DeepRec Extension 即 DeepRec 扩展,在 DeepRec 训练推理框架之上,围绕大规模稀疏模型分布式训练,我们从训练任务的视角提出了自动弹性训练,分布式容错等功能,进一步提升稀疏模型训练的整体效率,助力 DeepRec 引擎在稀疏场景中发挥更大的优势。
序言
DeepRec 作为大规模稀疏模型的训练和推理引擎,在阿里集团内部以及云上的搜索,推荐和广告业务场景中,获得业界高度认可。它提供了针对稀疏模型领域的 EmbeddingVariable 功能,使用户可以轻松构建大规模稀疏参数的模型结构,此外还提供了 EmbeddingVariable 一系列演进功能,分布式优化,Runtime 优化,图及算子优化,从模型效果以及训练吞吐两个方面进行性能优化。尽管 DeepRec 在异步训练下提出了 GRPC++,StarServer 等一系列通信优化的工作,但是从用户视角,依然存在分布式训练的痛点,例如容错,资源选择等。DeepRec Extension 旨在以更低成本,更高效率进行模型的分布式训练。
动机
在大规模稀疏模型的训练中,模型尺寸随着业务发展增长到百 GB / TB 量级,分布式训练无疑是模型训练的一个必选项。无论是阿里集团内部客户还是阿里云客户,面对 TensorFlow 的 PS (Parameter Server) 分布式训练始终有很多困扰。
① 复杂的分布式建模接口。
由于 TensorFlow 提供了底层创建 Graph / Session 的能力,用户在构建计算图的时候可以自由设置参数的 Partition 策略,以及参数的 placement 策略,一旦设置不合适就会导致参数在 PS 上负载不均,使得模型训练吞吐下降。这增加了用户由单机模型代码修改为分布式版本的成本。
② 资源预估困难,资源无法弹性。
无论开源 kubeflow 生态,还是业界 TensorFlow 分布式训练产品的接口,都是把各个角色的资源申请暴露于用户面前,用户提交任务的时候难于确定申请的资源量,常常由于资源申请过少而在训练过程中出现 OOM,抑或是资源申请过多导致了资源浪费成本上涨。任务的资源实际使用量往往很难预估,尤其在稀疏模型参数可以动态变化的场景,静态的资源申请无法满足动态资源变化的需求。
③ 分布式容错机制过于简单。
目前 TensorFlow 的容错机制为定期持久化 checkpoint,在发生 Failover 时候将模型回退到最近的 checkpoint。DeepRec 针对稀疏参数的场景提出了增量 checkpoint 功能,可以降低参数节点发生意外宕机时的训练损失,但依然不能避免从持久化存储设备中读取全量及增量的 checkpoint。这使得发生容错时,模型恢复具有很高的成本,在外部存储的读取效率低的场景中尤其突出。与此同时,PS 节点的内存、磁盘以及网络资源相对空闲,可以利用其进行参数备份以减少完整模型读取的开销。在 TensorFlow 的设计中训练样本并没有进行 checkpoint 的保存与恢复,在发生 Failover 时候模型成功恢复而样本数据丢失状态信息,进而引起了样本丢失或者样本重算等不期望的行为。
④ 分布式环境复杂。
在分布式 PS 异步训练场景中,PS 往往运行来自多个 Worker 的 PS 子图,一旦某一个 PS 发生机器异常(分布式环境下慢节点)会影响所有 Worker 的训练效率,进而拖慢整个训练的吞吐。系统侧需要及时地发现慢节点,进行替换。单个 PS 发生异常对整体任务的影响要比单个 Worker 发生异常大得多,从资源调度角度来说,PS 需要比 Worker 更高的优先级。
回到深度学习框架的初衷,我们始终追求为算法工程师提供一个易用高效的框架,使用者聚焦模型的构建,框架屏蔽底层硬件、资源等信息。框架解决的问题是,模型如何便捷地在分布式环境中运行,如何更高效地运行,如何自动进行容错等一些列运行时问题。更少的超参配置对用户来说是一种更高易用性,对框架来说是获得更多的优化空间。更多的超参配置对高阶用户更友好,方便用户对模型进行精细管理。DeepRec Extension 旨在解决上述提到的问题,使用户可以低成本高效地分布式训练模型。围绕怎么从系统角度提升分布式训练效率的问题,DeepRec Extension 提供了以下功能:
- 分布式训练资源预估
- 自动弹性训练
- 资源/计算图监控
- 自动备份容错
设计思路及整体架构
DeepRec Extension 的功能涉及到资源调度,图优化,图执行,我们希望这些功能的设计实现与开源框架 kubeflow/DeepRec/TensorFlow 解耦,不绑定任何一个框架版本,充分利用开源框架的可扩展接口进行功能设计与实现。在 DeepRec/TensorFlow 设计哲学中所有操作都可以抽象为 Operation,DeepRec Extension 把相关的逻辑实现也进行了 Operation 抽象,并且结合 GraphOptimization 和 Hook 对原始计算图进行修改,进而把功能应用到计算图中。K8S 生态提供了 CRD 可扩展接口,DeepRec Extension 的整体设计相比社区版的 kubeflow + TensorFlow 封装了 CRD,对原生的 TFJob 进行了扩展,并且加入了 AIMaster 类型节点支持分布式任务的弹性扩缩,容错等功能。此外,我们所提供的功能都对系统的开销尽可能小,在发生容错或弹性伸缩的时候,减少 IO 的发生,降低额外的成本。
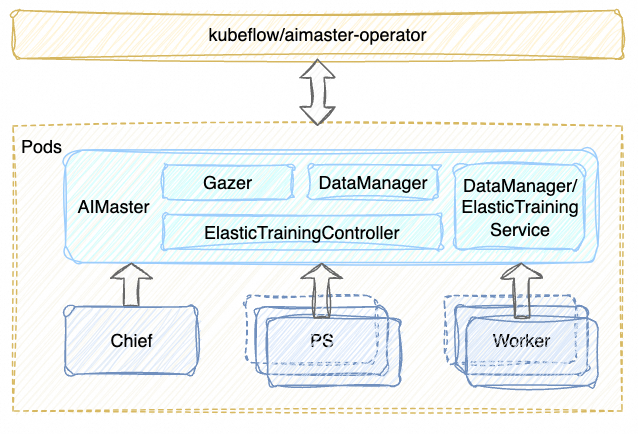
用户提交一个的。此种类型的相比 kubeflow 的增加了 AIMaster 节点,该被 aimaster-operator 管理,先拉起 AIMaster Pod 以及 Service,随后创建 kubeflow::TFJob。AIMaster 负责分布式训练资源预估,弹性训练,以及自动容错。
- 弹性训练
AIMaster 先拉起 Chief 节点,Chief 对任务的 checkpoint 进行估计,如果任务的 checkpoint 为空,则根据用户或系统的初始化 PS 数量来初始化合适的 PS/Worker 节点数量或资源。训练任务运行过程中,各个角色(Chief、PS、Worker)向 AIMaster Gazer 汇报各自的运行状态信息,AIMaster ElasticTrainingController 根据运行信息以及用户配置的策略进行弹性训练决策,当发生扩容或缩容后, AIMaster 维护任务状态,各个角色暂停训练,AIMaster 向调度申请新增的 PS/Worker 资源,并收集所有 PS 的 server 信息,PS 节点动态更新集群 Server 信息, Chief 驱动执行参数的重分布过程,最终将任务状态置为 running,完成扩容或缩容过程。整个过程 PS/Worker 进程不重启。
- 自动容错
在 AIMaster 中 DataManager 由 Chief 进行初始化,维护一个全局的样本状态信息,由各个 Worker 的 DataSet 进行消费,当模型触发一次保存 checkpoint 动作的时候,DataManager 也进行一次 checkpoint 保存,并且记录与模型的对应关系。当 Worker 发生 Failover 时候,由于 Worker 无状态信息,调度器重新拉起 Worker,继续训练。当 PS 发生 Failover 时候,失败的 PS 重启,正常的 PS 保持不动,由于在常规保存 checkpoint 的时候 PS 之间做了参数备份,失败 PS 从其他 PS 获取最新的 checkpoint 数据,正常 PS 从本地获取最新的 checkpoint 数据,无需从 checkpoint 源端发起读取模型并加载的操作。
功能特性
1.Gazer
Gazer 定位为对分布式训练任务各个节点以及图信息的监控模块,其结果可以通过 TensorBoard 可视化的展示给用户或者通过 RPC 接口汇报给 AIMaster,据此来进行动态的资源扩缩或者慢节点驱逐。指标分为两个层次:
- 机器级信息,比如CPU 内存使用量等
- Graph级信息,包含PS子图执行时长,PS子图的Resource资源用量等
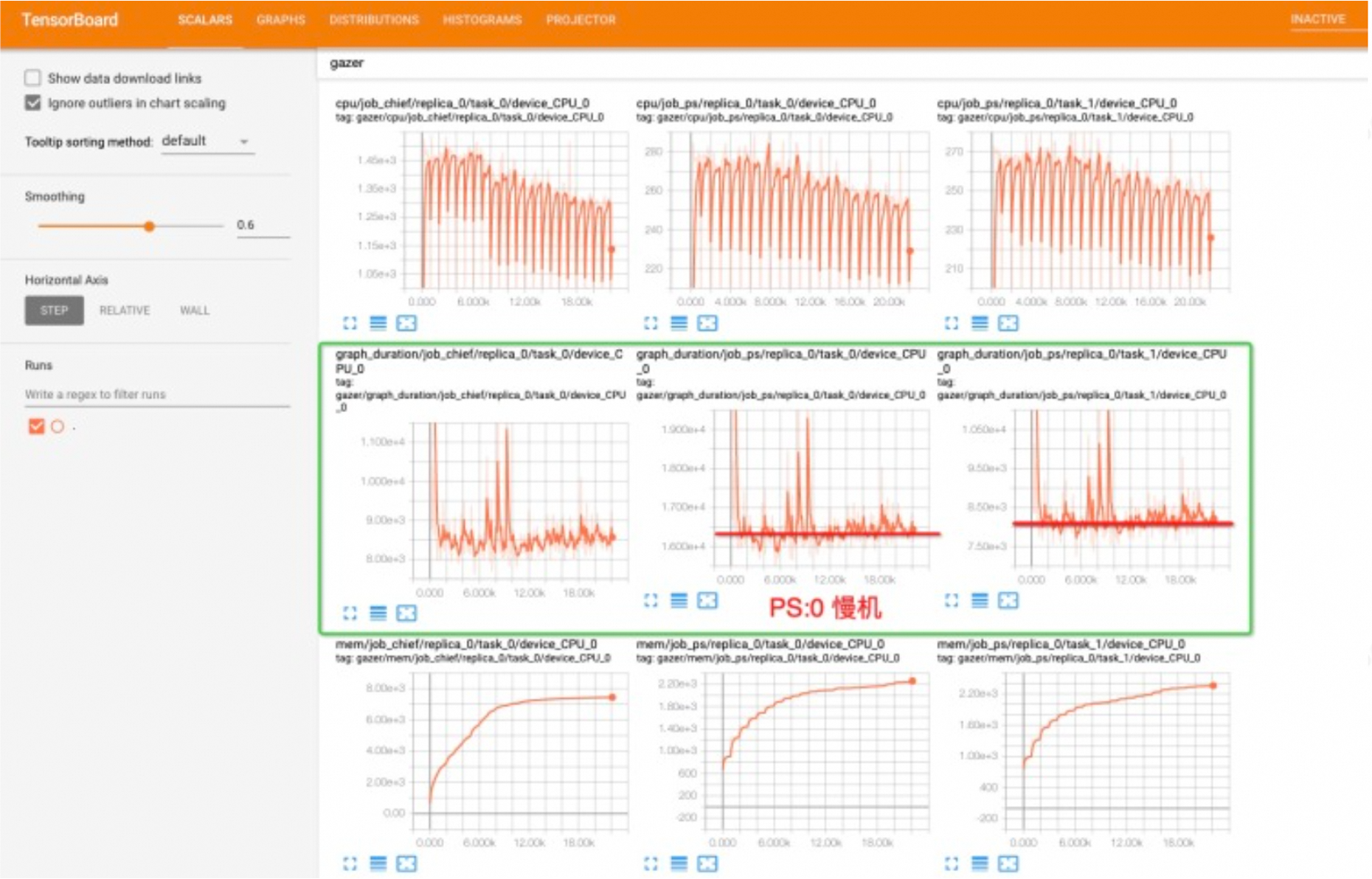
实现方案为 Operation + Grappler:内置了自定义的 Op 进行以上统计信息的收集,在用户构图后,以图改写的方式将 Op 加入到 summary 子图中,运行时依赖 SummaryHook,定期执行图,将信息汇报给 AIMaster 或者将信息写到 Summary,用户可以通过 TensorBoard 进行查询。下图展示了一个任务的 Gazer 信息,显示 PS:0 节点存在慢机。方便用户实时查看训练任务各个节点的状态信息,用户可以在 Gazer 模块中自定义监视指标,进行监测。
2.资源预估
考虑到大部分生产任务都是周期性的模型训练,从历史信息中获取资源消耗是一个直观的方法,我们利用了已存在的模型 checkpoint 进行模型尺寸的分析,计算出所需的 PS 资源数,来进行 PS 数目与资源的初始化。对于从头开始训练的模型,我们根据用户或者系统赋予的默认值进行初始化 PS 资源。资源预估功能可以帮助用户在训练之初申请合理的资源,降低训练成本,在实际的线上生产任务中节约 42%资源。
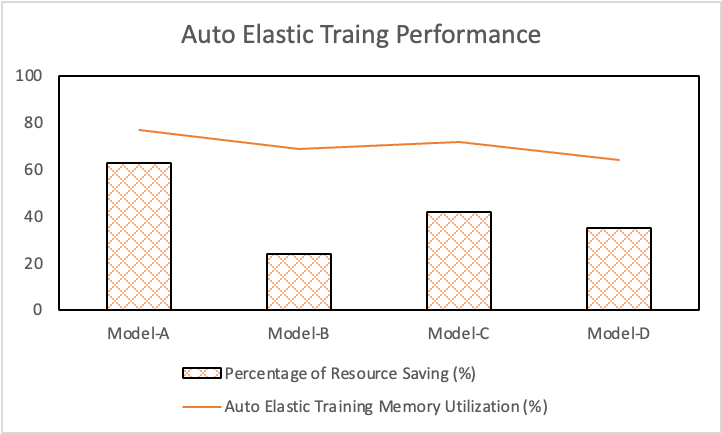
3.自动弹性训练
自动弹性训练,由于 Worker 节点无状态,Worker 的弹性相对简单。这里主要阐述 PS 发生弹性扩缩的系统行为。原则是不重启任务以及各个角色 python 进程。
弹性训练由以下几个模块组成:弹性 GrpcServer、动态图变换与参数迁移、AIMaster 控制器、数据动态分发。
- 弹性 GrpcServer
DeepRec 注册了一个 ElasticGRPCServer,区别于原有的 GRPCServer,支持 Server 动态更新集群中的增删节点,并更新分布式 Session 信息,保证图在新的集群环境中正确执行。全局的集群节点信息由 AIMaster 负责维护,当发生节点弹性扩缩后,AIMaster 向 PS/Worker 广播最新集群信息。
- 动态图变换与参数迁移
计算图中根据参数的类型,可以被分为稠密参数和稀疏参数,稀疏参数又可分为 static shape 的 Variable 和 dynamic shape 的 EmbeddingVariable。
| Resource | static/dynamic | |
| 稠密参数 | Variable | static |
| 稀疏参数 | Variable | static |
| EmbeddingVariable | dynamic |
考虑到参数服务器的 load balance,在发生 PS 节点数目变化时,对 Variable 和 EmbeddingVariable 都有必要进行参数重分布,Variable 依照 TensorFlow 原生的 Partitioner 策略进行新的 Partition 改造,EmbeddingVariable 由于其 Key-Value 属性,稀疏参数的 ID Partition 通过计算图中 Operation 进行改造。所有参数还需要进行重新放置,才能保证数据的一致性。以上都通过 TensorFlow 的 Operation + Grappler 实现,与 DeepRec/TensorFlow 进行了解耦。
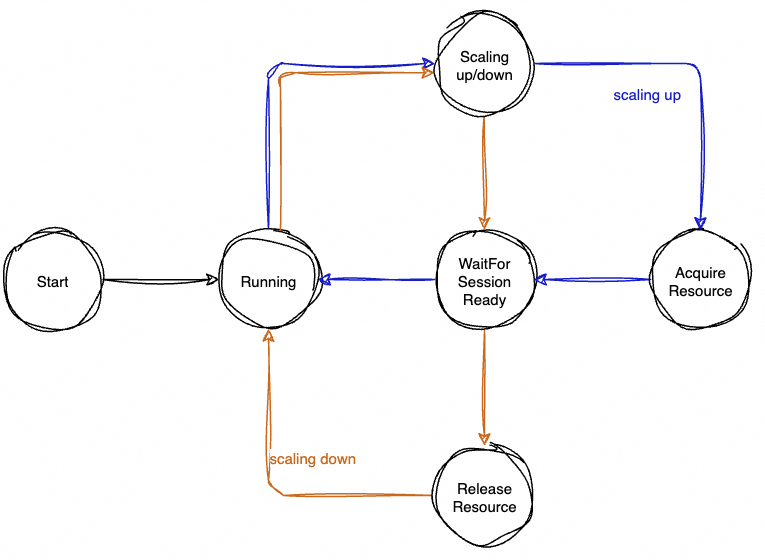
- AIMaster 控制器
AIMaster 在处理扩容和缩容的过程中,自身维护一个状态机,所有 Worker/PS/Chief 从 AIMaster Controller 获取扩缩容的状态,结合 Worker 注册的 Hook 机制完成各自逻辑的执行,并对 AIMaster 的弹性过程进行状态切换。
- 数据动态分发
数据动态分发功能是支持 Worker 弹性的必要条件,AIMaster 中记录了一个全局的样本读取状态信息,初始化由 Chief 完成,在训练过程中每个 Chief/Worker 都向 AIMaster 拉取一个数据分片以供训练,有效避免了单个 Worker 慢机拖慢整个训练任务的情况。
自动弹性训练功能,主要解决了两类问题,一是,在训练不断增长的稀疏模型时候,一旦用户设置初始资源过小,则会在训练某个时刻遇到 PS OOM 导致训练任务失败,用户则需要手工申请更大的资源,进行任务重启;二是,在实际使用资源动态改变的场景下,系统自动地进行资源适配,节约用户训练模型的成本。
下图为在不同模型下开启自动弹性训练功能后,带来的任务资源节省占比以及实际资源利用率。
4.自动容错
容错功能整体分为两个部分:数据分发的容错与 PS 参数的容错。
- 数据分发的容错
数据的消费状态与模型两者共同构成了训练任务的总状态,在模型训练中,数据状态的持久化与模型参数持久化同步发生,在节点发生 Failover 时,模型与数据状态需要同步恢复,否则会产生样本数据的重复训练或者丢样本的情况,影响模型训练精度。
- PS 容错
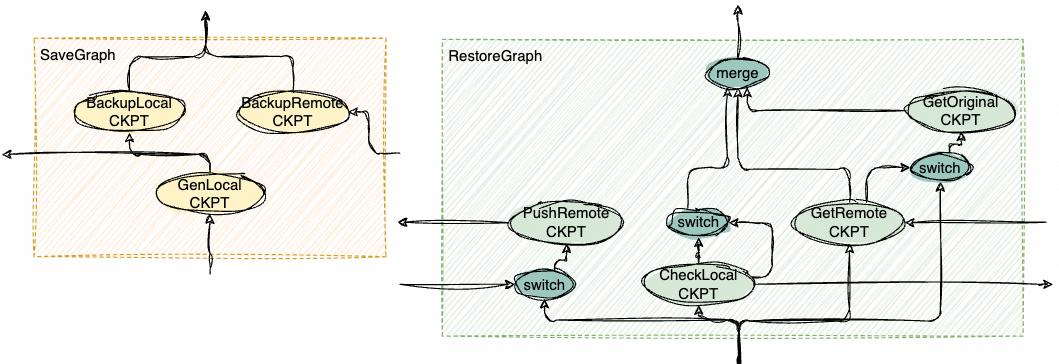
为了 PS 参数的高效恢复,DeepRec Extension 利用了节点的剩余内存或磁盘资源来做备份,避免从远端分布式文件系统跨网络读取 checkpoint,提高了模型恢复的效率。正常训练过程中,在保存 Checkpoint 的同时,触发 PS 的冗余保存,以 Graph 的方式执行本地与远端的参数备份,备份行为发生在后台,不影响任务保存常规 Checkpoint 的耗时。参数备份介质由用户指定,分为内存和磁盘。当 PS 节点发生 Failover 时,正常 PS 节点从本地快速恢复最新的 Checkpoint,异常 PS 节点被调度重启拉起后,从其他 PS 快速恢复 Checkpoint,大大提高了模型恢复的效率。模型文件在 Device 之间以 Slice Tensor 传输,便于进行内存管理。上图是保存和恢复的 Graph 示意图。
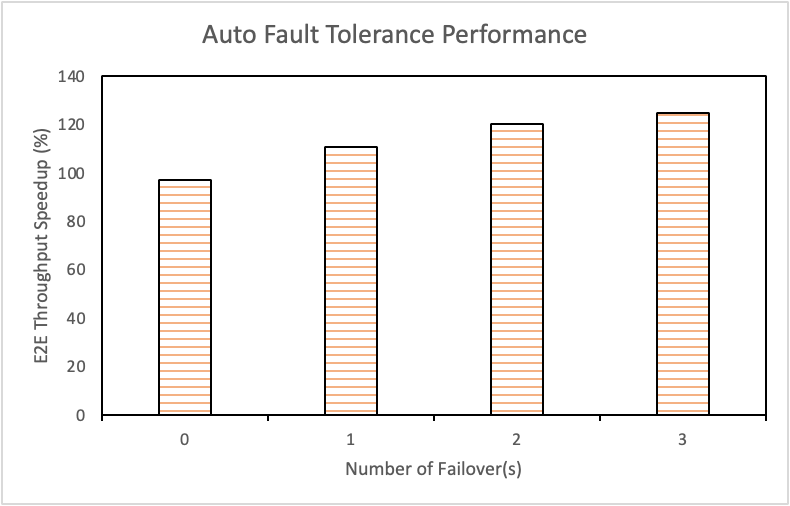
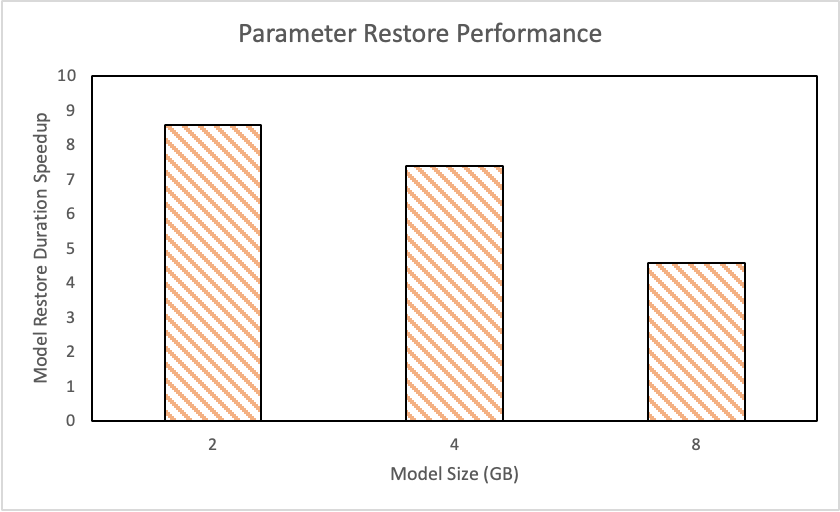
左图为在单 PS 节点模型尺寸为 10 GB,在 Failover 次数为 0-4 情况下,开启自动容错后分布式训练 E2E 吞吐性能提升。右图为不同模型尺寸下,PS 节点加载模型耗时性能提升。
总结与展望
DeepRec Extension 从用户使用,资源利用,训练效率以及可靠性角度系统地解决了分布式训练效率的问题。未来将从以下几个方向持续优化训练的性能。
- 自动弹性训练在弹性策略方面目前仅支持了 PS 和 Worker 各自 role 的弹性扩缩,PS 和 Worker 的联合弹性训练能更高效地利用资源,最大化训练吞吐,对用户来说提交任务接口也会更加简单,未来在开源社区也会展开讨论与设计实现。
- PS 节点在发生弹性扩缩后,需要移动一定体量的参数,在某些场景不容忽视,对于稀疏参数的冷热特点,对参数的移动考虑按需的策略可以极大降低网络的开销。
- 容错功能与增量 Checkpoint 的结合,在目前容错的基础上,减少备份参数规模,进一步减少系统开销,提升容错的效率。
DeepRec Extension 项目已在 Github (https://github.com/DeepRec-AI/extension)开源,开发者可以快速进行部署,也可以做二次开发,定制自定义的监控信息,弹性训练策略。欢迎开发者一同繁荣 DeepRec 社区。


![【Linux】-Spark分布式内存计算集群部署[20]](https://img-blog.csdnimg.cn/direct/3a5740f066064622b922b13773fb10a9.png)