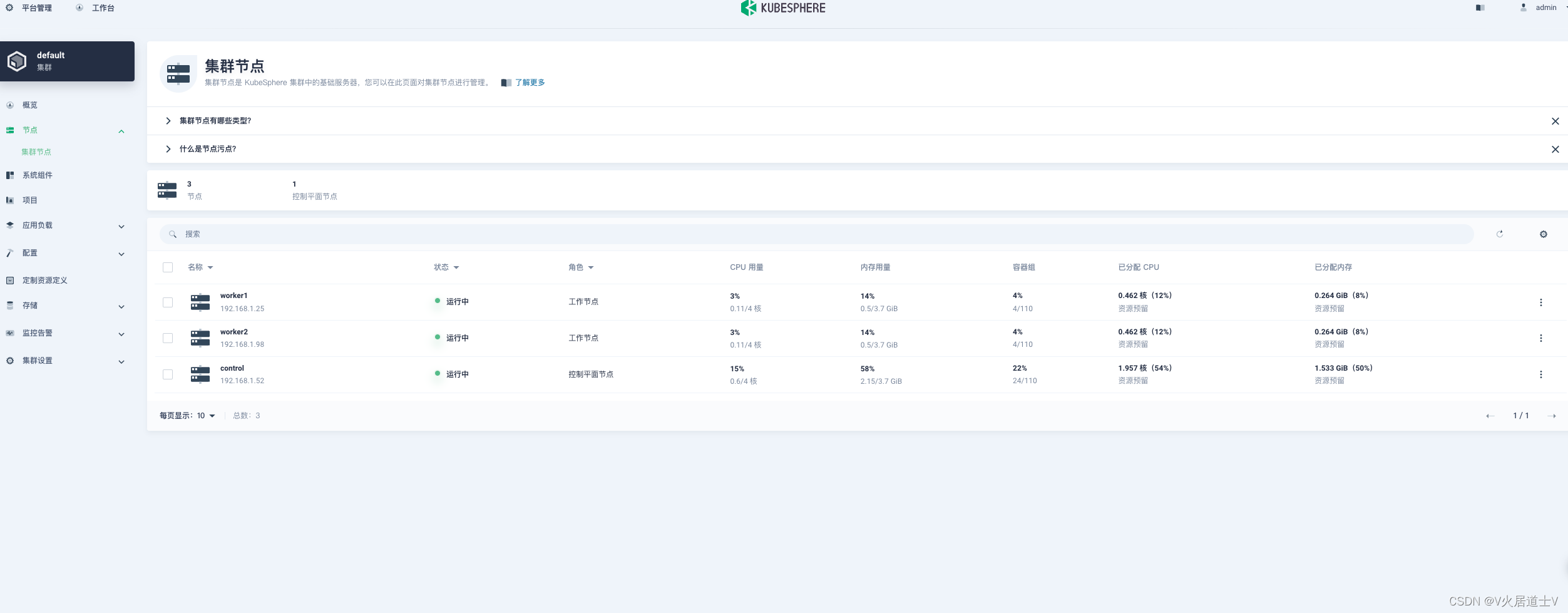
模型效果取决于数据效果,但在精细度上控制不够,只是大力出奇迹,这样有很大的问题:
(1)数据量太多或者没有这方面的数据,模型学不会怎么办
(2)安全性问题,模型输出一些不该输出的东西
所以InstructGPT就是标一点数据然后把模型微调一下
Abstract
Making language models bigger does not inherently make them better at following a user’s intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters.Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
翻译:
增大语言模型的规模并不一定能使其更好地遵循用户的意图。例如,大型语言模型可能生成不真实、有毒或对用户毫无帮助的输出。换句话说,这些模型与用户并不一致。在这篇论文中,我们展示了一种通过使用人类反馈进行微调的方式来使语言模型与用户意图保持一致的方法,这适用于广泛的任务。从标注者编写的提示和通过 OpenAI API 提交的提示开始,我们收集了标注者展示所需模型行为的演示数据集,并使用这些数据集通过监督学习来微调 GPT-3。然后,我们收集了一个模型输出排名的数据集,用这些数据通过人类反馈的强化学习来进一步微调这个监督模型。我们将由此产生的模型称为 InstructGPT。在我们提示分布上的人类评估中,尽管参数数量减少了 100 倍,但1.3B参数的 InstructGPT 模型的输出还是优于 175B 参数的 GPT-3 的输出。此外,InstructGPT 模型在真实性方面有所提高,在生成有毒输出方面有所减少,同时在公共 NLP 数据集上的性能回退最小。尽管 InstructGPT 仍然会犯一些简单的错误,但我们的结果显示,使用人类反馈进行微调是将语言模型与人类意图保持一致的一个有希望的方向。
总结:
在人类的反馈上做微调
对输出的概率分布采样打标谁更好,排序,然后丢进强化学习学习策略
Introduction
训练时的目标只是预测文本的下一个词,和我们的使用它的意图还是有不一样的
使用基于人类反馈的强化学习(RLHF)
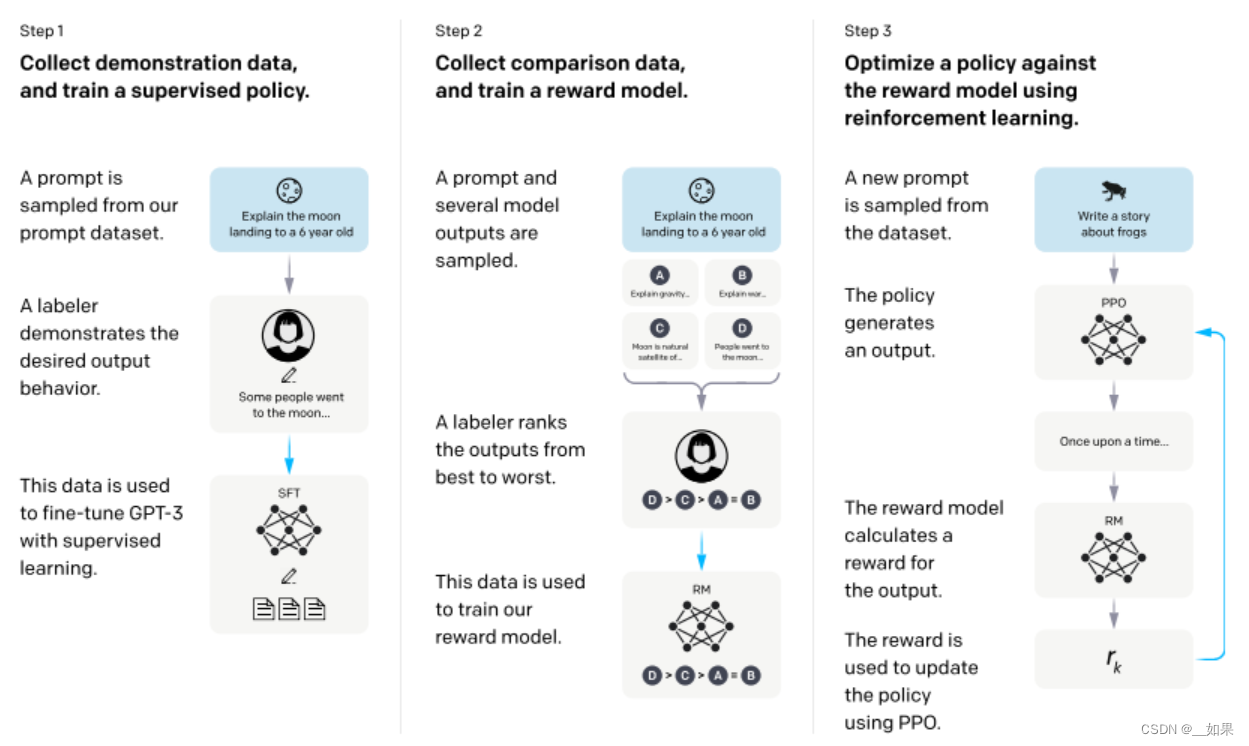
step1:
首先找一些人来写各种各样的问题,称为prompt,这里是:向6岁的小孩解释什么是月亮
然后让人来写出一个答案,这里是:一些人去了月球....
把问题和答案拼成一段话,微调GPT3
在人类标注的数据上微调出来的模型叫作SFT,有监督的微调
但是人写答案很贵,所以
step2:
将问题喂给SFT,对它生成的概率分布对应的答案让人去排序,将排序结果结果丢给强化学习模型训练,使其对答案打的分数满足排序的顺序
step3:
根据RM的打分结果,继续优化step1的SFT
Labelers significantly prefer InstructGPT outputs over outputs from GPT-3
InstructGPT models show improvements in truthfulness over GPT-3
InstructGPT shows small improvements in toxicity over GPT-3, but not bias
We can minimize performance regressions on public NLP datasets by modifying our RLHF fine-tuning procedure
Our models generalize to the preferences of “held-out” labelers that did not produce any training data
Public NLP datasets are not reflective of how our language models are used
InstructGPT models show promising generalization to instructions outside of the RLHF finetuning distribution
InstructGPT still makes simple mistakes
与GPT-3的输出相比,标注者明显更喜欢InstructGPT的输出
与GPT-3相比,InstructGPT模型的真实性有所提高
与GPT-3相比,InstructGPT在毒性方面略有改善,但偏见上没有太多提升
通过修改我们的RLHF微调过程来减少公共NLP数据集上性能的下降
我们的模型推广到没有产生任何训练数据的“搁置”标注者的偏好
公开的NLP数据集不能反映我们的语言模型是如何被使用的,因为数据分布不一致
InstructGPT模型对RLHF调优分布之外的指令显示出有希望的泛化
InstructGPT仍然会犯一些简单的错误
Methods and experimental details
Models
Supervised fine-tuning (SFT)
把GPT3在标注好的prompt上重新训练一次,1w3的数据量少,会过拟合,但是不要紧,因为是用来初始化后面的模型而非直接应用,反而还会有点帮助
Reward modeling (RM)


Reinforcement learning (RL)
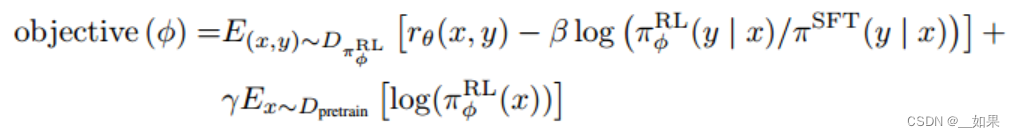
用PPO算法,也就是对这个函数梯度下降

Discussion
The cost of increasing model alignment is modest relative to pretraining
InstructGPT三个模型的训练成本比预训练模型的成本低很多
![c语言:利用随机函数产生20个[120, 834] 之间互不相等的随机数, 并利用选择排序法将其从小到大排序后输出(每行输出5个)](https://img-blog.csdnimg.cn/direct/6cfdce68f41d4cb1971a3175f31e3742.png)


![[STM32-HAL库]Flash库-HAL库-复杂数据读写-STM32CUBEMX开发-HAL库开发系列-主控STM32F103C6T6](https://img-blog.csdnimg.cn/direct/db1f0cc36a25422087ab111766224fe1.png)