LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images (2024-03-18)
| 文章概要 |
|---|
| 作者: Ruyi Xu; Yuan Yao; Zonghao Guo; Junbo Cui; Zanlin Ni; Chunjiang Ge; Tat-Seng Chua; Zhiyuan Liu; Maosong Sun; Gao Huang |
| 期刊: arXiv 预印版 |
| DOI: 10.48550/arXiv.2403.11703 |
| 摘要: Visual encoding constitutes the basis of large multimodal models (LMMs) in understanding the visual world. Conventional LMMs process images in fixed sizes and limited resolutions, while recent explorations in this direction are limited in adaptivity, efficiency, and even correctness. In this work, we first take GPT-4V and LLaVA-1.5 as representative examples and expose systematic flaws rooted in their visual encoding strategy. To address the challenges, we present LLaVA-UHD, a large multimodal model that can efficiently perceive images in any aspect ratio and high resolution. LLaVA-UHD includes three key components: (1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks. Notably, our model built on LLaVA-1.5 336x336 supports 6 times larger (i.e., 672x1088) resolution images using only 94% inference computation, and achieves 6.4 accuracy improvement on TextVQA. Moreover, the model can be efficiently trained in academic settings, within 23 hours on 8 A100 GPUs (vs. 26 hours of LLaVA-1.5). |
| GitHub链接: https://github.com/thunlp/LLaVA-UHD |
📜 研究核心
“(1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks.”
(1)一种图像模块化策略,将原生分辨率图像划分为更小的可变大小切片,以实现高效和可扩展的编码,
(2)一个压缩模块,进一步压缩来自视觉编码器的图像标记
(3)一个空间模式,用于组织LLM的切片标记。
综合实验表明,LLaVA-UHD的性能优于已建立的LMM,在9个基准测试中训练了2-3个数量级的数据。
⚙️ 内容
“High-Resolution Image Partition Strategy. The goal of image slicing strategy is to determine a split of high-resolution images, with minimal changes to the resolutions of each slice. Given an image in resolution (WI , HI ) and a ViT pretrained in resolution (Wv, Hv), we first determine the number of slices (i.e., the ideal computation) needed to process the image: N = ⌈ WI×HI Wv×Hv ⌉. Then we factorize the slice number N into m columns and n rows: CN = {(m, n)|m × n = N, m ∈ N, n ∈ N}. To select the most appropriate partition, we define a score function to measure the deviation from the standard pretraining setting of ViT:”
高分辨率图像分区策略。图像切片策略的目标是确定高分辨率图像的拆分,同时对每个切片的分辨率进行最小的更改。给定分辨率(WI,HI)的图像和分辨率预训练的ViT(Wv,Hv),我们首先确定处理图像所需的切片数(即理想计算):N = ⌈ WI×HI Wv×Hv ⌉。然后我们将切片编号 N 分解为 m 列和 n 行:CN = {(m, n)|m × n = N, m ∈ N, n ∈ N}。为了选择最合适的分区,我们定义了一个评分函数来衡量与 ViT 标准预训练设置的偏差:
S
(
W
I
,
H
I
,
W
v
,
H
v
,
m
,
n
)
=
−
∣
log
W
I
×
n
H
I
×
m
−
log
W
v
H
v
∣
,
S\left(W_{I}, H_{I}, W_{v}, H_{v}, m, n\right)=-\left|\log \frac{W_{I} \times n}{H_{I} \times m}-\log \frac{W_{v}}{H_{v}}\right|,
S(WI,HI,Wv,Hv,m,n)=−
logHI×mWI×n−logHvWv
,
其中,得分越高 S(·) 表示与 ViT 标准设置的偏差较小,因此,分区可以按如下方式获得:
m ∗ , n ∗ = arg max ( m , n ) ∈ C ˉ S ( W I , H I , W v , H v , m , n ) , m^*,n^*=\arg\max_{(m,n)\in\bar{\mathbb{C}}}S(W_I,H_I,W_v,H_v,m,n), m∗,n∗=arg(m,n)∈CˉmaxS(WI,HI,Wv,Hv,m,n),
“where the candidate set C¯ = CN. In practice, we notice that in some cases, there might be only a few possible factorization schemes for N , especially for prime numbers, which can lead to limited choices and therefore extreme partitions of images. For example, N = 7 has only two extreme partition choices, 1:7 and 7:1. To address the issue, in addition to the ideal slice number N , we also allow a modest change of slice numbers N − 1, N + 1 to incorporate more plausible partition choices. Therefore, the final partition is given by Equation 2, where C¯ = CN−1 ∪ CN ∪ CN+1.”
其中候选集 C ̄ = CN。在实践中,我们注意到,在某些情况下,N 可能只有几种可能的因式分解方案,尤其是对于素数,这可能导致有限的选择,从而导致图像的极端分区。例如,N = 7 只有两个极端的分区选择,即 1:7 和 7:1。为了解决这个问题,除了理想的切片数 N 之外,我们还允许对切片数 N − 1, N + 1 进行适度的更改,以包含更合理的分区选择。因此,最终的分区由等式 2 给出,其中 C ̄ = CN−1 ∪ CN ∪ CN+1。
“Theoretically, we show that the partition strategy guarantees minor expected changes and modest worst-case changes with respect to standard pretraining resolution (Wv, Hv) for each slice. Specifi- cally, we show that for input images where N ≤ 20 and aspect ratio in [1 : 6, 6 : 1], the aspect ratio of each slice resides within [1 : 2, 2 : 1], and the area of each slice resides within [0.33WI HI , 1.5WI HI ]. We refer readers to Section B for full proof details.”
从理论上讲,我们表明,分区策略保证了每个切片的标准预训练分辨率(Wv、Hv)的微小预期变化和适度的最坏情况变化。具体来说,我们表明,对于 N ≤ 20 且纵横比为 [1 : 6, 6 : 1] 的输入图像,每个切片的纵横比位于 [1 : 2, 2 : 1] 以内,每个切片的面积位于 [0.33WI HI , 1.5WI HI ] 以内。
💡 创新点
“these experimental findings shed light on GPT-4V’s potential vulnerabilities in highresolution image processing, warranting further investigation into the implications of these weaknesses and the development of strategies to counter potential adversarial attacks on LMMs.”
这些实验结果(前置试点实验,可看原始论文)揭示了GPT - 4V在高分辨率图像处理中的潜在弱点,值得进一步研究这些弱点的影响,并开发对抗LMMs潜在对抗攻击的策略。
“Combining the results with the public information from OpenAI, we hypothesize the most likely cause is that, there are overlaps in the slices of GPT-4V when the image resolution is not divisible by 512”
结合实验结果和OpenAI公开信息,我们猜测最有可能的原因是,当图像分辨率不可分割为512时,GPT - 4V的切片存在重叠。
总的来说,针对这些问题,该研究提出一种自适应可变大小的图像分块方法,可处理不同宽高比的图片,其在ViT-L/14(336×336)中,最高分辨率达672 × 1008,最低分辨率达336×336。同时为减低图像Token增加所带来的平方级复杂度增加,采用交叉注意力将图像Token数量重新采样到合适的范围,此外,压缩策略不仅减低了高分辨图像输入的计算成本,同时进一步促使ViT原始要求分辨率图像输入的计算成本。
在适应LLM模型输入方面,还有一个问题需要解决,不同宽高比图像的划分是动态的,如何将这种动态信息合理地告知?该研究采用一个简单的方案:使用 “,” 分隔一行中的切片表示,并使用 “\n” 分隔不同的行。
🧩 不足
分辨率限制:最高分辨率达672 × 1008,最低分辨率达336×336(ViT预训练尺寸)
图像切片独立编码,仅在LLM存在相互作用,并未在视觉编码层建立有效链接作用
🔁 研究内容
💧 数据
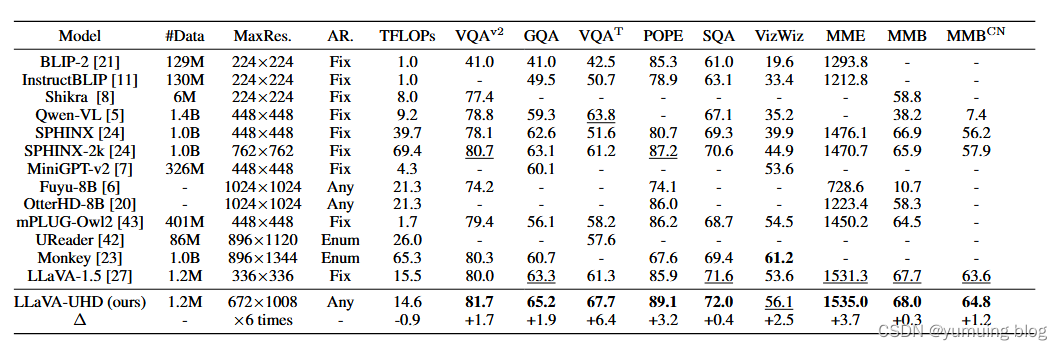
“We adopt 9 popular benchmarks to evaluate our model, including: (1) General visual question answering benchmarks such as VQA-V2 [4], GQA [18], ScienceQA [30], and VizWiz [15]; (2) Optical character based visual question answering benchmark such as TextVQA [36]; (3) Hallucination benchmark such as POPE [22]; (4) Comprehensive benchmarks such as MME [14], MMBench [29], and MMBench-CN [29].”
(1) 通用视觉问答基准,如 VQA-V2 [4]、GQA [18]、ScienceQA [30] 和 VizWiz [15];
(2)基于光学字符的视觉问答基准,如TextVQA [36];
(3)幻觉基准,如POPE[22];
(4)MME[14]、MMBench[29]、MMBench-CN[29]等综合基准测试。评估指标。
除了在流行基准测试中的性能外,我们还报告了在支持的最大分辨率下处理图像的计算成本 (TFLOP)。计算成本由视觉编码器、投影仪和 LLM 汇总而来。我们还报告了累积的多模态训练数据量以供参考,其中包括相关和指令调整期间使用的图像-文本对。对于在现有多模态模型上作为主干进行后训练的模型,这也包括主干的训练数据基线。
🔬 实验
“(1) General baselines. We adopt Qwen- VL [5], LLaVA-1.5 [27], MiniGPT-v2 [7], Shikra [8], BLIP-2 [21] and InstructBLIP [11] as representative general baselines. Since the implementation of LLaVA-UHD is highly aligned with LLaVA-1.5, it serves as the most direct baseline. (2) High-resolution LMMs. SPHINX [24] and mPLUG-Owl2 [43] encode images in fixed resolutions; Ureader [42] and Monkey [23] support enumerated resolution types (several predefined fixed-shape slices); Fuyu-8B [6] and OtterHD-8B [20] can encode images in any resolutions.”
(1)一般基线。我们采用 Qwen-VL [5]、LLaVA-1.5 [27]、MiniGPT-v2 [7]、Shikra [8]、BLIP-2 [21] 和 InstructBLIP [11] 作为具有代表性的一般基线。由于 LLaVA-UHD 的实现与 LLaVA-1.5 高度一致,因此它是最直接的基线。
(2)高分辨率LMM。 SPHINX [24]和mPLUG-Owl2 [43]以固定分辨率对图像进行编码;Ureader [42] 和 Monkey [23] 支持枚举分辨率类型(几个预定义的固定形状切片);Fuyu-8B [6] 和 OtterHD-8B [20] 可以对任何分辨率的图像进行编码。
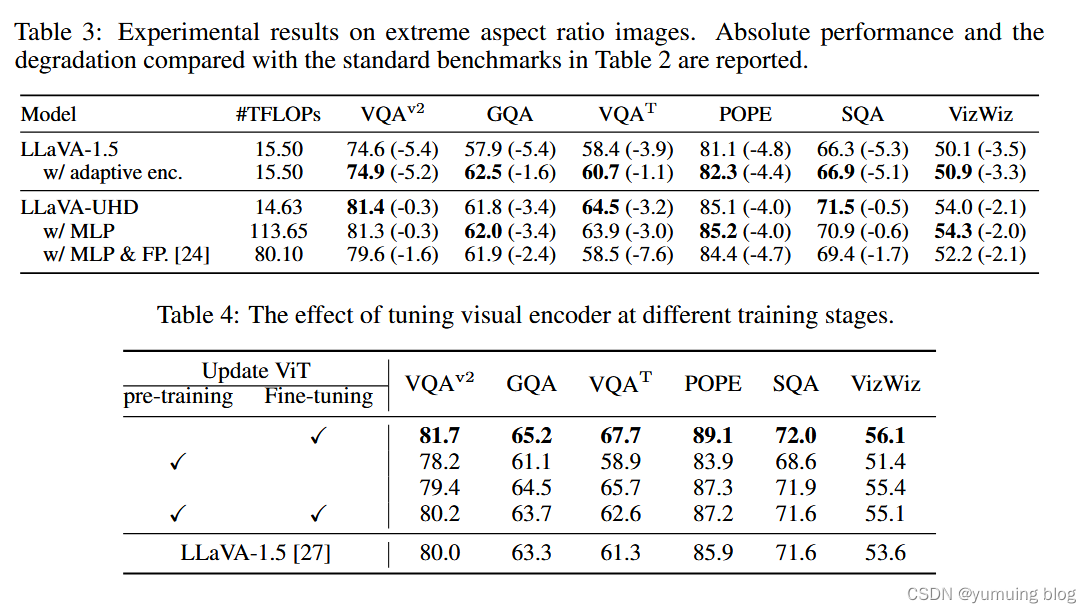
消融实验
“Ablation Study. In Table 2, we conduct ablation studies on alternative components. (1) We replace the padding strategy of LLaVA-1.5 with the adaptive encoding strategy of LLaVA-UHD, supporting arbitrary aspect ratios while maintaining identical maximum resolutions. We can observe consistent improvement since wasted computation from padding is avoided. (2) We replace the perceiver resampler of LLaVA-UHD with the 2-layer MLP of LLaVA-1.5. We observe that perceiver resampler achieves comparable or better performance than MLP, using only 12.9% computation cost. (3) We further replace the LLaVA-UHD image partition strategy with the naive partition strategy [24] (i.e., fixed 2 × 2 slices).”
在表2中,我们对替代成分进行了消融研究。
( 1 )我们将LLaVA - 1.5的填充策略替换为LLaVA - UHD的自适应编码策略,在保持相同的最大分辨率的同时支持任意的纵横比。由于避免了从填充中浪费的计算,我们可以观察到持续的改进。
( 2 )将LLaVA - UHD的感知重采样器替换为LLaVA - 1.5的2层MLP。我们观察到感知重采样器取得了与MLP相当或更好的性能,仅使用了12.9 %的计算开销。
( 3 )我们进一步将LLaVA - UHD图像划分策略替换为朴素划分策略[ 24 ] (即固定2 × 2切片)。

表3:对极端宽高比图像的实验结果。报告了与表2中标准基准相比的绝对性能和退化情况。
表4:视觉编码器在不同训练阶段的调优效果。
📜 结论
“We report the main experimental results in Table 1, from which we have the following observations: (1) LLaVA-UHD outperforms strong baselines on popular benchmarks. This includes strong general baselines trained on 2-3 orders of magnitude more data such as Qwen-VL and InstructBLIP, and also high-resolution LMMs that require significantly more computation such as Fuyu-8B, OtterHD-8B, Monkey and SPHINX-2k. The results show that LLaVA-UHD can properly deal with native-resolution images for strong performance, as well as good data and computation efficiency. (2) LLaVA-UHD achieves significant improvements over the LLaVA-1.5 backbone. Notably, by simply perceiving images in native high-resolution, LLaVA-UHD achieves 6.4 accuracy improvement on TextVQA and 3.2 accuracy improvement on POPE. The reason is that the blurred content in low-resolution images can prevent LMMs from accurately identifying the challenging fine-grained objects and optical characters. The results demonstrate the fundamental role of perceiving native high-resolution images in various multimodal tasks, and the effectiveness of LLaVA-UHD in addressing the problem. (3) In terms of resolution and efficiency, compared with LLaVA-1.5 associated fixed 336 × 336 resolution, LLaVA-UHD supports 672×1088 resolution images in any aspect ratio using only 94% inference computation. The”
在表1中报告了主要的实验结果,从中,我们得到了以下观察结果:
(1)LLaVA-UHD在流行的基准测试中表现优于强大的基线。这包括在 Qwen-VL 和 InstructBLIP 等 2-3 个数量级的数据上训练的强大通用基线,以及需要更多计算的高分辨率 LMM,例如 Fuyu-8B、OtterHD-8B、Monkey 和 SPHINX-2k。结果表明,LLaVA-UHD能够正确处理原生分辨率图像,具有较强的性能,以及良好的数据和计算效率。
(2)LLaVA-UHD在LLaVA-1.5骨干网的基础上取得了显著的改进。值得注意的是,通过简单地感知原生高分辨率的图像,LLaVA-UHD 在 TextVQA 上实现了 6.4 的精度提升,在 POPE 上实现了 3.2 的精度提升。原因是低分辨率图像中的模糊内容会阻止LMM准确识别具有挑战性的细粒度物体和光学字符。结果表明,感知原生高分辨率图像在各种多模态任务中发挥了重要作用,LLaVA-UHD在解决该问题方面具有有效性。
(3)在分辨率和效率方面,与LLaVA-1.5相关的固定336×336分辨率相比,LLaVA-UHD仅使用94%的推理计算,支持任意宽高比的672×1088分辨率图像。结果表明,LLaVA-UHD在未来可能具有更大的分辨率。
💭 思考启发
部分大型多模态语言模型存在一定的视觉幻觉问题一部分原因来自对于图像编码的处理策略问题之上。图像编码策略如果采用重叠图片块,可能导致类似于图片物品计数问题的出错,而其他对于图片进行变形操作的策略,更会导致模型对于图片小目标、低分辨率的误判。合理且适应多种分辨率的图像编码策略是有必要的。




![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-16讲 EPIT定时器](https://img-blog.csdnimg.cn/direct/2c1364a5c1894b57b6167b3832854144.png)