文章目录
- 安装配置环境
- 图像采集
- 采集函数
- 爬取一类图片
- 爬取多类图片
- 一些参考类别的关键词
- 制作图像分类数据集的注意事项
- 删除多余文件
- 删除系统自动生成的多余文件
- 删除gif格式的图像文件
- 删除非三通道的图像¶
- 统计图像尺寸、比例分布
- 采用的数据集
- 统计数据集的基本信息
- 可视化图像尺寸分布
- 划分训练集和测试集
- 创建训练集文件夹和测试集文件夹
- 划分训练集、测试集,移动文件
- 可视化文件夹中的图像
- 指定要可视化图像的文件夹
- 读取文件夹中的所有图像
- 画图
- 图像分类数据集探索统计
- 导入数据集
- 图像数量柱状图可视化
- 总结
安装配置环境
!pip install numpy pandas matplotlib requests tqdm opencv-python
图像采集
import os
import time
import requests
import urllib3
urllib3.disable_warnings()
from tqdm import tqdm #进度条库
import os
采集函数
该函数实现根据关键词和爬取数量,先在本地创建文件夹,再爬取目标图片并保存图像文件至本地
def craw_single_class(keyword, DOWNLOAD_NUM = 50):
"""
参数说明:
keyword: 爬取对象
DOWNLOAD_NUM:爬取的数量
"""
########################HTTP请求参数###############################
cookies = {
'BDqhfp': '%E7%8B%97%E7%8B%97%26%26NaN-1undefined%26%2618880%26%2621',
'BIDUPSID': '06338E0BE23C6ADB52165ACEB972355B',
'PSTM': '1646905430',
'BAIDUID': '104BD58A7C408DABABCAC9E0A1B184B4:FG=1',
'BDORZ': 'B490B5EBF6F3CD402E515D22BCDA1598',
'H_PS_PSSID': '35836_35105_31254_36024_36005_34584_36142_36120_36032_35993_35984_35319_26350_35723_22160_36061',
'BDSFRCVID': '8--OJexroG0xMovDbuOS5T78igKKHJQTDYLtOwXPsp3LGJLVgaSTEG0PtjcEHMA-2ZlgogKK02OTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF': 'tJPqoKtbtDI3fP36qR3KhPt8Kpby2D62aKDs2nopBhcqEIL4QTQM5p5yQ2c7LUvtynT2KJnz3Po8MUbSj4QoDjFjXJ7RJRJbK6vwKJ5s5h5nhMJSb67JDMP0-4F8exry523ioIovQpn0MhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0D6bBjHujtT_s2TTKLPK8fCnBDP59MDTjhPrMypomWMT-0bFH_-5L-l5js56SbU5hW5LSQxQ3QhLDQNn7_JjOX-0bVIj6Wl_-etP3yarQhxQxtNRdXInjtpvhHR38MpbobUPUDa59LUvEJgcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj0DKLtD8bMC-RDjt35n-Wqxobbtof-KOhLTrJaDkWsx7Oy4oTj6DD5lrG0P6RHmb8ht59JROPSU7mhqb_3MvB-fnEbf7r-2TP_R6GBPQtqMbIQft20-DIeMtjBMJaJRCqWR7jWhk2hl72ybCMQlRX5q79atTMfNTJ-qcH0KQpsIJM5-DWbT8EjHCet5DJJn4j_Dv5b-0aKRcY-tT5M-Lf5eT22-usy6Qd2hcH0KLKDh6gb4PhQKuZ5qutLTb4QTbqWKJcKfb1MRjvMPnF-tKZDb-JXtr92nuDal5TtUthSDnTDMRhXfIL04nyKMnitnr9-pnLJpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuj6tWj6j0DNRabK6aKC5bL6rJabC3b5CzXU6q2bDeQN3OW4Rq3Irt2M8aQI0WjJ3oyU7k0q0vWtvJWbbvLT7johRTWqR4enjb3MonDh83Mxb4BUrCHRrzWn3O5hvvhKoO3MA-yUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQXH_E5bj2qRCqVIKa3f',
'BDSFRCVID_BFESS': '8--OJexroG0xMovDbuOS5T78igKKHJQTDYLtOwXPsp3LGJLVgaSTEG0PtjcEHMA-2ZlgogKK02OTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF_BFESS': 'tJPqoKtbtDI3fP36qR3KhPt8Kpby2D62aKDs2nopBhcqEIL4QTQM5p5yQ2c7LUvtynT2KJnz3Po8MUbSj4QoDjFjXJ7RJRJbK6vwKJ5s5h5nhMJSb67JDMP0-4F8exry523ioIovQpn0MhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0D6bBjHujtT_s2TTKLPK8fCnBDP59MDTjhPrMypomWMT-0bFH_-5L-l5js56SbU5hW5LSQxQ3QhLDQNn7_JjOX-0bVIj6Wl_-etP3yarQhxQxtNRdXInjtpvhHR38MpbobUPUDa59LUvEJgcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj0DKLtD8bMC-RDjt35n-Wqxobbtof-KOhLTrJaDkWsx7Oy4oTj6DD5lrG0P6RHmb8ht59JROPSU7mhqb_3MvB-fnEbf7r-2TP_R6GBPQtqMbIQft20-DIeMtjBMJaJRCqWR7jWhk2hl72ybCMQlRX5q79atTMfNTJ-qcH0KQpsIJM5-DWbT8EjHCet5DJJn4j_Dv5b-0aKRcY-tT5M-Lf5eT22-usy6Qd2hcH0KLKDh6gb4PhQKuZ5qutLTb4QTbqWKJcKfb1MRjvMPnF-tKZDb-JXtr92nuDal5TtUthSDnTDMRhXfIL04nyKMnitnr9-pnLJpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuj6tWj6j0DNRabK6aKC5bL6rJabC3b5CzXU6q2bDeQN3OW4Rq3Irt2M8aQI0WjJ3oyU7k0q0vWtvJWbbvLT7johRTWqR4enjb3MonDh83Mxb4BUrCHRrzWn3O5hvvhKoO3MA-yUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQXH_E5bj2qRCqVIKa3f',
'indexPageSugList': '%5B%22%E7%8B%97%E7%8B%97%22%5D',
'cleanHistoryStatus': '0',
'BAIDUID_BFESS': '104BD58A7C408DABABCAC9E0A1B184B4:FG=1',
'BDRCVFR[dG2JNJb_ajR]': 'mk3SLVN4HKm',
'BDRCVFR[-pGxjrCMryR]': 'mk3SLVN4HKm',
'ab_sr': '1.0.1_Y2YxZDkwMWZkMmY2MzA4MGU0OTNhMzVlNTcwMmM2MWE4YWU4OTc1ZjZmZDM2N2RjYmVkMzFiY2NjNWM4Nzk4NzBlZTliYWU0ZTAyODkzNDA3YzNiMTVjMTllMzQ0MGJlZjAwYzk5MDdjNWM0MzJmMDdhOWNhYTZhMjIwODc5MDMxN2QyMmE1YTFmN2QyY2M1M2VmZDkzMjMyOThiYmNhZA==',
'delPer': '0',
'PSINO': '2',
'BA_HECTOR': '8h24a024042g05alup1h3g0aq0q',
}
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
'Accept': 'text/plain, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'sec-ch-ua-platform': '"macOS"',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1647837998851_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=MCwzLDIsNiwxLDUsNCw4LDcsOQ%3D%3D&ie=utf-8&sid=&word=%E7%8B%97%E7%8B%97',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
############################创建文件夹################################
if os.path.exists('dataset/'+keyword):
print('文件夹 dataset/{} 已存在,之后直接将爬取到的图片保存至该文件夹中'.format(keyword))
else:
os.makedirs('dataset/{}'.format(keyword))
print('新建文件夹:dataset/{}'.format(keyword))
#####################爬取并保存图像文件至本地#########################
count = 1
with tqdm(total=DOWNLOAD_NUM, position=0, leave=True) as pbar:
num = 0 #爬取第几张
FLAG = True #是否继续爬取
while FLAG:
page = 30 * count
params = (
('tn', 'resultjson_com'),
('logid', '12508239107856075440'),
('ipn', 'rj'),
('ct', '201326592'),
('is', ''),
('fp', 'result'),
('fr', ''),
('word', f'{keyword}'),
('queryWord', f'{keyword}'),
('cl', '2'),
('lm', '-1'),
('ie', 'utf-8'),
('oe', 'utf-8'),
('adpicid', ''),
('st', '-1'),
('z', ''),
('ic', ''),
('hd', ''),
('latest', ''),
('copyright', ''),
('s', ''),
('se', ''),
('tab', ''),
('width', ''),
('height', ''),
('face', '0'),
('istype', '2'),
('qc', ''),
('nc', '1'),
('expermode', ''),
('nojc', ''),
('isAsync', ''),
('pn', f'{page}'),
('rn', '30'),
('gsm', '1e'),
('1647838001666', ''),
)
response = requests.get('https://image.baidu.com/search/acjson', headers=headers, params=params, cookies=cookies)
if response.status_code == 200:
try:
json_data = response.json().get("data")
if json_data:
for x in json_data:
type = x.get("type")
if type not in ["gif"]:#剔除gif格式的图片
img = x.get("thumbURL")
fromPageTitleEnc = x.get("fromPageTitleEnc")
try:
resp = requests.get(url=img, verify=False)
time.sleep(1)
# print(f"链接 {img}")
# 保存文件名
# file_save_path = f'dataset/{keyword}/{num}-{fromPageTitleEnc}.{type}'
file_save_path = f'dataset/{keyword}/{num}.{type}'
with open(file_save_path, 'wb') as f:
f.write(resp.content)
f.flush()
# print('第 {} 张图像 {} 爬取完成'.format(num, fromPageTitleEnc))
num += 1
pbar.update(1) # 进度条更新
# 爬取数量达到要求
if num > DOWNLOAD_NUM:
FLAG = False
print('{} 张图像爬取完毕'.format(num))
break
except Exception:
pass
except:
pass
else:
break
count += 1
爬取一类图片
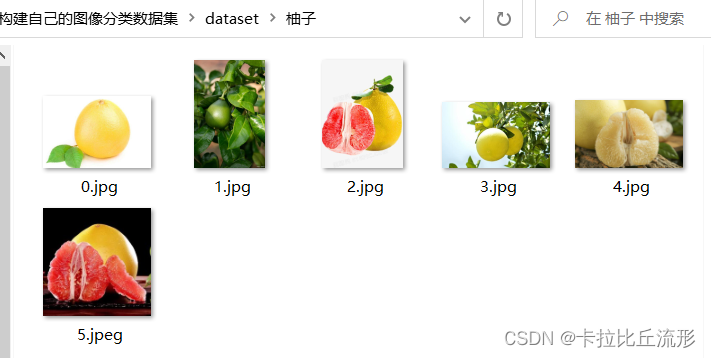
这里以柚子为关键词,设置爬取的数量为5
craw_single_class('柚子', DOWNLOAD_NUM = 5)
爬取的结果如下图所示
爬取多类图片
将想要爬取的关键词写入列表中,对每一个关键词分别爬取五张图片
class_list = ['黄瓜','南瓜','冬瓜','木瓜','苦瓜','丝瓜','窝瓜','甜瓜','香瓜','白兰瓜','黄金瓜','西葫芦','人参果','羊角蜜','佛手瓜','伊丽莎白瓜']
for each in class_list:#对列表中的关键词分别进行爬取
craw_single_class(each, DOWNLOAD_NUM = 5)

一些参考类别的关键词
由于不同类别的水果有很多子类,爬取图片的时候要注意关键词的别称,这里给出了一些参考类别的关键词
# 苹果
'苹果 水果','青苹果'
# 常见水果
'菠萝','榴莲','椰子','香蕉','梨','芒果'
# 西红柿类
'圣女果','西红柿'
# 桔橙类
'砂糖橘','脐橙','金桔','柠檬','西柚','血橙','芦柑','青柠','沃柑','粑粑柑','橘子','柚子'
# 桃类
'猕猴桃','油桃','水蜜桃','蟠桃','杨桃','黄桃'
# 樱桃类
'樱桃','智利 车厘子'
# 火龙果类
'白心火龙果','红心火龙果'
# 葡萄类
'马奶提子','红提'
# 萝卜类
'胡萝卜','白萝卜'
# 莓类
'桑葚','蔓越莓','蓝莓','草莓','树莓','菠萝莓''黑莓 水果'
# 其它类
'山楂','桂圆','杨梅','西梅','沙果','枣','荔枝','腰果','无花果','沙棘','羊奶果','百香果','黄金百香果','甘蔗','菠萝蜜','酸角','蛇皮果','人参果','红芭乐','白芭乐','牛油果','莲雾','山竹','杏','李子','柿子','枇杷','香橼','毛丹','石榴'
制作图像分类数据集的注意事项
- 删除无关图片
- 类别均衡
- 多样性、代表性、一致性
- 数据集应尽可能包括目标物体的各类场景,训练出的图像分类模型才能在各类测试场景中具备好的泛化性能,防止过拟合。
- 不同尺寸、比例的图像
- 不同拍摄环境(光照、设备、拍摄角度、遮挡、远近、大小)
- 不同形态(完整西瓜、切瓣西瓜、切块西瓜)
- 不同部位(全瓜、瓜皮、瓜瓤、瓜子)
- 不同时期(瓜秧、小瓜、大瓜)
- 不同背景(人物、菜地、抠图)
- 不同图像域(照片、漫画、剪贴画、油画)
- 如果训练集的图像分布与测试集(或真实测试场景)的图像分布不一致,会出现OOD(Out-Of-Distribution)问题。
- 数据集应尽可能包括目标物体的各类场景,训练出的图像分类模型才能在各类测试场景中具备好的泛化性能,防止过拟合。
删除多余文件
说明:本章的命令都要在Linux环境下才能实现,dataset_delete_test是数据集文件
删除系统自动生成的多余文件
!for i in `find . -iname '__MACOSX'`; do rm -rf $i;done
!for i in `find . -iname '.DS_Store'`; do rm -rf $i;done
!for i in `find . -iname '.ipynb_checkpoints'`; do rm -rf $i;done
删除gif格式的图像文件
dataset_path = 'dataset_delete_test'
for fruit in tqdm(os.listdir(dataset_path)):
for file in os.listdir(os.path.join(dataset_path, fruit)):
file_path = os.path.join(dataset_path, fruit, file)
img = cv2.imread(file_path)
if img is None:
print(file_path, '读取错误,删除')
os.remove(file_path)
删除非三通道的图像¶
for fruit in tqdm(os.listdir(dataset_path)):
for file in os.listdir(os.path.join(dataset_path, fruit)):
file_path = os.path.join(dataset_path, fruit, file)
img = np.array(Image.open(file_path))
try:
channel = img.shape[2]
if channel != 3:
print(file_path, '非三通道,删除')
os.remove(file_path)
except:
print(file_path, '非三通道,删除')
os.remove(file_path)
统计图像尺寸、比例分布
采用的数据集
fruit81水果图像分类数据集
包含81个类别:
白兰瓜,羊角蜜,哈密瓜,西瓜,佛手瓜,木瓜,甜瓜-白,甜瓜-伊丽莎白,甜瓜-金,甜瓜-绿,
黄桃,猕猴桃,杨桃,水蜜桃,蟠桃,油桃,圣女果,西红柿,
红苹果,青苹果,芒果,菠萝,石榴,山竹,椰子,香蕉,梨,榴莲,枇杷,
桑葚,菠萝莓,黑莓,草莓,蓝莓,树莓,莲雾,蛇皮果,牛油果,
沃柑,血橙,柚子,脐橙,西柚,粑粑柑,香橼,柠檬,橘子,砂糖橘,芦柑,金桔,青柠,
人参果,山楂,沙棘,甘蔗,樱桃,车厘子,杨梅,百香果,无花果,桂圆,毛丹,酸角,荔枝,杏,枣,柿子,菠萝蜜,羊奶果,沙果,李子,腰果,西梅,
葡萄-红,葡萄-白,番石榴-红,番石榴-百,白心火龙果,红心火龙果,胡萝卜,白萝卜,
数据集下载链接:
fruit81_full.zip(未划分训练测试集)
fruit81_split.zip(已划分训练测试集)
统计数据集的基本信息
import os
import numpy as np
import pandas as pd
import cv2
from tqdm import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
# 指定数据集路径
dataset_path = 'fruit81_full'
os.chdir(dataset_path)
print(os.listdir())
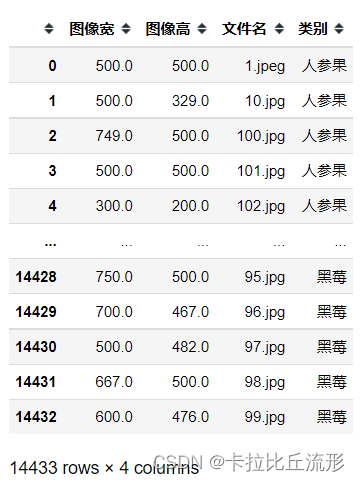
df = pd.DataFrame()
for fruit in tqdm(os.listdir()): # 遍历每个类别
os.chdir(fruit)
for file in os.listdir(): # 遍历每张图像
try:
img = cv2.imread(file)
df = df.append({'类别':fruit, '文件名':file, '图像宽':img.shape[1], '图像高':img.shape[0]}, ignore_index=True)
except:
print(os.path.join(fruit, file), '读取错误')
os.chdir('../')
os.chdir('../')
共有14433条数据,每条数据有图像宽、图像高、文件名、类别四个属性
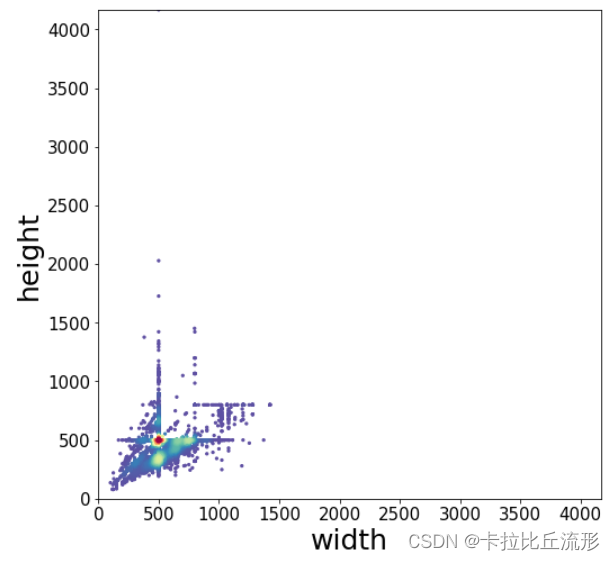
可视化图像尺寸分布
对统计过的信息进行可视化
from scipy.stats import gaussian_kde
from matplotlib.colors import LogNorm
x = df['图像宽']
y = df['图像高']
xy = np.vstack([x,y])
z = gaussian_kde(xy)(xy)
# Sort the points by density, so that the densest points are plotted last
idx = z.argsort()
x, y, z = x[idx], y[idx], z[idx]
plt.figure(figsize=(8,8))
# plt.figure(figsize=(12,12))
plt.scatter(x, y, c=z, s=5, cmap='Spectral_r')
# plt.colorbar()
# plt.xticks([])
# plt.yticks([])
plt.tick_params(labelsize=15)
xy_max = max(max(df['图像宽']), max(df['图像高']))
plt.xlim(xmin=0, xmax=xy_max)
plt.ylim(ymin=0, ymax=xy_max)
plt.ylabel('height', fontsize=25)
plt.xlabel('width', fontsize=25)
plt.savefig('图像尺寸分布.pdf', dpi=120, bbox_inches='tight')
plt.show()
从图中可以看出500×500像素的图片最多
划分训练集和测试集
import os
import shutil
import random
import pandas as pd
# 指定数据集路径
dataset_path = 'fruit81_full'
dataset_name = dataset_path.split('_')[0]
classes = os.listdir(dataset_path)
创建训练集文件夹和测试集文件夹
# 创建 train 文件夹
os.mkdir(os.path.join(dataset_path, 'train'))
# 创建 test 文件夹
os.mkdir(os.path.join(dataset_path, 'val'))
# 在 train 和 test 文件夹中创建各类别子文件夹
for fruit in classes:
os.mkdir(os.path.join(dataset_path, 'train', fruit))
os.mkdir(os.path.join(dataset_path, 'val', fruit))
划分训练集、测试集,移动文件
test_frac = 0.2 # 测试集比例
random.seed(123) # 随机数种子,便于复现
df = pd.DataFrame()
print('{:^18} {:^18} {:^18}'.format('类别', '训练集数据个数', '测试集数据个数'))
for fruit in classes: # 遍历每个类别
# 读取该类别的所有图像文件名
old_dir = os.path.join(dataset_path, fruit)
images_filename = os.listdir(old_dir)
random.shuffle(images_filename) # 随机打乱
# 划分训练集和测试集
testset_numer = int(len(images_filename) * test_frac) # 测试集图像个数
testset_images = images_filename[:testset_numer] # 获取拟移动至 test 目录的测试集图像文件名
trainset_images = images_filename[testset_numer:] # 获取拟移动至 train 目录的训练集图像文件名
# 移动图像至 test 目录
for image in testset_images:
old_img_path = os.path.join(dataset_path, fruit, image) # 获取原始文件路径
new_test_path = os.path.join(dataset_path, 'val', fruit, image) # 获取 test 目录的新文件路径
shutil.move(old_img_path, new_test_path) # 移动文件
# 移动图像至 train 目录
for image in trainset_images:
old_img_path = os.path.join(dataset_path, fruit, image) # 获取原始文件路径
new_train_path = os.path.join(dataset_path, 'train', fruit, image) # 获取 train 目录的新文件路径
shutil.move(old_img_path, new_train_path) # 移动文件
# 删除旧文件夹
assert len(os.listdir(old_dir)) == 0 # 确保旧文件夹中的所有图像都被移动走
shutil.rmtree(old_dir) # 删除文件夹
# 工整地输出每一类别的数据个数
print('{:^18} {:^18} {:^18}'.format(fruit, len(trainset_images), len(testset_images)))
# 保存到表格中
df = df.append({'class':fruit, 'trainset':len(trainset_images), 'testset':len(testset_images)}, ignore_index=True)
# 重命名数据集文件夹
shutil.move(dataset_path, dataset_name+'_split')
# 数据集各类别数量统计表格,导出为 csv 文件
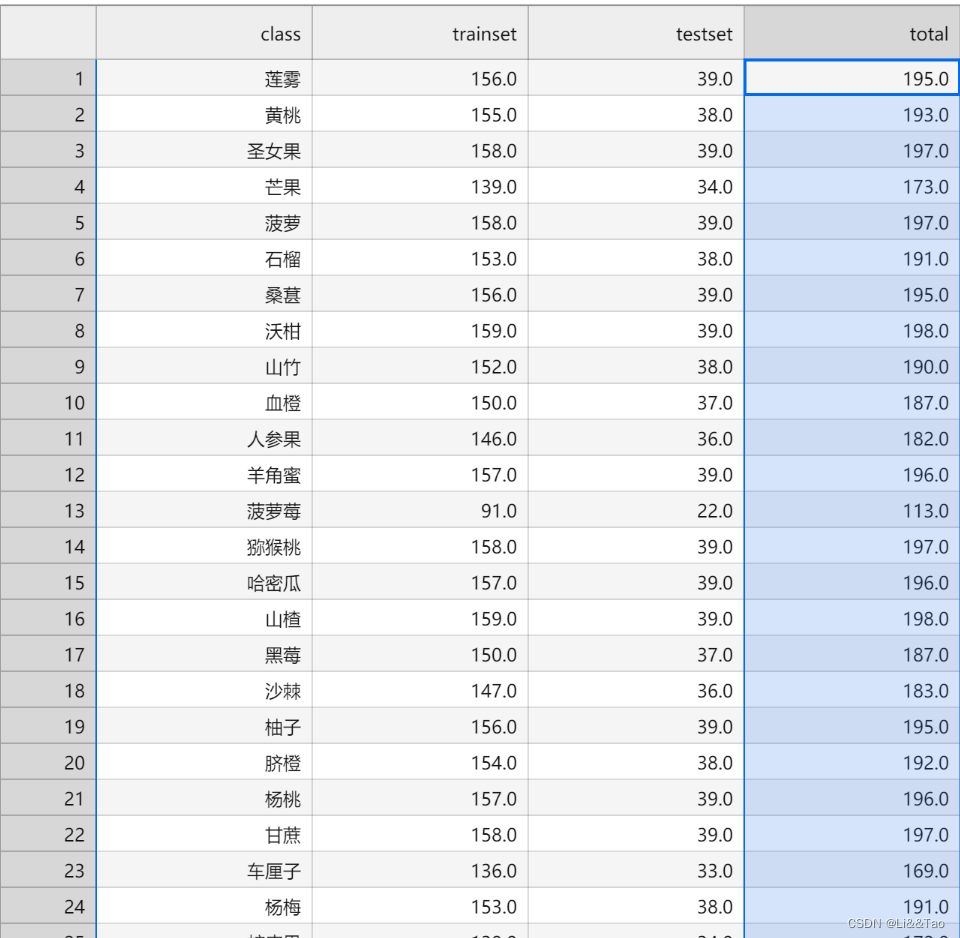
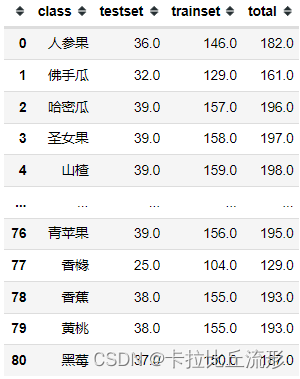
df['total'] = df['trainset'] + df['testset']
df.to_csv('数据量统计.csv', index=False)
df
统计得到的部分结果如下图所示:
可视化文件夹中的图像
这里我们可视化训练集中樱桃的图像
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from mpl_toolkits.axes_grid1 import ImageGrid
%matplotlib inline
import numpy as np
import math
import os
import cv2
from tqdm import tqdm
指定要可视化图像的文件夹
folder_path = 'fruit81_split/train/樱桃'
# 可视化图像的个数
N = 36
# n 行 n 列
n = math.floor(np.sqrt(N))
n
读取文件夹中的所有图像
images = []
for each_img in os.listdir(folder_path)[:N]:
img_path = os.path.join(folder_path, each_img)
#img_bgr = cv2.imread(img_path)
img_bgr = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), 1) #解决路径中存在中文的问题
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
images.append(img_rgb)
画图
fig = plt.figure(figsize=(6, 8),dpi=80)
grid = ImageGrid(fig, 111, # 类似绘制子图 subplot(111)
nrows_ncols=(n, n), # 创建 n 行 m 列的 axes 网格
axes_pad=0.02, # 网格间距
share_all=True
)
# 遍历每张图像
for ax, im in zip(grid, images):
ax.imshow(im)
ax.axis('off')
plt.tight_layout()
plt.show()

图像分类数据集探索统计
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# windows操作系统
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# Mac操作系统,参考 https://www.ngui.cc/51cto/show-727683.html
# 下载 simhei.ttf 字体文件
# !wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf
# Linux操作系统,例如 云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
# 运行完毕后重启 kernel,再从头运行一次
# !wget https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220716-mmclassification/dataset/SimHei.ttf -O /environment/miniconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/SimHei.ttf
# !rm -rf /home/featurize/.cache/matplotlib
# import matplotlib
# matplotlib.rc("font",family='SimHei') # 中文字体
# # plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
# plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
导入数据集
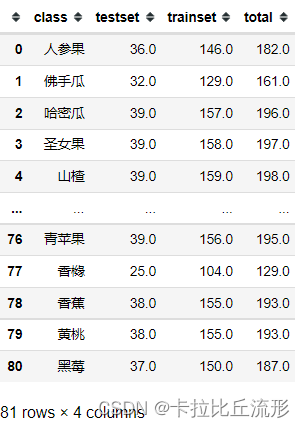
这里采用划分训练集和测试集阶段得到的表格
df = pd.read_csv('数据量统计.csv')
df
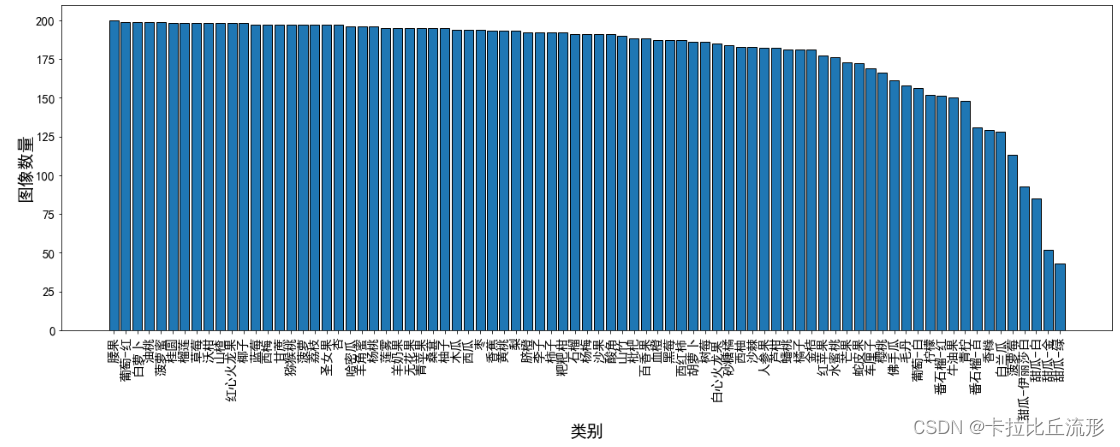
图像数量柱状图可视化
# 指定可视化的特征
feature = 'total'
# feature = 'trainset'
# feature = 'testset'
df = df.sort_values(by=feature, ascending=False)#按总数据量从高到低排序
plt.figure(figsize=(22, 7))
x = df['class']
y = df[feature]
plt.bar(x, y, facecolor='#1f77b4', edgecolor='k')
plt.xticks(rotation=90)
plt.tick_params(labelsize=15)
plt.xlabel('类别', fontsize=20)
plt.ylabel('图像数量', fontsize=20)
# plt.savefig('各类别图片数量.pdf', dpi=120, bbox_inches='tight')
plt.show()
plt.figure(figsize=(22, 7))
x = df['class']
y1 = df['testset']
y2 = df['trainset']
width = 0.55 # 柱状图宽度
plt.xticks(rotation=90) # 横轴文字旋转
plt.bar(x, y1, width, label='测试集')
plt.bar(x, y2, width, label='训练集', bottom=y1)
plt.xlabel('类别', fontsize=20)
plt.ylabel('图像数量', fontsize=20)
plt.tick_params(labelsize=13) # 设置坐标文字大小
plt.legend(fontsize=16) # 图例
# 保存为高清的 pdf 文件
plt.savefig('各类别图像数量.pdf', dpi=120, bbox_inches='tight')
plt.show()
总结
本篇文章主要讲述了构建自己图像分类数据集的步骤以及常见的问题。首先数据集的来源可以是从网上爬取的、自己拍照得到的、网上现成的数据集。对于我们得到的数据集我们可以利用Shell命令进行简单的清洗,包括删除系统自动生成的文件、gif格式图片、非三通道图片等,熟悉Linux操作可以帮助我们更好的清洗我们的数据。之后我们可以对我们的数据集进行划分、统计、可视化。