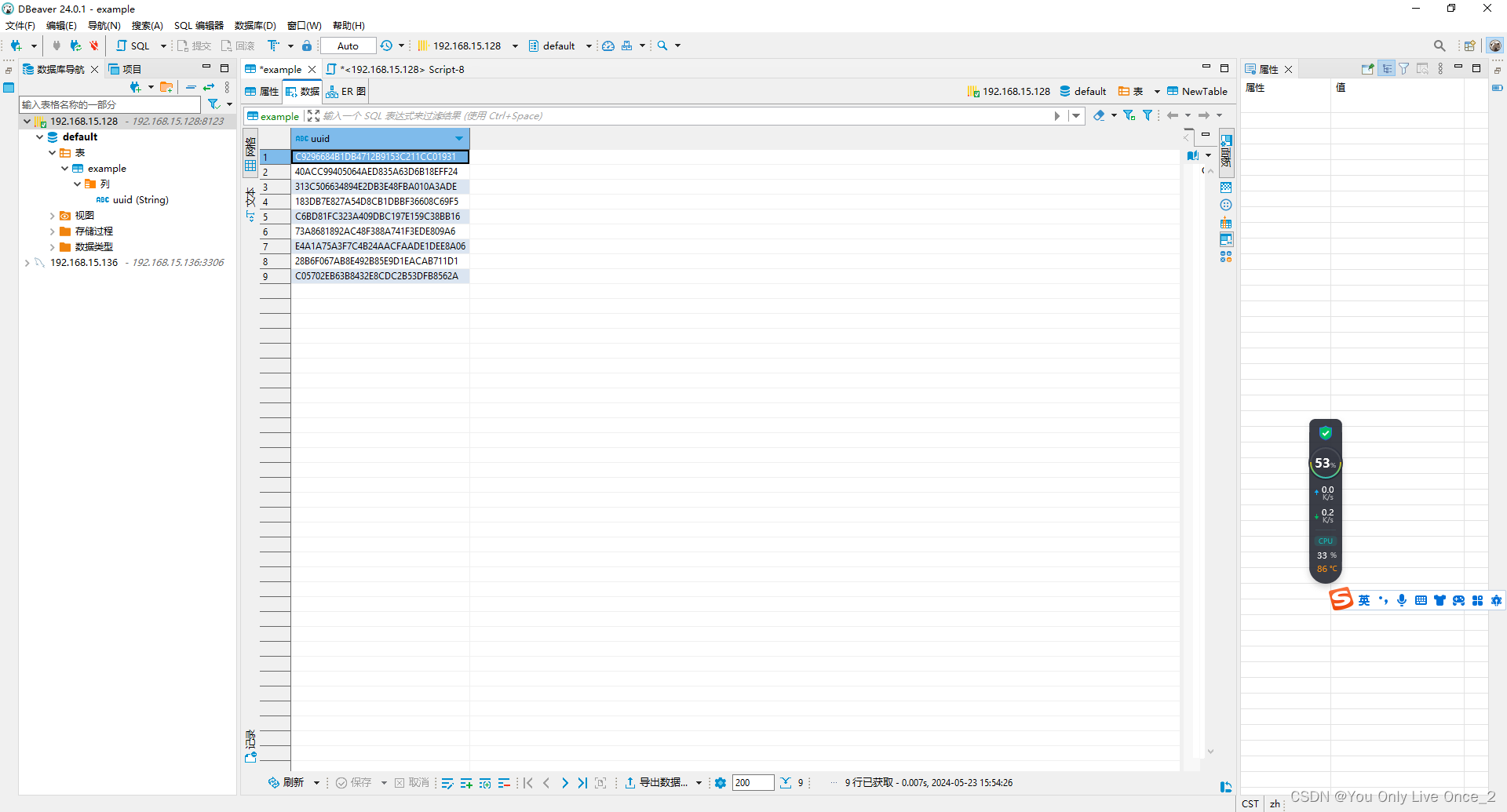
1、Adaboost算法
Adaboost算法是一种集成学习方法,通过结合多个弱学习器来构建一个强大的预测模型。核心思想:如果一个简单的分类器在训练数据上犯错误,那么它在测试数据上也可能犯错误。
Adaboost通过迭代地训练一系列的分类器,并为每次训练选择训练数据的子集,从而使得每个分类器在训练数据上的错误率最小化。
算法步骤
1.1 分配每个观测样本
,一个初始权重
,
,其中n为样本总量数。
1.2 训练一个“弱模型”(常用决策树)
1.3 对于每个目标:
1.3.1 如果预测错误,
1.3.2 如果预测正确,
1.4 训练一个新的“弱模型”,其中权重较大的观测样本相应分配较高的优先权
1.5 重复步骤三和四,直到得到样本被完美预测,或是训练处当前规模的决策树
优点:
1、提高准确率:通过集成多个弱分类器,Adaboost可以显著提高预测的准确率,尤其是在处理复杂和非线性问题时。
2、处理不平衡数据:Adaboost能够自动调整每个分类器的权重,以对错误率的类别给予更多的关注,这有助于提高少数类的分类性能。
3、对异常值不敏感:由于Adaboost会根据错误率来调整权重,异常值的影响会被减少。
4、模型透明度高:Adaboost可以提供每个弱分类器的权重,这使得模型易于解释和理解。
缺点:
1、过拟合风险:如果弱分类器的选择不当或者迭代次数过多,Adaboost可能会导致过拟合,尤其是在数据量较小的情况下。
2、计算成本:由于需要训练多个弱分类器,Adaboost的计算成本较高,尤其是在大模型数据集上。
3、弱学习器选择:Adaboost的效果很大程度上取决于所选的弱学习器,如果弱学习器选择不当,Adaboost可能无法达到预测的性能。
4、对噪声敏感:Adaboost可能会对噪声数据敏感,因为噪声数据可能会导致某些分类器权重过高,从而影响最终预测。
5、解释性差:尽管Adaboost提供每个弱分类器的权重,但整个集成模型的解释性仍然不如单个决策树或线性模型。
6、依赖正则化:Adaboost依赖于正则化来防止过拟合,这意味着模型可能会在测试集上表现不佳。
2、拟合度:调整R方
是一个统计量,用于衡量线性回归模型对观测数据的拟合程度,特别是在模型中包含多个自变量时,调整R方考虑了模型中自变量的数量,从而避免了模型过渡拟合的风险。
RSS:残差平方和
TSS:总平方和
n:观测值
d:特征值
的取值范围是从0到1,
只反映了模型解释变异的能力,它并不考虑模型的复杂度。
当为0时,表示模型没有解释任何因变量的变异,即模型完全不能预测因变量的值
当为1时,表示模型完全解释了因变量的变异,即模型完美地预测了因变量的值
3、Agglomerative聚类
是一种基于距离的层次聚类算法,在这个算法中,每个数据点最初都被视为一个单独的簇,然后逐步合并这些簇,直到达到某个停止条件。合并的决策是基于簇之间的相似度(通常使用距离度量),即两个簇之间的相似度越高,他们被合并的可能性越大。
4、AIC赤池信息量准则
是一种用于评估统计模型拟合优度的指标,AIC考虑了模型拟合数据的能力和模型的复杂度,旨在找到一个在数据拟合和模型复杂度之间达到平衡的模型。
AIC的基本思想:一个好的模型应该既能够很好地拟合数据,又不会过于复杂。因此,AIC在计算似然函数值的基础上,对模型复杂度进行惩罚,即增加一个与模型参数数量成正比的项。这样,AIC的值越小,表示模型越优秀。
n:观测值
:样本方差
RSS:残差平方和
d:特征值
AIC的缺点:对模型复杂度的惩罚是固定的,即每个参数的惩罚都是2。这可能会导致某些模型在参数数量上略有不同,但整体结构相似时,AIC的值差异较大。为了解决这个问题,出现了贝叶斯信息量准则(BIC)