基础多线程:
UE4中的多线程模型主要基于FRunnable和FRunnableThread两个核心概念。其中,FRunnable定义了一个可以在线程上运行的对象,而FRunnableThread则提供了一个平台无关的线程对象抽象,负责驱动FRunnable对象的初始化、执行和清理。
一、FRunnable的生命周期管理
- 初始化(Init):当一个FRunnable实例被创建并准备执行时,首先需要调用其Init方法进行初始化。这个过程通常涉及资源的分配、状态的设置等,确保线程在执行前处于正确的状态。
- 运行(Run):FRunnable的Run方法是线程执行的核心,它包含了线程需要完成的任务或计算。这个方法的设计旨在确保线程能够高效地完成其工作,同时避免阻塞其他线程。
- 停止(Stop):如果需要提前终止线程的执行,可以调用Stop方法。这个方法允许线程安全地结束其操作,释放资源,并确保应用程序的稳定运行。
- 退出处理(Exit):一旦FRunnable的Run方法执行完毕,无论是正常结束还是通过Stop方法强制终止,都会调用Exit方法进行清理工作,如释放内存、关闭打开的句柄等,保证资源的合理释放。
二、FRunnableThread的线程管理
- 线程创建(Create):通过FRunnableThread的Create方法,可以创建一个新的线程并开始执行指定的FRunnable对象。这个过程包括分配线程堆栈、设置线程属性等,确保新线程能够正确地运行。
- 线程控制:UE4提供了一套丰富的线程控制机制,包括暂停(Suspend)、恢复(Resume)、杀死(Kill)等方法,允许开发者根据需要精确地控制线程的行为。这些方法为调试和错误恢复提供了极大的便利。
- 线程同步:为了确保线程间数据的一致性和避免竞争条件,UE4支持多种同步原语,如锁(Lock)、信号量(Semaphore)和原子操作(AtomicOperations)。这些工具帮助开发者构建高度并行且线程安全的应用。
- 线程局部存储(TLS):UE4还支持线程局部存储,允许每个线程拥有其独立的数据副本。这对于提高多线程程序的性能和模块化非常有帮助,因为它减少了线程间的数据共享和竞争。
三、与C++标准库的互操作性
- 模型映射:尽管UE4采用了独特的FRunnable和FRunnableThread模型,但它们与C++标准库中的std::thread(基于Callable和Thread)是可以相互转换的。这种映射关系使得UE4的多线程功能既可以利用引擎特有的优化,又能保持与标准C++代码的良好兼容性。
- 功能实现:通过UE4提供的设施,开发者可以实现类似std::thread的功能,反之亦然。这意味着开发者可以根据自己的喜好和项目需求选择使用UE4的原生多线程接口或是标准库中的对应功能。
- 性能考量:在选择使用UE4的多线程模型还是C++标准库时,性能是一个重要因素。虽然UE4的模型在游戏开发中经过了特别优化,但标准库的通用性可能在非游戏应用中更具优势。因此,开发者需要根据具体场景做出恰当的选择。
- 代码移植性:为了确保代码具有良好的移植性和可维护性,开发者应当在编写多线程代码时考虑到两种模型的差异。理想情况下,代码应当足够模块化,以便能够在最少修改的情况下从一种模型迁移到另一种模型。
四、 AsyncTask系统
- 基于线程池:UE4中的AsyncTask系统是基于线程池的概念构建的,允许开发者轻松地执行后台异步任务,而不需要直接处理线程的创建和销毁。
- FNonAbandonableTask:这是所有异步任务类的基类,通过继承这个类并实现DoWork()方法,可以定义异步任务的具体行为。
- 使用示例:文章提供了一个ExampleAsyncTask的代码示例,展示了如何创建和使用异步任务。这包括任务的启动、同步和异步执行以及如何确保任务完成。
- 线程池实现:FQueuedThreadPool是UE4中线程池的实现,维护了一组工作线程和任务队列。这种结构优化了线程的使用,减少了线程创建和销毁的开销。
五、 TaskGraph系统
- 从Tick函数谈起:TaskGraph系统紧密集成于UE4的主循环(Tick函数)中,允许在每帧更新时安排和执行任务。
- 任务与线程:系统中的任务(如渲染、物理计算等)可以自动分配到可用的线程上执行,提高了引擎的并行处理能力。
- 任务与事件:TaskGraph还支持基于事件的异步任务执行模式,这允许更复杂的依赖性和执行顺序管理。
- 技术细节:虽然文章没有深入讨论TaskGraph的内部机制,但它显然是一个高度复杂和强大的系统,旨在最大化UE4引擎的性能和响应性。
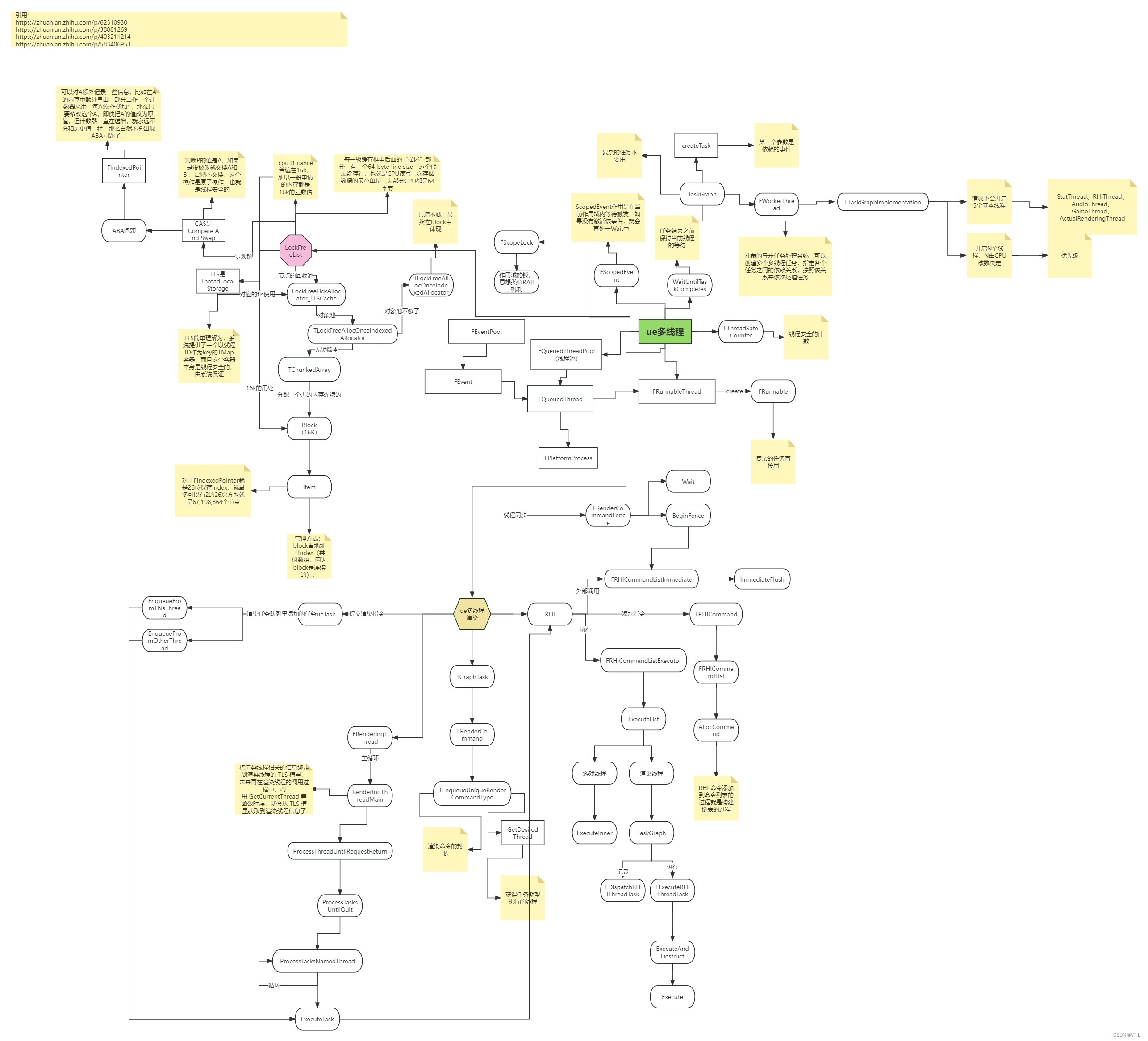
六、LockFreeList
-
容器设计初衷
- 问题解决:传统的TQueue存在一些问题,如内存分配效率低、不支持多生产者多消费者模式以及伪共享问题。这些问题在高并发场景下尤为明显,因此UE需要一种更高效的数据结构来支持其复杂的多线程需求。
- 性能优化:LockFreeList通过使用锁自由(lock-free)算法,避免了传统锁定机制带来的性能损耗,特别是在高并发的情况下。
-
核心组件
- 节点与回收池:LockFreeList定义了特定的节点结构,并实现了一个节点回收池。这种设计可以有效减少内存碎片和提高内存使用效率。
- 专用Allocator:为了进一步优化内存分配,LockFreeList使用了专用的内存分配器(Allocator),这有助于避免内存碎片,确保数据的连续存储,从而提高缓存命中率。
-
数据结构实现
- 基本容器类型:实现了栈和队列两种基本的容器类型,这些都是构建更复杂数据结构的基础。
- 扩展容器:基于栈和队列,LockFreeList还实现了FStallingTaskQueue等专为TaskGraph设计的容器,以及TClosableLockFreePointerListUnorderedSingleConsumer等更复杂的容器类型。
-
多线程知识应用
- CPU缓存利用:LockFreeList在设计时充分考虑了CPU缓存的行为,例如通过预分配特定大小的数据块来对齐CPU缓存行,从而减少缓存未命中的情况。
- 避免伪共享:通过在数据结构中添加适当的填充(padding),确保不同线程访问的数据不会位于同一缓存行上,从而避免伪共享问题。
-
原子操作与CAS
- Compare And Swap (CAS):LockFreeList广泛使用了CAS操作来实现线程安全的数据处理。这种非阻塞式的编程技术允许在不使用锁的情况下安全地更新数据。
- ABA问题处理:通过引入计数器或其他状态信息,LockFreeList能够有效地识别并处理ABA问题,确保数据的一致性和完整性。
-
TLS的使用
- 线程局部存储 (TLS):在某些情况下,LockFreeList利用TLS来存储线程独有的数据,这样可以在不增加额外同步开销的情况下保证线程安全。
Unreal多线程渲染:
UE的多线程渲染源码执行流程非常复杂且高度优化
1. 背景和目标
- 瓶颈问题: 在单线程渲染中,CPU很容易成为性能瓶颈,尤其是在处理重负载的场景(如包含大量人物、汽车和建筑的大型游戏场景)时。
- 并行性提升: 为了充分利用现代硬件(尤其是GPU)的性能,UE5设计了一种新的多线程渲染架构,旨在通过提升渲染过程的并行性来解决这一问题。
2. 多线程RHI命令的生成和翻译
- 命令生成: UE5中的RHI(Render Hardware Interface)命令生成过程是多线程的,这允许同时利用多个CPU核心来生成渲染命令,从而提高整体渲染效率。
- 命令翻译: 这些命令还需要被有效地翻译为GPU可以执行的指令,这一步骤同样在多线程环境中完成,以确保命令的快速和准确转化。
3. RHI资源的创建和更新
- 资源优化: 在UE5中,RHI资源的创建和更新也是多线程的,这样可以减少这些操作对主线程的影响,从而减轻主线程的负担,使其能够更快地响应其他任务。
4. RHI线程的引入
- 专用RHI线程: UE5引入了一个单独的RHI线程,专门用于执行RHI命令。这样做的目的是让渲染线程专注于渲染逻辑(例如裁剪和场景设置),而将实际的渲染命令执行交由RHI线程处理。
- 异步执行: 这种设计不仅提高了渲染效率,而且通过异步执行RHI命令,减少了对渲染线程的阻塞,使得渲染线程和RHI线程能够更加高效地协同工作。
5. RHI命令的记录与执行
- 命令记录: UE5使用FRHICommandList来记录RHI命令,这些命令最终会被发送到RHI线程进行执行。
- 异步操作: 这种异步操作模式允许渲染线程在一帧的中间阶段就开始向RHI线程发送命令,然后继续进行其他任务。这大大提高了渲染线程和RHI线程的并行工作效率。
- 顺序保证: 为了确保命令按照正确的顺序执行,UE5实现了一套机制,即在创建新的Task时将之前发送的Task作为前置条件,确保命令的有序执行。
6. 跨平台支持
- 框架通用性: 整个多线程RHI命令的生成和执行过程被设计为不直接依赖于特定的硬件,这意味着这套机制可以被各种平台使用,包括移动设备。
- 图形API支持: 不同的图形API(如OpenGL, Vulkan, D3D12, Metal等)都可以通过实现各自的RHICommandContext来支持这一框架,无论是立即上下文还是延迟上下文。







![【代码随想录】【算法训练营】【第17天】 [110]平衡二叉树 [257]二叉树的所有路径 [404]左叶子之和](https://img-blog.csdnimg.cn/direct/50fab2b67f1a4a44a47f9e4492030359.png)