kube-prometheus
基于github安装
选择对应的版本
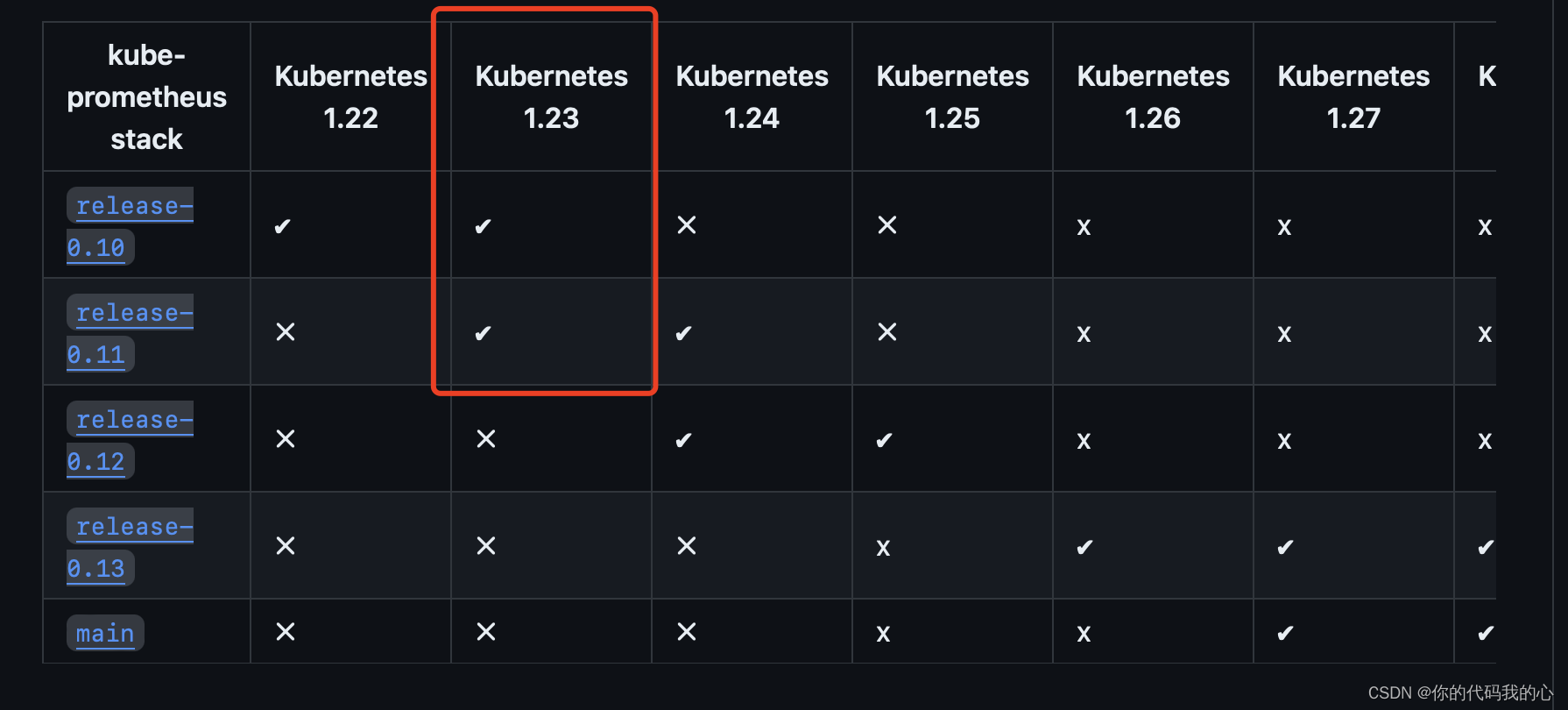
这里选择 https://github.com/prometheus-operator/kube-prometheus/tree/release-0.11
下载修改为国内镜像源
image: quay.io 改为 quay.mirrors.ustc.edu.cn
image: k8s.gcr.io 改为 lank8s.cn创建 prometheus-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: monitoring
name: prometheus-ingress
spec:
ingressClassName: nginx
rules:
- host: grafana.wolfcode.cn
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grafana
port:
number: 3000
- host: prometheus.wolfcode.cn
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-k8s
port:
number: 9090
- host: alertmanager.wolfcode.cn
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: alertmanager-main
port:
number: 9093
host文件修改
根据自己的情况配置
# Mac 下
sudo vim /etc/hosts
192.168.10.102 grafana.wolfcode.cn
192.168.10.102 prometheus.wolfcode.cn
192.168.10.102 alertmanager.wolfcode.cn
# 先创建 setup 由于一些大资源,用apply会报错
kubectl create -f ./manifests/setup/
# 创建 其他
kubectl apply -f ./manifests/
# 查看
kubectl get all -n monitoring
# 成功的结果
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 2/2 Running 0 7m53s
pod/alertmanager-main-1 2/2 Running 0 7m53s
pod/alertmanager-main-2 2/2 Running 0 7m53s
pod/blackbox-exporter-746c64fd88-kdvhp 3/3 Running 0 47m
pod/grafana-5fc7f9f55d-fnhlg 1/1 Running 0 47m
pod/kube-state-metrics-84f49c948f-k8g4g 3/3 Running 0 29m
pod/node-exporter-284jk 2/2 Running 0 47m
pod/node-exporter-p6prn 2/2 Running 0 47m
pod/node-exporter-v7cmd 2/2 Running 0 47m
pod/node-exporter-z6j9g 2/2 Running 0 47m
pod/prometheus-adapter-6bbcf4b845-22gbn 1/1 Running 0 9m49s
pod/prometheus-adapter-6bbcf4b845-n5bnq 1/1 Running 0 9m49s
pod/prometheus-k8s-0 2/2 Running 0 6m28s
pod/prometheus-k8s-1 1/2 ImagePullBackOff 0 5m20s
pod/prometheus-operator-f59c8b954-h6q4g 2/2 Running 0 8m11s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.99.85.3 <none> 9093/TCP,8080/TCP 47m
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 7m53s
service/blackbox-exporter ClusterIP 10.107.220.197 <none> 9115/TCP,19115/TCP 47m
service/grafana ClusterIP 10.100.1.202 <none> 3000/TCP 47m
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 47m
service/node-exporter ClusterIP None <none> 9100/TCP 47m
service/prometheus-adapter ClusterIP 10.100.12.96 <none> 443/TCP 47m
service/prometheus-k8s ClusterIP 10.100.245.37 <none> 9090/TCP,8080/TCP 47m
service/prometheus-operated ClusterIP None <none> 9090/TCP 7m51s
service/prometheus-operator ClusterIP None <none> 8443/TCP 46m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/node-exporter 4 4 4 4 4 kubernetes.io/os=linux 47m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/blackbox-exporter 1/1 1 1 47m
deployment.apps/grafana 1/1 1 1 47m
deployment.apps/kube-state-metrics 1/1 1 1 47m
deployment.apps/prometheus-adapter 2/2 2 2 9m49s
deployment.apps/prometheus-operator 1/1 1 1 47m
NAME DESIRED CURRENT READY AGE
replicaset.apps/blackbox-exporter-746c64fd88 1 1 1 47m
replicaset.apps/grafana-5fc7f9f55d 1 1 1 47m
replicaset.apps/kube-state-metrics-6c8846558c 0 0 0 47m
replicaset.apps/kube-state-metrics-84f49c948f 1 1 1 29m
replicaset.apps/prometheus-adapter-6bbcf4b845 2 2 2 9m49s
replicaset.apps/prometheus-operator-f59c8b954 1 1 1 47m
NAME READY AGE
statefulset.apps/alertmanager-main 3/3 7m53s
statefulset.apps/prometheus-k8s 1/2 7m51s
具体操作
接下来访问我们定义的ingress
访问不了,由于我重新安装了 所以导致我的ingress-nginx没有部署---导致无法访问
ingress安装
最后的最后!!!!还是无法访问,但但但但是在终端通过
curl -H "host: alertmanager.wolfcode.cn" 192.168.10.102
又能打印出网页内容地址--问了一下 ai ,我把代理一关,困扰了我几天的问题终于解决啦
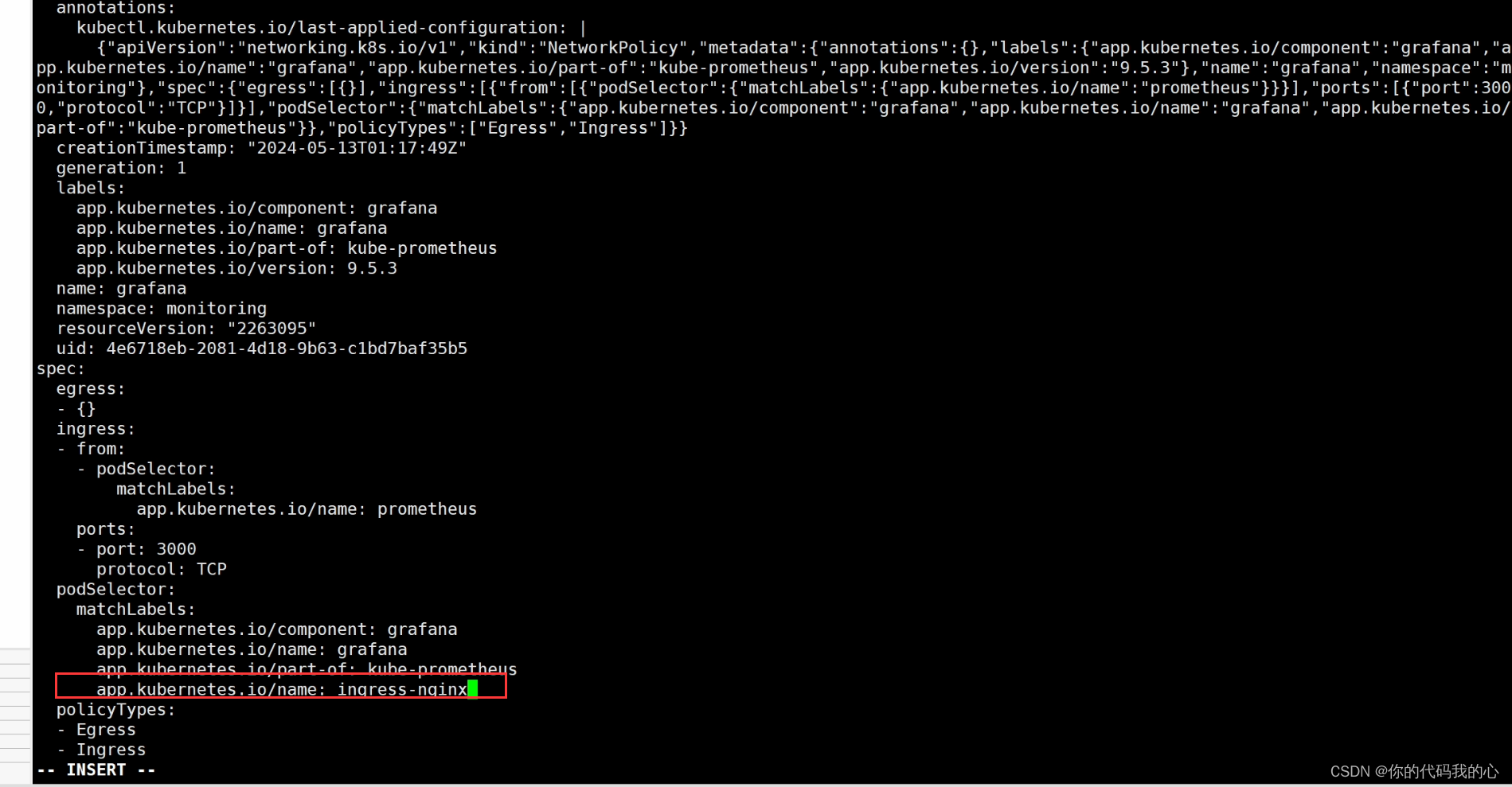
差一个grafana
kubectl edit networkPolicy -n monitoring grafana
内存不够 升级虚拟机内存重启 master报错了
重新安装
kubectl 查看命令是否正常
cd ~ 进入根目录
ll -a 查看是否存在.kube文件
rm -rf .kube/ 删除
systemctl restart docker 重启docker
systemctl restart kubelet 重启kubelet
kubeadm reset 重置
rm -rf /etc/cni/ 删除
# Step 2: 安装 kubeadm、kubelet、kubectl
yum install -y kubelet-1.23.6 kubeadm-1.23.6 kubectl-1.23.6
# 开启自启动
systemctl enable kubelet
#================在k8s-master上执行==============
# Step 1: 初始化master节点
kubeadm init \
--apiserver-advertise-address=192.168.10.100 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.23.6 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
# Step 2: 安装成功后,复制如下配置并执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# Step 3: 查看是否初始化成功
kubectl get nodes
# 其他的参考 https://blog.csdn.net/weixin_41104307/article/details/137704714?spm=1001.2014.3001.5501
# ============分别在 k8s-node1 和 k8s-node2 执行================
# 下方命令可以在 k8s master 控制台初始化成功后复制 join 命令
# Step 1: 将node节点加入master
kubeadm join 192.168.10.100:6443 --token ce9w0v.48oku10ufudimvy3 \
--discovery-token-ca-cert-hash sha256:9ef74dbe219fb48ad72d776be94149b77616b8d9e52911c94fe689b01e47621c
其他节点的处理
kubeadm reset
sudo rm /etc/kubernetes/kubelet.conf
sudo rm /etc/kubernetes/pki/ca.crt
sudo netstat -tuln | grep 10250
reboot
kubeadm join 192.168.10.100:6443 --token 3prl7s.pplcxwsvql7i1s1d \
--discovery-token-ca-cert-hash sha256:9ef74dbe219fb48ad72d776be94149b77616b8d9e52911c94fe689b01e47621c
k8s证书过期参考
token过期解决方案【里面包含重新生成token】
主要是这个镜像
k8s拉取镜像失败处理 ImagePullBackOff ErrImageNeverPull





![[力扣]——231.2的幂](https://img-blog.csdnimg.cn/direct/13db527755ec49f7979314ecbc41e86d.png)