请支持我的店铺tao 宝 王后兵 店
把chessbase17或fritz19根目录(如C:\Program Files\ChessBase\CBase17)的messages文件夹复制到本py文件所在的文件夹,运行本py文件可以生成新的Chinese strings文件。
strings2.py
"""strings文件的中文、英文的比较和新中文strings的生成"""
import os # 判断文件夹是否已存在和创建新文件夹用到
import shutil # 用于复制文件到另一个目录
root_path = "./messages"
en = "english"
cn = "chinese"
cn_new = "new_chinese"
cn_new_file_path = f"{root_path}/{cn_new}/"
def genCapWordsList(file_name, sub_dir_name):
"""生成大写符号的列表的函数(中文、英文都是用这个函数)"""
file = open(f"{root_path}/{sub_dir_name}/{file_name}.strings", mode="r", encoding='utf-8')
cap_words_list = []
line_nums = 0
content_begin_line_max = 21
content_flag = False
for line in file:
line_nums += 1
if line_nums < content_begin_line_max:
if line.startswith('M_'):
content_flag = True # 如果20行以内行以M_打头则正文起始了。因为如果全文都检测是浪费性能。
if content_flag and line.strip().endswith('";'): # 正文起头了,并且都是以";结尾的正规行
cap_words = line.split(',')[0] # 从正文起头后,大写字符提取出来 。
cap_words_list.append(cap_words) # 大写字符就加到列表中。
file.close()
return cap_words_list
def genLangDictList(file_name, sub_dir_name=en):
"""生成英文大写符号-字符串字典的列表"""
file = open(f"{root_path}/{sub_dir_name}/{file_name}.strings", mode="r", encoding='utf-8')
en_dict_list = []
line_nums = 0
content_begin_line_max = 21
content_flag = False
for line in file:
line_nums += 1
if line_nums < content_begin_line_max:
if line.startswith('M_'):
content_flag = True
if content_flag and line.strip().endswith('";'):
cap_words = line.split(',')[0]
enDict = {cap_words: line.split(',')[1].split('"')[1]}
en_dict_list.append(enDict) # 得到英语文件的字典列表
file.close()
return en_dict_list
def genCnDict(file_name):
"""生成中文大写符号-中文翻译的字典"""
file = open(f"{root_path}/{cn}/{file_name}.strings", mode="r", encoding='utf-8')
cn_dict = {}
line_nums = 0
content_begin_line_max = 21
content_flag = False
for line in file:
line_nums += 1
if line_nums < content_begin_line_max:
if line.startswith('M_'):
content_flag = True
if content_flag and line.strip().endswith('";'):
cap_words = line.split(',')[0]
cn_dict[cap_words] = line.split(',')[1].split('"')[1] # 得到中文文件的字典
file.close()
return cn_dict
def isCnEnEqual(file_name):
"""中文和英文strings文件的大写符号列表是否相同"""
is_equal = False
if genCapWordsList(file_name, en) == genCapWordsList(file_name, cn):
is_equal = True
return is_equal
def getMaxLen(file_name):
"""新生成的Chinese.strings中第一个英文引号" 放在哪一列"""
Max_len = len(sorted(genCapWordsList(file_name, en), key=len, reverse=True)[0]) + 4
return Max_len
def writeHeaders(file_name, file_path=cn_new_file_path, create_time="yyyy/mm/dd", author="yourName"):
"""写入统一headers"""
if not os.path.exists(file_path):
os.makedirs(file_path)
cn_new_file = open(f"{file_path}/{file_name}.strings", mode='w', encoding='utf-8')
uni_headers = f'''/*
Generated with StringsTool
版本: 0.1
创建日期: {create_time}
作者: {author}
IMPORTANT:
0. 不要在";后面再加任何注释//等字符(空白字符没关系)
1. Please do not change or translate the symbols in capital letters.
2. Do not remove or add commas and semicolons.
3. Make sure that every string is included into quotes.
*/
'''
cn_new_file.write(uni_headers)
cn_new_file.close()
def writeMainContents(file_name, dir_path=cn_new_file_path):
"""写入新的翻译内容"""
cn_new_file = open(f"{dir_path}/{file_name}.strings", mode='a', encoding='utf-8')
# 确定翻译内容部分,及每一行的内容的确定。用f字符串
cap_words_list = genCapWordsList(file_name, en)
Max_len = getMaxLen(file_name)
en_list = genLangDictList(file_name)
cn_dict = genCnDict(file_name)
for element in cap_words_list:
default_value = en_list[cap_words_list.index(element)][element]
value = cn_dict.get(element, default_value)
spaces = " " * (Max_len - len(element))
line = f'{element},{spaces}"{value}";\n'
cn_new_file.write(line)
cn_new_file.close()
def compareAndGenerate(file_name):
"""比较和生成新的Chinese strings文件"""
is_cn_en_equal = isCnEnEqual(file_name)
if not is_cn_en_equal:
print(f"{file_name}中文对比英文不同,将会生成新的{file_name}中文strings")
writeHeaders(file_name, create_time="20240519", author="yourName")
writeMainContents(file_name)
print(f"新建new_chinese {file_name}.strings成功\n")
else:
print(f"{file_name}中文对比英文相同,原有的中文{file_name}.strings可以继续使用")
source_path = f"{root_path}/{cn}/{file_name}.strings"
dest_path = f"{cn_new_file_path}/{file_name}.strings"
if not os.path.exists(source_path):
print(f"源文件 {source_path} 不存在")
else:
if not os.path.exists(dest_path):
os.makedirs(cn_new_file_path, exist_ok=True)
shutil.copy2(source_path, dest_path)
print(f"{file_name}.strings已复制到new_chinese文件夹\n")
if __name__ == "__main__":
name_lists = ["analysis", "app", "countries", "frame", "posTutor", "replayTraining", "textures"]
nums = 0
for name in name_lists:
nums += 1
print(nums, end=' ')
compareAndGenerate(name)
input("按下回车继续...")
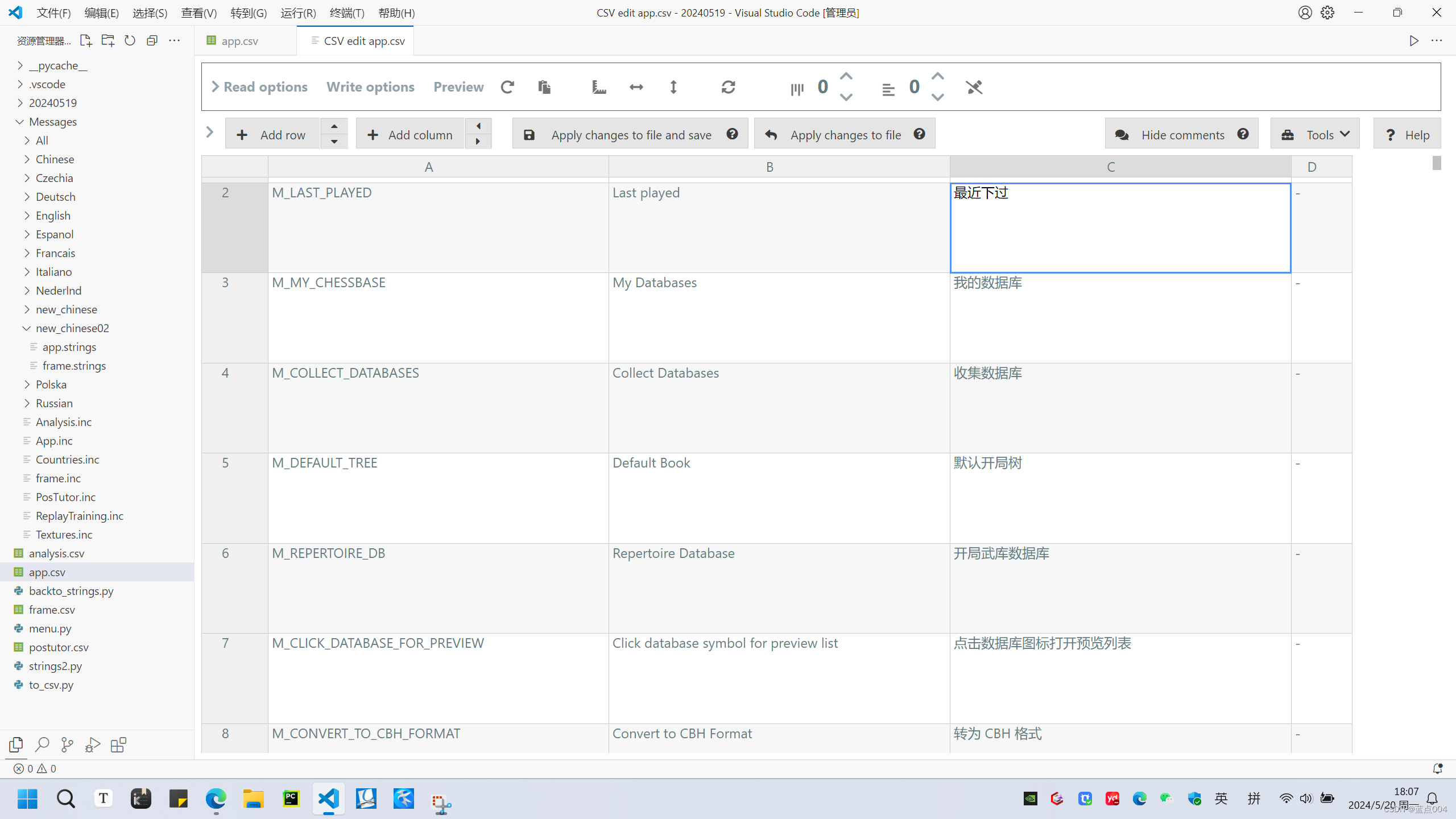
下面这个py文件可以把 英文和中文的strings合并到csv文件。csv文件可以用vscode edit csv插件 打开方便进行修改翻译。(注意不要用Excel)
to_csv.py
import strings2
def toCsv(file_name="app"):
"""英文和中文的strings合并到csv文件"""
cap_words_list = strings2.genCapWordsList(file_name, sub_dir_name=strings2.en)
lists_len = len(cap_words_list)
en_dict_list = strings2.genLangDictList(file_name, sub_dir_name=strings2.en)
cn_dict_list = strings2.genLangDictList(file_name, sub_dir_name=strings2.cn_new)
comments_list = "-" * lists_len
csv_file = open(f"{file_name}.csv", mode="wt", encoding="utf-8")
csv_file.write("大写符号,英语,汉语翻译,注释\n")
for i in range(lists_len):
key = cap_words_list[i]
line = f"{key},{en_dict_list[i][key]},{cn_dict_list[i][key]},{comments_list[i]}\n"
csv_file.write(line)
csv_file.close()
if __name__ == "__main__":
toCsv("app")
下面这个py文件可以在上面修改翻译保存后,从csv文件重新创建Chinese的strings文件。
backto_strings.py
import strings2
cn_new02 = "new_chinese02"
def writeBackToStrings(file_name):
"""从csv文件写回Chinese的strings文件"""
csv_file = open(f"{file_name}.csv", mode="rt", encoding="utf-8")
strings2.writeHeaders(file_name, file_path=f"{strings2.root_path}/{cn_new02}",create_time="2024", author="zhw") #
file = open(f"{strings2.root_path}/{cn_new02}/{file_name}.strings", mode='a', encoding='utf-8')
Max_len = strings2.getMaxLen(file_name)
first_line = True
for line in csv_file:
if first_line:
first_line = False
continue
line_list = line.strip().split(",")
spaces = " " * (Max_len - len(line_list[0]))
file.write(f'{line_list[0]},{spaces}"{line_list[2]}";\n')
file.close()
if __name__ == "__main__":
writeBackToStrings(file_name="app")
新代码和可执行程序在gitee上了。
chessbase strings比较生成和修改工具: chessbase strings比较、生成和中文翻译修改工具。