前面讲解了注意力神经网络
一、BERT模型
1、什么是BERT
它是由谷歌在2018年提出的 双向Transformer 编码器模型。
Bidirectional Encoder Representations from Transformers.
主要使用了Transformer的编码器
Transformer 编码器堆叠;
预训练 + 精调两步结构。
BERT的创新之处主要在于预训练的微调,主要包括Mask的语言模型和NSP 下一句的预测,前者可以捕捉单词间的表示,后者可以捕捉句子间的表示。
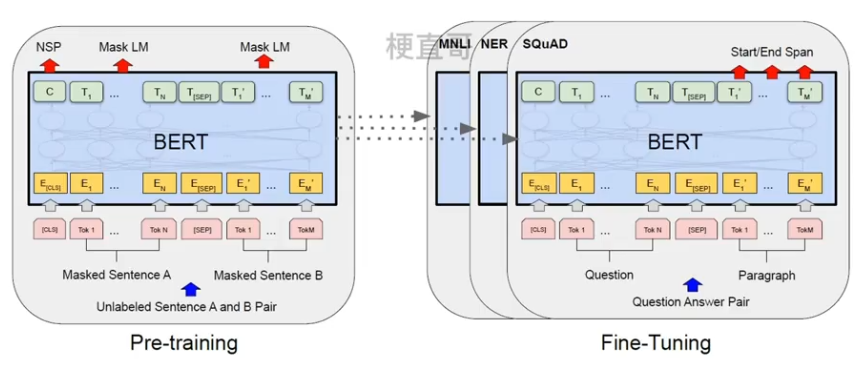
2、模型结构
主要特点在于其双向性,利用双向语言表示来训练模型。

此处对比当年大火的三个模型在网络结构上的区别如下:

在传统的Transformer模型中只考虑了左边的语境对当前词语的影响,而BERT模型同时考虑了左右两边的影响。
ELMo看起来也是双向的,但是其实他们的目标函数是不同的:
EMLo的目标函数是 P(wi | w1,w2....wi-1) P(wi | wi+1,...,wn)
独立训练两个表示然后进行拼接。
3、Embedding词嵌入
将文本中的词语 (或字符) 转化为向量表示;
通过预训练好的词向量矩阵来实现,用来捕捉词语间语义关系。
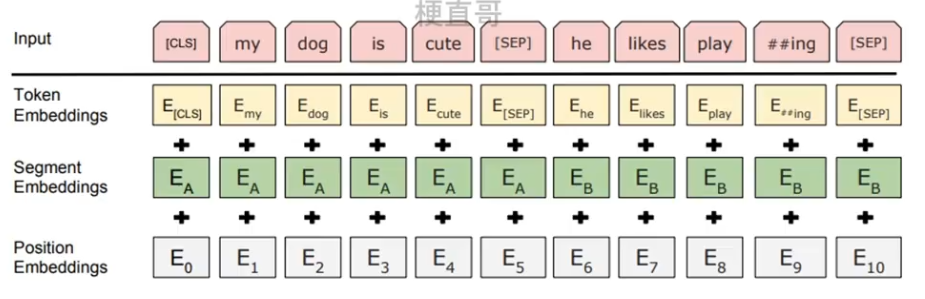
与传统的词袋模型不同,BERT的词嵌入是一个实数向量,可以通过词语之间的距离来判断词语之间的相似度。具体来说,它是由三种Embedding求和而成的。
Token Embeddings 是词向量;
Segment Embeddings 用来区别两种句子,因为预训练不光要作语言模型还要完成其他任务,比如两个句子作为输入的分类任务。
Position Embeddings 不同于Transformer中的利用正余弦函数的求法,BERT中是由一个学习出来的模型直接得到的。
4、预训练
(1)Masked语言模型 MLM
通过随机掩盖一些词语学习语义关系,更好地理解上下文信息。
随机mask掉 15% 的token,而不是把每个词都预测一遍,最终的损失函数只计算被mask掉的token。

如果一直用标记MASK来代替会影响模型,因为在实际预测中是碰不到这种标记的。
所以在随机mask时,10%的单词会被替换成其他单词,产生一些随机性,10%的单词不会被替换,剩下的80%才会被替换成MASK标记。
要注意的是 MASK LM预训练阶段时的模型并不知道真正被MASK的是哪一个词,所以模型的每一个词都要关注。此外由于序列的模型太大(512维),会影响训练速度,所以90%的 step步长 都是用sequence length = 128去训练的。
(2)下一句预测
面向问答和自然语言推理任务;
使模型理解两个句子间关系。
注意语料选文档级别的!!
训练的输入是句子A和B,B有一半的概率是A的下一句,模型需要预测B是不是A的下一句。
预训练的过程中可达97-98%准确率。

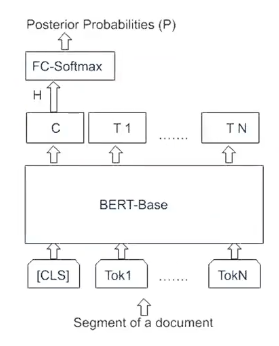
5、精调Fine-Tuning
主要是为了特定任务下提高准确率;
适用于各种不同的任务,比如分类任务/问答任务/序列标注等。‘
分类任务中:
通常只会更新BERT模型的最后一层,其他层权重不改变;
此外微调的数据通常要比预训练的数据更小,因此训练时间更短。
对于句子级别分类任务中,增加 softmax 层。
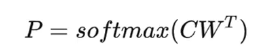
MNLI评估文本推理任务能力
QQP 和QNLI 测试问答任务效果
STS-B 测试语义相似度判定效果
MRPC测试抄袭检测中的效果
RTE评估文本蕴含任务的能力
SWAG评估推理生成任务能力
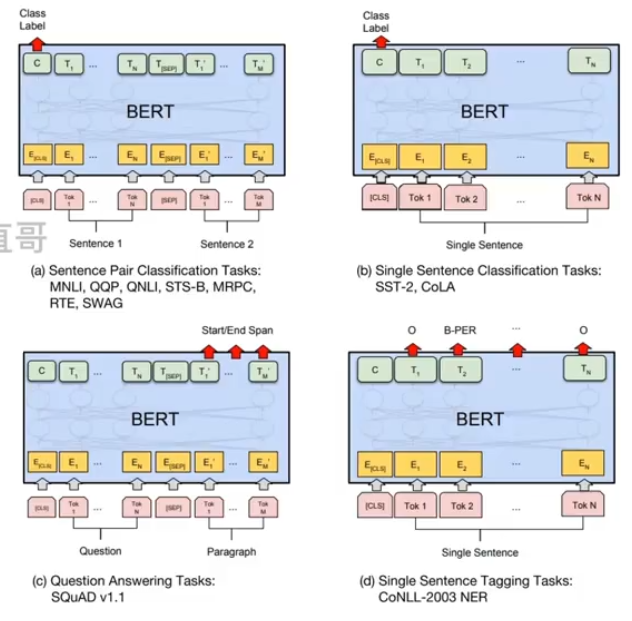
SST-2测试情感分析任务效果
COLA 测试模型在语言规则接受性判定任务中的效果
SQUAD 测试模型在问答任务中的效果
CONLL-2003NER 测试模型在命名实体识别任务中的效果
6、优缺点

二、GPT系列模型
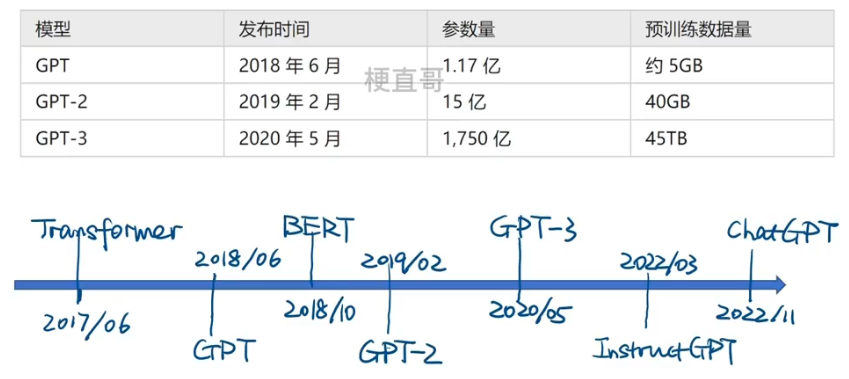
1、发展历程
(GPT)系列
Generative Pre-trained Transformer
秉承了不断堆叠Transformer结构的思想,通过提升训练语料的规模和质量,进一步提升网络的参数数量,来实现迭代和更新。
2、GPT-1 —— 无监督生成式预训练
模型思想
在GPT1之前的传统的NLP模型,我们使用大量数据对模型进行任务相关的监督式训练,但是有两个缺点:高质量标注数据获取难,模型泛化难。
将无监督的预训练与有监督的下游任务精调相结合。换句话说就是让Transformer的Decoder来生成大量的数据进行预训练,因此可以认为是生成式的预训练模型。

12个Transformer中的Decoder模块经修改后组成,每个Transformer块使用了多头注意力机制,然后通过全连接得到输出的概率分布。
注意Transformer本身是由6个encoder和decoder组成的,但是GPT全是Decoder。
词汇表有4万个token,位置嵌入包含512个位置(同Transformer),多头注意力包含768维状态和12个注意力头,基于位置的前向网络包含了3072个内部状态。
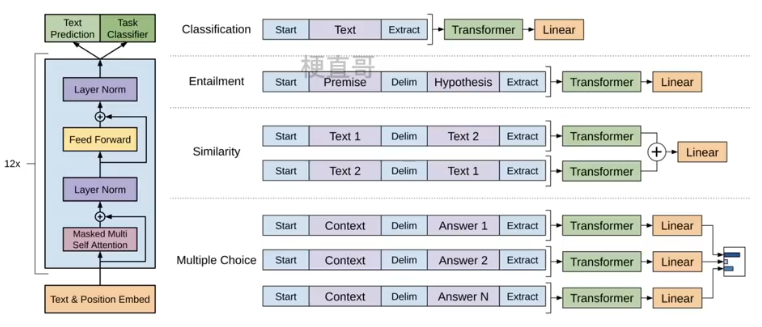
右边是不同NLP任务下,输入处理和输出结构上的不同。
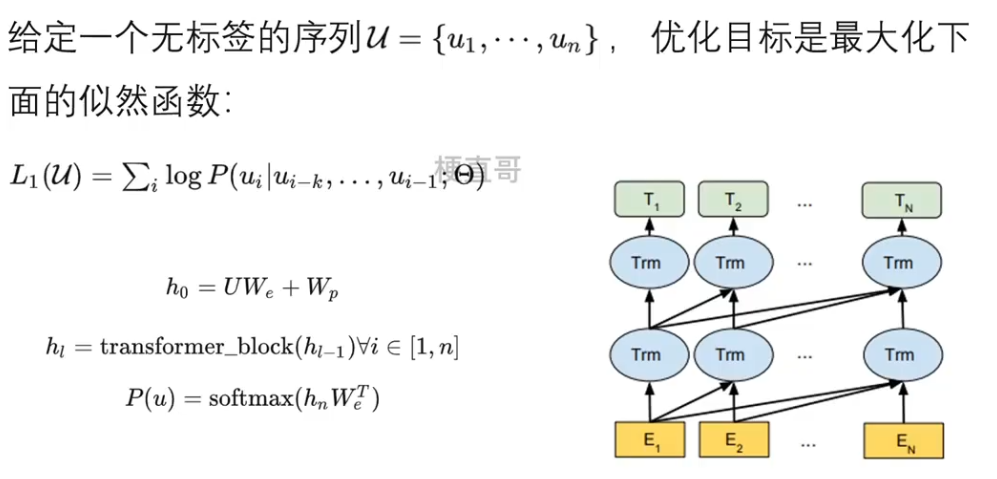
GPT-1无监督预训练
GPT-1的无监督预训练是基于语言模型进行训练的。
k 是滑动窗口的大小,P是条件概率,θ 是模型的参数,这些参数也是使用sgd 随机梯度下降进行优化。
U 是当前时间片的上下文token,We 是词嵌入矩阵,Wp是位置嵌入矩阵,n 是层数。
从h0开始逐层传递到hn层,最后使用softmax层进行输出,也就是预测下一个词语。
GPT-1有监督精调
当得到无监督的预训练模型之后,运用到有监督的任务当中。
Wy 是全连接层的参数,有监督的训练精调的目标是最大化 L2,
最终的目标是L3。L1是预训练的。λ 相当于预训练和精调之间的平衡。

GPT-1数据集
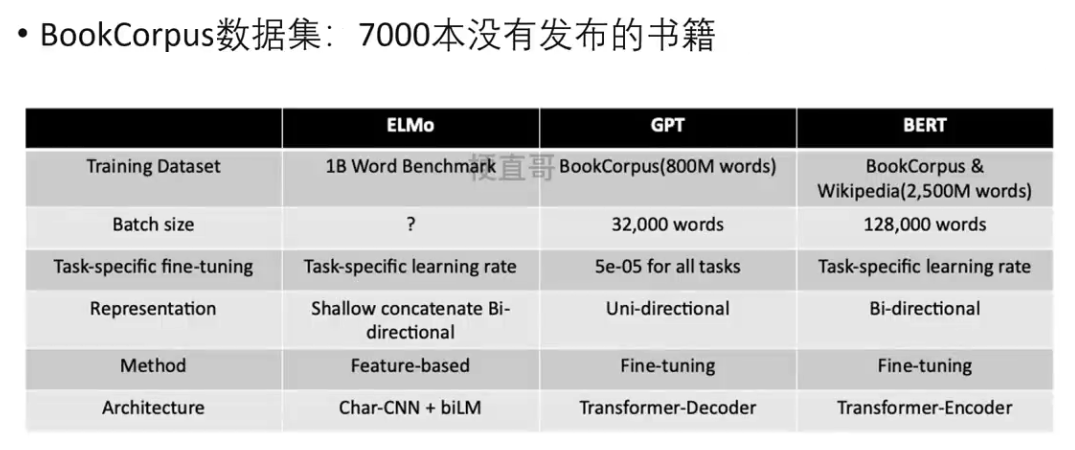
选择这个数据集的原因有两点,第一,这样一来,这个数据集拥有更长的上下文依赖关系,使得模型可以长期的学习这种长期的依赖关系的信息;第二,这些书籍没有发布,所以很难在下游数据集上见到,因此更能验证模型的泛化能力。
GPT-1性能
在监督学习12个任务中9个SOTA;
比LSTM模型稳定,泛化能力强;
简单的领域专家,而非通用语言学家;
无监督生成式预训练替代监督式学习。
3、GPT-2 —— 多任务学习
模型思想
实现多任务在同一模型上学习,扩增数据集和模型参数。

GPT-2模型思想
GPT-2的训练目标是使用无监督模型做有监督的任务。
任何有监督任务都是语言模型的一个子集。
当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型学习便可以完成其他有监督学习的任务。

GPT-2数据集

GPT-2模型参数

GPT-2性能
8个语言模型中7个SOTA;
Childrens Book Test”数据集命名实体识别任务超SOTA7%;
LAMBADA”数据集将困惑度从99.8降到8.6;
阅读理解数据中超过4基线模型中3个。
4、GPT-3 —— 情景学习
模型思想
海量参数1750亿,45TB训练数据,大力出奇迹。
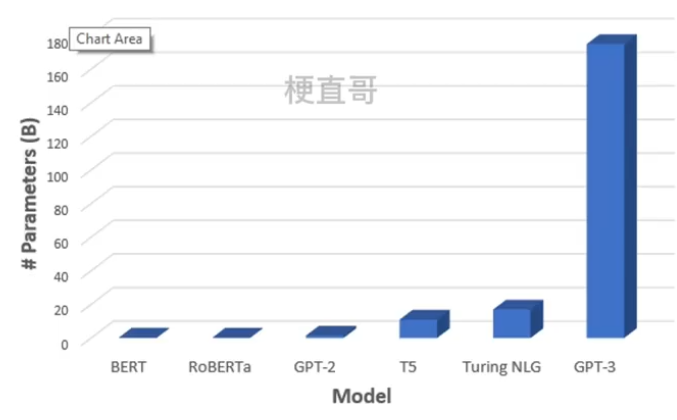
对话模式
GPT系列都是用Decoder进行训练,采用输入一句话输出一句话的对话模式。
对模型进行引导,教会它应当输出什么内容。
他提出了一种基于提示的情景式学习方式,对于不同的任务,仅需要插入不同的prompt参数,每个任务都单独训练prompt参数而不是预训练语言模型,这样可以大大缩短训练时间,也提高了模型的使用率。
若想理解其中的思想,要从机器学习中的元学习讲起。

元学习 Meta-Learning
通过学习任务间共性和差异,发现规律,并将其应用到新任务。
不同于多任务学习,多任务学习是通过同样的训练过程和参数来实现任务的相互促进和优化;而元学习是通过少量数据寻找合适的初始化范围,让模型能够在有限的数据集上快速拟合,这种方法可以使得模型具有更强的泛化能力。
元学习的核心思想就是寻找一个良好的初始值,使得模型能够快速适应新的任务。
具体来说,元学习的学习任务包括内外两个小循环:
在外循环中,模型通过多个任务来学习获得初始值,
在内循环中,模型使用初始值来快速适应新的任务,如果模型能够在少量数据上快速适应新任务就说明初始值是一个良好的,否则模型就需要进行更新。

情景学习 In-context Learning
把不同的场景作为内循环,而SGD作为外循环,来提高模型性能从上下文信息中学习语言含义和语法规则。
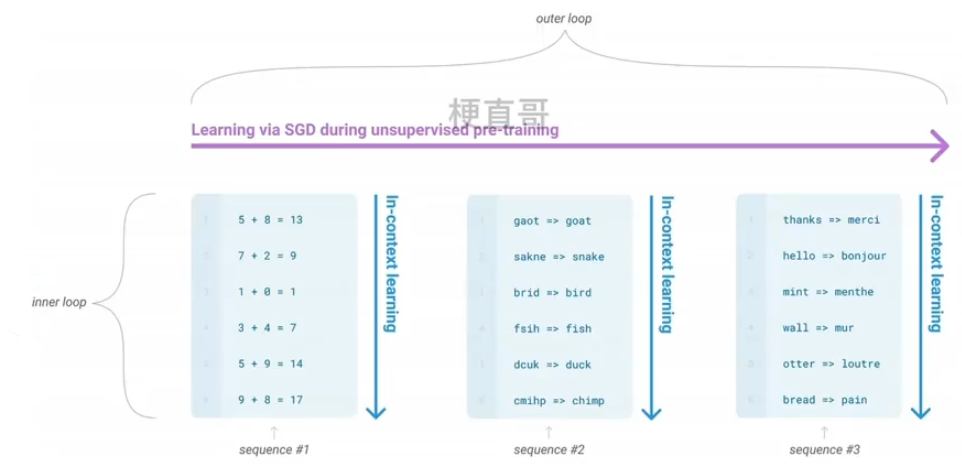
举个栗子:
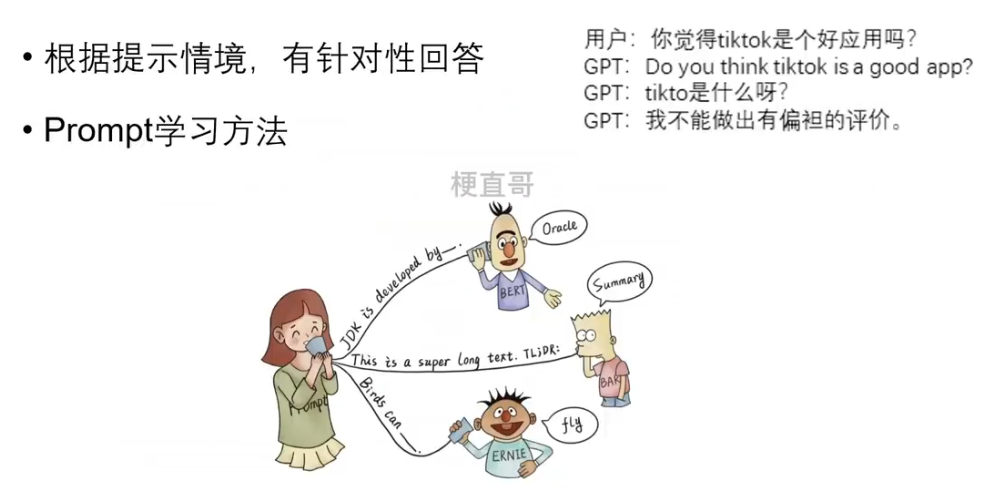
零样本、单样本、少量样本
Zero-shot Learning
One-shot Learning
Few-shot Learning
GPT3中使用了这三种学习方式。

GPT-3数据集

GPT-3模型参数
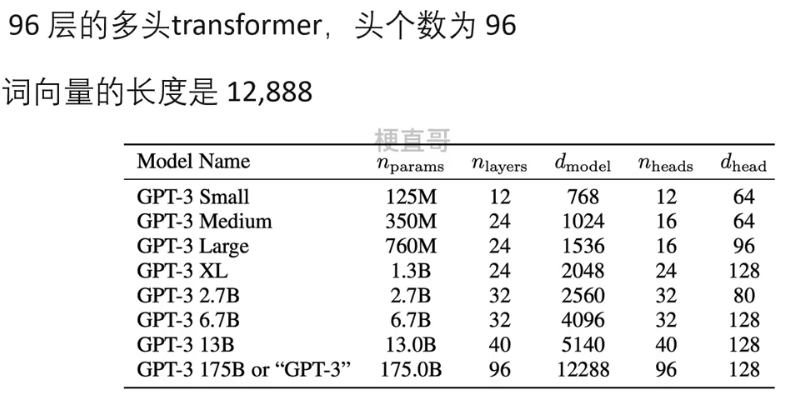
GPT-3性能
在很多复杂的NLP任务中取得了非常震惊的效果;
transformer架构,模型结构并没有创新性的设计;
典型不足:
不会判断命题有效与否;
难保证生成文章不含敏感内容;
不能保证长文章的连贯性,存在不停重复问题。
三、T5模型
1、基本思想
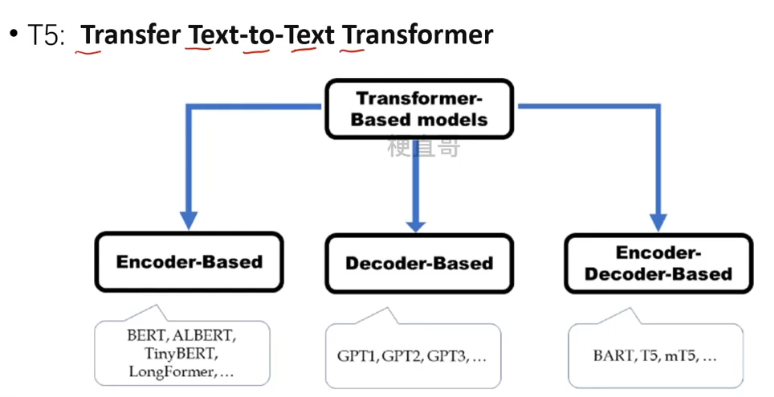
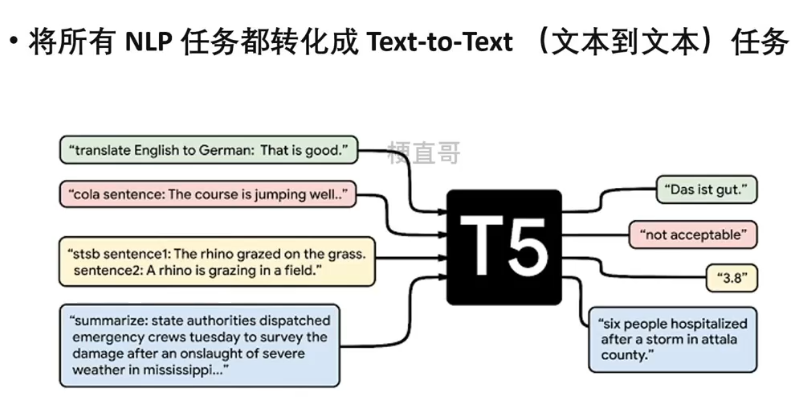
万物皆可 Seq2Seq
2、词表示发展史
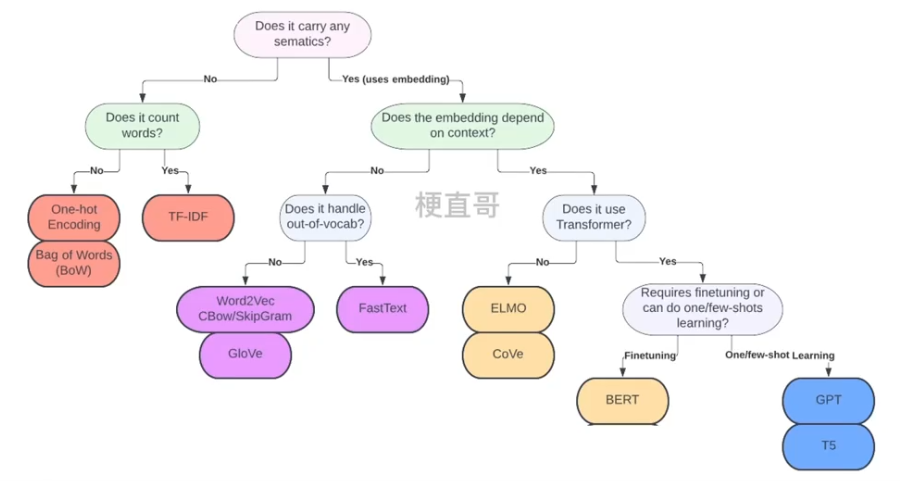
3、历史贡献

4、模型架构
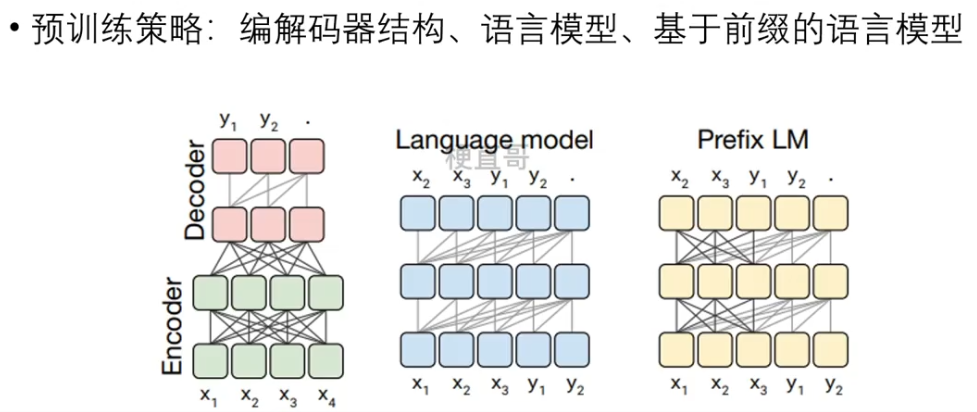
掩码操作

第一种结果最好。
5、预训练策略