Python 机器学习 基础 之 数据表示与特征工程 【分箱、离散化、线性模型与树 / 交互特征与多项式特征】的简单说明
目录
Python 机器学习 基础 之 数据表示与特征工程 【分箱、离散化、线性模型与树 / 交互特征与多项式特征】的简单说明
一、简单介绍
二、分箱、离散化、线性模型与树
三、交互特征与多项式特征
附录
一、参考文献
一、简单介绍
Python是一种跨平台的计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Python是一种解释型脚本语言,可以应用于以下领域: Web 和 Internet开发、科学计算和统计、人工智能、教育、桌面界面开发、软件开发、后端开发、网络爬虫。
Python 机器学习是利用 Python 编程语言中的各种工具和库来实现机器学习算法和技术的过程。Python 是一种功能强大且易于学习和使用的编程语言,因此成为了机器学习领域的首选语言之一。Python 提供了丰富的机器学习库,如Scikit-learn、TensorFlow、Keras、PyTorch等,这些库包含了许多常用的机器学习算法和深度学习框架,使得开发者能够快速实现、测试和部署各种机器学习模型。
Python 机器学习涵盖了许多任务和技术,包括但不限于:
- 监督学习:包括分类、回归等任务。
- 无监督学习:如聚类、降维等。
- 半监督学习:结合了有监督和无监督学习的技术。
- 强化学习:通过与环境的交互学习来优化决策策略。
- 深度学习:利用深度神经网络进行学习和预测。
通过 Python 进行机器学习,开发者可以利用其丰富的工具和库来处理数据、构建模型、评估模型性能,并将模型部署到实际应用中。Python 的易用性和庞大的社区支持使得机器学习在各个领域都得到了广泛的应用和发展。
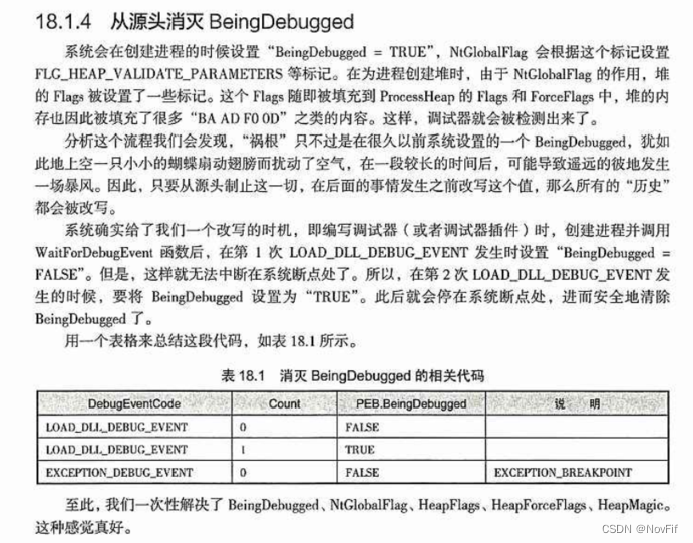
二、分箱、离散化、线性模型与树
在机器学习中,特征工程是提升模型性能的重要步骤。特征工程中的分箱、离散化、线性模型和树模型是常用的技术。以下是这些技术的介绍:
1. 分箱(Binning)
分箱是一种将连续特征转换为离散特征的技术。通过将连续数据分成多个区间(箱),每个区间的数据都映射到相同的离散值。分箱有助于处理噪声、提高模型的鲁棒性以及处理非线性关系。
类型:
- 等宽分箱(Equal-width binning):将数据按相同的宽度分为若干个区间。
- 等频分箱(Equal-frequency binning):将数据按相同的频率分为若干个区间。
示例:
import pandas as pd import numpy as np data = {'age': [23, 45, 18, 34, 55, 27, 64, 33, 29, 39]} df = pd.DataFrame(data) # 等宽分箱 df['age_bin'] = pd.cut(df['age'], bins=3, labels=['young', 'middle-aged', 'old']) # 等频分箱 df['age_bin_equal_freq'] = pd.qcut(df['age'], q=3, labels=['young', 'middle-aged', 'old']) print(df)2. 离散化(Discretization)
离散化与分箱类似,但通常是对特定范围的数值数据进行转换,使其成为离散的类别。离散化有助于处理非线性关系,并使特征更易于解释。
示例:
from sklearn.preprocessing import KBinsDiscretizer # 示例数据 X = np.array([[1], [2], [3], [4], [5]]) # 离散化 kbins = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform') X_binned = kbins.fit_transform(X) print(X_binned)3. 线性模型(Linear Models)
线性模型是机器学习中的一种基础模型,假设特征与目标之间存在线性关系。常见的线性模型包括线性回归和逻辑回归。
特点:
- 线性回归(Linear Regression):用于回归任务,目标变量是连续值。
- 逻辑回归(Logistic Regression):用于分类任务,目标变量是离散类别。
示例:
from sklearn.linear_model import LinearRegression, LogisticRegression # 示例数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y_reg = np.array([1, 2, 3, 4]) y_clf = np.array([0, 0, 1, 1]) # 线性回归 lin_reg = LinearRegression().fit(X, y_reg) # 逻辑回归 log_reg = LogisticRegression().fit(X, y_clf) print("Linear Regression coefficients:", lin_reg.coef_) print("Logistic Regression coefficients:", log_reg.coef_)4. 树模型(Tree Models)
树模型是一种非线性模型,可以捕捉特征之间复杂的交互关系。决策树是树模型的基本形式,通过递归地将数据划分为更小的子集来进行预测。
特点:
- 决策树(Decision Tree):构建树形结构,通过分裂节点来做出预测。
- 随机森林(Random Forest):多个决策树的集合,通过投票或平均来提高预测性能和鲁棒性。
- 梯度提升树(Gradient Boosting Trees):通过加法模型逐步优化残差来提高预测性能。
示例:
from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier # 示例数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([0, 0, 1, 1]) # 决策树 tree = DecisionTreeClassifier().fit(X, y) # 随机森林 forest = RandomForestClassifier(n_estimators=10).fit(X, y) # 梯度提升树 gbrt = GradientBoostingClassifier(n_estimators=10).fit(X, y) print("Decision Tree prediction:", tree.predict(X)) print("Random Forest prediction:", forest.predict(X)) print("Gradient Boosting prediction:", gbrt.predict(X))5. 分箱与模型结合的应用
分箱和离散化常常与树模型结合使用,以捕捉特征之间的非线性关系。线性模型也可以通过多项式特征扩展来结合分箱特征,从而提高模型的表现。
综上所述,分箱和离散化是特征工程的重要技术,可以将连续数据转换为离散特征,提高模型的鲁棒性和性能。线性模型和树模型是两种常用的机器学习模型,它们分别擅长处理线性和非线性关系。结合这些技术,可以有效提升机器学习模型的性能。
数据表示的最佳方法不仅取决于数据的语义,还取决于所使用的模型种类。线性模型与基于树的模型(比如决策树、梯度提升树和随机森林)是两种成员很多同时又非常常用的模型,它们在处理不同的特征表示时就具有非常不同的性质。我们回到第 2 章用过的 wave 回归数据集。它只有一个输入特征。下面是线性回归模型与决策树回归在这个数据集上的对比(见图 4-1):
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
import numpy as np
import matplotlib.pyplot as plt
import mglearn
X, y = mglearn.datasets.make_wave(n_samples=100)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
reg = DecisionTreeRegressor(min_samples_split=3).fit(X, y)
plt.plot(line, reg.predict(line), label="decision tree")
reg = LinearRegression().fit(X, y)
plt.plot(line, reg.predict(line), label="linear regression")
plt.plot(X[:, 0], y, 'o', c='k')
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.legend(loc="best")
plt.tight_layout()
plt.savefig('Images/02BinningDiscretizationLinearModelsAndTrees-01.png', bbox_inches='tight')
plt.show()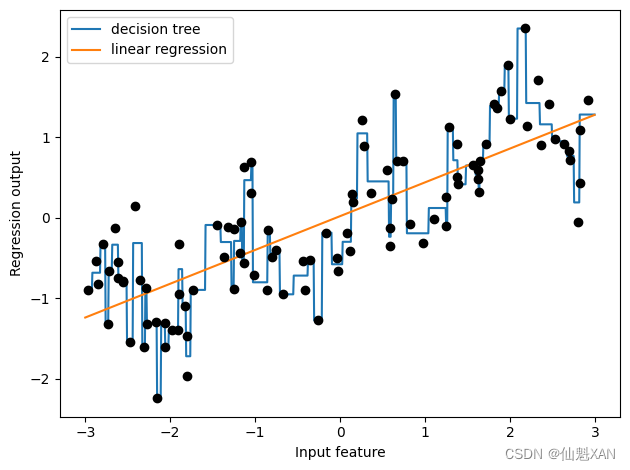
正如你所知,线性模型只能对线性关系建模,对于单个特征的情况就是直线。决策树可以构建更为复杂的数据模型,但这强烈依赖于数据表示。有一种方法可以让线性模型在连续数据上变得更加强大,就是使用特征分箱 (binning,也叫离散化 ,即 discretization)将其划分为多个特征,如下所述。
我们假设将特征的输入范围(在这个例子中是从 -3 到 3)划分成固定个数的箱子 (bin),比如 10 个,那么数据点就可以用它所在的箱子来表示。为了确定这一点,我们首先需要定义箱子。在这个例子中,我们在 -3 和 3 之间定义 10 个均匀分布的箱子。我们用 np.linspace 函数创建 11 个元素,从而创建 10 个箱子,即两个连续边界之间的空间:
bins = np.linspace(-3, 3, 11)
print("bins: {}".format(bins))bins: [-3. -2.4 -1.8 -1.2 -0.6 0. 0.6 1.2 1.8 2.4 3. ]
这里第一个箱子包含特征取值在 -3 到 -2.4 之间的所有数据点,第二个箱子包含特征取值在 -2.4 到 -1.8 之间的所有数据点,以此类推。
接下来,我们记录每个数据点所属的箱子。这可以用 np.digitize 函数轻松计算出来:
which_bin = np.digitize(X, bins=bins)
print("\nData points:\n", X[:5])
print("\nBin membership for data points:\n", which_bin[:5])
Data points: [[-0.75275929] [ 2.70428584] [ 1.39196365] [ 0.59195091] [-2.06388816]] Bin membership for data points: [[ 4] [10] [ 8] [ 6] [ 2]]
我们在这里做的是将 wave 数据集中单个连续输入特征变换为一个分类特征,用于表示数据点所在的箱子。要想在这个数据上使用 scikit-learn 模型,我们利用 preprocessing 模块的 OneHotEncoder 将这个离散特征变换为 one-hot 编码。OneHotEncoder 实现的编码与 pandas.get_dummies 相同,但目前它只适用于值为整数的分类变量:
from sklearn.preprocessing import OneHotEncoder
# 使用OneHotEncoder进行变换
encoder = OneHotEncoder(sparse_output=False)
# encoder.fit找到which_bin中的唯一值
encoder.fit(which_bin)
# transform创建one-hot编码
X_binned = encoder.transform(which_bin)
print(X_binned[:5])[[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]]
由于我们指定了 10 个箱子,所以变换后的 X_binned 数据集现在包含 10 个特征:
print("X_binned.shape: {}".format(X_binned.shape))X_binned.shape: (100, 10)
下面我们在 one-hot 编码后的数据上构建新的线性模型和新的决策树模型。结果见图 4-2,箱子的边界由黑色虚线表示:
line_binned = encoder.transform(np.digitize(line, bins=bins))
reg = LinearRegression().fit(X_binned, y)
plt.plot(line, reg.predict(line_binned), label='linear regression binned')
reg = DecisionTreeRegressor(min_samples_split=3).fit(X_binned, y)
plt.plot(line, reg.predict(line_binned), label='decision tree binned')
plt.plot(X[:, 0], y, 'o', c='k')
plt.vlines(bins, -3, 3, linewidth=1, alpha=.2)
plt.legend(loc="best")
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.tight_layout()
plt.savefig('Images/02BinningDiscretizationLinearModelsAndTrees-02.png', bbox_inches='tight')
plt.show()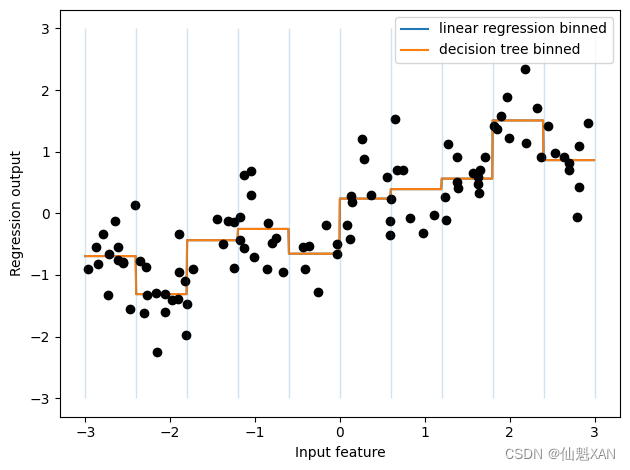
虚线和实线完全重合,说明线性回归模型和决策树做出了完全相同的预测。对于每个箱子,二者都预测一个常数值。因为每个箱子内的特征是不变的,所以对于一个箱子内的所有点,任何模型都会预测相同的值。比较对特征进行分箱前后模型学到的内容,我们发现,线性模型变得更加灵活了,因为现在它对每个箱子具有不同的取值,而决策树模型的灵活性降低了。分箱特征对基于树的模型通常不会产生更好的效果,因为这种模型可以学习在任何位置划分数据。从某种意义上来看,决策树可以学习如何分箱对预测这些数据最为有用。此外,决策树可以同时查看多个特征,而分箱通常针对的是单个特征。不过,线性模型的表现力在数据变换后得到了极大的提高。
对于特定的数据集,如果有充分的理由使用线性模型——比如数据集很大、维度很高,但有些特征与输出的关系是非线性的——那么分箱是提高建模能力的好方法。
三、交互特征与多项式特征
在机器学习中,特征工程是一项关键的步骤,其中包括创建新的特征来提升模型的表现。交互特征和多项式特征是两种常见的方法,用于捕捉特征之间的复杂关系。
1)交互特征(Interaction Features)
交互特征是由两个或多个原始特征的乘积组成的。这些特征可以帮助模型捕捉特征之间的交互作用,而不仅仅是独立的线性关系。
示例: 假设你有两个特征
X1和X2,你可以创建一个交互特征X1*X2。import numpy as np import pandas as pd # 假设我们有一个 DataFrame df df = pd.DataFrame({ 'X1': [1, 2, 3], 'X2': [4, 5, 6] }) # 创建交互特征 df['X1_X2'] = df['X1'] * df['X2'] print(df)输出将包含一个新列
X1_X2,其值是X1和X2的乘积。2)多项式特征(Polynomial Features)
多项式特征是通过对原始特征进行多项式扩展生成的。即,将特征提升到更高的次幂,并包括这些幂的交互项。
示例: 假设你有一个特征
X,你可以创建该特征的平方X^2、立方X^3等等。可以使用
scikit-learn中的PolynomialFeatures类来自动创建这些特征。from sklearn.preprocessing import PolynomialFeatures # 假设我们有一个 2D 数组 X X = np.array([[1, 2], [3, 4], [5, 6]]) # 创建一个 PolynomialFeatures 实例,指定多项式的最高次幂为 2 poly = PolynomialFeatures(degree=2, include_bias=False) X_poly = poly.fit_transform(X) print("原始特征:\n", X) print("多项式特征:\n", X_poly)输出的
X_poly将包含原始特征,以及每个特征的平方和两个特征的交互项。示例:以下是一个综合示例,展示如何在数据集中创建交互特征和多项式特征:
import numpy as np import pandas as pd from sklearn.preprocessing import PolynomialFeatures # 创建一个示例 DataFrame df = pd.DataFrame({ 'X1': [1, 2, 3, 4], 'X2': [2, 3, 4, 5] }) # 创建交互特征 df['X1_X2'] = df['X1'] * df['X2'] # 使用 PolynomialFeatures 创建多项式特征 poly = PolynomialFeatures(degree=2, include_bias=False) X = df[['X1', 'X2']] X_poly = poly.fit_transform(X) # 将多项式特征添加到 DataFrame 中 poly_feature_names = poly.get_feature_names_out(['X1', 'X2']) df_poly = pd.DataFrame(X_poly, columns=poly_feature_names) # 将原始 DataFrame 和多项式特征 DataFrame 合并 df_combined = pd.concat([df, df_poly], axis=1) print(df_combined)输出将包含原始特征、交互特征以及所有多项式特征。
- 交互特征:通过两个或多个特征的乘积生成,用于捕捉特征之间的交互作用。
- 多项式特征:通过对特征进行多项式扩展生成,包括特征的高次幂和交互项。
这些特征可以帮助提升模型的表现,特别是当原始特征之间存在非线性关系时。
想要丰富特征表示,特别是对于线性模型而言,另一种方法是添加原始数据的交互特征 (interaction feature)和多项式特征 (polynomial feature)。这种特征工程通常用于统计建模,但也常用于许多实际的机器学习应用中。
作为第一个例子,我们再看一次图 4-2。线性模型对 wave 数据集中的每个箱子都学到一个常数值。但我们知道,线性模型不仅可以学习偏移,还可以学习斜率。想要向分箱数据上的线性模型添加斜率,一种方法是重新加入原始特征(图中的 x 轴)。这样会得到 11 维的数据集,如图 4-3 所示。
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
import numpy as np
import matplotlib.pyplot as plt
import mglearn
from sklearn.preprocessing import OneHotEncoder
X, y = mglearn.datasets.make_wave(n_samples=100)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
bins = np.linspace(-3, 3, 11)
which_bin = np.digitize(X, bins=bins)
line_binned = encoder.transform(np.digitize(line, bins=bins))
# 使用OneHotEncoder进行变换
encoder = OneHotEncoder(sparse_output=False)
# encoder.fit找到which_bin中的唯一值
encoder.fit(which_bin)
# transform创建one-hot编码
X_binned = encoder.transform(which_bin)
X_combined = np.hstack([X, X_binned])
print(X_combined.shape)(100, 11)
reg = LinearRegression().fit(X_combined, y)
line_combined = np.hstack([line, line_binned])
plt.plot(line, reg.predict(line_combined), label='linear regression combined')
for bin in bins:
plt.plot([bin, bin], [-3, 3], ':', c='k')
plt.legend(loc="best")
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.plot(X[:, 0], y, 'o', c='k')
plt.tight_layout()
plt.savefig('Images/03InteractionFeaturesAndPolynomialFeatures-01.png', bbox_inches='tight')
plt.show()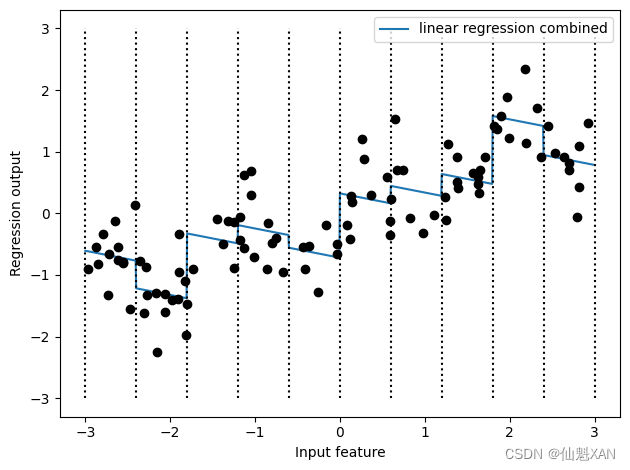
在这个例子中,模型在每个箱子中都学到一个偏移,还学到一个斜率。学到的斜率是向下的,并且在所有箱子中都相同——只有一个 x 轴特征,也就只有一个斜率。因为斜率在所有箱子中是相同的,所以它似乎不是很有用。我们更希望每个箱子都有一个不同的斜率!为了实现这一点,我们可以添加交互特征或乘积特征,用来表示数据点所在的箱子以及数据点在 x 轴上的位置。这个特征是箱子指示符与原始特征的乘积。我们来创建数据集:
X_product = np.hstack([X_binned, X * X_binned])
print(X_product.shape)(100, 20)
这个数据集现在有 20 个特征:数据点所在箱子的指示符与原始特征和箱子指示符的乘积。你可以将乘积特征看作每个箱子 x 轴特征的单独副本。它在箱子内等于原始特征,在其他位置等于零。图 4-4 给出了线性模型在这种新表示上的结果:
reg = LinearRegression().fit(X_product, y)
line_product = np.hstack([line_binned, line * line_binned])
plt.plot(line, reg.predict(line_product), label='linear regression product')
for bin in bins:
plt.plot([bin, bin], [-3, 3], ':', c='k')
plt.plot(X[:, 0], y, 'o', c='k')
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.legend(loc="best")
plt.tight_layout()
plt.savefig('Images/03InteractionFeaturesAndPolynomialFeatures-02.png', bbox_inches='tight')
plt.show()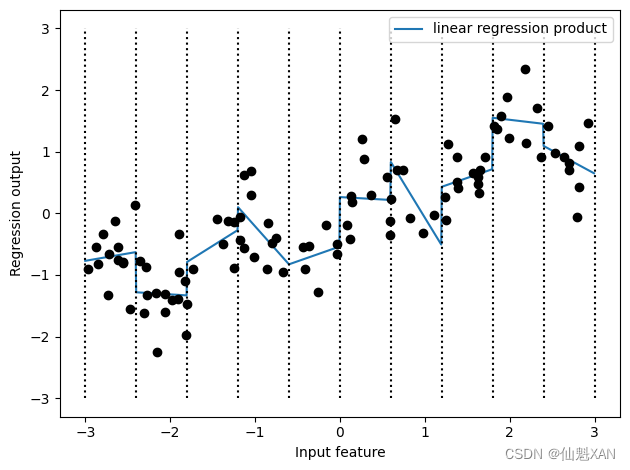
如你所见,现在这个模型中每个箱子都有自己的偏移和斜率。
使用分箱是扩展连续特征的一种方法。另一种方法是使用原始特征的 多项式 (polynomial)。对于给定特征 x ,我们可以考虑 x ** 2 、x ** 3 、x ** 4 ,等等。这在 preprocessing 模块的 PolynomialFeatures 中实现:
from sklearn.preprocessing import PolynomialFeatures
# 包含直到x ** 10的多项式:
# 默认的"include_bias=True"添加恒等于1的常数特征
poly = PolynomialFeatures(degree=10, include_bias=False)
poly.fit(X)
X_poly = poly.transform(X)多项式的次数为 10,因此生成了 10 个特征:
print("X_poly.shape: {}".format(X_poly.shape))X_poly.shape: (100, 10)
我们比较 X_poly 和 X 的元素:
print("Entries of X:\n{}".format(X[:5]))
print("Entries of X_poly:\n{}".format(X_poly[:5]))Entries of X: [[-0.75275929] [ 2.70428584] [ 1.39196365] [ 0.59195091] [-2.06388816]] Entries of X_poly: [[-7.52759287e-01 5.66646544e-01 -4.26548448e-01 3.21088306e-01 -2.41702204e-01 1.81943579e-01 -1.36959719e-01 1.03097700e-01 -7.76077513e-02 5.84199555e-02] [ 2.70428584e+00 7.31316190e+00 1.97768801e+01 5.34823369e+01 1.44631526e+02 3.91124988e+02 1.05771377e+03 2.86036036e+03 7.73523202e+03 2.09182784e+04] [ 1.39196365e+00 1.93756281e+00 2.69701700e+00 3.75414962e+00 5.22563982e+00 7.27390068e+00 1.01250053e+01 1.40936394e+01 1.96178338e+01 2.73073115e+01] [ 5.91950905e-01 3.50405874e-01 2.07423074e-01 1.22784277e-01 7.26822637e-02 4.30243318e-02 2.54682921e-02 1.50759786e-02 8.92423917e-03 5.28271146e-03] [-2.06388816e+00 4.25963433e+00 -8.79140884e+00 1.81444846e+01 -3.74481869e+01 7.72888694e+01 -1.59515582e+02 3.29222321e+02 -6.79478050e+02 1.40236670e+03]]
你可以通过调用 get_feature_names 方法来获取特征的语义,给出每个特征的指数:
print("Polynomial feature names:\n{}".format(poly.get_feature_names_out ()))Polynomial feature names: ['x0' 'x0^2' 'x0^3' 'x0^4' 'x0^5' 'x0^6' 'x0^7' 'x0^8' 'x0^9' 'x0^10']
你可以看到,X_poly 的第一列与 X 完全对应,而其他列则是第一列的幂。有趣的是,你可以发现有些值非常大。第二行有大于 20 000 的元素,数量级与其他行都不相同。
将多项式特征与线性回归模型一起使用,可以得到经典的 多项式回归 (polynomial regression)模型(见图 4-5):
reg = LinearRegression().fit(X_poly, y)
line_poly = poly.transform(line)
plt.plot(line, reg.predict(line_poly), label='polynomial linear regression')
plt.plot(X[:, 0], y, 'o', c='k')
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.legend(loc="best")
plt.tight_layout()
plt.savefig('Images/03InteractionFeaturesAndPolynomialFeatures-03.png', bbox_inches='tight')
plt.show()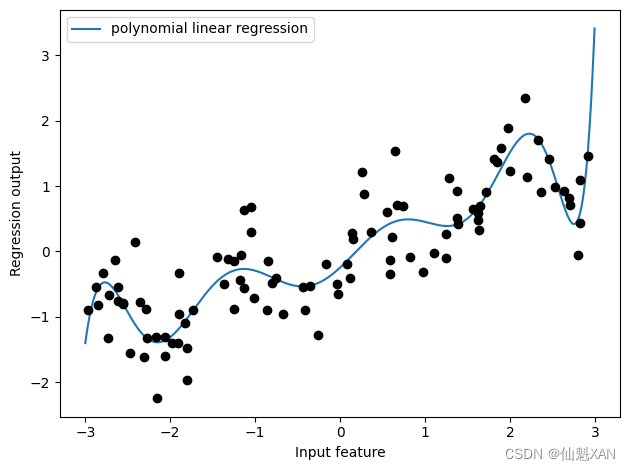
如你所见,多项式特征在这个一维数据上得到了非常平滑的拟合。但高次多项式在边界上或数据很少的区域可能有极端的表现。
作为对比,下面是在原始数据上学到的核 SVM 模型,没有做任何变换(见图 4-6):
from sklearn.svm import SVR
for gamma in [1, 10]:
svr = SVR(gamma=gamma).fit(X, y)
plt.plot(line, svr.predict(line), label='SVR gamma={}'.format(gamma))
plt.plot(X[:, 0], y, 'o', c='k')
plt.ylabel("Regression output")
plt.xlabel("Input feature")
plt.legend(loc="best")
plt.tight_layout()
plt.savefig('Images/03InteractionFeaturesAndPolynomialFeatures-04.png', bbox_inches='tight')
plt.show()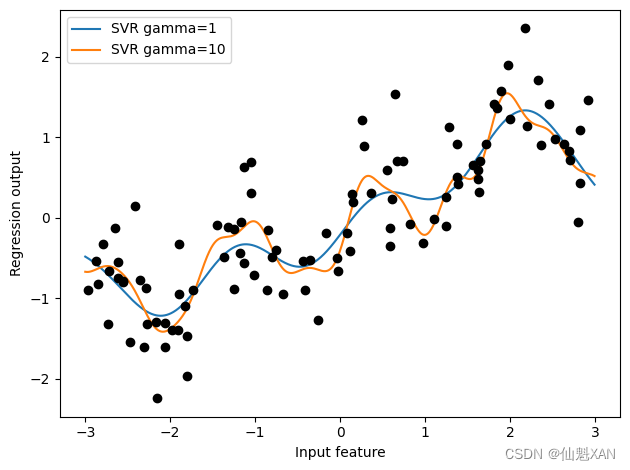
使用更加复杂的模型(即核 SVM),我们能够学到一个与多项式回归的复杂度类似的预测结果,且不需要进行显式的特征变换。
我们再次观察波士顿房价数据集,作为对交互特征和多项式特征更加实际的应用。我们在第 2 章已经在这个数据集上使用过多项式特征了。现在来看一下这些特征的构造方式,以及多项式特征的帮助有多大。首先加载数据,然后利用 MinMaxScaler 将其缩放到 0 和 1 之间:
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
# 加载加州房价数据集
california = fetch_california_housing()
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
california.data, california.target, random_state=0)
# 缩放数据
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
poly = PolynomialFeatures(degree=2).fit(X_train_scaled)
X_train_poly = poly.transform(X_train_scaled)
X_test_poly = poly.transform(X_test_scaled)
print("X_train.shape: {}".format(X_train.shape))
print("X_train_poly.shape: {}".format(X_train_poly.shape))X_train.shape: (15480, 8) X_train_poly.shape: (15480, 45)
我们提取多项式特征和交互特征,次数最高为 2,原始数据有 8 个特征,现在被扩展到 45 个交互特征。这些新特征表示两个不同的原始特征之间所有可能的交互项,以及每个原始特征的平方。这里 degree=2 的意思是,我们需要由最多两个原始特征的乘积组成的所有特征。利用 get_feature_names_out 方法可以得到输入特征和输出特征之间的确切对应关系:
print("Polynomial feature names:\n{}".format(poly.get_feature_names_out()))Polynomial feature names: ['1' 'x0' 'x1' 'x2' 'x3' 'x4' 'x5' 'x6' 'x7' 'x0^2' 'x0 x1' 'x0 x2' 'x0 x3' 'x0 x4' 'x0 x5' 'x0 x6' 'x0 x7' 'x1^2' 'x1 x2' 'x1 x3' 'x1 x4' 'x1 x5' 'x1 x6' 'x1 x7' 'x2^2' 'x2 x3' 'x2 x4' 'x2 x5' 'x2 x6' 'x2 x7' 'x3^2' 'x3 x4' 'x3 x5' 'x3 x6' 'x3 x7' 'x4^2' 'x4 x5' 'x4 x6' 'x4 x7' 'x5^2' 'x5 x6' 'x5 x7' 'x6^2' 'x6 x7' 'x7^2']
第一个新特征是常数特征,这里的名称是 "1" 。接下来的 13 个特征是原始特征(名称从 "x0" 到 "x12" )。然后是第一个特征的平方("x0^2" )以及它与其他特征的组合。
我们对 Ridge 在有交互特征的数据上和没有交互特征的数据上的性能进行对比:
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train_scaled, y_train)
print("Score without interactions: {:.3f}".format(
ridge.score(X_test_scaled, y_test)))
ridge = Ridge().fit(X_train_poly, y_train)
print("Score with interactions: {:.3f}".format(
ridge.score(X_test_poly, y_test)))Score without interactions: 0.584 Score with interactions: 0.605
显然,在使用 Ridge 时,交互特征和多项式特征对性能有很大的提升。但如果使用更加复杂的模型(比如随机森林),情况会稍有不同:
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators=100).fit(X_train_scaled, y_train)
print("Score without interactions: {:.3f}".format(
rf.score(X_test_scaled, y_test)))
rf = RandomForestRegressor(n_estimators=100).fit(X_train_poly, y_train)
print("Score with interactions: {:.3f}".format(rf.score(X_test_poly, y_test)))Score without interactions: 0.795 Score with interactions: 0.810
你可以看到,即使没有额外的特征,随机森林的性能也要优于 Ridge 。添加交互特征和多项式特征实际上会略微降低其性能。
附录
一、参考文献
参考文献:[德] Andreas C. Müller [美] Sarah Guido 《Python Machine Learning Basics Tutorial》