Hadoop完全分布式安装配置
- 任务内容
本实训需要使用root用户完成相关配置,master、slave1、slave2三台节点都需要安装JDK与Hadoop,具体要求如下:
- 将JDK安装包解压到/root/software目录下;
- 在“/etc/profile”文件中配置JDK环境变量JAVA_HOME和PATH的值,并让配置文件立即生效;
- 查看JDK版本,检测JDK是否安装成功。
- 在主节点将Hadoop安装包解压到/root/software目录下;
- 依次配置hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和workers配置文件;Hadoop集群部署规划如表11所示;
| 服务器 | master | slave1 | slave2 |
| HDFS | NameNode | ||
| HDFS | SecondaryNameNode | ||
| HDFS | DataNode | DataNode | DataNode |
| YARN | ResourceManager | ||
| YARN | NodeManager | NodeManager | NodeManager |
| 历史日志服务器 | JobHistoryServer |
- 在master节点的Hadoop安装目录下依次创建hadoopDatas/tempDatas、hadoopDatas/namenodeDatas、hadoopDatas/datanodeDatas、hadoopDatas/dfs/nn/edits、hadoopDatas/dfs/snn/name和hadoopDatas/dfs/nn/snn/edits目录;
- 在master节点上使用scp命令将配置完的Hadoop安装目录直接拷贝至slave1和slave2;
- 在三个节点的“/etc/profile”文件中配置Hadoop环境变量HADOOP_HOME和PATH的值,并让配置文件立即生效;
- 在主节点格式化集群;
- 在主节点依次启动HDFS、YARN集群和历史服务。
注意,实训环境的3个节点master、slave1和slave2,它们的主机名及IP地址在实训环境中可以通过3.1前置步骤中的“初始化网络”配置完成,而且实训环境已设置SSH免密切换节点,各节点时间已同步,因此跳过这些步骤。
【说明】原赛题提供的软件版本为Hadoop3.1.3,JDK8u191,调整采用Hadoop3.1.4、JDK8u281实现任务内容。
- 实现环境
- 使用CentOS7.9以上版本的Linux操作系统虚拟节点3个。
- 使用1.8版本的JDK。
- 使用3.1.4版本的Hadoop安装包。
- 实现步骤
- 前置步骤
- 在Linux终端执行命令“initnetwork”,或者双击桌面上名称为“初始化网络”的图标,初始化实训平台网络。
- 在Linux终端执行命令“wget -P /opt/software http://house.tipdm.com/SZ-Competition/ZZ052_2024/jdk-8u281-linux-x64.tar.gz”,下载jdk-8u281-linux-x64.tar.gz到Linux本地/opt/software目录。
- 在Linux终端执行命令“wget -P /opt/software http://house.tipdm.com/SZ-Competition/ZZ052_2024/hadoop-3.1.4.tar.gz”,下载hadoop-3.1.4.tar.gz到Linux本地/opt/software目录。
- 打开3个终端窗口,其中2个窗口使用“ssh slave1”和“ssh slave2”命令分别连接slave1与slave2节点。
- 安装JDK并设置环境变量
- 将/opt/software目录的文件jdk-8u281-linux-x64.tar.gz安装包解压到/root/software路径(若路径不存在,则需新建),具体实现如代码34所示,解压完成后查看/root/software目录的内容,返回结果如图33所示。
代码3-1 解压JDK安装包
| mkdir -p /root/software tar -zxf /opt/software/jdk-8u281-linux-x64.tar.gz -C /root/software |
![]()
图3-1 查看/root/software目录内容
- 在master节点修改/etc/profile文件,设置JDK环境变量并使其生效,具体实现如代码32所示。
| # 编辑/etc/profile文件 vim /etc/profile # 添加以下内容 export JAVA_HOME=/root/software/jdk1.8.0_281 export PATH=$PATH:$JAVA_HOME/bin # 添加内容后按Esc,输入“:wq”回车保存退出 # 使环境变量生效 source /etc/profile |
- 在master节点分别执行“java -version”和“javac”命令,返回结果如图3-2所示。

图3-2 java -version和javac命令返回结果
- 将master节点JDK解压后的安装文件发送到slave1、slave2节点的/opt/module目录,具体实现如代码33所示,发送完毕后需参考代码32在slave1与slave2节点设置JDK环境变量并使其生效。
| # 若路径不存在,则需新建 ssh slave1 "mkdir -p /root/software " ssh slave2 "mkdir -p /root/software " # 发送JDK至子节点 scp -r /root/software/jdk1.8.0_281 slave1:/root/software scp -r /root/software/jdk1.8.0_281 slave2:/root/software |
-
- 解压Hadoop安装包
将/opt/software目录的文件hadoop-3.1.4.tar.gz安装包解压到/root/software路径(若路径不存在,则需新建),具体实现如代码34所示,解压完成后查看/root/software目录的内容,返回结果如图33所示。
| mkdir -p /root/software tar -zxf /opt/software/hadoop-3.1.4.tar.gz -C /root/software |

-
- 修改Hadoop配置文件
以下步骤均在master节点上操作。
- 在代码34中已经将Hadoop解压到/root/software路径,使用cd命令切换至Hadoop的安装目录,然后按题目要求,创建Hadoop临时数据目录、NameNode元数据目录、DataNode数据存储目录等相关路径,具体实现如代码35所示,完成后查看/root/software/hadoop-3.1.4/hadoopDatas目录的内容,返回结果如图34所示。
| # 进入Hadoop的安装目录 cd /root/software/hadoop-3.1.4 # 创建Hadoop相关目录 mkdir -p ./hadoopDatas/tempDatas mkdir -p ./hadoopDatas/namenodeDatas mkdir -p ./hadoopDatas/datanodeDatas mkdir -p ./hadoopDatas/dfs/nn/edits mkdir -p ./hadoopDatas/dfs/snn/name mkdir -p ./hadoopDatas/dfs/nn/snn/edits |

- 使用cd命令切换至/root/software/hadoop-3.1.4/etc/hadoop目录,然后使用“vim”命令修改Hadoop的配置文件。
修改core-site.xml文件,该文件包含集群全局参数,主要用于定义系统级别的参数,如HDFS URI、Hadoop的临时数据目录等,在<configuration>和</configuration>之间添加配置,添加如代码36所示的内容。注意Hadoop的临时数据目录需要设置为代码35中已提前创建的目录。
| <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/root/software/hadoop-3.1.4/hadoopDatas/tempDatas</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> |
修改hadoop-env.sh和yarn-env.sh文件,这两个文件分别是Hadoop与YARN运行基本环境的配置文件,需要添加JDK的实际位置。在文件中修改JAVA_HOME值为当前节点JDK的安装位置,如代码37所示。
代码3-7 修改hadoop-env.sh和yarn-env.sh
| export JAVA_HOME=/usr/java/jdk1.8.0_281-amd64 |
修改mapred-site.xml,设定MapReduce运行配置,使用YARN作为MapReduce的框架,设置ApplicationMaster、Map和Reduce任务的环境变量,指定MapReduce应用程序运行所需的类路径,配置历史服务器JobHistory Server的地址以及WEB访问地址,在<configuration>和</configuration>之间添加内容,具体如代码38所示。
| <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/root/software/hadoop-3.1.4</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/root/software/hadoop-3.1.4</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/root/software/hadoop-3.1.4</value> </property> <property> <name>mapreduce.application.classpath</name> <value>/root/software/hadoop-3.1.4/share/hadoop/mapreduce/*:/root/software/hadoop-3.1.4/share/hadoop/mapreduce/lib/* </value> </property> <!-- jobhistory properties --> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> |
修改yarn-site.xml文件,设定YARN运行配置,主要配置ResourceManager、NodeManager的通信端口、web监控端口等,在<configuration>和</configuration>之间添加内容,具体如代码39所示。如果需要指定YARN的ResourceManager的地址为slave1或slave2,只需将配置项yarn.resourcemanager.hostname的值修改为slave1或slave2即可。
| <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/root/software/hadoop-3.1.4/hadoop/yarn/local</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/root/software/hadoop-3.1.4/tmp/logs</value> </property> <property> <name>yarn.log.server.url</name> <value>http://master:19888/jobhistory/logs/</value> <description>URL for job history server</description> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> </property> <property> <name>mapreduce.map.memory.mb</name> <value>8192</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>8192</value> </property> <property> <name>yarn.application.classpath</name> <value> /root/software/hadoop-3.1.4/etc/hadoop:/root/software/hadoop-3.1.4/share/hadoop/common/lib/*:/root/software/hadoop-3.1.4/share/hadoop/common/*:/root/software/hadoop-3.1.4/share/hadoop/hdfs:/root/software/hadoop-3.1.4/share/hadoop/hdfs/lib/*:/root/software/hadoop-3.1.4/share/hadoop/hdfs/*:/root/software/hadoop-3.1.4/share/hadoop/mapreduce/lib/*:/root/software/hadoop-3.1.4/share/hadoop/mapreduce/*:/root/software/hadoop-3.1.4/share/hadoop/yarn:/root/software/hadoop-3.1.4/share/hadoop/yarn/lib/*:/root/software/hadoop-3.1.4/share/hadoop/yarn/* </value> </property> |
修改workers文件,master、slave1、slave2节点均作为DataNode,在workers文件里面删除原有的localhost,添加如代码310所示的内容。
| master slave1 slave2 |
修改hdfs-site.xml文件,设置HDFS运行配置,主要配置如NameNode和DataNode数据的存放位置、文件副本的个数、SecondaryNameNode的地址等,并且指定NameNode元数据目录、DataNode数据存储目录和NameNode的edits文件存储目录等路径。在<configuration>和</configuration>之间添加内容,具体如代码311所示。
| <property> <name>dfs.namenode.name.dir</name> <value>file:///root/software/hadoop-3.1.4/hadoopDatas/namenodeDatas</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///root/software/hadoop-3.1.4/hadoopDatas/datanodeDatas</value> </property> <property> <name>dfs.namenode.edits.dir</name> <value>file:///root/software/hadoop-3.1.4/hadoopDatas/dfs/nn/edits</value> </property> <property> <name> dfs.namenode.checkpoint.dir</name> <value>file:///root/software/hadoop-3.1.4/hadoopDatas/dfs/snn/name</value> </property> <property> <name> dfs.namenode.checkpoint.edits.dir</name> <value>file:///root/software/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> |
进入/root/software/hadoop-3.1.4/sbin目录,修改HDFS的启动脚本start-dfs.sh与停止脚本stop-dfs.sh,在#!/usr/bin/env bash下方添加内容,指定DataNode、NameNode和SecondaryNameNode各个组件的运行用户,具体如代码312所示。
| HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root |
进入/root/software/hadoop-3.1.4/sbin目录,修改YARN的启动脚本start-yarn.sh和停止脚本stop-yarn.sh,在#!/usr/bin/env bash下方添加内容,指定YARN组件的运行用户,具体如代码313所示。
| YARN_RESOURCEMANAGER_USER=root HDFS_DATANODE_SECURE_USER=root YARN_NODEMANAGER_USER=root |
注意,本次搭建的Hadoop集群共有3个节点,其主机名及IP地址在实训环境中已通过4.1前置步骤中的“初始化网络”配置完成,而且实训环境已设置免密切换节点,各节点时间已同步,因此跳过这些步骤。
-
- 启动关闭Hadoop集群
- 配置Hadoop环境变量
在3个节点上修改/etc/profile文件,在文件末尾修改如代码314所示内容,文件修改完保存退出,执行命令“source /etc/profile”使配置生效。(/root/software/hadoop-3.1.4/bin目录包含了hdfs、mapred和yarn等脚本文件,用于管理和使用Hadoop。)
| export HADOOP_HOME=/root/software/hadoop-3.1.4 export PATH=$PATH:$HADOOP_HOME/bin |
- 执行代码315所示命令,在slave1与slave2节点创建对应目录,然后将master节点已经部署好的Hadoop与/etc/profile文件复制传输到slave1、slave2节点。
| ssh slave1 "mkdir -p /root/software" ssh slave2 "mkdir -p /root/software" scp -r /root/software/hadoop-3.1.4 slave1:/root/software/ scp -r /root/software/hadoop-3.1.4 slave2:/root/software/ scp /etc/profile slave1:/etc/profile scp /etc/profile slave2:/etc/profile # 在slave1与slave2节点执行以下命令使环境变量生效 source /etc/profile |
- 在master上执行命令“hdfs namenode -format”进行格式化,若出现“successfully formatted”提示,则格式化成功,如图3-5所示。
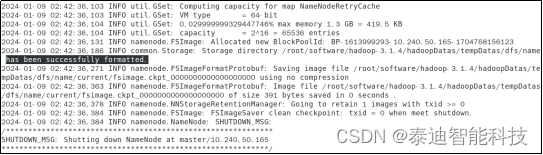
- 启动集群
在master节点,确保修改后的环境变量已经生效,在Linux终端分别执行如代码316所示的命令。
| # 进入Hadoop的sbin目录 cd /root/software/hadoop-3.1.4/sbin # 启动HDFS相关服务 ./start-dfs.sh # 启动YARN相关服务 ./start-yarn.sh # 启动日志相关服务 mapred --daemon start historyserver |
Hadoop集群启动之后,在主节点master,子节点slave1,slave2分别执行jps,出现如图36所示的信息,说明Hadoop集群启动成功。
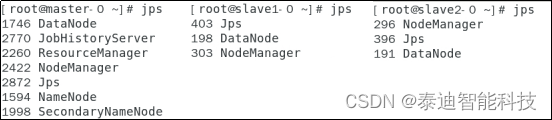
- 同理,关闭集群也只需要在master节点,在Linux终端分别执行如代码317所示的命令。
| # 进入Hadoop的sbin目录 cd /root/software/hadoop-3.1.4/sbin # 关闭YARN相关服务 ./stop-yarn.sh # 关闭HDFS相关服务 ./stop-dfs.sh # 关闭日志相关服务 mapred --daemon stop historyserver |
了解详细内容请联系广东泰迪智能科技股份有限公司
欲了解更多信息,欢迎登陆官网http://www.tipdm.com/,咨询电话18927565259
*更多相关内容请持续关注,具体内容解释权归泰迪智能科技所有。







![【Linux】-Elasticsearch安装部署[16]](https://img-blog.csdnimg.cn/direct/c133b9e39074499e8594dc36ec193009.png)