【摘要】大型语言模型(LLM)的不断进步使人们越来越关注开发公平可靠的方法来评估其性能的关键问题。特别是测试集泄漏、提示格式过拟合等主观或非主观作弊现象的出现,给法学硕士的可靠评估带来了重大挑战。由于评估框架通常利用正则表达式 (RegEx) 进行答案提取,因此某些模型可能会调整其响应以符合 RegEx 可以轻松提取的特定格式。然而,基于正则表达式的关键答案提取模块经常出现提取错误。本文对整个LLM评估链进行了全面分析,证明优化关键答案提取模块可以提高提取准确性,减少LLM对特定答案格式的依赖,增强LLM评估的可靠性。为了解决这些问题,我们提出了 xFinder,一个专门为关键答案提取而设计的模型。作为此过程的一部分,我们创建了一个专门的数据集,即关键答案查找器 (KAF) 数据集,以确保有效的模型训练和评估。通过真实场景的泛化测试和评估,结果表明,只有 5 亿个参数的最小 xFinder 模型的平均答案提取准确率达到 93.42%。相比之下,最佳评估框架中的 RegEx 准确率为 74.38%。与现有评估框架相比,xFinder 表现出更强的鲁棒性和更高的准确性。
原文:xFinder: Robust and Pinpoint Answer Extraction for Large Language Models
地址:https://arxiv.org/abs/2405.11874v1
代码:https://github.com/IAAR-Shanghai/xFinder
出版:未知
机构: Institute for Advanced Algorithms Research, Shanghai; Renmin University of China解析人:公众号“码农的科研笔记”
1 研究问题
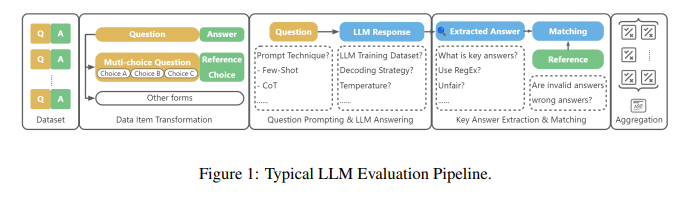
本文研究的核心问题是: 如何设计一种精准、鲁棒的大语言模型(LLMs)生成内容中的关键答案抽取方法。
考虑这样一个场景:现有多个LLMs如GPT-4、PaLM、Bard等,针对同一个问题生成了不同的回答。这些回答可能格式多样,有的用自然语言直接给出答案,有的则先给出推理过程再得出结论。我们希望从这些回答中抽取出最终的关键答案,以便对不同LLM的表现进行评估和比较。然而现有的基于正则表达式的抽取方法往往无法应对LLM生成内容的多样性,导致大量答案被漏抽或错抽。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
LLM生成的回答内容丰富多样,很难用简单的模板或规则进行匹配和抽取。比如有的回答会先给出推理过程,再在最后给出结论;有的回答会在中间某处给出答案,然后进行补充说明。
-
不同LLM对于同一个问题的理解和表述方式差异很大。比如针对"人工智能会取代人类吗"这个问题,有的LLM可能直接回答"不会",而有的LLM则可能从技术、伦理、经济等多个角度分析利弊,但最终也是得出"不会取代"的结论。
-
现有的基于正则表达式(RegEx)的抽取方法缺乏灵活性和泛化能力。它们通常依赖于特定的答案格式(如"The answer is ...")来定位和提取答案,一旦LLM生成的回答不符合预设格式,就很容易出错。
-
缺乏高质量的答案抽取数据集。由于LLM回答的多样性,人工标注答案抽取的数据成本很高。而直接将其他QA或MRC数据集转化为答案抽取任务的数据质量较差。
针对这些挑战,本文提出了一种预训练+微调的"xFinder"方法:
xFinder的核心思想是先在大规模语料上预训练一个语言模型,使其具备基本的语言理解和生成能力,然后在答案抽取数据集上进行微调,使其习得从LLM生成内容中定位和抽取关键答案的能力。 具体来说,xFinder采用的是基于Transformer的encoder-decoder结构。Encoder负责对LLM生成的文本进行编码,生成each token的上下文表示。Decoder则根据question和answer range的embedding,在encoder的输出表示中定位含有答案的句子和span。 为了训练xFinder,本文构建了一个KB Answer Finder (KAF)数据集,包含由10个不同LLM在8个任务上生成的回答,以及对应的人工标注的关键答案。此外还有一个泛化测试集,包含另外8个LLM在11个新任务上的生成内容,用于评估xFinder的泛化能力。 实验结果表明,xFinder相比传统的RegEx方法,在答案抽取的精确度和鲁棒性上都有大幅提升。在泛化测试集上,参数量只有5亿的xFinder-qwen1505模型的平均抽取准确率达到了93.42%,而最好的RegEx方法只有74.38%。
2 研究方法
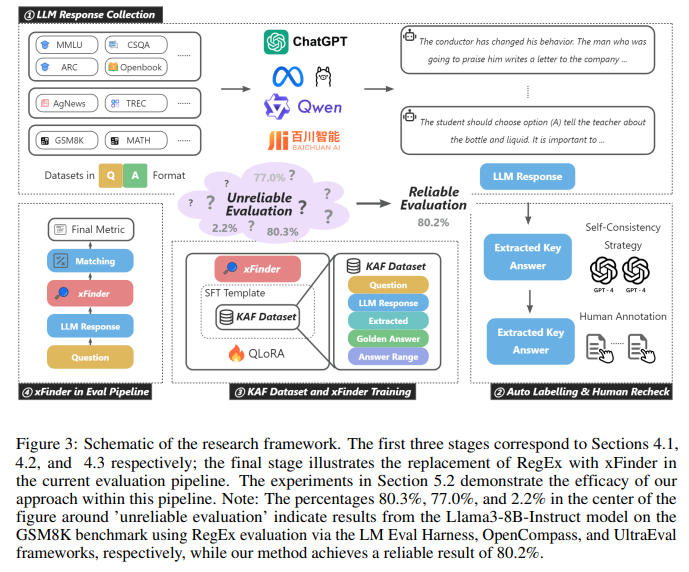
为了有效地微调xFinder模型,构建一个高质量的数据集至关重要。论文构建了一个专门用于关键答案提取的数据集KAF(Key Answer Finder)。本节将详细介绍KAF数据集的构建过程以及xFinder模型的训练方法。
2.1 KAF数据集构建
2.1.1 LLM回答生成
KAF数据集构建的第一步是利用不同的大型语言模型,针对多个评估任务生成问题-回答对。论文选取了18个典型的评估任务数据集,涵盖了广泛的知识领域。
为了引导LLM生成多样化的回答,论文精心设计了8种提示词配置,包括0-shot(-restrict)、0-shot-cot(-restrict)、5-shot(-restrict)和5-shot-cot(-restrict)。其中,-restrict表示在提示词末尾添加一个标准化回答格式的要求。通过这些提示词,可以得到LLM在不同few-shot设置和推理模式下的多样化回答。
此外,考虑到不同系列和规模的LLM在面对同一个问题时可能给出不同的回答,论文选取了10个不同的LLM来生成回答,以进一步丰富数据的异质性。
2.1.2 半自动标注与人工复核
KAF数据集构建的关键是从LLM回答中提取出关键答案作为标签。论文针对训练集、测试集和泛化集采用了不同的标注策略:
-
对于训练集,为了提高标注效率,论文采用了一种半自动化的方法。首先利用GPT-4生成两组标注,然后应用自洽性策略,对两轮标注结果不一致的样本以及所有数学题进行人工复核。
-
对于测试集和泛化集,为确保标签的准确性,全部采用两轮人工标注的方式。
自洽性策略的核心思想是:对同一个样本利用两种不同形式的提示(常规形式和XML形式)生成两组标注,若结果一致则认为标注可靠,否则交由人工复核。这种方法可以充分利用GPT-4的能力提高标注效率,同时通过人工复核保证关键样本的标注质量。
2.1.3 KAF数据集概述
KAF数据集包含26,900个训练样本、4,961个测试样本和4,482个泛化样本。每个样本包括一个问题、候选答案范围、LLM对该问题的回答以及从回答中提取的关键答案标签。
值得注意的是,训练集和测试集中的问答对来自于10个LLM在8个评估任务上的回答,而泛化集的问答对则来自于8个LLM在另外11个全新评估任务上的回答。这种划分方式有助于全面评估xFinder模型的泛化性能。
2.2 xFinder模型训练
根据第3节中对关键答案提取任务的定义,xFinder的训练目标是学会从LLM回答y中准确定位包含最终答案的关键句s,并从s中提取出与问题q对应的关键答案k。
xFinder的输入包括问题q、LLM回答y、关键答案类型以及候选答案范围,输出为从y中提取的关键答案k。在训练过程中,论文主要使用了XTuner工具包中的QLoRA方法进行微调,并精心设计了指令型提示词来充分发挥xFinder的指令遵循能力。
此外,为了增强xFinder的泛化性,论文还对KAF训练集进行了数据增强:
-
对50%的字母选项问题,通过增减选项数量来模拟LLM对此类问题的回答。
-
对含有外包装关键句的样本,随机替换外包装提示词以丰富语言模式。
通过在高质量的KAF数据集上微调,并应用数据增强策略提升泛化性,xFinder可以在实际应用中准确地提取LLM回答中的关键信息,为后续的自动化评估打下坚实基础。 第四步、实验部分详细撰写:
5 实验
5.1 实验场景介绍
本论文提出了一个专门用于关键答案抽取的模型xFinder,实验的目标是验证xFinder在关键答案抽取任务上的有效性,以及在真实评估场景中替换主流框架的正则抽取模块后对LLM排名的影响。
5.2 实验设置
Datasets:
-
KAF(Key Answer Finder)数据集:包含训练集26,900个样本,测试集4,961个样本,泛化集4,482个样本。训练和测试集的问答对由10个LLM在8个评估任务上生成,泛化集由8个LLM在11个新评估任务生成。
-
14个主流评估任务数据集
Baselines:
-
主流框架:OpenCompass、UltraEval、LM Eval Harness
-
GPT-4
-
Implementation details:
-
使用XTuner工具和QLoRA方法微调基础模型,在8×A100 GPU上训练
-
主要微调超参数:batch size为1,max length为2048,学习率2e-4,AdamW优化器
metric:关键答案抽取准确率
5.3 实验结果
5.3.1 KAF测试集上xFinder vs. RegEx的抽取准确率对比
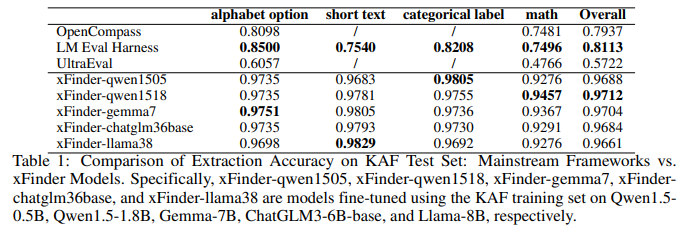
目的:评估使用KAF训练集微调后的xFinder模型在KAF测试集上的关键答案抽取性能,与主流框架的RegEx方法进行对比
涉及图表:表1
实验细节概述:选取19个不同规模(0.5B~8B)的LLM,使用KAF训练集进行微调,在KAF测试集上评估抽取准确率,与OpenCompass、UltraEval和LM Eval Harness的RegEx方法进行对比
结果:
-
使用KAF训练集微调的xFinder模型具有很高的有效性,尽管模型参数规模差异16倍,但抽取准确率差异不超过0.5%,说明KAF数据集质量高
-
xFinder模型在各类型问题上的准确率均显著高于主流框架的RegEx方法
5.3.2 KAF泛化集上xFinder vs. 其他模型的抽取准确率对比
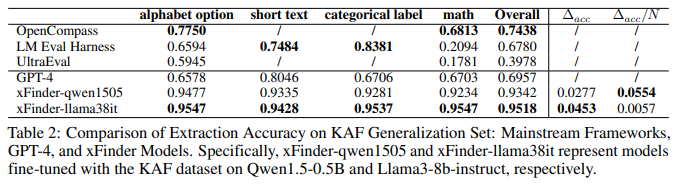
目的:评估xFinder在未见过的任务上的抽取能力
涉及图表:表2
实验细节概述:选取2个有代表性的xFinder模型,在KAF泛化集上评估抽取准确率,与GPT-4、OpenCompass、UltraEval和LM Eval Harness进行对比
结果:
-
xFinder在泛化集上保持了较高的抽取准确率,而主流框架的RegEx方法表现很差,尤其在抽取数学问题的关键答案时
-
即使是GPT-4也难以从复杂多变的LLM输出中准确抽取关键答案
-
xFinder展现了很好的泛化能力
5.3.3 实验三、在真实场景下使用xFinder和主流评估框架评估LLM性能
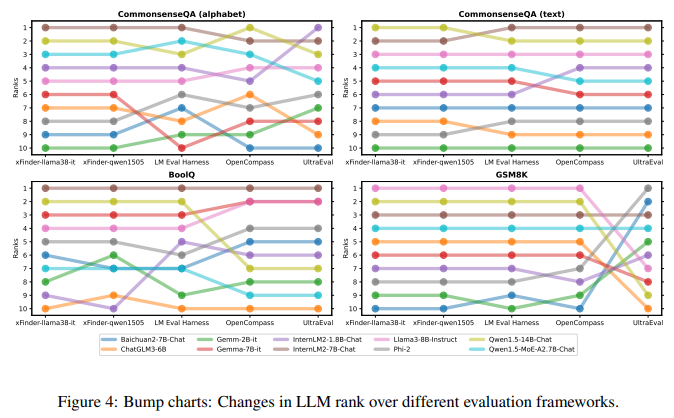
目的: 验证在实际LLM评估任务中使用xFinder替代正则表达式抽取答案的有效性
涉及图表: 图4,表8-27
实验细节概述:
-
选择xFinder-qwen1505(∆acc/N最高)和xFinder-llama38it(∆acc最高)用于真实场景评估
-
在14个主流评估任务上,使用xFinder-qwen1505、xFinder-llama38it和主流评估框架评估10个LLM的性能,对比LLM排名差异
结果:
-
主流评估框架的LLM排名存在显著差异,说明基于正则表达式的方法不可靠,可能影响模型评估和排名
-
使用不同基础模型微调的xFinder在同一任务上对LLM的排名比较一致,表明xFinder更加稳定可靠
-
将评估任务设置为字母选项的可靠性值得怀疑,建议减少现有评估框架对字母选项格式的依赖
4 总结后记
本论文针对评估大语言模型(LLM)的关键答案提取问题,提出了一种名为xFinder的专用模型。通过构建高质量的KAF数据集并在此基础上微调模型,实现了在多个评估任务上相比主流基于正则表达式的方法取得更高的提取准确率。实验结果表明,所提xFinder模型具有更强的鲁棒性和泛化能力,为提高LLM评估的可靠性提供了新的思路。
疑惑和想法:
-
除了微调方法,是否可以探索基于prompt engineering的方式来适配xFinder到新的任务?
可借鉴的方法点:
-
针对特定问题构建高质量数据集并微调模型的思路可以推广到其他LLM评估任务,如事实性评估、对齐度评估等。
-
采用自洽性(self-consistency)策略生成高质量标注数据的方法可以应用到其他需要人工标注的场景,提高标注效率。
-
系统测试不同提示形式对LLM生成内容的影响,有助于设计出更加有效和公平的评估方案。