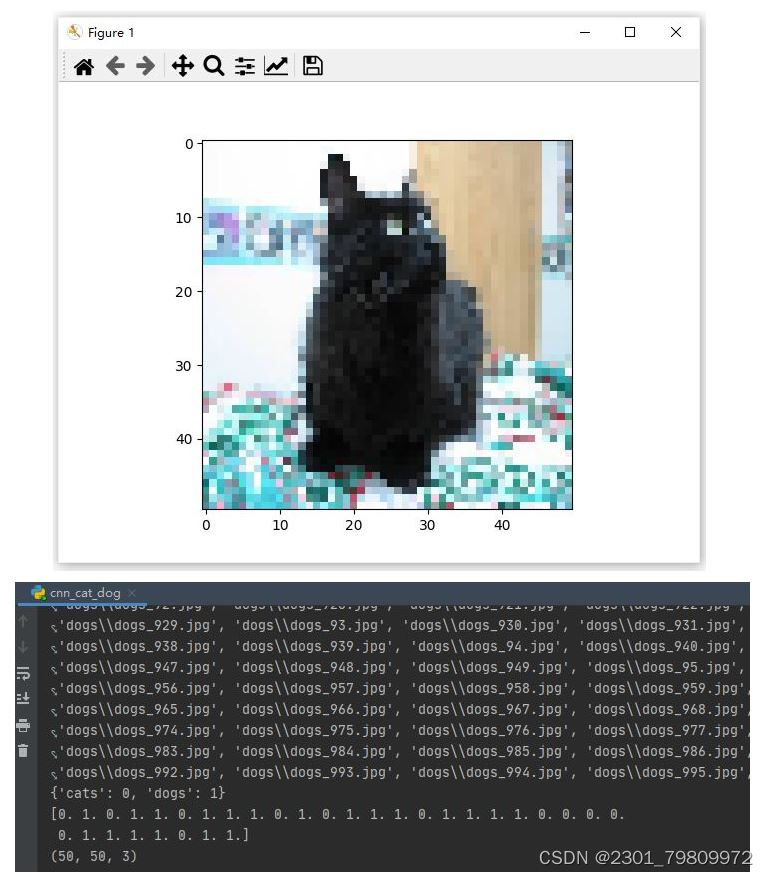
理论与python实现部分
3.1. 线性回归 — 动手学深度学习 2.0.0 documentation
c++代码
没能力实现反向传播求梯度,只能自己手动算导数了
#include <bits/stdc++.h>
#include <time.h>
using namespace std;
//y_hat = X * W + b
// linreg 函数:线性回归预测
// 参数:
// double** X: 输入数据的二维数组,其中 X[i][j] 表示第 i 个样本的第 j 个特征
// double* W: 权重向量,W[j] 表示第 j 个特征的权重
// double b: 偏置项
// int batch_size: 批量大小,即一次处理的样本数量
// int lenw: 权重向量的长度,即特征的数量
// 返回值:
// double* y_hat: 预测值的数组,长度为 batch_size
double* linreg(double** X, double* W, double b, int batch_size, int lenw)
{
// 分配内存来存储预测值
double* y_hat = new double[batch_size];
// 遍历每一个样本
for (int i=0; i<batch_size; i++)
{
double sum=0; // 求和计算 X * W
// 遍历每一个特征
for (int j=0; j<lenw; j++)
{
// 累加该样本的每个特征与对应权重的乘积
sum += X[i][j]*W[j];
}
// 加上偏置项得到最终的预测值
y_hat[i] = sum+b;
}
// 返回预测值的数组
return y_hat;
}
// squared_loss 函数:计算平方损失
// 参数:
// double* y_hat: 预测值的数组
// double* y: 实际值的数组
// int len: 预测值和实际值的长度(应相同)
// 返回值:
// double* l: 平方损失的数组,长度为 len
double* squared_loss(double* y_hat, double* y, int len)
{
// 分配内存来存储平方损失
double* l = new double[len];
// 遍历每一个预测值与实际值
for (int i=0; i<len; i++)
{
// 计算平方损失 (y_hat[i]-y[i])^2 的一半(常用在损失函数中)
l[i] = 0.5 * (y_hat[i]-y[i]) * (y_hat[i]-y[i]);
}
// 返回平方损失的数组
return l;
}
// sum 函数:计算数组的和
// 参数:
// double* l: 需要求和的数组
// int len: 数组的长度
// 返回值:
// double ans: 数组的和
double sum(double* l, int len)
{
double ans=0; // 初始化和为0
for (int i=0; i<len; i++)
{
ans += l[i]; // 累加数组中的每一个元素
}
return ans; // 返回数组的和
}
// sgd 函数:使用随机梯度下降(Stochastic Gradient Descent)算法更新权重和偏置项
// 参数:
// double** X: 输入数据的二维数组,其中 X[i][j] 表示第 i 个样本的第 j 个特征
// double* y: 实际值的数组,与输入数据一一对应
// double* W: 权重向量,W[j] 表示第 j 个特征的权重
// double &b: 偏置项的引用,以便在函数内部修改其值
// int lenw: 权重向量的长度,即特征的数量
// double lr: 学习率(Learning Rate),用于控制权重更新的步长
// int batch_size: 批量大小,即一次处理的样本数量
// 返回值:
// 无返回值,但会直接修改 W 和 b 的值
/*
y_hat = X * W + b
loss = 0.5 * (y_hat - y) * (y_hat - y)
d(loss)/d(y_hat) = y_hat - y
d(y_hat)/d(W) = X
d(y_hat)/d(b) = 1
∴ d(loss) / d(W) = d(loss)/d(y_hat) * d(y_hat)/d(W) = (y_hat - y) * X
d(loss) / d(b) = d(loss)/d(y_hat) * d(y_hat)/d(b) = (y_hat - y) * 1
*/
void sgd(double** X, double* y, double* W, double &b, int lenw, double lr, int batch_size)
{
// 调用 linreg 函数获取预测值
double* y_hat = linreg(X, W, b, batch_size, lenw);
// 计算每个权重的梯度
for (int i=0; i<lenw; i++)
{
double grad=0;// 初始化当前权重的梯度为0
for (int j=0; j<batch_size; j++)
{
// 计算梯度:每个样本的梯度为该样本的特征值与预测误差的乘积
grad += X[j][i]*(y_hat[j]-y[j]);
}
// 更新权重:使用学习率乘以平均梯度(梯度之和 除以batch_size),并从当前权重中减去
W[i] = W[i] - lr * grad / batch_size;
}
// 计算偏置项的梯度
double grad=0; // 初始化偏置项的梯度为0
for (int j=0; j<batch_size; j++)
{
// 计算梯度和:所有样本的预测误差之和
grad += (y_hat[j]-y[j]);
}
// 更新偏置项:使用学习率乘以平均梯度(除以batch_size),并从当前偏置项中减去
b = b - lr * grad / batch_size;
// 释放预测值数组的内存
delete[] y_hat;
}
int main()
{
// 设定真实的权重和偏置项,用于比较训练结果
const double true_w[] = {3.3, -2.4}, true_b = 11.4;
// 设定权重向量的长度
const int lenw=2;
// 初始化权重和偏置项
double w[lenw] = {0, 0}; // 理论上应该可以为任意值
double b=0.0;
// 设定样本数量
int sample_num=2000;
// 分配二维数组内存用于存储特征数据
double** X = new double*[sample_num];
for (int i=0; i<sample_num; i++) X[i] = new double[lenw];
// 分配一维数组内存用于存储实际标签
double y[sample_num];
// 打开数据文件datas.txt并读取特征数据和标签
// 单行数据格式 x1 x2 x3 ... xn y
freopen("datas.txt", "r", stdin);
for (int i=0; i<sample_num; i++)
{
for (int j=0; j<lenw; j++)
{
scanf("%lf", &X[i][j]); // 读取特征值
}
scanf("%lf", &y[i]); // 读取标签
}
// 关闭数据文件,并重新打开标准输入
freopen("CON", "r", stdin);
// 设定学习率、迭代次数和批量大小
double lr = 0.03;
int num_epochs = 800;
// 将数据集分成50个批次
int batch_size = sample_num/50;
double* (*net) (double**, double*, double, int, int);
double* (*loss) (double*, double*, int);
net = linreg;// 函数指针,没啥实际用处
loss = squared_loss;
time_t st=clock();
// 迭代训练模型
for (int epoch=0; epoch < num_epochs; epoch++)
{
// 计算当前批次的预测值
double* y_hat = net(X, w, b, batch_size, lenw);
// 计算当前批次的损失
double loss1 = sum(loss(y_hat, y, batch_size), batch_size);
// 使用随机梯度下降更新权重和偏置项
// 如果不需要输出查看训练过程的损失,每次迭代其实只需要sgd函数就可以完成训练(即参数 w 和 b 的更新)
sgd(X, y, w, b, lenw, lr, batch_size);
// 计算整个数据集的预测值
double* y1_hat = linreg(X, w, b, sample_num, lenw);
// 计算整个数据集的损失
double loss2 = sum(loss(y1_hat, y, sample_num), sample_num);
// 每50个迭代周期打印一次训练损失
if (epoch%50 == 0)
printf("in epoch %d, train loss is %lf\n", epoch+1, loss2/sample_num);
// 释放当前批次和整个数据集预测值的内存
delete[] y_hat;
delete[] y1_hat;
}
// 设定测试样本数量
int test_num=30;
// 分配二维数组内存用于存储测试数据
double** test_X = new double*[test_num];
for (int i=0; i<test_num; i++) test_X[i] = new double[lenw];
// 分配一维数组内存用于存储测试标签
double test_y[test_num];
// 打开测试数据文件tests.txt并读取测试数据和标签
freopen("tests.txt", "r", stdin);
for (int i=0; i<test_num; i++)
{
for (int j=0; j<lenw; j++)
{
scanf("%lf", &test_X[i][j]); // 读取测试特征值
}
scanf("%lf", &test_y[i]); // 读取测试标签
}
// 关闭测试数据文件,并重新打开标准输入
freopen("CON", "r", stdin);
// 计算测试集的预测值
double* test_y_hat = linreg(test_X, w, b, test_num, lenw);
// 计算测试数据的损失值
double loss2 = sum(squared_loss(test_y_hat, test_y, test_num), test_num);
// 计算测试数据的平均损失值
double loss_mean = loss2 / test_num;
printf("in test, loss is %lf\n", loss_mean);
printf("w is ");
for (int i=0; i<lenw; i++) printf("%lf%c", w[i], i==(lenw-1)?'\n':' ');
printf("b=%lf\n", b);
printf("true_w is {3.3, -2.4}, true_b is 11.4\n");
time_t ed=clock();
printf(" %d epoch, time %d ms\n", num_epochs, ed-st);
// 注意:这里还需要释放test_X数组的内存,以及之前分配的X数组的内存
// 释放test_X数组的内存
for (int i = 0; i < test_num; i++) {
delete[] test_X[i];
}
delete[] test_X;
// 释放X数组的内存(注意:这部分代码应在前面的循环之后添加)
for (int i = 0; i < sample_num; i++) {
delete[] X[i];
}
delete[] X;
}训练效果
和pytorch的训练效果对比






![Rabbitmq 搭建使用案例 [附源码]](https://img-blog.csdnimg.cn/direct/b9f98d491d284ba392c6f3ba1d3bacda.png)