周末遛狗时,我想起一个老问题:神经网络能预测三角形的面积吗?
神经网络非常擅长分类,例如根据花瓣长度和宽度以及萼片长度和宽度预测鸢尾花的种类(setosa、versicolor 或 virginica)。神经网络还擅长一些回归问题,例如根据城镇房屋的平均面积、城镇的税率、与最近大城市的距离等预测城镇的房价中位数。
但神经网络并不适用于普通的数学计算,例如根据底边和高计算三角形的面积。如果你的小学数学有点生疏,我会提醒你,三角形的面积是底边乘以高的 1/2。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
我在一家大型科技公司工作,PyTorch 是官方首选的神经网络代码库,也是我个人首选的库。周末遛狗时,我决定使用 PyTorch 1.6 版(当前版本)预测三角形面积。
我编写了一个程序,以编程方式生成 10,000 个训练样本,其中底边和高边的值是 0.1 到 0.9 之间的随机值(因此面积在 0.005 到 0.405 之间)。我创建了一个 2-(100-100-100-100)-1 神经网络 — 2 个输入节点、4 个隐藏层(每个隐藏层有 100 个节点)和一个输出节点。我在隐藏节点上使用了 tanh 激活,在输出节点上没有使用激活。
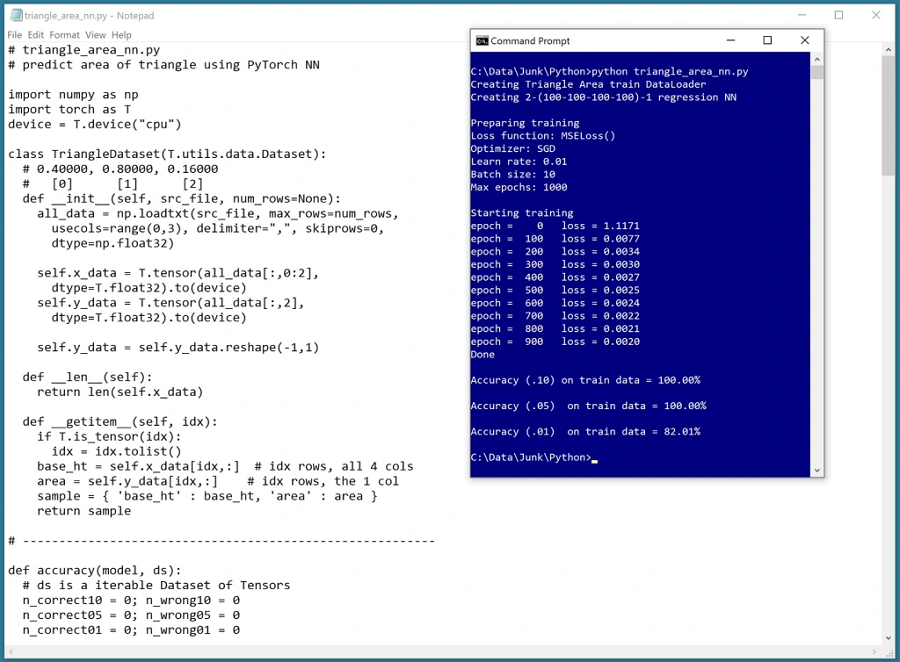
我使用 10 个样本作为批次对网络进行了 1,000 个周期的训练。
训练后,网络正确地预测了 100% 的训练项目在正确区域的 10% 以内,100% 的训练项目在正确区域的 5% 以内,82% 的训练项目在正确区域的 1% 以内。这是否是一个好结果取决于你的观点。
很有趣。深度学习引起了很多关注,并且有大量关于该主题的研究活动。但这不是魔术。

在我思考三角形的那个周末,我看了一部 1967 年的老间谍电影《比男杀手更致命》,里面的女杀手都留着蜂窝发型。左图:女演员 Elke Sommer 扮演主要杀手。我不知道这种发型是怎么回事。中图和右图:互联网图片搜索返回了不少这样的图片,所以我猜蜂窝发型现在有时仍然在使用。
我的代码如下:
# triangle_area_nn.py
# predict area of triangle using PyTorch NN
import numpy as np
import torch as T
device = T.device("cpu")
class TriangleDataset(T.utils.data.Dataset):
# 0.40000, 0.80000, 0.16000
# [0] [1] [2]
def __init__(self, src_file, num_rows=None):
all_data = np.loadtxt(src_file, max_rows=num_rows,
usecols=range(0,3), delimiter=",", skiprows=0,
dtype=np.float32)
self.x_data = T.tensor(all_data[:,0:2],
dtype=T.float32).to(device)
self.y_data = T.tensor(all_data[:,2],
dtype=T.float32).to(device)
self.y_data = self.y_data.reshape(-1,1)
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
if T.is_tensor(idx):
idx = idx.tolist()
base_ht = self.x_data[idx,:] # idx rows, all 4 cols
area = self.y_data[idx,:] # idx rows, the 1 col
sample = { 'base_ht' : base_ht, 'area' : area }
return sample
# ---------------------------------------------------------
def accuracy(model, ds):
# ds is a iterable Dataset of Tensors
n_correct10 = 0; n_wrong10 = 0
n_correct05 = 0; n_wrong05 = 0
n_correct01 = 0; n_wrong01 = 0
# alt: create DataLoader and then enumerate it
for i in range(len(ds)):
inpts = ds[i]['base_ht']
tri_area = ds[i]['area'] # float32 [0.0] or [1.0]
with T.no_grad():
oupt = model(inpts)
delta = tri_area.item() - oupt.item()
if delta < 0.10 * tri_area.item():
n_correct10 += 1
else:
n_wrong10 += 1
if delta < 0.05 * tri_area.item():
n_correct05 += 1
else:
n_wrong05 += 1
if delta < 0.01 * tri_area.item():
n_correct01 += 1
else:
n_wrong01 += 1
acc10 = (n_correct10 * 1.0) / (n_correct10 + n_wrong10)
acc05 = (n_correct05 * 1.0) / (n_correct05 + n_wrong05)
acc01 = (n_correct01 * 1.0) / (n_correct01 + n_wrong01)
return (acc10, acc05, acc01)
# ----------------------------------------------------------
class Net(T.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hid1 = T.nn.Linear(2, 100) # 2-(100-100-100-100)-1
self.hid2 = T.nn.Linear(100, 100)
self.hid3 = T.nn.Linear(100, 100)
self.hid4 = T.nn.Linear(100, 100)
self.oupt = T.nn.Linear(100, 1)
T.nn.init.xavier_uniform_(self.hid1.weight) # glorot
T.nn.init.zeros_(self.hid1.bias)
T.nn.init.xavier_uniform_(self.hid2.weight) # glorot
T.nn.init.zeros_(self.hid2.bias)
T.nn.init.xavier_uniform_(self.hid3.weight) # glorot
T.nn.init.zeros_(self.hid3.bias)
T.nn.init.xavier_uniform_(self.hid4.weight) # glorot
T.nn.init.zeros_(self.hid4.bias)
T.nn.init.xavier_uniform_(self.oupt.weight) # glorot
T.nn.init.zeros_(self.oupt.bias)
def forward(self, x):
z = T.tanh(self.hid1(x)) # or T.nn.Tanh()
z = T.tanh(self.hid2(z))
z = T.tanh(self.hid3(z))
z = T.tanh(self.hid4(z))
z = self.oupt(z) # no activation
return z
# ----------------------------------------------------------
def main():
# 0. make training data file
np.random.seed(1)
T.manual_seed(1)
hi = 0.9; lo = 0.1
train_f = open("area_train.txt", "w")
for i in range(10000):
base = (hi - lo) * np.random.random() + lo
height = (hi - lo) * np.random.random() + lo
area = 0.5 * base * height
s = "%0.5f, %0.5f, %0.5f \n" % (base, height, area)
train_f.write(s)
train_f.close()
# 1. create Dataset and DataLoader objects
print("Creating Triangle Area train DataLoader ")
train_file = ".\\area_train.txt"
train_ds = TriangleDataset(train_file) # all rows
bat_size = 10
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True)
# 2. create neural network
print("Creating 2-(100-100-100-100)-1 regression NN ")
net = Net()
# 3. train network
print("\nPreparing training")
net = net.train() # set training mode
lrn_rate = 0.01
loss_func = T.nn.MSELoss()
optimizer = T.optim.SGD(net.parameters(),
lr=lrn_rate)
max_epochs = 1000
ep_log_interval = 100
print("Loss function: " + str(loss_func))
print("Optimizer: SGD")
print("Learn rate: 0.01")
print("Batch size: 10")
print("Max epochs: " + str(max_epochs))
print("\nStarting training")
for epoch in range(0, max_epochs):
epoch_loss = 0.0 # for one full epoch
epoch_loss_custom = 0.0
num_lines_read = 0
for (batch_idx, batch) in enumerate(train_ldr):
X = batch['base_ht'] # [10,4] base, height inputs
Y = batch['area'] # [10,1] correct area to predict
optimizer.zero_grad()
oupt = net(X) # [10,1] computed
loss_obj = loss_func(oupt, Y) # a tensor
epoch_loss += loss_obj.item() # accumulate
loss_obj.backward()
optimizer.step()
if epoch % ep_log_interval == 0:
print("epoch = %4d loss = %0.4f" % \
(epoch, epoch_loss))
print("Done ")
# 4. evaluate model
net = net.eval()
(acc10, acc05, acc01) = accuracy(net, train_ds)
print("\nAccuracy (.10) on train data = %0.2f%%" % \
(acc10 * 100))
print("\nAccuracy (.05) on train data = %0.2f%%" % \
(acc05 * 100))
print("\nAccuracy (.01) on train data = %0.2f%%" % \
(acc01 * 100))
if __name__ == "__main__":
main()原文链接:用神经网络预测三角形面积 - BimAnt