1 论文回顾
-
基本思路

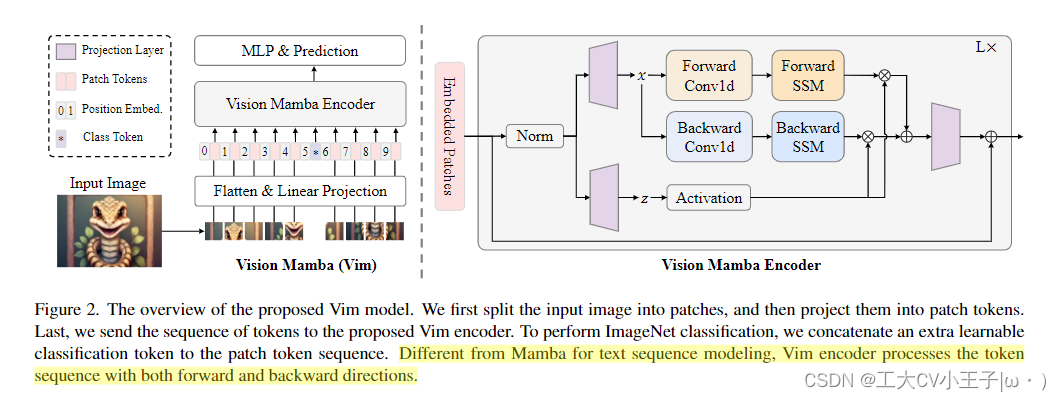
论文解读见:
《VideoMamba》论文笔记_video mamba-CSDN博客
-
注意
- Vision Mamba和VIT的输入和输出的shape的形状是相同的(VIT基于Transformer的Encoder设计,输入经过多层MHA和MLP计算,输入和输出的形状相同,Mamba的SSM架构就可以做到输入与输出token的个数以及每个token的维度相同,自然也可以做到整个输入和输出的形状相同,再者Vision Mamba的设计参照VIT的结构,自然也要注意输入与输出形状相同。两者的输入流经过各自对应的Encoder之后都具备了上下文信息,其效果相同,效率上基于Mamba的模型会更胜一筹。
- 正如1所说,Vision Mamba的设计参照VIT,这两个工作的流程是相同的,这里主要指的是图片打patch 再concat上class token再加上Position Embedding这个流程,两个模型唯一不同的地方就是Emcoder部分的不同,VIT使用的是Transformer的Encoder,Vim使用的是Mamba的Encoder,二者都是用于token间信息交互,上下文建模的
2 环境配置
按照官方readme.md配置,如果有问题照着下面这个链接改
vision mamba 运行训练记录,解决bimamba_type错误-CSDN博客
值得说明的一点是,如果你之前在跑其他的mamba,环境拿过来是不能直接直接用的,因为标准的Mamba类是没有bimamba_type这个参数的,

所以,需要去Vim代码官网去找到mamba-1p1p1包,下载之后放自己项目里
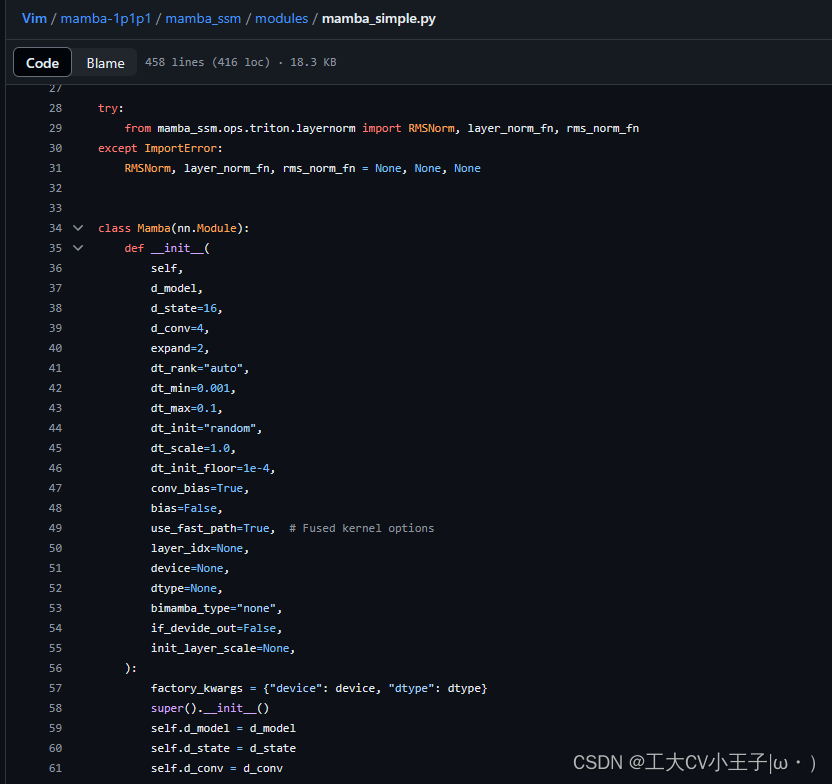
事实上Vision Mamba重写了这个Mamba类,可以看到里边是由bimamba_type这个参数的(这其实也是Vision Mamba的主要贡献),执行如下代码
cp -rf mamba-1p1p1/mamba_ssm /home/liyhc/anaconda3/envs/mamba/lib/python3.10/site-packages
#后边是系统的mamba的安装路径,自己照着自己环境mamba的安装路径进行修改3 代码笔记
3.1 代码链接
官方代码链接
Vim/vim/models_mamba.py at main · hustvl/Vim (github.com)
我手敲的带中文注释的链接
Johnny-Haytham/Vim: Vim with chinese notation (github.com)
3.2 Module
3.2.1 PatchEmbed
class PatchEmbed(nn.Module):
def __init__(self, img_size=224,patch_size=16,stride=16,in_channels=3,embed_dim=768,norm_layer=None,flatten=True):
super(PatchEmbed, self).__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)#将img_size和patch_size化成元组的形式
self.img_size = img_size
self.patch_size = patch_size
#一个patch形成一个grid(网格),这里记录网格的形状
self.grid_size = ((img_size[0] - patch_size[0]) // stride + 1 , (img_size[1] - patch_size[1]) // stride + 1)
self.num_patches = self.grid_size[0] * self.grid_size[1]#总共的patch个数
self.flatten = flatten
#打patch的操作,实际为卷积的操作(为了不重复卷积,步长的大小理论上因该等于卷积核的大小)
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=stride)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()#nn.Identity的输入等于输出,通常作为占位层使用
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1],\
f"Input img size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})"
x = self.proj(x)#B,C,H,W——>B,embed_dim,grid_size,grid_size
if self.flatten:
x = x.flatten(2).transpose(1, 2)#B,embed_dim,grid_size,grid_size——>B,embed_dim,grid_size*grid_size——>B,grid_size*grid_size,embed_dim
x = self.norm(x)
return x
3.2.2 Vim Encoder Block
class Block(nn.Module):
def __init__(
self, dim, mixer_cls,
norm_cls = nn.LayerNorm,
fused_add_norm=False,residual_in_fp32=False,drop_path=0.
):
super(Block, self).__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.mixer = mixer_cls(dim)#这其实是Mamba的部分固定参数的调用
self.norm = norm_cls(dim)
self.drop_path = DropPath(drop_path)
if self.fused_add_norm:
assert RMSNorm is not None,"RMSNorm import Fails"
assert isinstance(
self.norm, (nn.LayerNorm, RMSNorm)
),"Only LayerNorm and RMSNorm are supported for fused_add_norm"
def forward(self,
hidden_states: Tensor,#上一个时间状态的输出,也就是ht-1
residual: Optional[Tensor]=None,
inference_params = None):
if not self.fused_add_norm:#如果fused_add_norm为False
if residual is None:#如果残差为空,这个是if用于第一个block处理输入数据
residual = hidden_states
else:#如果残差不为空,这个if用于处理除了第一个block以外的所有block的操作
residual = residual + self.drop_path(self.mixer(hidden_states))
# 将residual的数据类型转化为self.norm.weight.dtype,将residual归一化后保存为hidden_states
hidden_states = self.norm(residual.to(dtype=self.norm.weight.dtype))
if self.residual_in_fp32:#如果指定self_residual的类型是float32的话
residual = residual.to(torch.float32)
else:#如果fused_add_norm不为False
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm, RMSNorm) else layer_norm_fn
if residual is None:#如果残差为空,这个是if用于第一个block处理输入数据
hidden_states,residual = fused_add_norm_fn(
hidden_states,
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
else:#如果残差不为空,这个if用于处理除了第一个block以外的所有block的操作
hidden_states,residual = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm.weight,
self.norm.bias,
residual=residual,
prenorm=True,
residual_in_fp32=self.residual_in_fp32,
eps=self.norm.eps,
)
hidden_states = self.mixer(hidden_states,inference_params=inference_params)
return hidden_states, residual
def create_block(
d_model, #token维度
ssm_cfg=None, #ssm模型的配置文件
norm_epsilon=1e-5, #
drop_path=0.,
rms_norm=False,
residual_in_fp32=False,
fused_add_norm=False,
layer_idx=None,
device=None,
dtype=None,
if_bimamba=False, #是否使用双向mamba扫描
bimamba_type="none",
if_devide_out=False,
init_layer_scale=None,
):
if if_bimamba:#如果使用双向mamba扫描
bimamba_type = "v1" #这是一个模型的版本号
if ssm_cfg is None:
ssm_cfg = {}
factory_kwargs = {"device": device, "dtype": dtype}
mixer_cls = partial( #代表着VIM Encoder对class token的拼接方式,cls token可以拼接到不同位置(所有token前面,所有token中间,...或是随机位置)
Mamba,
layer_idx=layer_idx,
bimamba_type=bimamba_type,
if_devide_out=if_devide_out,
init_layer_scale=init_layer_scale,
**ssm_cfg,
**factory_kwargs
)
norm_cls=partial( #对于class token的normalization函数
nn.LayerNorm if not rms_norm else RMSNorm,eps=norm_epsilon,**factory_kwargs
) #eps用于避免归一化过程中分母为0的情况
block =Block(
d_model,
mixer_cls,
norm_cls=norm_cls,
drop_path=drop_path,
fused_add_norm=fused_add_norm,
residual_in_fp32=residual_in_fp32,
)
block.layer_idx = layer_idx
return block
3.3 Vision Mamba整体
class VisionMamba(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
stride=16,
depth=24, #需要构造的block的个数
embed_dim=192,
channels=3,
num_classes=1000, #这里用imagenet做分类任务所以有1000个类,也就代表了最后的mlp的输出层包含1000个节点
ssm_cfg=None, #ssm的配置文件
drop_rate=0., #drop_rate是针对于dropout的频率(对某个节点进行失活的操作)
drop_path_rate=0.1, #drop_path_rate是针对drop_path的频率(对某个层进行失活的操作)
norm_epsilon:float=1e-5,
rms_norm:bool=False, #是否使用rms_norm这种方法
fused_add_norm=False,
residual_in_fp32=False, #残差链接的时候是不是浮点型
device=None,
dtype=None,
pt_hw_seq_len=14, #代表sequence的长度
if_bidirectional=False,
final_pool_type='none', #最后池化层的类型
if_abs_pos_embed=False, #在位置编码的时候是不是需要用绝对值编码(有两种位置编码方式:1、直接给出的绝对值位置编码 2、可学习的位置编码)
if_rope=False, #rope也是一种对positionembeding的特殊编码方式
if_rope_residual=False, #对 residual的rope 旨在增加鲁棒性
flip_img_sequences_ratio=-1., #image_squence的反转概率
if_bimamba=False,
bimamba_type="none", #表示使用的mamba的版本
if_cls_token=False, #拼不拼clstoken
if_devide_out=False,
init_layer_scale=None,
use_double_cls_token=False,
use_middle_cls_token=False,
**kwargs): #为了保证模型的可扩展性所以加一个**kwargs
factory_kwargs = {"device": device, "dtype": dtype}
# add factory_kwargs into kwargs
kwargs.update(factory_kwargs)
super(VisionMamba,self).__init__()
self.residual_in_fp32 = residual_in_fp32
self.fused_add_norm = fused_add_norm
self.if_bidirectional = if_bidirectional
self.final_pool_type = final_pool_type
self.if_abs_pos_embed = if_abs_pos_embed
self.if_rope = if_rope
self.if_rope_residual = if_rope_residual
self.flip_img_sequences_ratio = flip_img_sequences_ratio
self.if_cls_token = if_cls_token
self.use_double_cls_token = use_double_cls_token #这个拼接clstoken的方式是头拼一个尾拼一个
self.use_middle_cls_token = use_middle_cls_token #这个拼接clstoken的方式是中间拼一个
self.num_tokens = 1 if if_cls_token else 0 #表示拼了几个cls token进去?存疑
# pretrain parameters
self.num_classes = num_classes
self.d_model = self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, stride=stride, in_channels=channels, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
if if_cls_token: #如果使用cls token的话
if use_double_cls_token:
self.cls_token_head = nn.Parameter(torch.zeros(1, 1, self.embed_dim))#拼在token序列最前面的clstoken
self.cls_token_tail = nn.Parameter(torch.zeros(1, 1, self.embed_dim))#拼在token序列最后面的clstoken
self.num_tokens = 2 #代表了拼了几个cls token
else:
self.cls_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
# self.num_tokens = 1
if if_abs_pos_embed: #如果使用给定的位置编码(给定绝对值)
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, self.embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
#if if_rope: #Rope(Rotary Position Embedding)对于Position Embedding的翻转操作,(数据增强操作)
# half_head_dim = embed_dim // 2
# hw_seq_len = img_size // patch_size #高/宽方向的序列长度
# self.rope = VisionRotaryEmbeddingFast(
# dim=half_head_dim,
# pt_seq_len=pt_hw_seq_len,
# ft_seq_len=hw_seq_len
# )
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity() #这个是最终的分类头
#drop path rate 随机失活一些东西,目的是让模型的鲁棒性更强,效果更好
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] #构建从start到end的等距张量,目的是为每层网络设置独立的drop_path_rate
inter_dpr = [0.0] +dpr #第一层不需要dropout,所以要在最开始拼个0
self.drop_path = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
self.layers = nn.ModuleList(
[
create_block(#对VisionMamba的Encoder进行初始化的操作
embed_dim,
ssm_cfg=ssm_cfg,
norm_epsilon=norm_epsilon,
rms_norm=rms_norm,
residual_in_fp32=residual_in_fp32,
fused_add_norm=fused_add_norm,
layer_idx=i,
if_bimamba=if_bimamba,
bimamba_type=bimamba_type,
drop_path=inter_dpr[i],
if_devide_out=if_devide_out,
init_layer_scale=init_layer_scale,
**factory_kwargs
)
for i in range(depth)
]
)
self.norm_f = (nn.LayerNorm if not rms_norm else RMSNorm)(embed_dim, eps=norm_epsilon,**factory_kwargs)
#trunc_normal_函数是一个用于对张量进行截断正态分布初始化的函数。它通常用于初始化神经网络的权重或偏置。
if if_abs_pos_embed:
trunc_normal_(self.pos_embed, std=.02)
if if_cls_token:
if use_double_cls_token:
trunc_normal_(self.cls_token_head, std=.02)
trunc_normal_(self.cls_token_tail, std=.02)
else:
trunc_normal_(self.cls_token, std=.02)
#定义前向特征传播的方法
def forward_features(self, x,inference_params=None,
if_random_cls_token_position=False,
if_random_token_rank=False):
x = self.patch_embed(x)
B, M, _ = x.shape
if self.if_cls_token:
if self.use_double_cls_token: #在序列前后拼double_cls_token
cls_token_head = self.cls_token_head.expand(B, -1, -1)#expend 是共享内存的拓展 并不是创建新的张量
cls_token_tail = self.cls_token_tail.expand(B, -1, -1)
token_position = [0, M+1]
x = torch.cat((cls_token_head, x, cls_token_tail), dim=1)
M = x.shape[1]
else:
if self.use_middle_cls_token:
cls_token = self.cls_token.expand(B, -1, -1)
token_position =M//2
x = torch.cat((x[:,:token_position,:], cls_token, x[:,token_position:,:]), dim=1)
elif if_random_cls_token_position:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = random.randint(0,M)
x = torch.cat((x[:,:token_position,:], cls_token, x[:,token_position:,:]), dim=1)
print("token_position: ", token_position)
else:
cls_token = self.cls_token.expand(B, -1, -1)
token_position = 0
x = torch.cat((cls_token, x), dim=1)
M = x.shape[1]
if self.if_abs_pos_embed:
x= x+self.pos_embed
x = self.pos_drop(x)
if if_random_token_rank:#是否要把所有的token序列打乱,如果打乱了的话自然要更新存储clstoken的位置
#生成随机 shuffle索引
shuffle_indices = torch.randperm(M)#torch.randperm(M)是用于生成一个从0到M-1的随机排列的整数序列的函数。
if isinstance(token_position, list):
print("original value: ",x[0, token_position[0],0], x[0, token_position[1],0])
else:
print("original value: ",x[0, token_position,0])
print("original token_position: ", token_position)
#执行shuffle
x = x[:, shuffle_indices, :]
if isinstance(token_position, list):
new_token_position = [torch.where(shuffle_indices == token_position[i])[0].item() for i in range(len(token_position))]
token_position = new_token_position
else:
token_position = torch.where(shuffle_indices == token_position)[0].item()
if isinstance(token_position, list):
print("new value: ", x[0, token_position[0],0], x[0, token_position[1],0])
else:
print("new value: ", x[0, token_position, 0])
print("new token_position: ", token_position)
if_flip_img_suquences = False
if self.flip_img_sequences_ratio > 0 and (self.flip_img_sequences_ratio - random.random()) >1e-5:
x=x.flip([1])#会创建一个与张量 x 的形状相同的新张量,其中第一个维度的元素被翻转。翻转是指将第一个维度中的元素按相反的顺序重新排列。
if_flip_img_suquences = True
#mamba的整体部分
residual = None
hidden_states = x
if not self.if_bidirectional:#只使用单向扫描(所以单向扫描就既可以选择正向单向扫描进行rope,也可以选择反向单项扫描进行rope)
for layer in self.layers:
if if_flip_img_suquences and self.if_rope:#反转序列并使用加强版的position Embedding
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
#rope about
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residuals:
residual = self.rope(residual)
if if_flip_img_suquences and self.if_rope:#这里并不是跟上上段代码重复,而是filp了之后要再反转过来
hidden_states = hidden_states.flip([1])
if residual is not None:
residual = residual.flip([1])
hidden_states, residual = layer(
hidden_states, residual, inference_params=inference_params,
)
else:#如果采用双向扫描
for i in range(len(self.layers)//2):
if self.if_rope:
hidden_states = self.rope(hidden_states)
if residual is not None and self.if_rope_residuals:
residual = self.rope(residual)
hidden_states_f, residual_f = self.layers[i * 2](
hidden_states, residual, inference_params=inference_params
)
hidden_state_b, residual_b = self.layers[i * 2 + 1](
hidden_states.flip([1]),None if residual is None else residual.flip([1]),inference_params=inference_params
)
hidden_states = hidden_states_f + hidden_state_b.flip([1])
residual = residual_f + residual_b.flip([1])
if not self.fused_add_norm:#如果不使用fused_add_norm
if residual is None:#如果残差为空
residual = hidden_states
else:#如果残差不为空
residual = residual + self.drop_path(hidden_states)
hidden_states = self.norm_f(residual.to(dtype=self.norm_f.weight.dtype))
else:
fused_add_norm_fn = rms_norm_fn if isinstance(self.norm_f,RMSNorm) else layer_norm_fn
hidden_states = fused_add_norm_fn(
self.drop_path(hidden_states),
self.norm_f.weight,
self.norm_f.bias,
eps=self.norm_f.eps,
residual=residual,
prenorm=False,
residual_in_fp32=self.residual_in_fp32,
)
# return only cls token if it exists
if self.if_cls_token:
if self.use_double_cls_token:
return (hidden_states[:,token_position[0],:] + hidden_states[:,token_position[1],:]) / 2
else:
if self.use_middle_cls_token:
return hidden_states[:,token_position,:]
elif if_random_cls_token_position:
return hidden_states[:,token_position,:]
else:
return hidden_states[:,token_position,:]
if self.final_pool_type == 'none':
return hidden_states[:,-1,:]#这个切片是为了之后的mlp所做出的妥协
elif self.final_pool_type == 'mean':
return hidden_states.mean(dim=1)
elif self.final_pool_type == 'max':
return hidden_states
elif self.final_pool_type == 'all':
return hidden_states
else:
raise NotImplementedError
def forward(self,x,return_features=False,inference_params=None,if_random_cls_token_position=False,if_random_token_rank=False):
x = self.forward_features(x,inference_params,if_random_cls_token_position = if_random_cls_token_position,if_random_token_rank = if_random_token_rank)
if return_features:
return x
x = self.head(x)
if self.final_pool_type == 'max':
x = x.max(dim=1)[0]
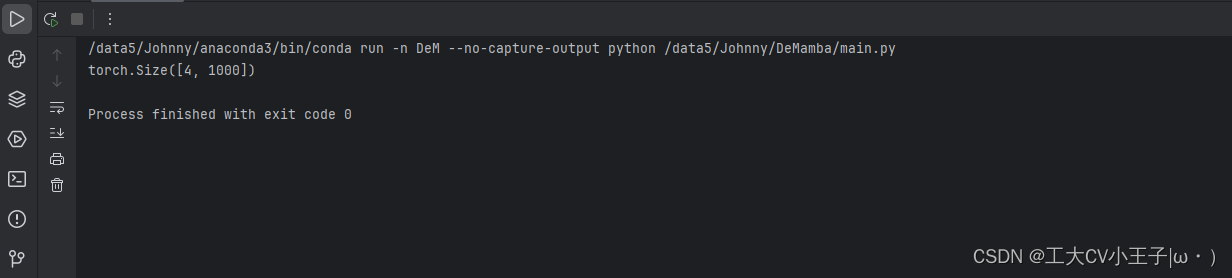
return x3.4 测试
def test():
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = VisionMamba(
patch_size=16,
embed_dim=192,
depth=24,
rms_norm=True,
residual_in_fp32=True,
fused_add_norm=True,
final_pool_type='mean',
if_abs_pos_embed=True,
if_rope=False,
if_rope_residual=False,
bimamba_type="V2",
if_cls_token=True,
if_device_out=True,
use_double_cls_token=True
).to(device)
x = torch.randn(size=(4,3,224,224)).to(device)
preds = model(x)
print(preds.shape)
if __name__ == '__main__':
test()3.5 输出
参考文献
下个风口?Mamba手推公式&代码手搓_哔哩哔哩_bilibili