1、paligemma
参考:https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md
模型架构:
文本与图像特征一起送入大模型

在线体验网址:
https://huggingface.co/spaces/big-vision/paligemma
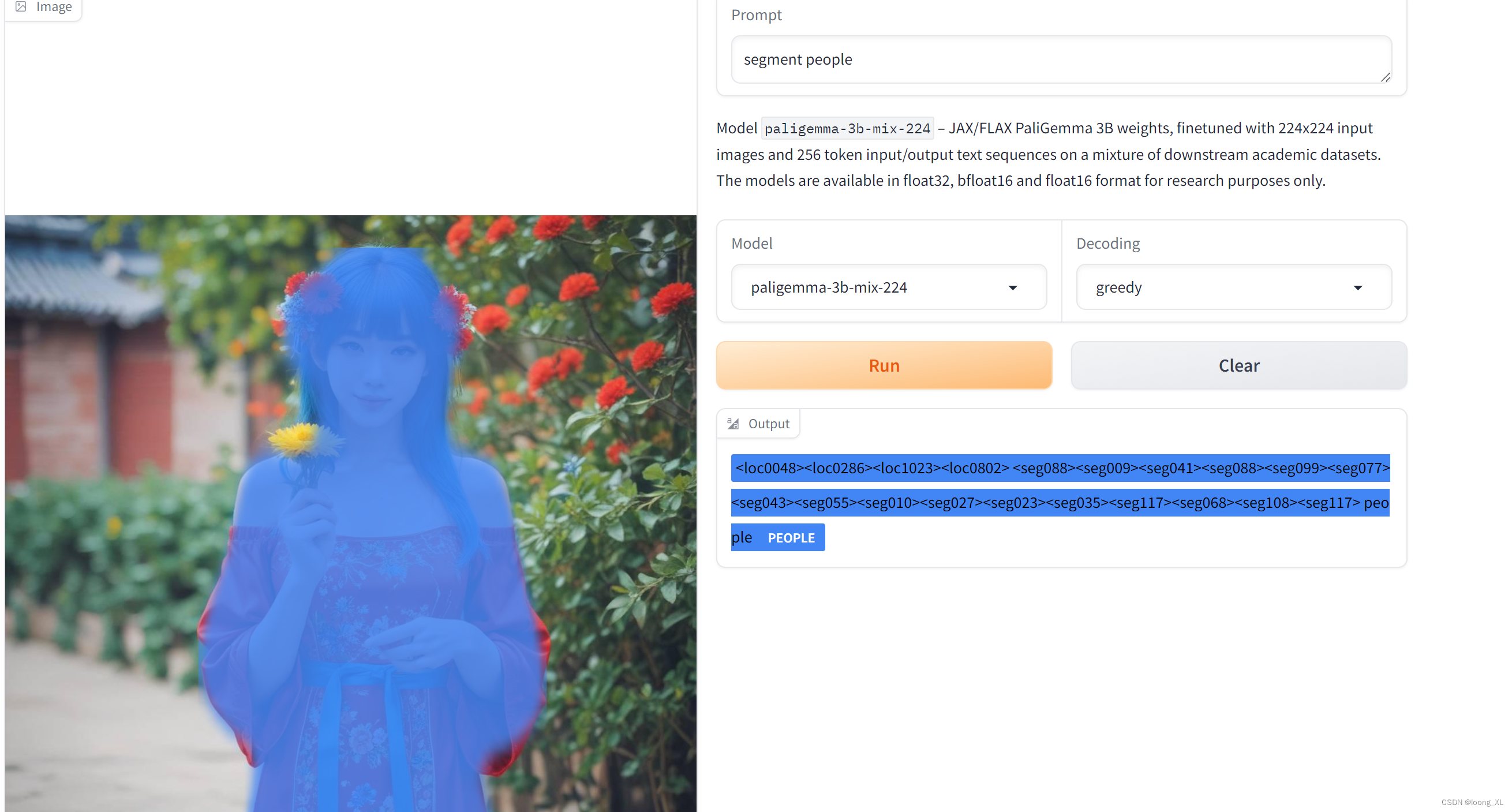
通过文字prompt既可与图片对话输出,下面是官方案例

2、Grounding-DINO-1.5
参考:
https://github.com/IDEA-Research/Grounding-DINO-1.5-API?tab=readme-ov-file#3-runing-demo-code
模型架构:
类似CLIP对比学习方式