter()const
{
for (int i = 0; i < _nLength; ++i)
{
if (gs.c_IsChineseCharacter(_pData[i]))
{
return true;
}
}
return false;
}
/// <summary>
/// 是否错误的文件名
/// </summary>
/// <returns></returns>
/// 创建时间: 2022-12-30 最后一次修改时间:2022-12-30
bool IsInvalidPathName()const
{
return ( IsHaveAnyChar(gs.InvalidPathChars) || _nLength > 260 );
}
/// <summary>
/// 是否全是小写英文字母
/// </summary>
/// <returns></returns>
/// 创建时间: 2022-12-20 最后一次修改时间:2022-12-20
inline bool IsAllLowerCaseEnglishLetter()const
{
if (_nLength == 0) return false;
for (int i = 0; i < _nLength; ++i)
{
if ( _pData[i] < _t('a') || _pData[i] > _t('z') ) return false;
}
return true;
}
/// <summary>
/// 返回所有的控制字符的拷贝
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-09-17 最后一次修改时间:2022-09-17
inline _Str<T> CopyControl() const
{
_Str<T> sResult(_t(""), _nLength);
for (int i = 0; i < _nLength; ++i)
{
if (gcf.gcf_iscntrl(_pData[i])) sResult.Add(_pData[i]);
}
return sResult;
}
/// <summary>
/// 返回不包含空格和控制字符的可打印字符
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2022-02-07 最后一次修改时间:2022-02-07
inline _Str<T> RemoveWCPrintable() const
{
_Str<T> sResult(_t(""), _nLength);
for (int i = 0; i < _nLength; ++i)
{
if ( gcf.gcf_isprint(_pData[i]) && (!gcf.gcf_iscntrl(_pData[i])) && (!gcf.gcf_isspace(_pData[i])) )
{
sResult.Add(_pData[i]);
}
}
return sResult;
}
/// <summary>
/// 返回每一个字符都用cSplit隔开的字符串。
/// </summary>
/// <param name="cSplit">分隔符</param>
/// <returns></returns>
/// 创建时间: 2021-11-08 最后一次修改时间:2022-12-08
inline _Str<T> ConnectForSplit(const _char cSplit) const
{
if (_nLength <= 1) return *this;
_Str<T> sResult(_t(""), _nLength * 2);
for (int i = 0; i < _nLength - 1; ++i)
{
sResult.Add(_pData[i]);
sResult.Add(cSplit);
}
sResult.Add(last());
return sResult;
}
/// <summary>
/// 返回每一个字符都用sSplit隔开的字符串的拷贝
/// </summary>
/// <param name="cSplit">分隔符</param>
/// <returns></returns>
/// 创建时间: 2021-11-08 最后一次修改时间:2022-12-08
inline _Str<T> ConnectForSplit(const _char *sSplit) const
{
assert(sSplit != null && *sSplit != 0);
if (_nLength <= 1) return *this;
int n = _Math::strLen_t<T>(sSplit);
_Str<T> sResult(_t(""), _nLength + _nLength * n);
for (int i = 0; i < _nLength - 1; ++i)
{
sResult.Add(_pData[i]);
sResult.Add(sSplit,n);
}
sResult.Add(last());
return sResult;
}
/// <summary>
/// 返回每隔nCount个字符以cSplitChar分隔的字符串的拷贝
/// </summary>
/// <param name="cSplitChar">分隔字符</param>
/// <param name="nCount"></param>
/// <returns></returns>
/// 创建时间: 2023-02-25 最后一次修改时间:2023-02-25
inline _Str<T> ConnectForSplit(const T cSplitChar, const int nCount) const
{
assert(cSplitChar != 0 && nCount > 0);
_Str<T> sResult(_t(""), _nLength * 2);
for (int i = 0; i < _nLength; ++i)
{
sResult.Add(_pData[i]);
if ( (i + 1) % nCount == 0)
{
if( i + 1 != _nLength)
sResult.Add(cSplitChar);
}
}
return sResult;
}
/// <summary>
/// 返回用charArray中的每一个字符分割的数组
/// </summary>
/// <param name="charArray"></param>
/// <returns></returns>
/// 创建时间: 2023-05-13 最后一次修改时间:2023-05-13 (已测试)
inline _Array<_Str<T>> SplitEveryChar(const T* charArray, bool bIgnoreEmptyString = false)const
{
_Array<_Str<T>> arrResult;
_Str<T> tmp;
for (int i = 0; i < _nLength; ++i)
{
if (_Math::strChr_t<T>(charArray, _pData[i]) == -1)
{
tmp.Add(_pData[i]);
}
else
{
if (tmp.Length == 0)
{
if (!bIgnoreEmptyString)
{
arrResult.Add(tmp);
}
}
else
{
arrResult.Add(tmp);
}
tmp.Clear();
}
}
if (_nLength > 0) //添加最后一个
{
if (tmp.Length == 0)
{
if (!bIgnoreEmptyString)
{
arrResult.Add(tmp);
}
}
else
{
arrResult.Add(tmp);
}
}
return arrResult;
}
/// <summary>
/// 返回除ASCII以外的的字符。
/// </summary>
/// <param name="sText"></param>
/// <returns></returns>
/// 创建时间: 2021-12-25 最后一次修改时间:2021-12-25
inline _Str<T> RemoveASCII() const
{
if (_nLength <= 1) return *this;
_Str<T> sResult(_t(""), _nLength);
for (int i = 0; i < _nLength; ++i)
{
if(!gcf.gcf_isascii(_pData[i])) sResult.Add(_pData[i]);
}
return sResult;
}
/// <summary>
/// 返回除去 nStart 到 nEnd 的一段,包括 nStart 和 nEnd 字符的拷贝,原字符串不变。
/// </summary>
/// <param name="nStart"></param>
/// <param name="nEnd"></param>
/// <returns></returns>
/// 创建时间: 2023-02-15 最后一次修改时间:2023-02-15 (已测试)
inline _Str<T> Remove(const int nStart, const int nEnd) const
{
assert(nStart >= 0 && nEnd >= 0 && nEnd >= nStart);
_Str<T> sResult;
sResult.SetBuffer(_nLength);
//拷贝前半部分
sResult.Add(_pData, nStart);
//拷贝后半部分
sResult.Add(_pData + nEnd + 1, _nLength - nEnd - 1);
return sResult;
}
/// <summary>
/// 近回把字符串区间 [nReplaceStart ,nReplaceEnd] 用 sNewString 代替的拷贝,原字符串不变。
/// </summary>
/// <param name="nReplaceStart"></param>
/// <param name="nReplaceEnd"></param>
/// <param name="sNewString"></param>
/// <returns></returns>
/// 创建时间: 2023-02-21 最后一次修改时间:2023-02-21 (已测试)
inline _Str<T> Replace(const int nReplaceStart, const int nReplaceEnd, const _Str<T>& sNewString)
{
assert(nReplaceStart >= 0 && nReplaceEnd >= 0 && nReplaceEnd >= nReplaceStart && nReplaceStart < _nLength &&nReplaceEnd < _nLength);
_Str<T> sResult;
sResult.SetBuffer(_nLength + sNewString._nLength);
int n = 0;
//拷贝前半部分
sResult.Add(_pData, nReplaceStart);
sResult.Add(sNewString);
//拷贝后半部分
sResult.Add(_pData + nReplaceEnd + 1, _nLength - nReplaceEnd - 1);
return sResult;
}
/// <summary>
/// 返回一个把旧的字符串用新的字符串代替的拷贝。
/// </summary>
/// <param name="sOld"></param>
/// <param name="sNewStr"></param>
/// <returns></returns>
/// 创建时间: 2023-05-10 最后一次修改时间:2023-05-11 (已测试)
inline _Str<T> ReplaceAll(const _Str<T>& sOld, const _Str<T>& sNew)const
{
if (sOld.Length == 0) return *this; //返回拷贝
int i = this->IndexOf(sOld);
if( i == -1) return *this; //返回拷贝
_Str<T> sResult(_t(""), _nLength);
int j = 0;
while (i != -1)
{
sResult.Add(SubStr(j, i - j));
sResult.Add(sNew);
j = i + sOld.Length;
i = IndexOf(sOld, j);
}
//拷贝最后一段
if (j < _nLength)
{
sResult.Add(SubStr(j, _nLength - j));
}
return sResult;
}
/// <summary>
/// 返回一个把旧的字符串用新的字符串代替的拷贝。
/// </summary>
/// <param name="arrOld"></param>
/// <param name="arrNew"></param>
/// <returns></returns>
/// 创建时间: 2023-05-11 最后一次修改时间:2023-05-11 (已测试)
inline _Str<T> ReplaceAll(const _Array<_Str<T>>& arrOld, const const _Array<_Str<T>>& arrNew)const
{
assert(arrOld.Length == arrNew.Length);
_string sResult = *this;
for (int i = 0; i < arrOld.Length; ++i)
{
sResult = sResult.ReplaceAll(arrOld[i], arrNew[i]);
}
return sResult;
}
/// <summary>
/// 返回不包含sCharArray的所有字符的文本的拷贝
/// </summary>
/// <param name="sText"></param>
/// <param name="sCharArray"></param>
/// <returns></returns>
/// 创建时间: 2021-12-25 最后一次修改时间:2021-12-25
inline _Str<T> RemoveCharArray(const T* pCharArray)const
{
_Str<T> sResult((T*)null, _nLength);
for (int i = 0; i < _nLength; ++i) {
if (_Math::strChr_t<T>(pCharArray, _pData[i]) == -1) {
sResult.Add(_pData[i]);
}
}
return sResult;
}
/// <summary>
/// 返回除去tChar的字符串
/// </summary>
/// <param name="tChar"></param>
/// <returns></returns>
/// 创建时间: 2023-05-04 最后一次修改时间:2023-05-04
inline _Str<T> RemoveChar(const T& tChar)const
{
_Str<T> sResult((T*)null, _nLength);
for (int i = 0; i < _nLength; ++i) {
if(_pData[i] != tChar)
sResult.Add(_pData[i]);
}
return sResult;
}
/// <summary>
/// 每隔nCount字符用分隔符cSplit进行分组。
/// </summary>
/// <param name="sText"></param>
/// <param name="nCount"></param>
/// <param name="cSplit"></param>
/// <returns></returns>
/// 创建时间: 2021-11-13 最后一次修改时间:2022-12-08
inline _Str<T> DivideIntoGroups(const int nCount, const _char cSplit) const
{
assert(cSplit != 0);
int n = _nLength / nCount;
if (n <= 1) return *this;
_Str<T> sResult(null, _nLength + nCount * 2);
for (int i = 0; i < n - 1; ++i)
{
sResult.Add(SubStr(nCount * i, nCount));
sResult.Add(cSplit);
}
//拷贝剩下的
sResult.Add(SubStr(nCount * (n - 1), _nLength - nCount * (n - 1)));
return sResult;
}
/// <summary>
/// 放弃对象当前使用的内存,可能内存已托管给别的对象,
/// 重新初始化当前对象,除非内存给其它对象托管,否则不要调用这个函数。
/// </summary>
/// 创建时间:2022-12-29 最后一次修改时间:2022-12-29
inline void GiveUpMem()
{
this->InitData(0);
}
/// <summary>
/// 托管其他对象的内存,在 pData中,要有一个以零为值的 T 数据。
/// </summary>
/// <param name="pMemory"></param>
/// <param name="nCount"></param>
/// 创建时间:2022-12-29 最后一次修改时间:2022-12-29
inline virtual void TrusteeshipMem(const _byte* pData, const int& nMemoryLength)
{
ClearMemory(); //清除内存
int nCount = nMemoryLength / sizeof(T);
if (nCount * sizeof(T) != nMemoryLength)
{
throw _t("托管内存错误!");
}
_pData = (T*)pData;
_nLength = _Math::strLen_t<T>(_pData);
_nBuffer = nCount - _nLength - 1;
if (_nBuffer < 0)
{
throw _t("托管内存错误!");
}
}
//_Check_return_ _ACRTIMP double __cdecl atof(_In_z_ char const* _Str<T>ing);
//_Check_return_ _CRT_JIT_INTRINSIC _ACRTIMP int __cdecl atoi(_In_z_ char const* _Str<T>ing);
//_Check_return_ _ACRTIMP long __cdecl atol(_In_z_ char const* _Str<T>ing);
//_Check_return_ _ACRTIMP long long __cdecl atoll(_In_z_ char const* _Str<T>ing);
//_Check_return_ _ACRTIMP __int64 __cdecl _atoi64(_In_z_ char const* _Str<T>ing);
inline __int64 ToInt64()const
{
//return ::_atoi64( (_char*)_pData);
return std::stoll((_char*)_pData);
}
inline int ToInt()const
{
//return ::atoi((_char*)_pData);
return std::stoi((_char*)_pData);
}
inline int ToDouble()const
{
//return ::atof((_char*)_pData);
return std::wcstod((_char*)_pData);
}
/// <summary>
/// 比较字符串大小
/// </summary>
/// <param name="s"></param>
/// <returns></returns>
/// 创建时间:2023-01-18 最后一次修改时间:2023-01-18
inline int CompareTo(const _Str<T>& s)const
{
return _Math::StrCmp_t<T>(_pData, s._pData);
}
/// <summary>
/// 把每个字符都用UNICODE值表示,且每人字符都用逗号分隔。
/// </summary>
/// <returns></returns>
/// 创建时间:2023-06-27 最后一次修改时间:2023-06-27 (已测试)
inline _Str<T> UnicodeVale()const
{
_Str<T> result;
if (_nLength <= 0) return result;
result.SetBuffer(_nLength * 4);
if ( typeid(_char) == typeid(T) )
{
for (int i = 0; i < _nLength - 2; ++i)
{
result.Add( _Math::IntToStr((__int64)_pData[i]).Data);
result.Add((const T*)",");
}
result.Add(_Math::IntToStr((__int64)_pData[_nLength - 1]).Data);
}
return result;
}
/// <summary>
/// 把缓冲区初始化为0
/// </summary>
/// 创建时间:2023-02-08 最后一次修改时间:2023-02-08
inline void ZeroBuffer()
{
for (int i = _nLength + 1; i <= _nBuffer + _nLength; ++i)
{
_pData[i] = 0;
}
}
//---------------------------------------------------------------------------------------静态函数
inline static _Str<wchar_t> CopyFrom(const wchar_t* pStr, const int nCopyCount)
{
_Str<wchar_t> sResult(L"", nCopyCount);
/*
sResult.setl
for (int i = 0; i < nCopyCount; ++i)
{
sResult.Add(pStr[i]);
}
*/
_Memory::Copy<wchar_t>((wchar_t*)sResult.Data, pStr, nCopyCount);
sResult.SetNewLength(nCopyCount);
return sResult;
}
inline static _Str<char> CopyFrom(const char* pStr, const int nCopyCount)
{
_Str<char> sResult("", nCopyCount);
/*
for (int i = 0; i < nCopyCount; ++i)
{
sResult.Add(pStr[i]);
}
*/
_Memory::Copy<char>((char*)sResult.Data, pStr, nCopyCount);
sResult.SetNewLength(nCopyCount);
return sResult;
}
};//----------------------------------------------------------------------------------------
#ifdef _UNICODE_
template<class T>
std::wistream& operator >> (std::wistream& os, _Str<T>& aString)
{
_Mem<T> m(1000);
os >> m.Pointer;
aString = m.Pointer;
return os;
}
template<class T>
std::wostream& operator<<(std::wostream& os, const _Str<T>& aString)
{
os << aString.Data;
return os;
}
#else
template<class T>
std::istream& operator >> (std::istream& os, _Str<T>& aString)
{
_Mem<T> m(1000);
os >> m.Pointer;
aString = m.Pointer;
return os;
}
template<class T>
std::ostream& operator<<(std::ostream& os, const _Str<T>& aString)
{
os << aString.Data;
return os;
}
#endif
_LF_END_
#endif _StrW.h
/*******************************************************************************************
文件名 : _StrW.h
作者 : 李锋
功能 : UNICODE 字符串
创建时间 : 2023年2月13日
最后一次修改时间 : 2024年24月13日
********************************************************************************************/
#ifndef __STRW_H_
#define __STRW_H_
#include "_Str.h"
#ifdef _MFC_
#include<afx.h>
#endif
//#include "C:/Program Files (x86)/Reference Assemblies/Microsoft/Framework/.NETFramework/v4.8/mscorlib.dll"
_LF_BEGIN_
class _StrListW; /// 前置声明
class _StrA;
class _StrW : public _Str<wchar_t>
{
public:
//---------------------------------------------------------------------------------构造与析构
/// <summary>
/// 缺省构造,默认为15个字符的缓冲大小
/// </summary>
_StrW() : _Str<wchar_t>() {}
_StrW(const _StrW& rhs) : _Str<wchar_t>(rhs) {}
_StrW(const _Str<wchar_t>& rhs) : _Str<wchar_t>(rhs) {}
/// <summary>
/// 拷贝构造,默认为0个字符的缺省缓冲
/// </summary>
/// <param name="pStr"></param>
/// <param name="nBuffer">缓冲区个数</param>
/// <param name="bZeroBuffer">是否实始化 buffer</param>
/// 创建时间: ????-??-?? 最后一次修改时间:2023-02-08
_StrW(const wchar_t* pStr, const int& nBuffer = 0, bool bZeroBuffer = false)
: _Str<wchar_t>(pStr, nBuffer, bZeroBuffer) {}
#ifdef _STR_COMPATIBILITY_
/// <summary>
/// 允许 _StrW str("abc"); 而不是每次都要写 _StrW str(_t("abc"))
/// </summary>
/// <param name="pStr">数据指针</param>
/// <param name="nBuffer">缓冲大小</param>
/// <param name="bZeroBuffer">是否把缓冲初始化为零</param>
/// 创建时间: 2023-05-08 最后一次修改时间:2023-05-08
_StrW(const char* pStr, const int& nBuffer = 0, bool bZeroBuffer = false);
operator _StrA() const;
#endif
/// <summary>
/// 拷贝构造函数
/// </summary>
/// <param name="pstr">要拷贝的字符串</param>
/// <param name="nStrLength">要拷贝的字符串长度</param>
/// <param name="nCopyStart">从那里开始拷贝,索引从零开始</param>
/// <param name="nCopyLength">要拷贝的长度</param>
/// <param name="nBuffer">字符串区缓冲区长度</param>
/// 创建时间: ????-??-?? 最后一次修改时间:2021-11-02
explicit _StrW(const wchar_t* pstr, const int& nStrLength, const int& nCopyStart, const int& nCopyLength, const int& nBuffer = 0)
: _Str<wchar_t>(pstr, nStrLength, nCopyStart, nCopyLength, nBuffer) {}
//inline _StrW(const std::wstring& sText) : _Str<wchar_t>(sText) {}
inline _StrW(const std::wstring& sText)
{
InitData( (int) sText.length() + _nDefaultBuffer);
Add(sText.c_str(), (int)sText.length());
}
inline explicit _StrW(const size_t& nLength, const wchar_t& ch)
: _Str<wchar_t>(nLength, ch) {
}
/// <summary>
/// 转换为单字节字符串
/// </summary>
/// <returns></returns>
_StrA ToStrA()const;
#ifdef _CLR_
/// <summary>
///
/// </summary>
/// <param name="sText"></param>
/// <param name="nBuffer"></param>
/// <param name="bZeroBuffer"></param>
/// 创建时间: ????-??-?? 最后一次修改时间:2022-02-08
inline _StrW(String^ sText, const int& nBuffer = 0, bool bZeroBuffer = false) : _Str<wchar_t>(sText, nBuffer, bZeroBuffer) {}
inline operator String ^ () const { return gcnew String(_pData); }
#endif
#ifdef _MFC_
/// <summary>
///
/// </summary>
/// <param name="sText"></param>
/// <param name="nBuffer"></param>
/// <param name="bZeroBuffer"></param>
/// 创建时间: 2024-01-22 最后一次修改时间:2024-01-22
inline _StrW(const CString& sText, const int& nBuffer = 0, bool bZeroBuffer = false)
: _Str<wchar_t>((const wchar_t*)sText, nBuffer, bZeroBuffer) {}
/// <summary>
///
/// </summary>
/// 创建时间: 2024-01-22 最后一次修改时间:2024-01-22
inline operator CString () const { return CString(_pData); }
#endif
//--------------------------------------------------------------------------------------------------------------------------类型转换
/// <summary>
/// 强制类型转换 char_ *p = (char_ *) this;
/// 或在函数调用中参数类型为 const char_ *p 时 ,而当你传入的类型为 str_时,编译器自动会把 str_ 类型转换为 str_._pData ;
/// </summary>
inline operator const wchar_t* () const { return _pData; }
//--------------------------------------------------------------------------------------------------------------Java String
//--------------------------------------------------------------------------------------------------------------CSharp String
//--------------------------------------------------------------------------------------------------------------Python String
/// <summary>
/// 返回全是大写字母的拷贝
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-03-25 最后一次修改时间:2023-03-25
_StrW Python_upper()const { return Upper(); }
/// <summary>
/// 返回全是小写字母的持由
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-03-25 最后一次修改时间:2023-03-25
_StrW Python_lower()const { return Lower(); }
/// <summary>
/// 模拟Python String.format
/// </summary>
/// <param name="pArgList"></param>
/// <returns></returns>
/// 创建时间: 2023-03-26 最后一次修改时间:2023-03-26 (已测试)
_StrW Python_format(const _StrListW& pArgList)const;
/// <summary>
/// 模拟Python String.format
/// </summary>
/// <param name="sArg"></param>
/// <param name="sSplit"></param>
/// <returns></returns>
/// 创建时间: 2023-03-26 最后一次修改时间:2023-03-26 (已测试)
_StrW Python_format(const _StrW& sArg, const _StrW& sSplit)const;
/// <summary>
/// 参数为null时删除左边的空白字符(包括’\n’, ‘\r’, ‘\t’, ’ ')
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-03-28 最后一次修改时间:2023-03-28 (已测试)
_StrW Python_lstrip(const wchar_t* pArrayChar = null)const;
/// <summary>
/// 参数为null时删除右边的空白字符(包括’\n’, ‘\r’, ‘\t’, ’ ')
/// </summary>
/// <param name="pArrayChar"></param>
/// <returns></returns>
/// 创建时间: 2023-03-28 最后一次修改时间:2023-03-28 (已测试)
_StrW Python_rstrip(const wchar_t* pArrayChar = null)const;
/// <summary>
/// 默认删除两边的空白符(包括’\n’, ‘\r’, ‘\t’, ’ '),注意:只删除开头或是结尾的字符,不删除中间部分的字符。
/// </summary>
/// <returns></returns>
/// 创建时间: 2023-03-28 最后一次修改时间:2023-03-28 (已测试)
_StrW Python_strip(const wchar_t* pArrayChar = null)const;
bool FileExists()const;
bool FileDelete() const;
/// <summary>
/// 查找第一次出现的子串,且子串后面的字符按一定的规则排列,: 第一种字符是 CharType1, 第二种是 CharType2 类型 ,依次类推.
/// 例 :
/// _Array<_CharType> ctArray = { _CharType::Digit,_CharType::EnglishLetters, _CharType::WhiteSpace };
/// _StrA s = "s1s1s s1a S2a W";
/// _pcn(s3.PowerIndexOf("s", ctArray)); 结果是 2,5
/// _pcn(s3.PowerIndexOf("s", ctArray, 10)); 结果是 -1,-1
/// _pcn(s3.PowerIndexOf("s", ctArray, 10, false)); 结果是 10,13
/// </summary>
/// <param name="sPartOne">第一部分字符</param>
/// <param name="ctArrayOtherPart">其它部分字符规则</param>
/// <param name="nPosStart">查找开始的位置</param>
/// <param name="bMatchCase">是否大小写匹配</param>
/// <returns>找到返回第一个字符的位置和最后一个字符的位置</returns>
/// 创建时间: 2022-02-20 最后一次修改时间:2022-02-21 已测试(2023-02-21)
_Pair<int, int> PowerIndexOf(const _StrW& sPartOne, const _Array<_CharType> ctArrayOtherPart, const int nPosStart = 0, bool bMatchCase = true);
/// <summary>
/// 以nMiddleIndex为中心,获取一个Word的左右边界,边界以空格或者特殊符号或者控制字符为界限。
/// </summary>
/// <param name="nMiddleIndex">中间字符在文本中的索引</param>
/// <returns></returns>
/// 创建时间:2022-12-17 最后一次修改时间: 2022-12-17 (已测试)
_Pair<int, int> GetWordBorder(int nMiddleIndex) const;
/// <summary>
///
/// </summary>
/// <param name="ctRule"></param>
/// <returns></returns>
/// 创建时间: 2023-02-26 最后一次修改时间:2023-02-26
bool IsMatchRule(const _Array<_CharType>& ctRule);
};
_LF_END_
#endif_StrW.cpp
#include "_StrW.h"
#include "_StrA.h"
#include "_StrListW.h"
#include "_Array.h"
#include "_Pair.h"
_LF_BEGIN_
_StrW _StrW::Python_format(const _StrListW& pArgList) const
{
_StrW sResult;
//设置缓冲区
sResult.SetBuffer(_nLength + pArgList.GetStringLength());
int iCount = 0;
for (int i = 0; i < _nLength; ++i)
{
if (_pData[i] == L'{')
{
//查找第二个配对
int iEnd = this->IndexOfRightPairChar(i, L'{', L'}');
if (iEnd != -1)
{
//获取 { } 中的数字字符
_StrW sCount = SubStr(i, iEnd - i).GetAllArabicDigit();
if (sCount.Length == 0) //自动选择参数
{
if (iCount < pArgList.Count)
{
sResult.Add(pArgList[iCount]);
}
else
{
sResult.Add(L"{ NULL }");
}
++iCount; //参数计数
}
else
{
int n = _Math::strToInt_t<wchar_t>(sCount.Data); //指定参数
if (n < pArgList.Count)
{
sResult.Add(pArgList[n]);
}
else
{
sResult.Add(L"{ NULL }");
}
}
i = iEnd; //跳过 {??} 参数
}
}
else
{
sResult.Add(_pData[i]);
}
}
return sResult;
}
_StrW _StrW::Python_format(const _StrW& sArg, const _StrW& sSplit) const
{
return Python_format(_StrListW(sArg, sSplit,true));
}
_StrW _StrW::Python_lstrip(const wchar_t* pArrayChar) const
{
int nLelfCopyStart = _nLength; //左边开始拷贝位置
const wchar_t* pRemove = pArrayChar == null ? L"\t\n\r " : pArrayChar;
for (int i = 0; i < _nLength; ++i)
{
if (_Math::strChr_t<wchar_t>(pRemove, _pData[i]) == -1)
{
nLelfCopyStart = i;
break;
}
}
return nLelfCopyStart < _nLength ? SubStr(nLelfCopyStart, _nLength - nLelfCopyStart) : _StrW();
}
_StrW _StrW::Python_rstrip(const wchar_t* pArrayChar) const
{
int nRightCopyStart = -1; //右边开始拷贝位置
const wchar_t* pRemove = pArrayChar == null ? L"\t\n\r " : pArrayChar;
for (int i = _nLength - 1; i >= 0; --i)
{
if (_Math::strChr_t<wchar_t>(pRemove, _pData[i]) == -1)
{
nRightCopyStart = i;
break;
}
}
return nRightCopyStart > 0 ? SubStr(0, nRightCopyStart + 1) : _StrW();
}
_StrW _StrW::Python_strip(const wchar_t* pArrayChar) const
{
int nLelfCopyStart = _nLength; //左边开始拷贝位置
const wchar_t* pRemove = pArrayChar == null ? L"\t\n\r " : pArrayChar;
for (int i = 0; i < _nLength; ++i)
{
if (_Math::strChr_t<wchar_t>(pRemove, _pData[i]) == -1)
{
nLelfCopyStart = i;
break;
}
}
int nRightCopyStart = -1; //右边开始拷贝位置
for (int i = _nLength - 1; i >= 0; --i)
{
if (_Math::strChr_t<wchar_t>(pRemove, _pData[i]) == -1)
{
nRightCopyStart = i;
break;
}
}
//拷贝长度
int nCopyLength = nRightCopyStart - nLelfCopyStart + 1;
return nCopyLength > 0 ? SubStr(nLelfCopyStart, nCopyLength) : _StrW();
}
bool _StrW::FileExists() const
{
return gcf.gcf_FileExisits(_pData);
}
bool _StrW::FileDelete() const
{
return gcf.gcf_FileDelete(_pData);
}
_Pair<int, int> _StrW::GetWordBorder(int nMiddleIndex) const
{
_Pair<int, int> pResult;
pResult.First = 0;
pResult.Second = 0;
for (int i = nMiddleIndex; i >= 0; --i)
{
_char c = _pData[i];
if (gs.s_Syntax_IsWordSeparator(c))
{
pResult.First = i + 1;
break;
}
}
for (int i = nMiddleIndex + 1; i < _nLength; ++i)
{
_char c = _pData[i];
if (gs.s_Syntax_IsWordSeparator(c))
{
pResult.Second = i - 1;
break;
}
}
return pResult;
}
bool _StrW::IsMatchRule(const _Array<_CharType>& ctRule)
{
if (ctRule.Length == 0)
{
return true;
}
return true;
}
_Pair<int, int> _StrW::PowerIndexOf(const _StrW& sPartOne, const _Array<_CharType> ctArrayOtherPart, const int nPosStart, bool bMatchCase)
{
/*
pPartOneLength[] 是长度计算的形式参数,在 main)() 函数中调用时,pPartOneLength 是一个指向数组第一个元素的指针。在执行 main() 函数时,
不知道 pPartOneLength 所表示的地址有多大的数据存储空间,只是告诉函数:一个数据存储空间首地址。
sizoef pPartOneLength 的结果是指针变量 pPartOneLength 占内存的大小,一般在 64 位机上是8个字节。a[0] 是 int 类型,
sizeof a[0] 是4个字节,结果是2。
在C/C++函数中计算传入的数组的长度是不可取的
*/
_Pair<int, int> paResult(-1, -1);
int iStart = nPosStart >= 0 ? nPosStart : 0;
if (iStart >= _nLength) return paResult;
int nEnd = _nLength - sPartOne._nLength;
int nAarryOtherPartLength = ctArrayOtherPart.Length;
for (int i = iStart; i <= nEnd; ++i)
{
bool bFind = true;
for (int j = 0; j < sPartOne._nLength; ++j)
{
if (bMatchCase)
{
if (_pData[i + j] != sPartOne._pData[j])
{
bFind = false;
break;
}
}
else
{
if (gcf.gcf_tolower(_pData[i + j]) != gcf.gcf_tolower(sPartOne._pData[j]))
{
bFind = false;
break;
}
}
}
//比较第二部份
if (bFind)
{
paResult.First = i;
int iStart = i + sPartOne._nLength;
int k = 0;
int n = 0;
int nCount = 0;
while (true)
{
bool bFinish = false;
for (n = 0; n < nAarryOtherPartLength; ++n)
{
if (ctArrayOtherPart[n] == _CharType::ArabicDigit)
{
//向后查找第一个不是数字的字符
bool bHave = false;
for (k = iStart; k < _nLength; ++k)
{
if (!gs.c_IsArabicDigit(_pData[k]))
{
iStart = k; //下次开始比较的位置
if (bHave)
{
if (n == nAarryOtherPartLength - 1) //一轮比较完成
{
paResult.Second = k - 1;
bFinish = true;
++nCount;
}
}
break;
}
else
{
bHave = true;
if (k == _nLength - 1) //栓果是否最后一个字符
{
if (n == nAarryOtherPartLength - 1)
{
paResult.Second = k;
}
return paResult;
}
}
}
}
else if (ctArrayOtherPart[n] == _CharType::Punctuation)
{
//向后查找第一个不是标点符号的字符
bool bHave = false;
for (k = iStart; k < _nLength; ++k)
{
if (!gs.c_IsPunctuation(_pData[k]))
{
iStart = k; //下次开始比较的位置
if (bHave)
{
if (n == nAarryOtherPartLength - 1) //一轮比较完成
{
paResult.Second = k - 1;
bFinish = true;
++nCount;
}
}
break;
}
else
{
bHave = true;
if (k == _nLength - 1) //栓果是否最后一个字符
{
if (n == nAarryOtherPartLength - 1)
{
paResult.Second = k;
}
return paResult;
}
}
}
}
else if (ctArrayOtherPart[n] == _CharType::EnglishLetters)
{
//向后查找第一个不是英文字母的字符
bool bHave = false;
for (k = iStart; k < _nLength; ++k)
{
if (!gs.c_IsEnglishLetters(_pData[k]))
{
iStart = k; //下次开始比较的位置
if (bHave)
{
if (n == nAarryOtherPartLength - 1) //一轮比较完成
{
paResult.Second = k - 1;
bFinish = true;
++nCount;
}
}
break;
}
else
{
bHave = true;
if (k == _nLength - 1) //栓果是否最后一个字符
{
if (n == nAarryOtherPartLength - 1)
{
paResult.Second = k;
}
return paResult;
}
}
}
}
else if (ctArrayOtherPart[n] == _CharType::WhiteSpace)
{
//向后查找第一个不是空格的字符
bool bHave = false;
for (k = iStart; k < _nLength; ++k)
{
if (!gs.c_IsWhiteSpace(_pData[k]))
{
iStart = k; //下次开始比较的位置
if (bHave)
{
if (n == nAarryOtherPartLength - 1) //一轮比较完成
{
paResult.Second = k - 1;
bFinish = true;
++nCount;
}
}
break;
}
else
{
bHave = true;
if (k == _nLength - 1) //栓果是否最后一个字符
{
if (n == nAarryOtherPartLength - 1)
{
paResult.Second = k;
}
return paResult;
}
}
}
}
else
{
throw("未知字符类型!");
}
}
if (!bFinish) //退出 while 循环
{
break;
}
}
if (nCount > 0) //已找到匹配字符串
{
return paResult;
}
}
}
return paResult;
}
#ifdef _STR_COMPATIBILITY_ //兼容 _StrA 与 _StrW 互相兼容
/// <summary>
/// 允许 _StrW str("abc"); 而不是每次都要写 _StrW str(_t("abc"))
/// </summary>
/// <param name="pStr">数据指针</param>
/// <param name="nBuffer">缓冲大小</param>
/// <param name="bZeroBuffer">是否把缓冲初始化为零</param>
/// 创建时间: 2023-05-08 最后一次修改时间:2023-05-08
_StrW::_StrW(const char* pStr, const int& nBuffer, bool bZeroBuffer) :
_Str<wchar_t>(gs.StringToWString(pStr).Pointer, nBuffer, bZeroBuffer)
{
}
_StrW::operator _StrA() const
{
return gs.WStringToString(_pData,_nLength).Pointer;
}
#endif
_StrA _StrW::ToStrA() const
{
_StrA sResult("", _nLength);
for (int i = 0; i < _nLength; ++i)
{
sResult.Add((char)_pData[i]);
}
return sResult;
}
_LF_END_

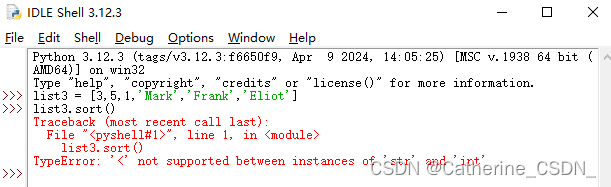


![[Linux] 进程概念](https://img-blog.csdnimg.cn/direct/040aee4f663046de874543a9b993dcd4.png)