1.Dubbo生态功能的思考
dubbo具有哪些功能呢?我们要根据dubbo的架构和本质是用来干什么的来思考?
首先对于分布式微服务,假设我们有两个服务A和B,并且都是集群部署的。那么按照我们正常的流程应该是启动两个微服务项目(启动时应该做什么呢? 检查、注册发布、版本支持、协议);
其次我们服务进行了集群部署,并且接口注册到了注册中心中。那么我们的消费者如何订阅到集群中的哪一个服务呢?如果网络通信中出现了错误怎么办呢?(负载均衡、容错机制、服务降级)
再其次我们找到了服务接口,那么我们使用该接口的调用方式是什么呢?(异步调用,泛化调用)
最后我们调用到了接口服务,那么接口的传参呢,应该怎么定义,以一种什么样的形式进行网络通信呢?参数需不需要做校验?(请求参数校验、调用链路隐式传参、Kryo和FST序列化)
2. 微服务启动
2.1 启动时检查
在dubbo服务中,难免会出现循环依赖的情况
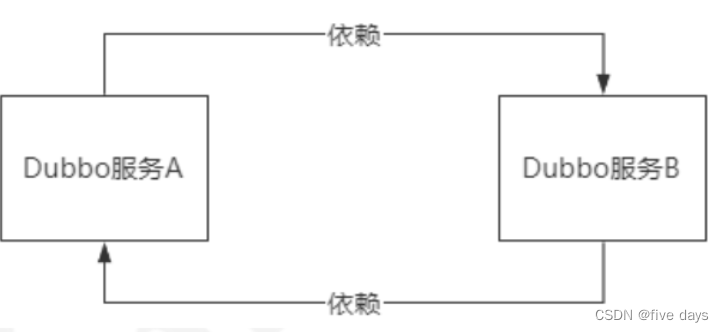
而Dubbo在启动的时候,会默认去检查依赖的服务状态,并且简历通信连接,因此在这种情况下,就会导致服务无法启动。
Dubbo里面提供了一个check参数,可以通过这个参数来关闭启动检查,等用到的时候再进行检查
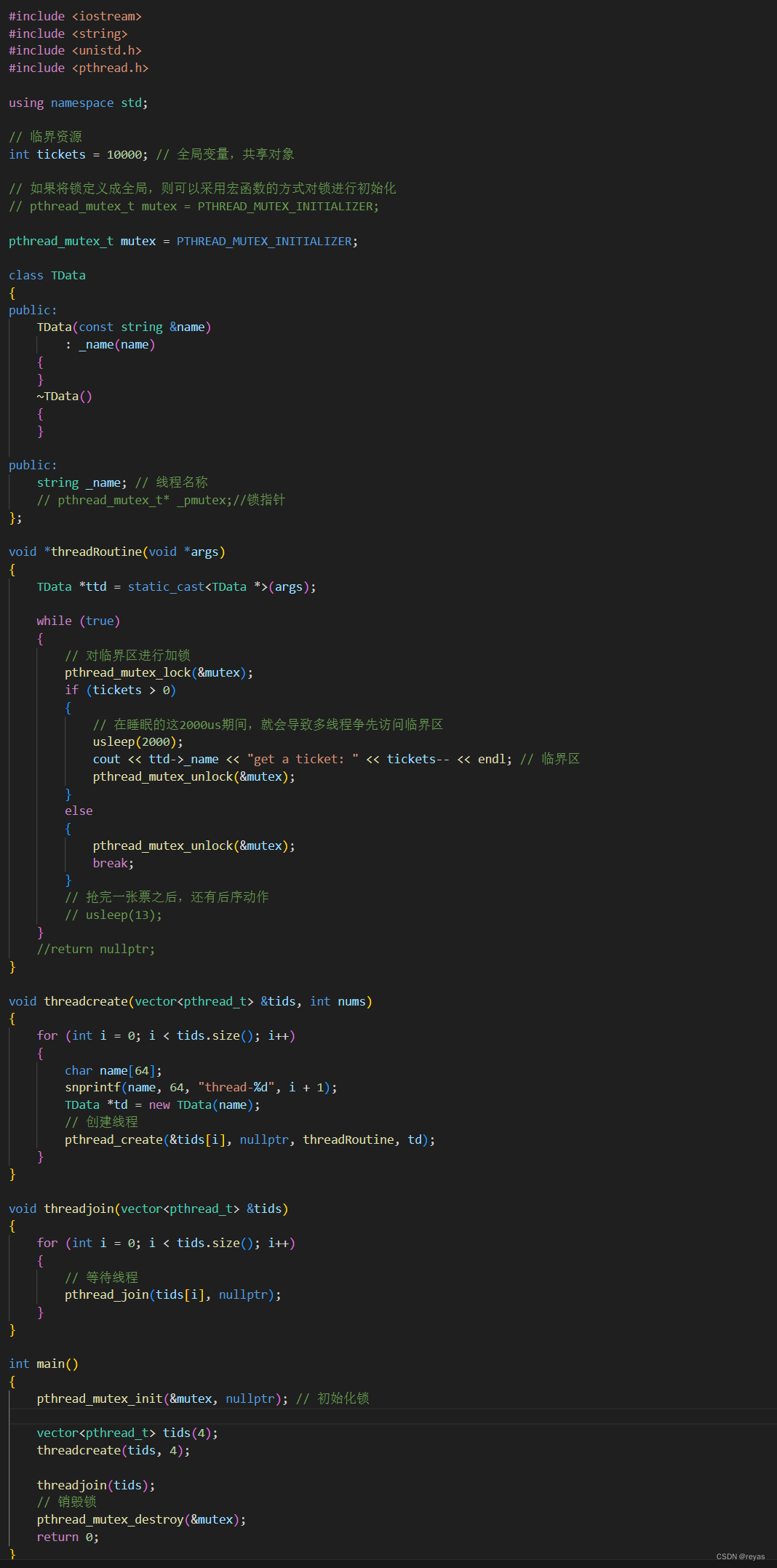
@RestController
public class UserController {
// 在启动的时候就不会检查userService该服务
@DubboReference(check = false)
IUserService userService;
@GetMapping("/coupon")
public String validCoupons(){
return userService.selectValidTemplates();
}
}
dubbo.consumer.check=false 关闭消费端所有服务的启动检查
dubbo.registry.check=false 关闭注册中心启动时检查
2.2 服务接口的版本支持
当我们在进行功能迭代的时候,就会可能存在新的功能对老版本不兼容的时候,因此这时候,我们就可以通过版本号来过渡,每次服务启动发布都是一个新的版本。
配置方式如下:
@DubboService(registry = {"zk-registry","nacos-registry"},version =
"1.0")
public class UserService implements IUserService {
@Override
public String say(String msg) {
return "Spring Boot Integration Apache Dubbo Example";
}
}消费端消费的时候,也可以在@DubboReference上指定消费的版本号
@RestController
public class UserController {
@DubboReference(version = "1.0")
IUserService userService;
@GetMapping("/say")
public String say(){
return userService.say("Mic");
}
}2.3 多协议支持
dubbo进行多协议发布的配置
dubbo.protocols.tri.name = tri
dubbo.protocols.tri.port = -1
dubbo.protocols.tri.id = tri
dubbo.protocols.dubbo.name = dubbo
dubbo.protocols.dubbo.port = -1
dubbo.protocols.dubbo.id = dubbo
添加注解信息 @DubboService(protocol={"dubbo","tri"})
2.4 服务的注册与发现
注册中心是dubbo生态的核心功能,对服务进行了一个统一的管理。当然dubbo也支持多注册中心注册,只需要配置时采用 registry={};即可
在dubbo3之前,都是面向RPC方法去定义服务的,但是这种方法有着很多的不足。
a.注册中心上存储的数据更多了,增加了数据推送的压力
b.业内主流的微服务模型都是基于应用纬度的服务注册发现。如果Dubbo要拥抱云原生,就必然需要和这些模型对齐。因此从Dubbo3开始,就增加了应用级别的服务注册发现,默认情况下,服务端会自动开启接口级和应用级的双重注册(为了兼容dubbo2.x版本)
# 双注册dubbo.application.register-mode = all# 仅应用级注册dubbo.application.register-mode = instance
dubbo.registry.address = "zookeeper : //192.168.8.133 : 2181?registry-type = service"
3. 如何找到集群服务接口
3.1 负载均衡策略
3.1.1 权重随机算法
假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights =[5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器 A 对应的区间上,此时返回服务器 A 即可。
3.1.2 加权轮询算法
加权轮询就是轮流分配,但是我们并不能保证每台服务器的性能都是相近的,因此我们应采用加权轮询的方式
比如服务器 A、B、C 权重比为 5:2:1。那么在8次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的2次请求,服务器 C 则收到其中的1次请求
3.1.3 一致性hash算法
简单来说,一致性hash算法就是一个hash圆环,假设服务器先根据ip和端口计算出的hash值在圆环上的位置,则dubbo中是根据传参来确定hash值的,因此一致性hash算法就是根据对象的传参计算出该对象的hash值,然后顺时针旋转,先到达哪台服务器就请求哪台服务器
3.1.4 最少活跃调用算法
最少活跃调用数算法,活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求这个是比较科学的负载均衡算法。每个服务提供者对应一个活跃数 active。初始情况下,所有服务提供者活跃数均为0。每收到一个请求,活跃数加1,完成请求后则将活跃数减1。在服 务运行一段时间后,性能好的服务提供者处理请求的速度更快,因此活跃数 下降的也越快,此时这样的服务提供者能够优先获取到新的服务请求
3.1.5 最短响应时间负载均衡算法
筛选成功调用响应时间最短的调用程序的数量,并计算这些调用程序的权重和数量。然后根据响应时间的长短来分配目标服务的路由权重
3.2 容错机制
3.2.1 Failover Cluster(默认)
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,单重试会带来更长延迟。可通过retries=“2”来设置重试次数(不含第一次)
3.2.2 Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
3.2.3 Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
3.2.4 Fallback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
3.2.5 Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
3.2.6 Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。(2.1.0开始支持)通常用于通知所有提供者更新缓存或日志等本地资源信息。
3.2.7 Available Cluster
调用目前可用的实例(只调用一个),如果当前没有可用的实例,则抛出异常。通常用于不需要负载均衡的场景。
3.2.8 Mergeable Cluster
将集群中的调用结果聚合起来返回结果,通常和group一起配合使用。通过分组对结果进行聚合并返回聚合后的结果,比如菜单服务,用group区分同一接口的多种实现,现在消费方需从每种group中调用一次并返回结果,对结果进行合并之后返回,这样就可以实现聚合菜单项。
注意: 在实际应用中 查询语句容错策略建议使用默认Failover Cluster, 而增删改建议使用 Failfast Cluster或者使用 Failover Cluster(retries="0") 策略 防止出现数据重复添加等等其它问题!建议在设计接口时候把查询接口方法单独做一个接口提供查询
3.3 服务降级
服务降级是一种策略,dubbo中提供了一个mock的配置,可以实现当服务提供方出现网络异常或者挂掉以后,客户端不抛出异常,而是通过Mock数据返回自定义的数据。主要有几种方式
1. 对一些非核心服务进行人工降级,在大促之前通过降级开关关闭哪些推荐内容、评价等对主流程没有影响的功能2. 故障降级,比如调用的远程服务挂了,网络故障、或者RPC服务返回异常。 那么可以直接降级,降级的方案比如设置默认值、采用兜底数据(系统推荐的行为广告挂了,可以提前准备静态页面做返回)等等3. 限流降级,在秒杀这种流量比较集中并且流量特别大的情况下,因为突发访问量特别大可能会导致系统支撑不了。这个时候可以采用限流来限制访问量。当达到阀值时,后续的请求被降级,比如进入排队页面,比如跳转到错误页(活动太火爆,稍后重试等)
4. 服务的调用方式
4.1 异步调用
dubbo实现异步调用主要是通过async这个属性来实现的。
代码举例:
@RestController
public class UserController {
@DubboReference(async = true,timeout = 5000)
IUserService userService;
@GetMapping("/say")
public String say() throws ExecutionException,InterruptedException {
String rs=userService.say("Mic");
System.out.println(Thread.currentThread().getName()+",非阻塞执行后续逻辑");
CompletableFuture<String> userFuture= RpcContext.getServerContext().getCompletableFuture();
CompletableFuture<String> future=userFuture.whenComplete((v,e)->{
if(e==null){
System.out.println(Thread.currentThread().getName()+":正常收到处理返回结 果:"+v);
}else{
e.printStackTrace();
}
});
System.out.println(Thread.currentThread().getName()+":不等待异步返回,继续执行后续代码");
return "调用成功";
}4.2 泛化调用
泛化调用是指服务端的服务没有遵循api模块,那么dubbo可以调用吗,可以的。只要知道接口的路径和方法名,dubbo中可以通过genericService进行泛化调用
@RestController
public class GenericController {
@DubboReference(interfaceName = "zsc.com.cn.user.IUserService")
GenericService genericService;
@GetMapping("/generic")
public String generic(){
Map<String,Object> person=new HashMap<>();
person.put("name","ZSC");
person.put("age",18);
Object result=genericService.$invoke(
"savePerson",
new String[]{"zsc.com.cn.user.Person"},
new Object[]{person});
return result.toString();
}
}5. 接口调用传参
5.1 请求参数校验
a.引入4个jar包
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>8.0.0.Final</version>
</dependency>
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
</dependency>
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.0</version>
</dependency>b.请求参数增加注解
@Data
public class CouponDto implements Serializable {
private static final long serialVersionUID = -1L;
@NotNull
@Size(min=1,max = 20)
private String name;
@Min(1)
@Max(1000)
private int num;
}5.2 调用链路隐式传参
可以通过RpcContext上的setAttachment和getAttachment在服务消费方和提供方之间进行 参数的隐式传递
RpcContext是一个ThreadLocal的临时状态记录器,可以获取服务端或者消费端的上下文信息
具体用法
在服务端写入,RpcContext.getServerContext.setAttachment(k,v);在服务端读取,RpcContext.getServerAttachment.getAttachment(k);在消费端写入,RpcContext.getClientAttachment.setAttachment(k,v);在消费端读取,RpcContext.getServerContext().getAttachment("result");
5.3 Kryo和FST序列化
序列化是远程通信过程中所对参数进行的一种操作方式,使得该参数经过序列化后能够进行网络通信,因此序列化对于远程调用的响应速度、吞吐量、网络带宽等消耗起着至关重要的作用。
目前最高效的针对java而设计的两种序列化方式是Kryo和FST,如何使用?
引入jar包,加一个配置即可
<dependency><groupId> org.apache.dubbo.extensions </groupId><artifactId> dubbo-serialization-kryo </artifactId><version> 1.0.0 </version></dependency>
<dependency><groupId> org.apache.dubbo.extensions </groupId><artifactId> dubbo-serialization-fst </artifactId><version> 1.0.0 </version></dependency>
针对指定协议配置序列化的方式
dubbo.protocol.name = dubbodubbo.protocol.serialization = kryo
6. 调用信息的记录
在dubbo3日志分为日志适配和访问日志,如果想记录每一次请求信息,可以开启访问日志,类似于apache的访问日志
使用方法有两种
a.直接设置dubbo.protocol.accesslog=true,表示输出到应用的log4j日志
b.输出到指定文件 dubbo.protocol.accesslog=/log/access.log
7.总结
本文从一个RPC的工作流程和中间需要进行的安全保障,交互形式,请求方式等出发,对dubbo生态的功能进行了一个简单的概况,从服务启动、发布到被消费者调用的整个远程通信过程中涉及到的点, dubbo都有着一系列的功能支持。