前言
本文介绍了使用云端GPU进行yolov5训练环境配置的过程
一、创建实例
这里使用的是恒源云的GPU服务器,官方网址为恒源云_GPUSHARE-恒源智享云
他的用户文档为Tmux - 恒源云用户文档
一般的问题在用户文档中都可以找到解决办法。
注册并登录后的界面如下图所示。
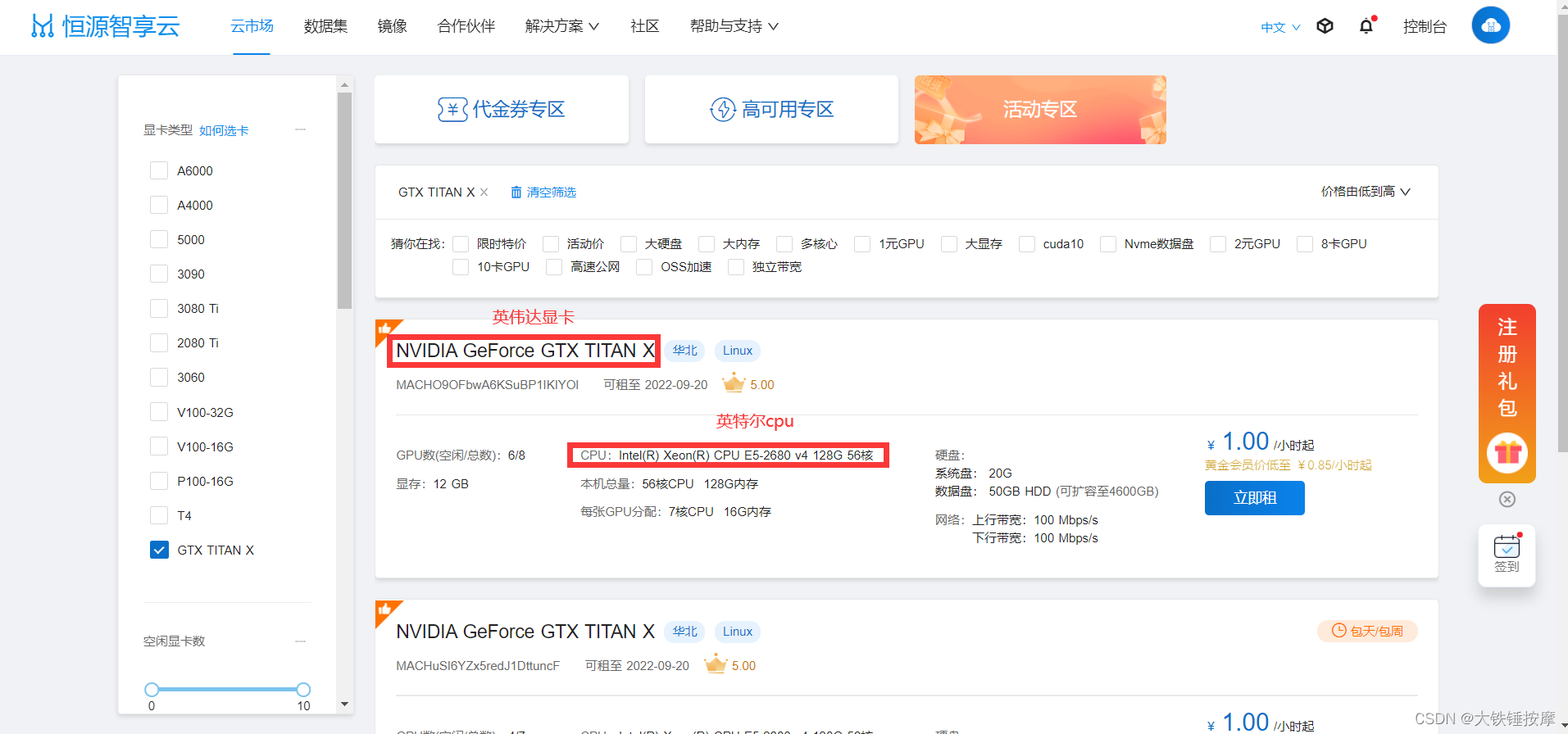
点击云市场,选择合适的机型,我这里选择的是TITAN X,务必注意的一点是一定要选择英伟达的显卡和英特尔的cpu,不然会出问题。
后面经过测试发现即使是英伟达的显卡和AMD的cpu,代码也是能跑的。
点击立即租后出现以下界面,完成镜像配置后点击创建实例。
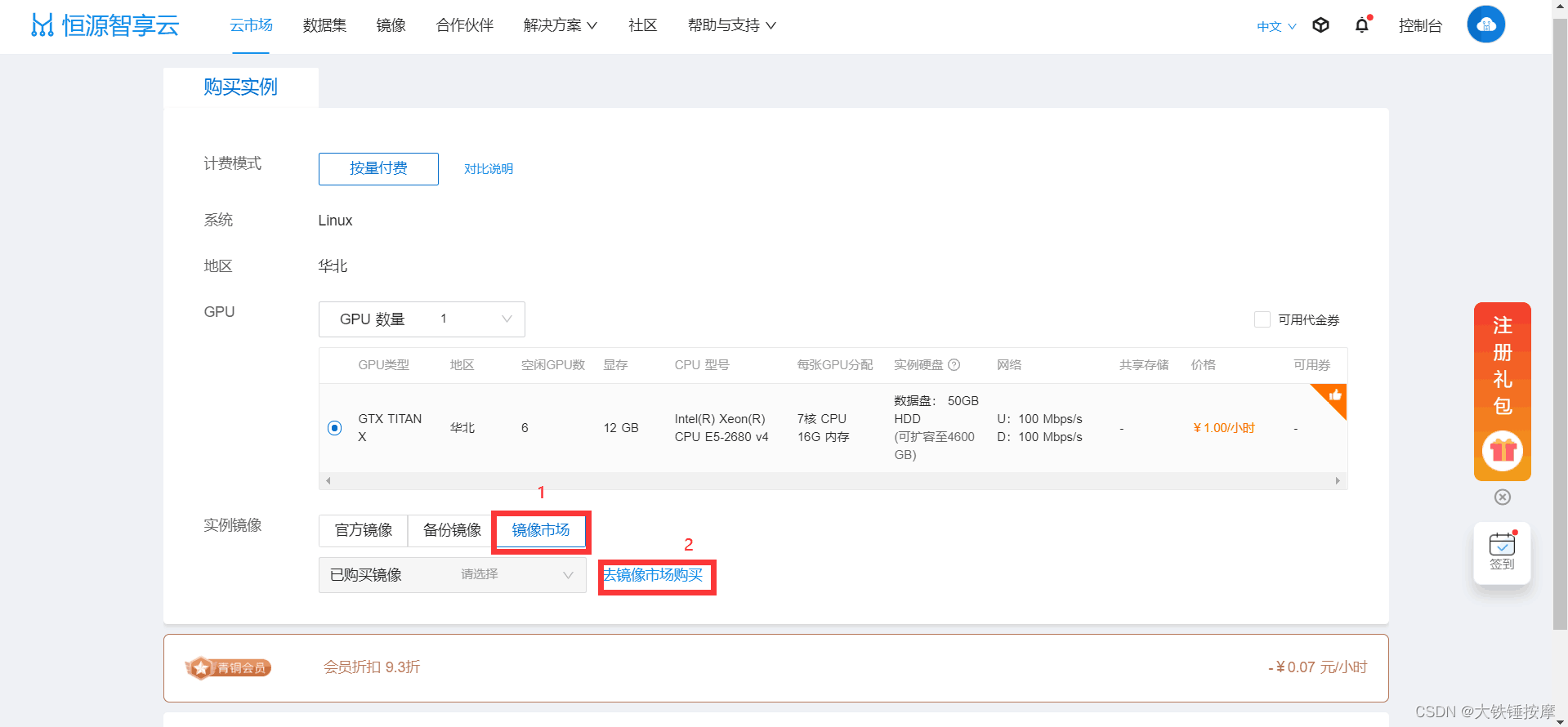
使用我上传的这个镜像即可,这个镜像已经配置好了yolov5训练所需的环境,也适用于30系显卡,可直接用于模型训练。
等待实例创建成功
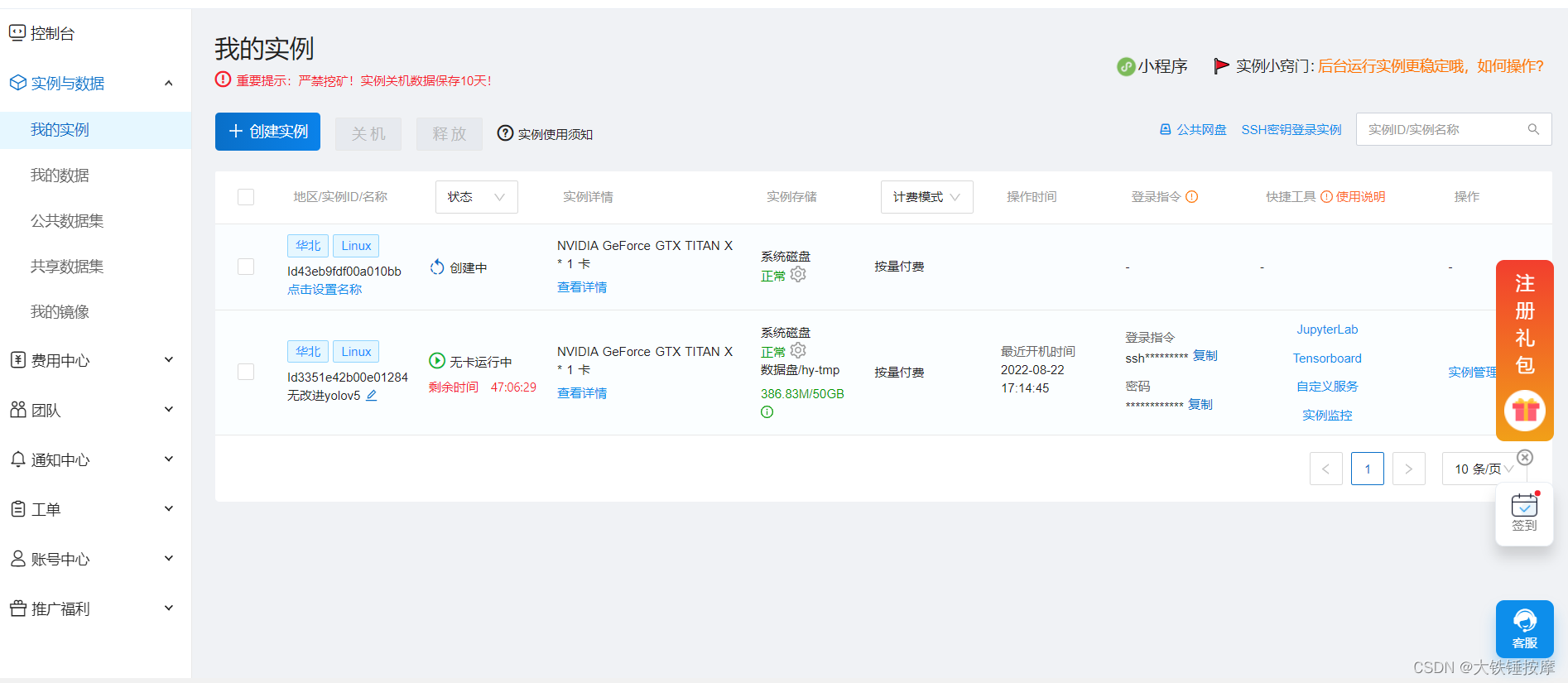
点击JupyterLab
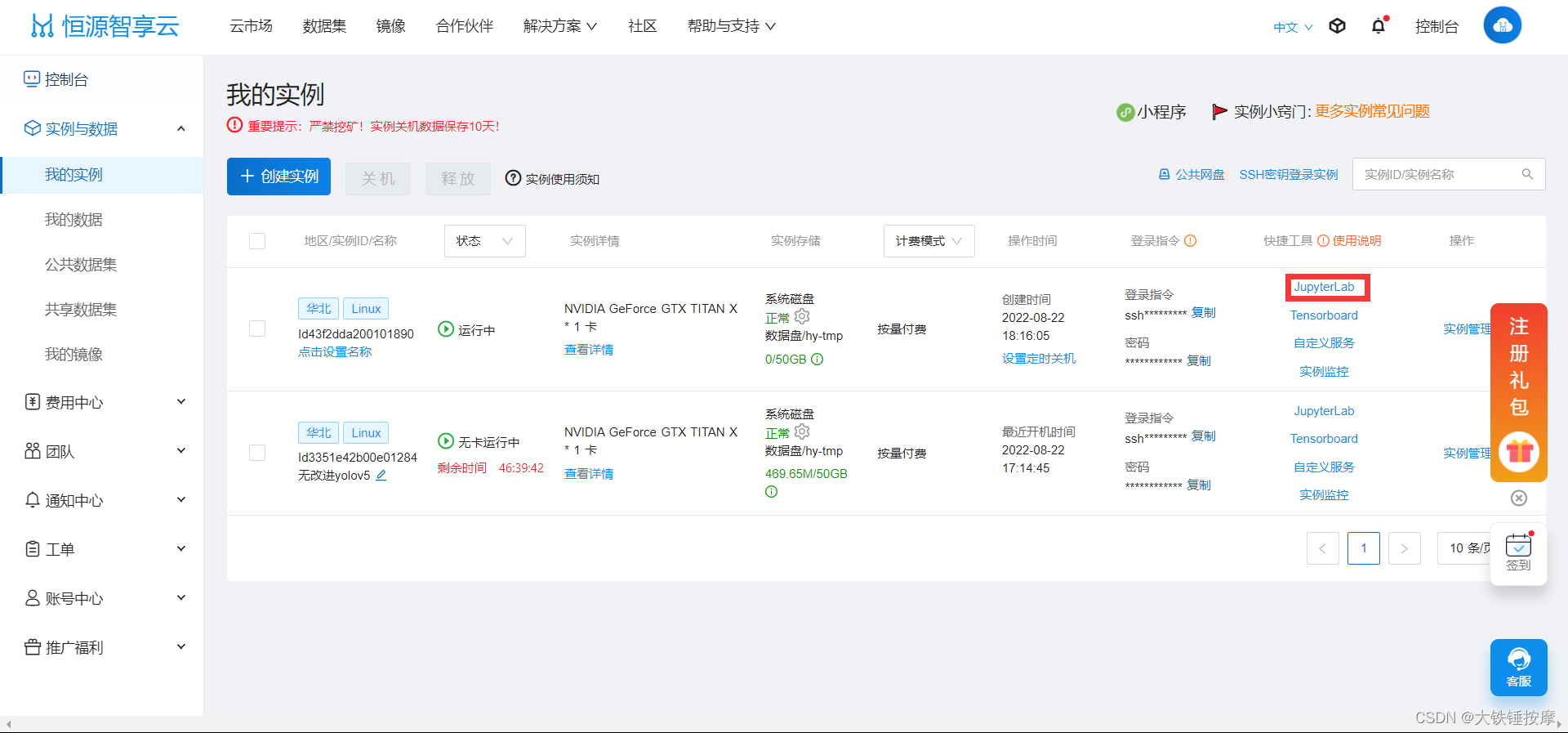
点击:
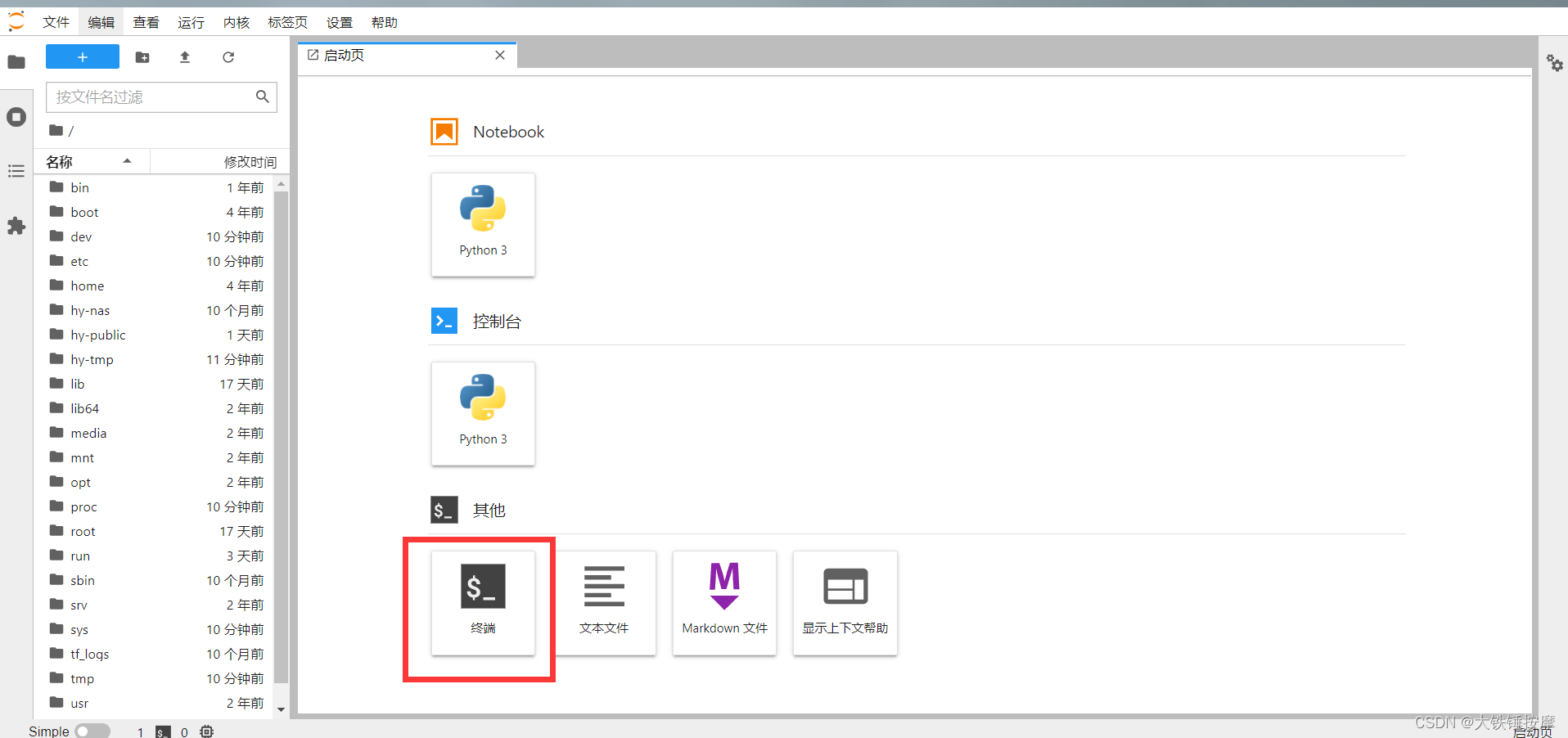
我已经将yolov5的训练环境配置好了,将数据集上传,然后将代码同步到云端即可进行训练,无需创建虚拟环境。
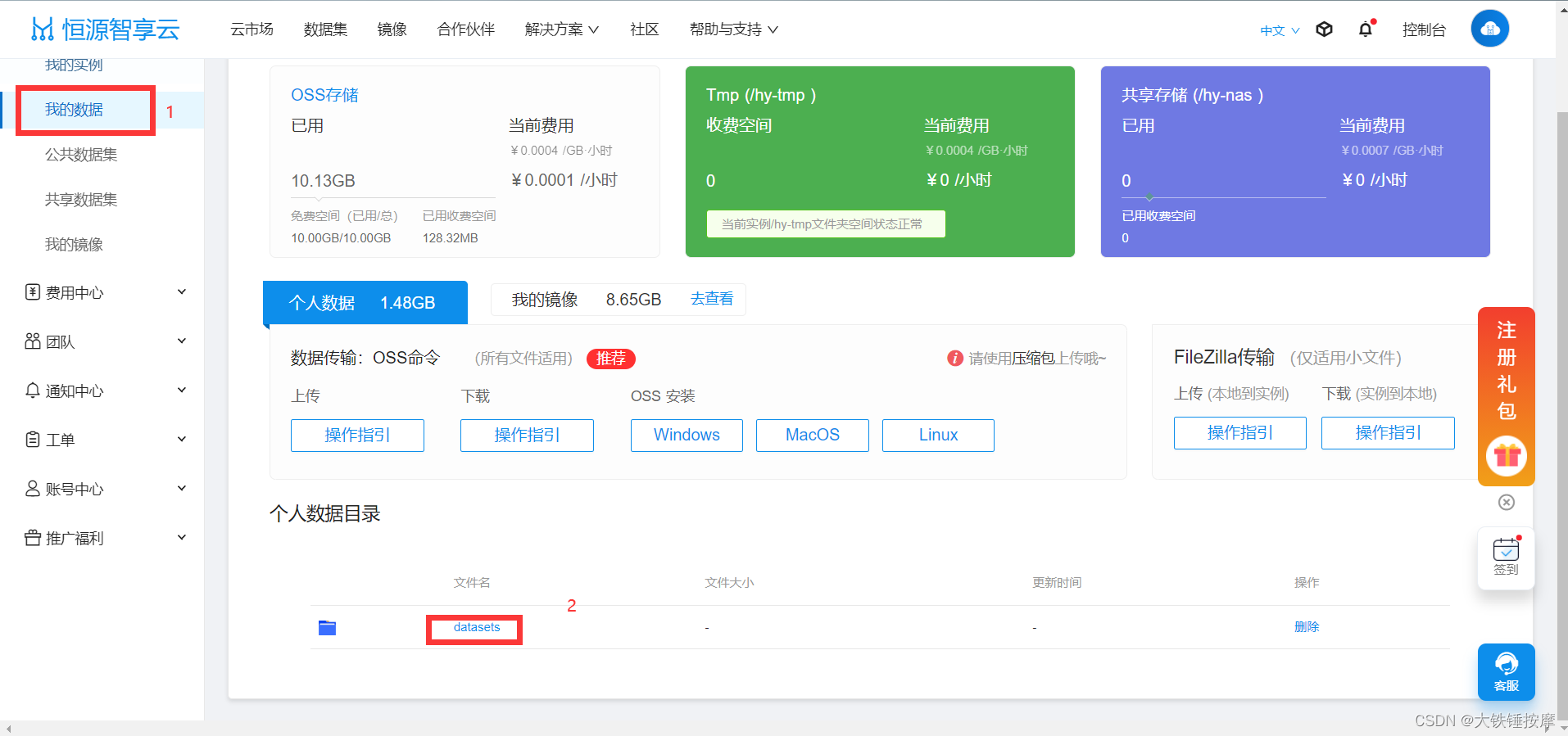
二、导入数据集到实例
导入数据集的方法见数据上传 - 恒源云用户文档,数据集建议使用oss进行上传,其他两种方法不适合传输大文件。见OSS - 恒源云用户文档。
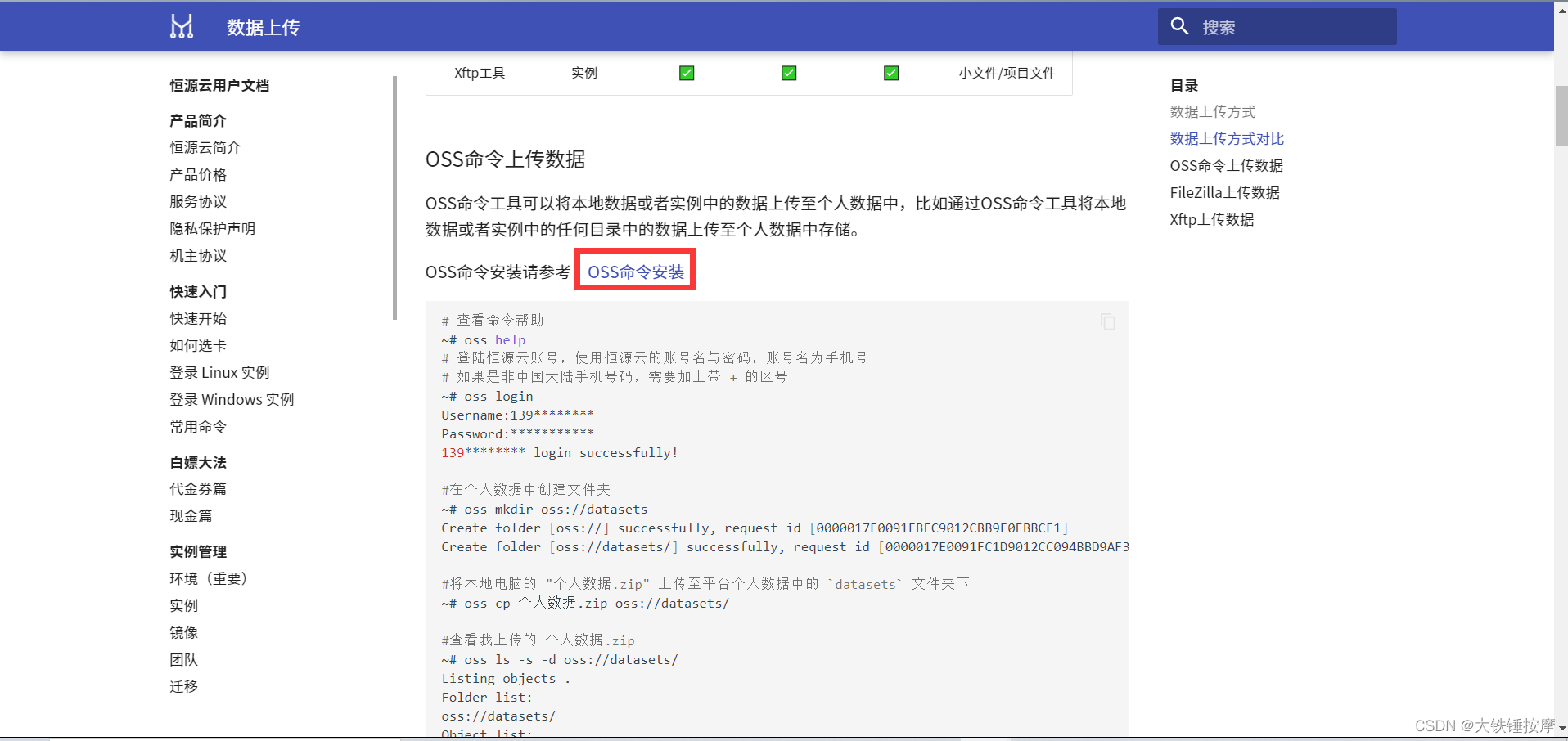
这里展示用windows上传数据的过程。
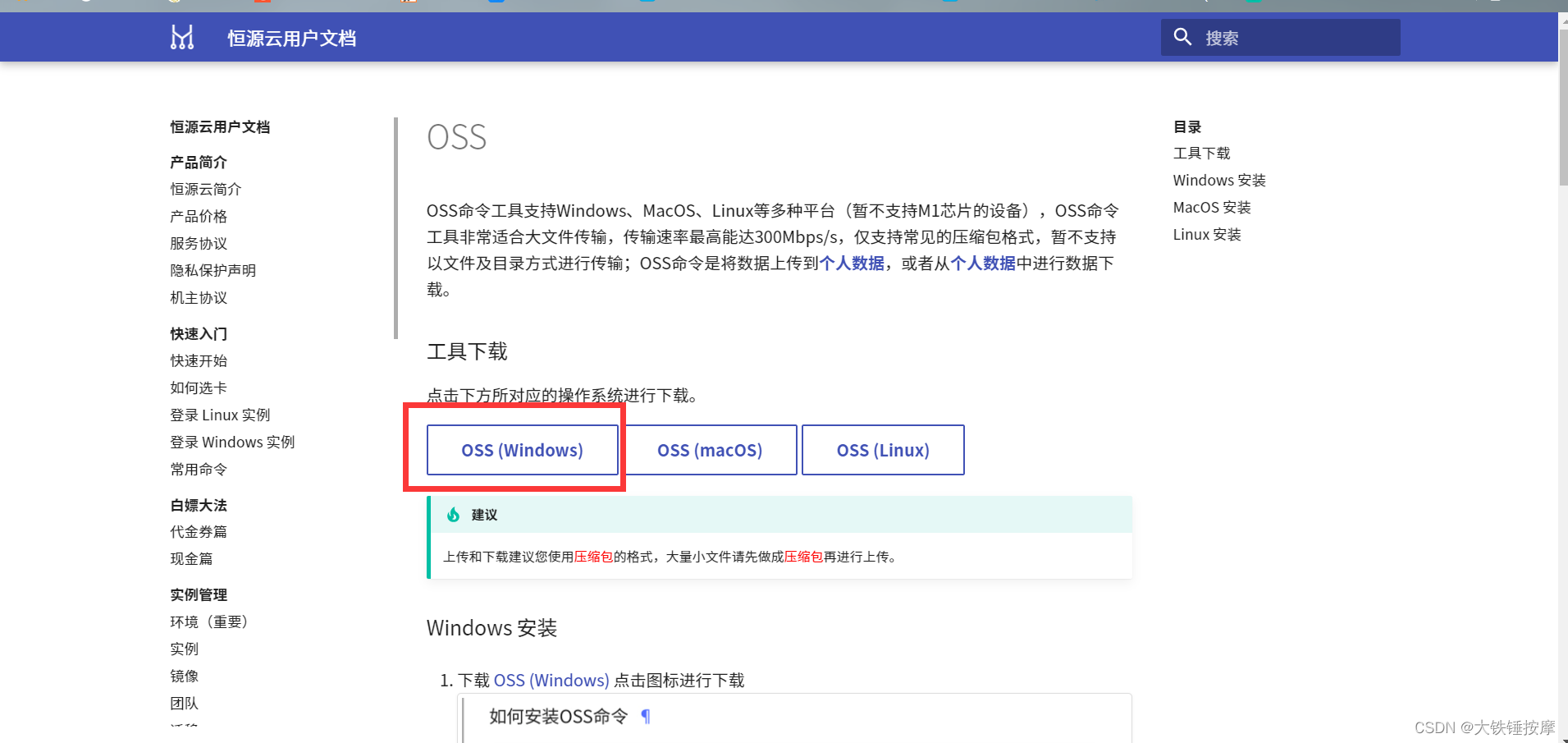
下载完成后的文件可以直接打开。

打开之后是这样。
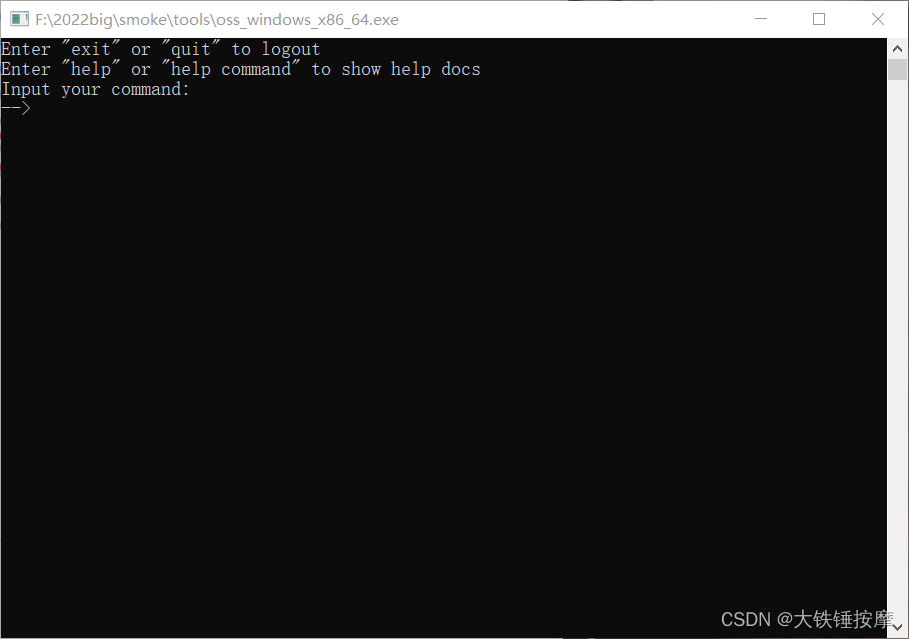
在这里需要登录一下,命令为 login,账号为注册恒源云的手机号,密码为登录恒源云的密码。
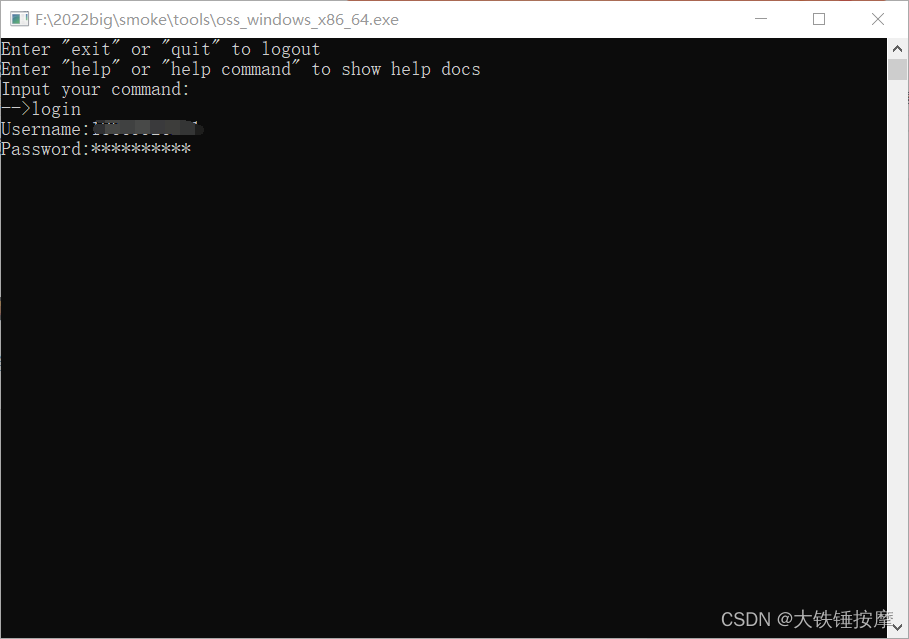
登录成功后,输入 mkdir oss://datasets ,创建一个个人数据的文件夹。
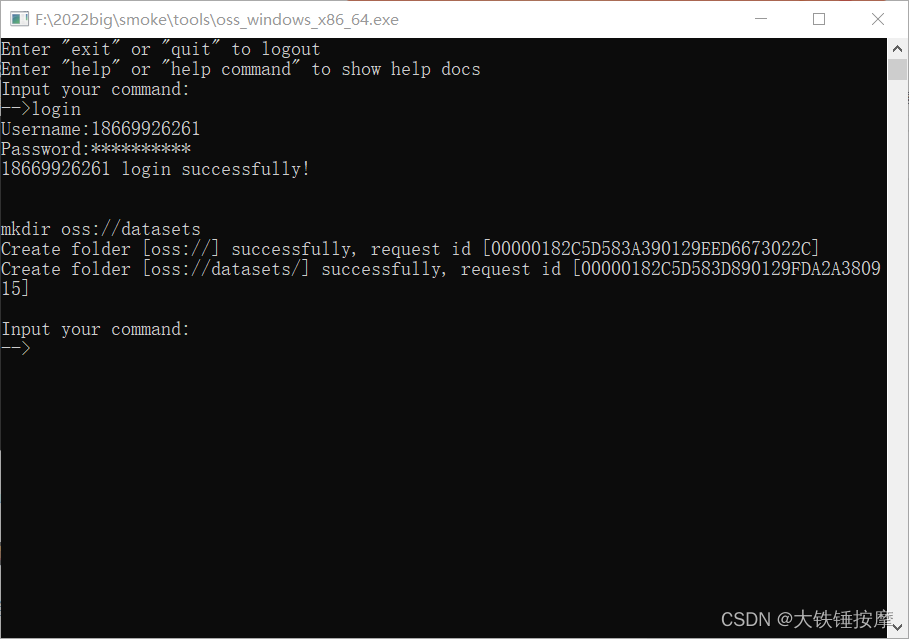
上传的数据必须是压缩包形式,把需要上传的数据集移到刚才下载的oss这个exe文件的文件夹下。

输入命令cp 你数据集的名字.zip oss://datasets/ 即可进行上传,上传的文件在datasets下,文件越大,传输的时间越长。
如果界面这样,那么说明上传成功了。

现在我们已经将数据上传到个人数据集了,现在需要将上传到个人数据集的数据下载到我们创建的实例中去,首先开启实例并点击JupyterLab。

点击:
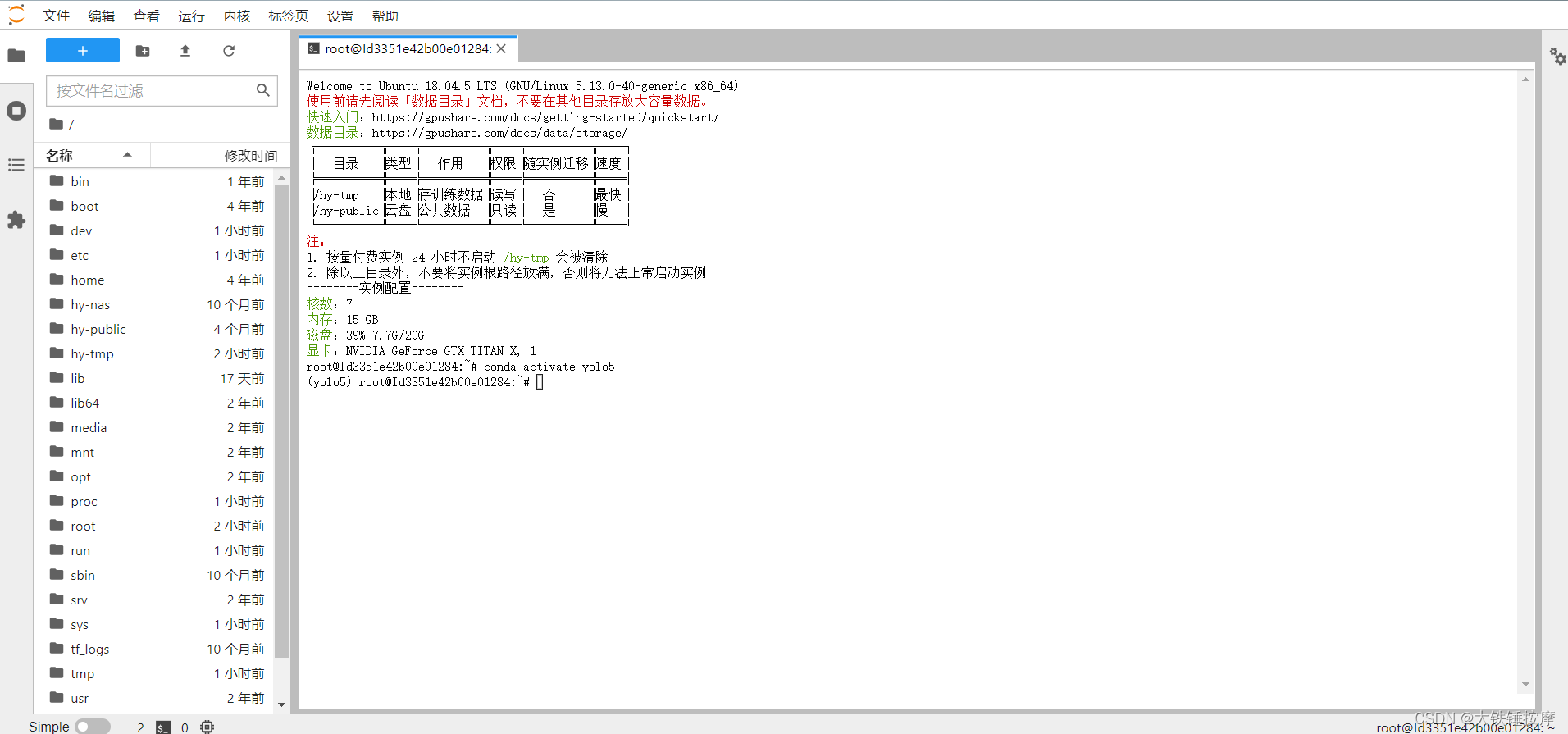
下载数据的命令为 oss cp oss://datasets/你数据集的名字.zip /hy-tmp/。
下载完毕后输入命令 cd /hy-tmp 进入存储数据的文件夹。
输入ls 查看是否下载成功。
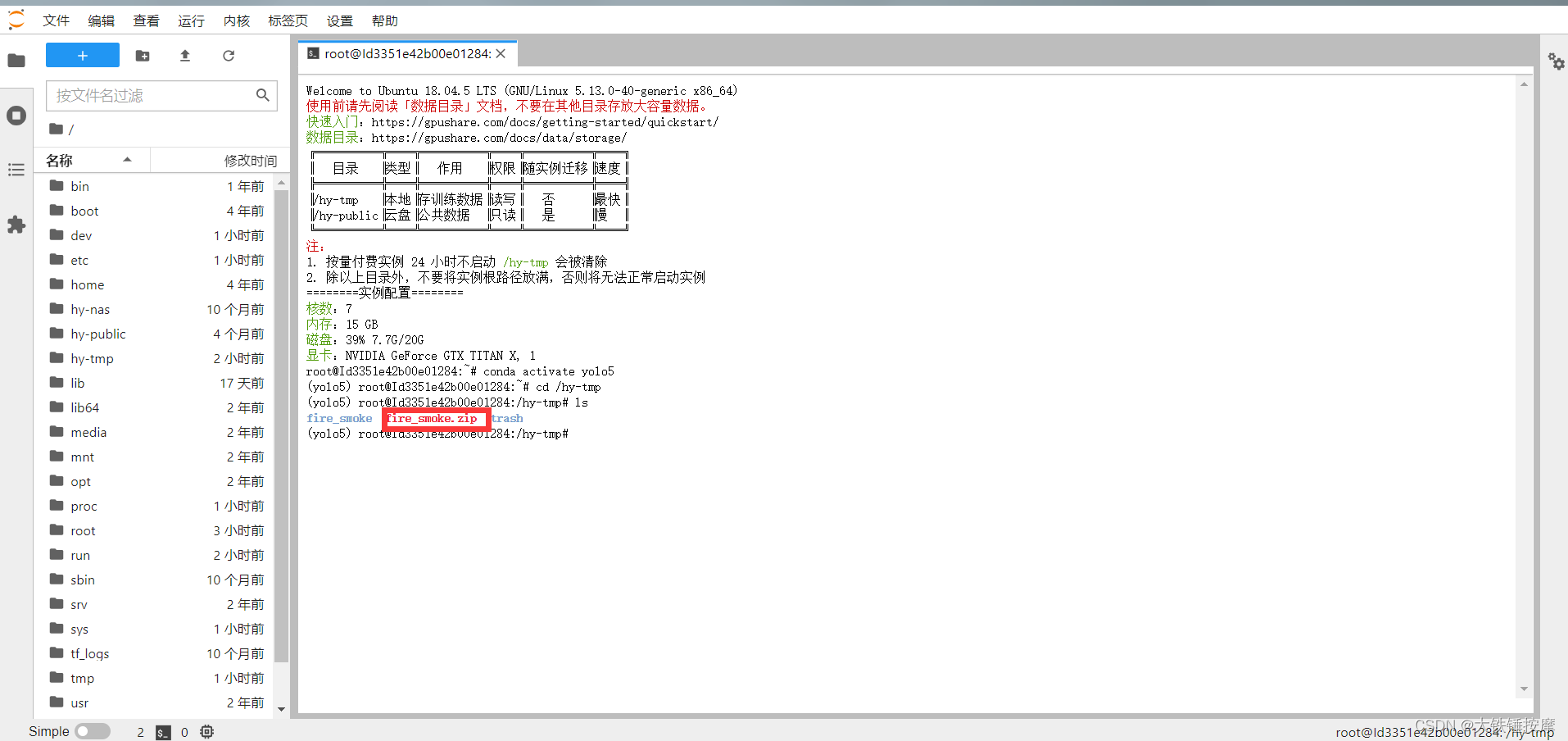
下载成功后,输入命令 unzip 你数据集的名字.zip,即可解压文件,到这里,我们已经将数据集成功下载到实例中了。
三、连接云端与本机的代码
这部分可以实现的功能是,将云端与本地的项目形成一个映射,本地中对项目做的改动会更新云端的项目文件,这里官方用户文档介绍的比较详细,我就不做说明了。
见PyCharm - 恒源云用户文档。
完成上述各步骤后,就可以在云端训练自己的yolov5模型了,注意训练的batchsize大小一定要和gpu的显存相适应,不然服务器会崩溃。比如说yolov5s的模型,在12g显存下 batchsize设置为16比较合适。