-
Segment Anything:建立了迄今为止最大的分割数据集,在1100万张图像上有超过1亿个掩码,模型的设计和训练是灵活的,其重要的特点是Zero-shot(零样本迁移性)转移到新的图像分布和任务,一个图像分割新的任务、模型和数据集。SAM由三个部分组成:一个强大的图像编码器(Image encoder)计算图像嵌入,一个提示编码器(Prompt encoder)嵌入提示,然后将两个信息源组合在一个轻量级掩码解码器(Mask decoder)中来预测分割掩码。在视觉领域通过Prompt+基础大模型的套路来解决目标分割的问题。
-
需要下载官方给的权重pth下载链接,权重文件可以在给的readme.md上的链接下载。下载好权重文件之后,我们就开始配置并调用SAM,主要的文件其实就在amg.py上面进行配置运行即可,其他文件大家有兴趣的可以仔细阅读一下了解。
-
主要我们就需要一个input文件,放入我们需要分割的文件路径,最好是jpg,png格式的,可以看官方支持什么格式,还有一个output文件路径,放入我们结果生成的文件。model-type就是刚才说的权重文件的类型。checkpoint就是权重文件路径,刚才下载的文件,把路径放进去即可。
-
parser.add_argument( "--input", type=str, required=False, default=r'.\JPEGImages', help="Path to either a single input image or folder of images.", ) parser.add_argument( "--output", type=str, required=False, default=r'.\JPEGImages\result', help=( "Path to the directory where masks will be output. Output will be either a folder of PNGs per image or a single json with COCO-style masks." ), ) parser.add_argument( "--model-type", type=str, required=False, default='vit_h', help="The type of model to load, in ['default', 'vit_h', 'vit_l', 'vit_b']", ) parser.add_argument( "--checkpoint", type=str, required=False, default=r'.\segment-anything-main\sam_vit_h_4b8939.pth', help="The path to the SAM checkpoint to use for mask generation.", )
-
-
SAM 源码提供了3种不同大小的模型。sam_model_registry函数在segment_anything/build_sam.py文件内定义,SAM的3种模型通过字典形式保存。
-
-
sam_model_registry = { "default": build_sam_vit_h, "vit_h": build_sam_vit_h, "vit_l": build_sam_vit_l, "vit_b": build_sam_vit_b, }# 选择合适的模型以及加载对应权重 sam = sam_model_registry[model_type](checkpoint=sam_checkpoint) sam.to(device=device) -
sam_model_registry中的 3 种模型结构是一致的,部分参数不同导致模型的大小有别。
-
def build_sam_vit_h(checkpoint=None): return _build_sam( encoder_embed_dim=1280, encoder_depth=32, encoder_num_heads=16, encoder_global_attn_indexes=[7, 15, 23, 31], checkpoint=checkpoint, ) def build_sam_vit_l(checkpoint=None): return _build_sam( encoder_embed_dim=1024, encoder_depth=24, encoder_num_heads=16, encoder_global_attn_indexes=[5, 11, 17, 23], checkpoint=checkpoint, ) def build_sam_vit_b(checkpoint=None): return _build_sam( encoder_embed_dim=768, encoder_depth=12, encoder_num_heads=12, encoder_global_attn_indexes=[2, 5, 8, 11], checkpoint=checkpoint, )
-
-
最后是_build_sam方法,完成了sam模型的初始化以及权重的加载,这里可以注意到sam模型由三个神经网络模块组成:ImageEncoderViT(Image encoder)、PromptEncoder和MaskDecoder。
-
def _build_sam( encoder_embed_dim, encoder_depth, encoder_num_heads, encoder_global_attn_indexes, checkpoint=None, ): prompt_embed_dim = 256 image_size = 1024 vit_patch_size = 16 image_embedding_size = image_size // vit_patch_size sam = Sam( image_encoder=ImageEncoderViT( depth=encoder_depth, embed_dim=encoder_embed_dim, img_size=image_size, mlp_ratio=4, norm_layer=partial(torch.nn.LayerNorm, eps=1e-6), num_heads=encoder_num_heads, patch_size=vit_patch_size, qkv_bias=True, use_rel_pos=True, global_attn_indexes=encoder_global_attn_indexes, window_size=14, out_chans=prompt_embed_dim, ), prompt_encoder=PromptEncoder( embed_dim=prompt_embed_dim, image_embedding_size=(image_embedding_size, image_embedding_size), input_image_size=(image_size, image_size), mask_in_chans=16, ), mask_decoder=MaskDecoder( num_multimask_outputs=3, transformer=TwoWayTransformer( depth=2, embedding_dim=prompt_embed_dim, mlp_dim=2048, num_heads=8, ), transformer_dim=prompt_embed_dim, iou_head_depth=3, iou_head_hidden_dim=256, ), pixel_mean=[123.675, 116.28, 103.53], pixel_std=[58.395, 57.12, 57.375], ) sam.eval() if checkpoint is not None: with open(checkpoint, "rb") as f: state_dict = torch.load(f) sam.load_state_dict(state_dict) return sam
-
-
SamPredictor类,sam模型被封装在SamPredictor类的对象中,方便使用。SamPredictor类在segment_anything/predictor.py文件。
-
predictor = SamPredictor(sam) predictor.set_image(image) # image_encoder操作在set_image时就已经执行了,而不是在predic时
-
-
首先确认输入是否是RGB或BGR三通道图像,将BGR图像统一为RGB,而后并对图像尺寸和channel顺序作出调整满足神经网络的输入要求。
-
def set_image(self, image: np.ndarray, image_format: str = "RGB",) -> None: # 图像不是['RGB', 'BGR']格式则报错 assert image_format in [ "RGB", "BGR", ], f"image_format must be in ['RGB', 'BGR'], is {image_format}." # H,W,C if image_format != self.model.image_format: image = image[..., ::-1] # H,W,C中 C通道的逆序RGB-->BGR # Transform the image to the form expected by the model 改变图像尺寸 input_image = self.transform.apply_image(image) # torch 浅拷贝 转tensor input_image_torch = torch.as_tensor(input_image, device=self.device) # permute H,W,C-->C,H,W # contiguous 连续内存 # [None, :, :, :] C,H,W -->1,C,H,W input_image_torch = input_image_torch.permute(2, 0, 1).contiguous()[None, :, :, :] self.set_torch_image(input_image_torch, image.shape[:2])
-
-
set_torch_image:用padding填补缩放后的图片,在 H 和 W 满足神经网络需要的标准尺寸,而后通过image_encoder模型获得图像特征数据并保存在self.features中,同时self.is_image_set设为true。注意image_encoder过程不是在predict_torch时与Prompt encoder过程和Mask decoder过程一同执行的,而是在set_image时就已经执行了。
-
def set_torch_image( self, transformed_image: torch.Tensor, original_image_size: Tuple[int, ...], ) -> None: # 满足输入是四个维度且为B,C,H,W assert ( len(transformed_image.shape) == 4 and transformed_image.shape[1] == 3 and max(*transformed_image.shape[2:]) == self.model.image_encoder.img_size ), f"set_torch_image input must be BCHW with long side {self.model.image_encoder.img_size}." self.reset_image() # 原始图像的尺寸 self.original_size = original_image_size # torch图像的尺寸 self.input_size = tuple(transformed_image.shape[-2:]) # torch图像进行padding input_image = self.model.preprocess(transformed_image) # image_encoder网络模块对图像进行编码 self.features = self.model.image_encoder(input_image) # 图像设置flag self.is_image_set = True
-
-
predict对输入到模型中进行预测的数据(标记点 apply_coords 和标记框 apply_boxes )进行一个预处理,并接受和处理模型返回的预测结果。
-
def predict( self, # 标记点的坐标 point_coords: Optional[np.ndarray] = None, # 标记点的标签 point_labels: Optional[np.ndarray] = None, # 标记框的坐标 box: Optional[np.ndarray] = None, # 输入的mask mask_input: Optional[np.ndarray] = None, # 输出多个mask供选择 multimask_output: bool = True, # ture 返回掩码logits, false返回阈值处理的二进制掩码。 return_logits: bool = False, ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]: # 假设没有设置图像,报错 if not self.is_image_set: raise RuntimeError("An image must be set with .set_image(...) before mask prediction.") # Transform input prompts # 输入提示转换为torch coords_torch, labels_torch, box_torch, mask_input_torch = None, None, None, None if point_coords is not None: # 标记点坐标对应的标记点标签不能为空 assert ( point_labels is not None ), "point_labels must be supplied if point_coords is supplied." # 图像改变了原始尺寸,所以对应的点位置也会发生改变 point_coords = self.transform.apply_coords(point_coords, self.original_size) # 标记点坐标和标记点标签 np-->tensor coords_torch = torch.as_tensor(point_coords, dtype=torch.float, device=self.device) labels_torch = torch.as_tensor(point_labels, dtype=torch.int, device=self.device) # 增加维度 # coords_torch:N,2-->1,N,2 # labels_torch: N-->1,N coords_torch, labels_torch = coords_torch[None, :, :], labels_torch[None, :] if box is not None: # 图像改变了原始尺寸,所以对应的框坐标位置也会发生改变 box = self.transform.apply_boxes(box, self.original_size) # 标记框坐标 np-->tensor box_torch = torch.as_tensor(box, dtype=torch.float, device=self.device) # 增加维度 N,4-->1,N,4 box_torch = box_torch[None, :] if mask_input is not None: # mask np-->tensor mask_input_torch = torch.as_tensor(mask_input, dtype=torch.float, device=self.device) # 增加维度 1,H,W-->B,1,H,W mask_input_torch = mask_input_torch[None, :, :, :] # 输入数据预处理完毕,可以输入到网络中 masks, iou_predictions, low_res_masks = self.predict_torch( coords_torch, labels_torch, box_torch, mask_input_torch, multimask_output, return_logits=return_logits, ) # 因为batchsize为1,压缩维度 # mask masks = masks[0].detach().cpu().numpy() # score iou_predictions = iou_predictions[0].detach().cpu().numpy() low_res_masks = low_res_masks[0].detach().cpu().numpy() return masks, iou_predictions, low_res_masks def postprocess_masks( self, masks: torch.Tensor, input_size: Tuple[int, ...], original_size: Tuple[int, ...], ) -> torch.Tensor: # mask上采样到与输入到模型中的图片尺寸一致 masks = F.interpolate( masks, (self.image_encoder.img_size, self.image_encoder.img_size), mode="bilinear", align_corners=False, ) masks = masks[..., : input_size[0], : input_size[1]] # mask resize 到与未做处理的原始图片尺寸一致 masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False) return masks
-
-
predict_torch:输入数据经过预处理后输入到模型中预测结果。Prompt encoder过程和Mask decoder过程是在predict_torch时执行的。
-
def predict_torch( self, point_coords: Optional[torch.Tensor], point_labels: Optional[torch.Tensor], boxes: Optional[torch.Tensor] = None, mask_input: Optional[torch.Tensor] = None, multimask_output: bool = True, return_logits: bool = False, ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]: # 假设没有设置图像,报错 if not self.is_image_set: raise RuntimeError("An image must be set with .set_image(...) before mask prediction.") # 绑定标记点和标记点标签 if point_coords is not None: points = (point_coords, point_labels) else: points = None # ----- Prompt encoder ----- sparse_embeddings, dense_embeddings = self.model.prompt_encoder( points=points, boxes=boxes, masks=mask_input, ) # ----- Prompt encoder ----- # ----- Mask decoder ----- low_res_masks, iou_predictions = self.model.mask_decoder( image_embeddings=self.features, image_pe=self.model.prompt_encoder.get_dense_pe(), sparse_prompt_embeddings=sparse_embeddings, dense_prompt_embeddings=dense_embeddings, multimask_output=multimask_output, ) # ----- Mask decoder ----- # 上采样mask掩膜到原始图片尺寸 # Upscale the masks to the original image resolution masks = self.model.postprocess_masks(low_res_masks, self.input_size, self.original_size) if not return_logits: masks = masks > self.model.mask_threshold return masks, iou_predictions, low_res_masks
-
-
get_image_embedding:获得图像image_encoder的特征。
-
def get_image_embedding(self) -> torch.Tensor: if not self.is_image_set: raise RuntimeError( "An image must be set with .set_image(...) to generate an embedding." ) assert self.features is not None, "Features must exist if an image has been set." return self.features
-
-
ResizeLongestSide是专门用来处理图片、标记点和标记框的工具类。ResizeLongestSide类在segment_anything/utils/transforms.py文件。
-
apply_image:原图尺寸根据标准尺寸计算调整(get_preprocess_shape)得新尺寸。
-
def apply_image(self, image: np.ndarray) -> np.ndarray: target_size = self.get_preprocess_shape(image.shape[0], image.shape[1], self.target_length) # to_pil_image将numpy装变为PIL.Image,而后resize return np.array(resize(to_pil_image(image), target_size)) -
不直接使用resize的目的是为了不破坏原图片中各个物体的比例关系。通过计算获得与标准尺寸对应的缩放比例并缩放图片,后续通过padding补零操作(虚线部分),将所有图片的尺寸都变成标准尺寸。
-
apply_coords:图像改变了原始尺寸,对应的标记点坐标位置也要改变[get_preprocess_shape]。
-
def apply_coords(self, coords: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray: old_h, old_w = original_size # 图像改变了原始尺寸,所以对应的标记点坐标位置也会发生改变 new_h, new_w = self.get_preprocess_shape( original_size[0], original_size[1], self.target_length ) # 深拷贝coords coords = deepcopy(coords).astype(float) # 改变对应标记点坐标 coords[..., 0] = coords[..., 0] * (new_w / old_w) coords[..., 1] = coords[..., 1] * (new_h / old_h) return coords -
apply_boxes:图像改变了原始尺寸,对应的标记框坐标位置也要改变[get_preprocess_shape]。
-
def apply_boxes(self, boxes: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray: # 图像改变了原始尺寸,所以对应的框坐标位置也会发生改变 # reshape: N,4-->N,2,2 boxes = self.apply_coords(boxes.reshape(-1, 2, 2), original_size) # reshape: N,2,2-->N,4 return boxes.reshape(-1, 4) -
get_preprocess_shape
-
def get_preprocess_shape(oldh: int, oldw: int, long_side_length: int) -> Tuple[int, int]: # H和W的长边(大值)作为基准,计算比例,缩放H W的大小 scale = long_side_length * 1.0 / max(oldh, oldw) newh, neww = oldh * scale, oldw * scale # 四舍五入 neww = int(neww + 0.5) newh = int(newh + 0.5) return (newh, neww)
-
-
图像编码器
-
SAM模型关于ViT网络的配置,以sam_vit_b为例,分析ViT网络的结构。
-
def build_sam_vit_b(checkpoint=None): return _build_sam( # 图像编码channel encoder_embed_dim=768, # 主体编码器的个数 encoder_depth=12, # attention中head的个数 encoder_num_heads=12, # 需要将相对位置嵌入添加到注意力图的编码器( Encoder Block) encoder_global_attn_indexes=[2, 5, 8, 11], # 权重 checkpoint=checkpoint, ) -
sam模型中image_encoder模块初始化
-
image_encoder=ImageEncoderViT( # 主体编码器的个数 depth=encoder_depth, # 图像编码channel embed_dim=encoder_embed_dim, # 输入图像的标准尺寸 img_size=image_size, # mlp中channel缩放的比例 mlp_ratio=4, # 归一化层 norm_layer=partial(torch.nn.LayerNorm, eps=1e-6), # attention中head的个数 num_heads=encoder_num_heads, # patch的大小 patch_size=vit_patch_size, # qkv全连接层的偏置 qkv_bias=True, # 是否需要将相对位置嵌入添加到注意力图 use_rel_pos=True, # 需要将相对位置嵌入添加到注意力图的编码器序号(Encoder Block) global_attn_indexes=encoder_global_attn_indexes, # attention中的窗口大小 window_size=14, # 输出的channel out_chans=prompt_embed_dim, ), -
ViT网络(ImageEncoderViT类)结构参数配置。
-
def __init__( self, img_size: int = 1024, # 输入图像的标准尺寸 patch_size: int = 16, # patch的大小 in_chans: int = 3, # 输入图像channel embed_dim: int = 768, # 图像编码channel depth: int = 12, # 主体编码器的个数 num_heads: int = 12, # attention中head的个数 mlp_ratio: float = 4.0, # mlp中channel缩放的比例 out_chans: int = 256, # 输出特征的channel qkv_bias: bool = True, # qkv全连接层的偏置flag norm_layer: Type[nn.Module] = nn.LayerNorm, # 归一化层 act_layer: Type[nn.Module] = nn.GELU, # 激活层 use_abs_pos: bool = True, # 是否使用绝对位置嵌入 use_rel_pos: bool = False, # 是否需要将相对位置嵌入添加到注意力图 rel_pos_zero_init: bool = True, # 源码暂时没有用到 window_size: int = 0, # attention中的窗口大小 global_attn_indexes: Tuple[int, ...] = (), # 需要将相对位置嵌入添加到注意力图的编码器序号(Encoder Block) ) -> None: super().__init__() self.img_size = img_size # -----patch embedding----- self.patch_embed = PatchEmbed( kernel_size=(patch_size, patch_size), stride=(patch_size, patch_size), in_chans=in_chans, embed_dim=embed_dim, ) # -----patch embedding----- # -----positional embedding----- self.pos_embed: Optional[nn.Parameter] = None if use_abs_pos: # Initialize absolute positional embedding with pretrain image size. # 使用预训练图像大小初始化绝对位置嵌入。 self.pos_embed = nn.Parameter( torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim) ) # -----positional embedding----- # -----Transformer Encoder----- self.blocks = nn.ModuleList() for i in range(depth): block = Block( dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, norm_layer=norm_layer, act_layer=act_layer, use_rel_pos=use_rel_pos, rel_pos_zero_init=rel_pos_zero_init, window_size=window_size if i not in global_attn_indexes else 0, input_size=(img_size // patch_size, img_size // patch_size), ) self.blocks.append(block) # -----Transformer Encoder----- # -----Neck----- self.neck = nn.Sequential( nn.Conv2d( embed_dim, out_chans, kernel_size=1, bias=False, ), LayerNorm2d(out_chans), nn.Conv2d( out_chans, out_chans, kernel_size=3, padding=1, bias=False, ), LayerNorm2d(out_chans), ) # -----Neck-----
-
-
ViT网络(ImageEncoderViT类)在特征提取中的几个基本步骤:
-
patch embedding:将图片切分成图片序列块,再经过维度映射后展平成一维向量
-
positional embedding:嵌入位置编码(用于保留位置信息)
-
Transformer Encoder:主体编码器
-
Neck:过渡层
-
def forward(self, x: torch.Tensor) -> torch.Tensor: # patch embedding过程 x = self.patch_embed(x) # positional embedding过程 if self.pos_embed is not None: x = x + self.pos_embed # Transformer Encoder过程 for blk in self.blocks: x = blk(x) # Neck过程 B H W C -> B C H W x = self.neck(x.permute(0, 3, 1, 2)) return x -
PatchEmbed类: 源码其实就是卷积核大小16x16(巧妙切分成固定大小16x16的patch),卷积核通道3×768的卷积操作。图像大小决定了patch的数量
-

-
class PatchEmbed(nn.Module): def __init__( self, kernel_size: Tuple[int, int] = (16, 16), # 卷积核大小 stride: Tuple[int, int] = (16, 16), # 步长 padding: Tuple[int, int] = (0, 0), # padding in_chans: int = 3, # 输入channel embed_dim: int = 768, # 输出channel ) -> None: super().__init__() self.proj = nn.Conv2d( in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding ) def forward(self, x: torch.Tensor) -> torch.Tensor: x = self.proj(x) # B C H W -> B H W C x = x.permute(0, 2, 3, 1) return x -
经过patch embedding后输出tokens需要加入位置编码,位置编码可以理解为一张map,map的行数与输入序列个数相同,每一行代表一个向量,向量的维度和输入序列tokens的维度相同,位置编码的操作是sum,所以维度依旧保持不变。图像尺寸是1024的,因此patch数量是64(=1024/16)
-
# 在ImageEncoderViT的__init__定义 if use_abs_pos: # Initialize absolute positional embedding with pretrain image size. # 使用预训练图像大小初始化绝对位置嵌入。 self.pos_embed = nn.Parameter( torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim) ) # 在ImageEncoderViT的forward添加位置编码 if self.pos_embed is not None: x = x + self.pos_embed -
Transformer Encoder多个重复堆叠Encoder Block组成。
-
# 在ImageEncoderViT的__init__定义 # -----Transformer Encoder----- self.blocks = nn.ModuleList() for i in range(depth): block = Block( dim=embed_dim, # 输入channel num_heads=num_heads, # attention中head的个数 mlp_ratio=mlp_ratio, # mlp中channel缩放的比例 qkv_bias=qkv_bias, # qkv全连接层的偏置flag norm_layer=norm_layer, # 归一化层 act_layer=act_layer, # 激活层 use_rel_pos=use_rel_pos, # 是否需要将相对位置嵌入添加到注意力图 rel_pos_zero_init=rel_pos_zero_init, # 源码暂时没有用到 window_size=window_size if i not in global_attn_indexes else 0, # attention中的窗口大小 input_size=(img_size // patch_size, img_size // patch_size), # 输入特征的尺寸 ) self.blocks.append(block) # -----Transformer Encoder----- -
Encoder Block从低到高由LayerNorm 、Multi-Head Attention和MLP构成。
-
class Block(nn.Module): def __init__( self, dim: int, # 输入channel num_heads: int, # attention中head的个数 mlp_ratio: float = 4.0, # mlp中channel缩放的比例 qkv_bias: bool = True, # qkv全连接层的偏置flag norm_layer: Type[nn.Module] = nn.LayerNorm, # 归一化层 act_layer: Type[nn.Module] = nn.GELU, # 激活层 use_rel_pos: bool = False, # 是否需要将相对位置嵌入添加到注意力图 rel_pos_zero_init: bool = True, # 源码暂时没有用到 window_size: int = 0, # attention中的窗口大小 input_size: Optional[Tuple[int, int]] = None, # 输入特征的尺寸 ) -> None: super().__init__() self.norm1 = norm_layer(dim) # 激活层 self.attn = Attention( # Multi-Head Attention dim, num_heads=num_heads, qkv_bias=qkv_bias, use_rel_pos=use_rel_pos, rel_pos_zero_init=rel_pos_zero_init, input_size=input_size if window_size == 0 else (window_size, window_size), ) self.norm2 = norm_layer(dim) self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer) # MLP self.window_size = window_size # def forward(self, x: torch.Tensor) -> torch.Tensor: shortcut = x x = self.norm1(x) # Window partition 对X进行padding if self.window_size > 0: H, W = x.shape[1], x.shape[2] x, pad_hw = window_partition(x, self.window_size) x = self.attn(x) # Reverse window partition 去除X的padding部分 if self.window_size > 0: x = window_unpartition(x, self.window_size, pad_hw, (H, W)) x = shortcut + x x = x + self.mlp(self.norm2(x)) return x -
Partition操作
-
def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]: B, H, W, C = x.shape pad_h = (window_size - H % window_size) % window_size pad_w = (window_size - W % window_size) % window_size if pad_h > 0 or pad_w > 0: x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h)) Hp, Wp = H + pad_h, W + pad_w # B,Hp/S,S,Wp/S,S,C x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C) # B,Hp/S,Wp/S,S,S,C-->BHpWp/SS,S,S,C windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C) return windows, (Hp, Wp) -
Unpartition操作
-
def window_unpartition( windows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int], hw: Tuple[int, int] ) -> torch.Tensor: Hp, Wp = pad_hw H, W = hw B = windows.shape[0] // (Hp * Wp // window_size // window_size) # BHpWp/SS,S,S,C-->B,Hp/S,Wp/S,S,S,C x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1) # B,Hp/S,Wp/S,S,S,C-->B,Hp,Wp,C x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1) if Hp > H or Wp > W: x = x[:, :H, :W, :].contiguous() # B,H,W,C return x -

-
window_partition调整了原始特征尺寸为(H×W–>S×S),目的是了在后续的Multi-Head Attention过程中将相对位置嵌入添加到注意力图(attn),并不是所有Block都需要在注意力图中嵌入相对位置信息;window_unpartition则是恢复特征的原始尺寸(S×S–>H×W)。
-
Multi-Head Attention:先从Attention讲解,再到Multi-Head Attention,最后再讲注意力特征嵌入了相对位置特征的Multi-Head Attention。
-
class Attention(nn.Module): """Multi-head Attention block with relative position embeddings.""" def __init__( self, dim: int, # 输入channel num_heads: int = 8, # head数目 qkv_bias: bool = True, use_rel_pos: bool = False, rel_pos_zero_init: bool = True, input_size: Optional[Tuple[int, int]] = None, # 嵌入相对位置注意力特征的尺寸 ) -> None: super().__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = head_dim**-0.5 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.proj = nn.Linear(dim, dim) self.use_rel_pos = use_rel_pos if self.use_rel_pos: # 使用相对位置编码 assert ( input_size is not None ), "Input size must be provided if using relative positional encoding." # initialize relative positional embeddings # 2S-1,Epos self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim)) self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim)) def forward(self, x: torch.Tensor) -> torch.Tensor: B, H, W, _ = x.shape # qkv with shape (3, B, nHead, H * W, C) qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4) # q, k, v with shape (B * nHead, H * W, C) q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0) # attn with shape (B * nHead, H * W, H * W) attn = (q * self.scale) @ k.transpose(-2, -1) if self.use_rel_pos: # 假设use_rel_pos是true (H, W)是 S×S attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W)) attn = attn.softmax(dim=-1) x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1) x = self.proj(x) return x -
对于输入到Multi-head attention模块的特征 F(N×E) ,通过attention模块的nn.Linear进一步提取特征获得输出特征 v(value) 。为了考虑 N 个特征之间存在的亲疏和位置关系对于 v 的影响,所以需要一个额外 attn(attention) 或者理解为权重 w(weight) 对 v 进行加权操作,这引出了计算 w 所需的 q(query) 与 k(key) ,因此可以看到任何V都考虑了N 个token特征之间相互的影响。Multi-head attention的流程如下图所示(不考虑batchsize):
- 首先将每个token的qkv特征维度embed_dim均拆分到每个head的上
- 每个head分别通过q和k计算得到权重w,权重w和v得到输出output,合并所有head的output得到最终的output
-
get_rel_pos用于计算h和w的相对位置的嵌入特征
-
def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor: max_rel_dist = int(2 * max(q_size, k_size) - 1) # Interpolate rel pos if needed. if rel_pos.shape[0] != max_rel_dist: # Interpolate rel pos. 相关位置进行插值 rel_pos_resized = F.interpolate( # 1,N,Ep --> 1,Ep,N --> 1,Ep,2S-1 rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1), size=max_rel_dist, mode="linear", ) # Ep,2S-1 --> 2S-1,Ep rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0) else: rel_pos_resized = rel_pos # Scale the coords with short length if shapes for q and k are different. # 如果q和k长度值不同,则用短边长度缩放坐标。 q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0) k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0) # S,S relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0) # tensor索引是tensor时,即tensor1[tensor2] # 假设tensor2某个具体位置值是2,则tensor1[2]位置的tensor1切片替换tensor2中的2 # tensor1->shape 5,5,3 tensor2->shape 2,2,3 tensor1切片->shape 5,3 tensor1[tensor2]->shape 2,2,3,5,3 # tensor1->shape 5,5 tensor2->shape 3,2,3 tensor1切片->shape 5 tensor1[tensor2]->shape 3,2,3,5 # 2S-1,Ep-->S,S,Ep return rel_pos_resized[relative_coords.long()] -

-
add_decomposed_rel_pos为atten注意力特征添加相对位置的嵌入特征。
-
def add_decomposed_rel_pos( attn: torch.Tensor, q: torch.Tensor, rel_pos_h: torch.Tensor, rel_pos_w: torch.Tensor, q_size: Tuple[int, int], k_size: Tuple[int, int], ) -> torch.Tensor: # S,S q_h, q_w = q_size k_h, k_w = k_size # rel_pos_h -> 2S-1×Epos Rh = get_rel_pos(q_h, k_h, rel_pos_h) Rw = get_rel_pos(q_w, k_w, rel_pos_w) B, _, dim = q.shape r_q = q.reshape(B, q_h, q_w, dim) # torch.einsum用于简洁的表示乘积、点积、转置等方法 # B,q_h, q_w, k_h rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh) # B,q_h, q_w, k_w rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw) attn = ( # B,q_h, q_w, k_h, k_w attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :] ).view(B, q_h * q_w, k_h * k_w) return attn -
MLP
-
class MLPBlock(nn.Module): def __init__( self, embedding_dim: int, mlp_dim: int, act: Type[nn.Module] = nn.GELU, ) -> None: super().__init__() self.lin1 = nn.Linear(embedding_dim, mlp_dim) self.lin2 = nn.Linear(mlp_dim, embedding_dim) self.act = act() def forward(self, x: torch.Tensor) -> torch.Tensor: return self.lin2(self.act(self.lin1(x))) -
Neck
-
# 在ImageEncoderViT的__init__定义 # -----Neck----- self.neck = nn.Sequential( nn.Conv2d( embed_dim, out_chans, kernel_size=1, bias=False, ), LayerNorm2d(out_chans), nn.Conv2d( out_chans, out_chans, kernel_size=3, padding=1, bias=False, ), LayerNorm2d(out_chans), ) # -----Neck----- class LayerNorm2d(nn.Module): def __init__(self, num_channels: int, eps: float = 1e-6) -> None: super().__init__() self.weight = nn.Parameter(torch.ones(num_channels)) self.bias = nn.Parameter(torch.zeros(num_channels)) self.eps = eps def forward(self, x: torch.Tensor) -> torch.Tensor: u = x.mean(1, keepdim=True) # dim=1维度求均值并保留通道 s = (x - u).pow(2).mean(1, keepdim=True) x = (x - u) / torch.sqrt(s + self.eps) x = self.weight[:, None, None] * x + self.bias[:, None, None] return x
-
-
sam模型中prompt_encoder模块初始化
-
prompt_encoder=PromptEncoder( # 提示编码channel(和image_encoder输出channel一致,后续会融合) embed_dim=prompt_embed_dim, # mask的编码尺寸(和image_encoder输出尺寸一致) image_embedding_size=(image_embedding_size, image_embedding_size), # 输入图像的标准尺寸 input_image_size=(image_size, image_size), # 对输入掩码编码的通道数 mask_in_chans=16, ),
-
-
ProEnco网络结构与执行流程,ProEnco网络(PromptEncoder类)结构参数配置。
-
def __init__( self, embed_dim: int, # 提示编码channel image_embedding_size: Tuple[int, int], # mask的编码尺寸 input_image_size: Tuple[int, int], # 输入图像的标准尺寸 mask_in_chans: int, # 输入掩码编码的通道数 activation: Type[nn.Module] = nn.GELU, # 激活层 ) -> None: super().__init__() self.embed_dim = embed_dim # 提示编码channel self.input_image_size = input_image_size # 输入图像的标准尺寸 self.image_embedding_size = image_embedding_size # mask的编码尺寸 self.pe_layer = PositionEmbeddingRandom(embed_dim // 2) self.num_point_embeddings: int = 4 # 4个点:正负点,框的俩个点 point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)] # 4个点的嵌入向量 # nn.ModuleList它是一个存储不同module, # 并自动将每个module的parameters添加到网络之中的容器 self.point_embeddings = nn.ModuleList(point_embeddings) # 4个点的嵌入向量添加到网络 self.not_a_point_embed = nn.Embedding(1, embed_dim) # 不是点的嵌入向量 self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1]) # mask的输入尺寸 self.mask_downscaling = nn.Sequential( # 输入mask时 4倍下采样 nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2), LayerNorm2d(mask_in_chans // 4), activation(), nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2), LayerNorm2d(mask_in_chans), activation(), nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1), ) self.no_mask_embed = nn.Embedding(1, embed_dim) # 没有mask输入时 嵌入向量 -
SAM模型中ProEnco网络结构如下图所示:
-

-
ProEnco网络(PromptEncoder类)在特征提取中的几个基本步骤:
- Embed_Points:标记点编码(标记点由点转变为向量)
- Embed_Boxes:标记框编码(标记框由点转变为向量)
- Embed_Masks:mask编码(mask下采样保证与Image encoder输出一致)
-
def forward( self, points: Optional[Tuple[torch.Tensor, torch.Tensor]], boxes: Optional[torch.Tensor], masks: Optional[torch.Tensor], ) -> Tuple[torch.Tensor, torch.Tensor]: # 获得 batchsize 当前predict为1 bs = self._get_batch_size(points, boxes, masks) # -----sparse_embeddings---- sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device()) if points is not None: coords, labels = points point_embeddings = self._embed_points(coords, labels, pad=(boxes is None)) sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1) if boxes is not None: box_embeddings = self._embed_boxes(boxes) sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1) # -----sparse_embeddings---- # -----dense_embeddings---- if masks is not None: dense_embeddings = self._embed_masks(masks) else: dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand( bs, -1, self.image_embedding_size[0], self.image_embedding_size[1] ) # -----dense_embeddings---- return sparse_embeddings, dense_embeddings def _get_batch_size( self, points: Optional[Tuple[torch.Tensor, torch.Tensor]], boxes: Optional[torch.Tensor], masks: Optional[torch.Tensor], ) -> int: if points is not None: return points[0].shape[0] elif boxes is not None: return boxes.shape[0] elif masks is not None: return masks.shape[0] else: return 1 def _get_device(self) -> torch.device: return self.point_embeddings[0].weight.device -
Embed_Points:标记点预处理,将channel由2变成embed_dim(MatMul:forward_with_coords),然后再加上位置编码权重。
-
def _embed_points( self, points: torch.Tensor, labels: torch.Tensor, pad: bool, ) -> torch.Tensor: # 移到像素中心 points = points + 0.5 # points和boxes联合则不需要pad if pad: padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device) # B,1,2 padding_label = -torch.ones((labels.shape[0], 1), device=labels.device) # B,1 points = torch.cat([points, padding_point], dim=1) # B,N+1,2 labels = torch.cat([labels, padding_label], dim=1) # B,N+1 point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size) # B,N+1,2f # labels为-1是非标记点,设为非标记点权重 point_embedding[labels == -1] = 0.0 point_embedding[labels == -1] += self.not_a_point_embed.weight # labels为0是背景点,加上背景点权重 point_embedding[labels == 0] += self.point_embeddings[0].weight # labels为1的目标点,加上目标点权重 point_embedding[labels == 1] += self.point_embeddings[1].weight return point_embedding -
pad的作用相当于box占位符号,box和points可以联合标定完成图像分割的,但是此时的box只能有一个,不能有多个。
-
Embed_Boxes:标记框预处理,将channel由4到2再变成embed_dim(MatMul:forward_with_coords),然后再加上位置编码权重。
-
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor: # 移到像素中心 boxes = boxes + 0.5 coords = boxes.reshape(-1, 2, 2) corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size) # # 目标框起始点的和末位点分别加上权重 corner_embedding[:, 0, :] += self.point_embeddings[2].weight corner_embedding[:, 1, :] += self.point_embeddings[3].weight return corner_embedding -
boxes reshape 后 batchsize 是会增加的,B,N,4–>BN,2,2;因此这里可以得出box和points联合标定时,box为什么只能是一个,而不能是多个。
-
Embed_Masks:mask的输出尺寸是Image encoder模块输出的图像编码尺寸的4倍,因此为了保持一致,需要4倍下采样。
-
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor: # mask下采样4倍 mask_embedding = self.mask_downscaling(masks) return mask_embedding # 在PromptEncoder的__init__定义 self.mask_downscaling = nn.Sequential( # 输入mask时 4倍下采样 nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2), LayerNorm2d(mask_in_chans // 4), activation(), nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2), LayerNorm2d(mask_in_chans), activation(), nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1), ) -
假设没有mask输入,则将no_mask_embed编码扩展到与图像编码一致的尺寸代替mask。
-
# 在PromptEncoder的forward定义 dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand( bs, -1, self.image_embedding_size[0], self.image_embedding_size[1] ) -
PositionEmbeddingRandom:用于将标记点和标记框的坐标进行提示编码预处理。
-
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None: super().__init__() if scale is None or scale <= 0.0: scale = 1.0 # 理解为模型的常数 [2,f] self.register_buffer( "positional_encoding_gaussian_matrix", scale * torch.randn((2, num_pos_feats)), ) -
将标记点的坐标具体的位置转变为[0~1]之间的比例位置
-
def forward_with_coords( self, coords_input: torch.Tensor, image_size: Tuple[int, int] ) -> torch.Tensor: coords = coords_input.clone() # 将坐标位置缩放到[0~1]之间 coords[:, :, 0] = coords[:, :, 0] / image_size[1] coords[:, :, 1] = coords[:, :, 1] / image_size[0] # B,N+1,2-->B,N+1,2f return self._pe_encoding(coords.to(torch.float)) -
标记点位置编码,因为sin和cos,编码的值归一化至 [-1,1]
-
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor: # assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape coords = 2 * coords - 1 # B,N+1,2 × 2,f --> B,N+1,f coords = coords @ self.positional_encoding_gaussian_matrix coords = 2 * np.pi * coords # outputs d_1 x ... x d_n x C shape # B,N+1,2f return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
-
-
MaskDecoder网络简述,sam模型中Mask_decoder模块初始化
-
mask_decoder=MaskDecoder( # 消除掩码歧义预测的掩码数 num_multimask_outputs=3, # 用于预测mask的网咯transformer transformer=TwoWayTransformer( # 层数 depth=2, # 输入channel embedding_dim=prompt_embed_dim, # MLP内部channel mlp_dim=2048, # attention的head数 num_heads=8, ), # transformer的channel transformer_dim=prompt_embed_dim, # MLP的深度,MLP用于预测掩模质量的 iou_head_depth=3, # MLP隐藏channel iou_head_hidden_dim=256, ), -
MaskDeco网络(MaskDecoder类)结构参数配置。
-
def __init__( self, *, # transformer的channel transformer_dim: int, # 用于预测mask的网咯transformer transformer: nn.Module, # 消除掩码歧义预测的掩码数 num_multimask_outputs: int = 3, # 激活层 activation: Type[nn.Module] = nn.GELU, # MLP深度,MLP用于预测掩模质量的 iou_head_depth: int = 3, # MLP隐藏channel iou_head_hidden_dim: int = 256, ) -> None: super().__init__() self.transformer_dim = transformer_dim # transformer的channel #----- transformer ----- self.transformer = transformer # 用于预测mask的网咯transformer # ----- transformer ----- self.num_multimask_outputs = num_multimask_outputs # 消除掩码歧义预测的掩码数 self.iou_token = nn.Embedding(1, transformer_dim) # iou的taken self.num_mask_tokens = num_multimask_outputs + 1 # mask数 self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim) # mask的tokens数 #----- upscaled ----- # 4倍上采样 self.output_upscaling = nn.Sequential( nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍 LayerNorm2d(transformer_dim // 4), activation(), nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2), activation(), ) # ----- upscaled ----- # ----- MLP ----- # 对应mask数的MLP self.output_hypernetworks_mlps = nn.ModuleList( [ MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3) for i in range(self.num_mask_tokens) ] ) # ----- MLP ----- # ----- MLP ----- # 对应iou的MLP self.iou_prediction_head = MLP( transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth ) # ----- MLP ----- -
SAM模型中MaskDeco网络结构如下图所示:
-

-
MaskDeco网络(MaskDecoder类)在特征提取中的几个基本步骤:
- transformer:融合特征(提示信息特征与图像特征)获得粗略掩膜src
- upscaled:对粗略掩膜src上采样
- mask_MLP:全连接层组(计算加权权重,使粗掩膜src转变为掩膜mask)
- iou_MLP:全连接层组(计算掩膜mask的Score)
-
def forward( self, # image encoder 图像特征 image_embeddings: torch.Tensor, # 位置编码 image_pe: torch.Tensor, # 标记点和标记框的嵌入编码 sparse_prompt_embeddings: torch.Tensor, # 输入mask的嵌入编码 dense_prompt_embeddings: torch.Tensor, # 是否输出多个mask multimask_output: bool, ) -> Tuple[torch.Tensor, torch.Tensor]: masks, iou_pred = self.predict_masks( image_embeddings=image_embeddings, image_pe=image_pe, sparse_prompt_embeddings=sparse_prompt_embeddings, dense_prompt_embeddings=dense_prompt_embeddings, ) # Select the correct mask or masks for output if multimask_output: mask_slice = slice(1, None) else: mask_slice = slice(0, 1) masks = masks[:, mask_slice, :, :] iou_pred = iou_pred[:, mask_slice] return masks, iou_pred def predict_masks( self, image_embeddings: torch.Tensor, image_pe: torch.Tensor, sparse_prompt_embeddings: torch.Tensor, dense_prompt_embeddings: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: # Concatenate output tokens # 1,E and 4,E --> 5,E output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0) # 5,E --> B,5,E output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1) # B,5,E and B,N,E -->B,5+N,E N是点的个数(标记点和标记框的点) tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1) # 扩展image_embeddings的B维度,因为boxes标记分割时,n个box时batchsize=batchsize*n # Expand per-image data in batch direction to be per-mask # B,C,H,W src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0) # B,C,H,W + 1,C,H,W ---> B,C,H,W src = src + dense_prompt_embeddings # 1,C,H,W---> B,C,H,W pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0) b, c, h, w = src.shape # ----- transformer ----- # Run the transformer # B,N,C hs, src = self.transformer(src, pos_src, tokens) # ----- transformer ----- iou_token_out = hs[:, 0, :] mask_tokens_out = hs[:, 1: (1 + self.num_mask_tokens), :] # Upscale mask embeddings and predict masks using the mask tokens # B,N,C-->B,C,H,W src = src.transpose(1, 2).view(b, c, h, w) # ----- upscaled ----- # 4倍上采样 upscaled_embedding = self.output_upscaling(src) # ----- upscaled ----- hyper_in_list: List[torch.Tensor] = [] # ----- mlp ----- for i in range(self.num_mask_tokens): # mask_tokens_out[:, i, :]: B,1,C # output_hypernetworks_mlps: B,1,c hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])) # B,n,c hyper_in = torch.stack(hyper_in_list, dim=1) # ----- mlp ----- b, c, h, w = upscaled_embedding.shape # B,n,c × B,c,N-->B,n,h,w masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w) # ----- mlp ----- # Generate mask quality predictions # iou_token_out: B,1,n iou_pred = self.iou_prediction_head(iou_token_out) # ----- mlp ----- # masks: B,n,h,w # iou_pred: B,1,n return masks, iou_pred -
MaskDeco由多个重复堆叠TwoWayAttention Block和1个Multi-Head Attention组成。
-
class TwoWayTransformer(nn.Module): def __init__( self, # 层数 depth: int, # 输入channel embedding_dim: int, # attention的head数 num_heads: int, # MLP内部channel mlp_dim: int, activation: Type[nn.Module] = nn.ReLU, attention_downsample_rate: int = 2, ) -> None: super().__init__() self.depth = depth # 层数 self.embedding_dim = embedding_dim # 输入channel self.num_heads = num_heads # attention的head数 self.mlp_dim = mlp_dim # MLP内部隐藏channel self.layers = nn.ModuleList() for i in range(depth): self.layers.append( TwoWayAttentionBlock( embedding_dim=embedding_dim, # 输入channel num_heads=num_heads, # attention的head数 mlp_dim=mlp_dim, # MLP中间channel activation=activation, # 激活层 attention_downsample_rate=attention_downsample_rate, # 下采样 skip_first_layer_pe=(i == 0), ) ) self.final_attn_token_to_image = Attention( embedding_dim, num_heads, downsample_rate=attention_downsample_rate ) self.norm_final_attn = nn.LayerNorm(embedding_dim) def forward( self, image_embedding: Tensor, image_pe: Tensor, point_embedding: Tensor, ) -> Tuple[Tensor, Tensor]: # BxCxHxW -> BxHWxC == B x N_image_tokens x C bs, c, h, w = image_embedding.shape # 图像编码(image_encoder的输出) # BxHWxC=>B,N,C image_embedding = image_embedding.flatten(2).permute(0, 2, 1) # 图像位置编码 # BxHWxC=>B,N,C image_pe = image_pe.flatten(2).permute(0, 2, 1) # 标记点编码 # B,N,C queries = point_embedding keys = image_embedding # -----TwoWayAttention----- for layer in self.layers: queries, keys = layer( queries=queries, keys=keys, query_pe=point_embedding, key_pe=image_pe, ) # -----TwoWayAttention----- q = queries + point_embedding k = keys + image_pe # -----Attention----- attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) # -----Attention----- queries = queries + attn_out queries = self.norm_final_attn(queries) return queries, keys -
TwoWayAttention Block由LayerNorm 、Multi-Head Attention和MLP构成。
-
class TwoWayAttentionBlock(nn.Module): def __init__( self, embedding_dim: int, # 输入channel num_heads: int, # attention的head数 mlp_dim: int = 2048, # MLP中间channel activation: Type[nn.Module] = nn.ReLU, # 激活层 attention_downsample_rate: int = 2, # 下采样 skip_first_layer_pe: bool = False, ) -> None: super().__init__() self.self_attn = Attention(embedding_dim, num_heads) self.norm1 = nn.LayerNorm(embedding_dim) self.cross_attn_token_to_image = Attention( embedding_dim, num_heads, downsample_rate=attention_downsample_rate ) self.norm2 = nn.LayerNorm(embedding_dim) self.mlp = MLPBlock(embedding_dim, mlp_dim, activation) self.norm3 = nn.LayerNorm(embedding_dim) self.norm4 = nn.LayerNorm(embedding_dim) self.cross_attn_image_to_token = Attention( embedding_dim, num_heads, downsample_rate=attention_downsample_rate ) self.skip_first_layer_pe = skip_first_layer_pe def forward( self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor ) -> Tuple[Tensor, Tensor]: # queries:标记点编码相关(原始标记点编码经过一系列特征提取) # keys:原始图像编码相关(原始图像编码经过一系列特征提取) # query_pe:原始标记点编码 # key_pe:原始图像位置编码 # 第一轮本身queries==query_pe没比较再"残差" if self.skip_first_layer_pe: queries = self.self_attn(q=queries, k=queries, v=queries) else: q = queries + query_pe attn_out = self.self_attn(q=q, k=q, v=queries) queries = queries + attn_out queries = self.norm1(queries) # Cross attention block, tokens attending to image embedding q = queries + query_pe k = keys + key_pe attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys) queries = queries + attn_out queries = self.norm2(queries) # MLP block mlp_out = self.mlp(queries) queries = queries + mlp_out queries = self.norm3(queries) # Cross attention block, image embedding attending to tokens q = queries + query_pe k = keys + key_pe attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries) keys = keys + attn_out keys = self.norm4(keys) return queries, keys -
TwoWayAttentionBlock是Prompt encoder的提示信息特征与Image encoder的图像特征的融合过程,而Prompt encoder对提示信息没有过多处理,因此TwoWayAttentionBlock的目的是边对提示信息特征做进一步处理边与图像特征融合。
-
MaskDeco的Attention与ViT的Attention有些细微的不同:MaskDeco的Attention是3个FC层分别接受3个输入获得q、k和v,而ViT的Attention是1个FC层接受1个输入后将结果均拆分获得q、k和v。
-
class Attention(nn.Module): def __init__( self, embedding_dim: int, # 输入channel num_heads: int, # attention的head数 downsample_rate: int = 1, # 下采样 ) -> None: super().__init__() self.embedding_dim = embedding_dim self.internal_dim = embedding_dim // downsample_rate self.num_heads = num_heads assert self.internal_dim % num_heads == 0, "num_heads must divide embedding_dim." # qkv获取 self.q_proj = nn.Linear(embedding_dim, self.internal_dim) self.k_proj = nn.Linear(embedding_dim, self.internal_dim) self.v_proj = nn.Linear(embedding_dim, self.internal_dim) self.out_proj = nn.Linear(self.internal_dim, embedding_dim) def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor: b, n, c = x.shape x = x.reshape(b, n, num_heads, c // num_heads) return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head def _recombine_heads(self, x: Tensor) -> Tensor: b, n_heads, n_tokens, c_per_head = x.shape x = x.transpose(1, 2) return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor: # Input projections q = self.q_proj(q) k = self.k_proj(k) v = self.v_proj(v) # Separate into heads # B,N_heads,N_tokens,C_per_head q = self._separate_heads(q, self.num_heads) k = self._separate_heads(k, self.num_heads) v = self._separate_heads(v, self.num_heads) # Attention _, _, _, c_per_head = q.shape attn = q @ k.permute(0, 1, 3, 2) # B,N_heads,N_tokens,C_per_head # Scale attn = attn / math.sqrt(c_per_head) attn = torch.softmax(attn, dim=-1) # Get output out = attn @ v # # B,N_tokens,C out = self._recombine_heads(out) out = self.out_proj(out) return out -
MaskDeco的Attention和ViT的Attention的结构对比示意图:
-

-
transformer_MLP
-
class MLPBlock(nn.Module): def __init__( self, embedding_dim: int, mlp_dim: int, act: Type[nn.Module] = nn.GELU, ) -> None: super().__init__() self.lin1 = nn.Linear(embedding_dim, mlp_dim) self.lin2 = nn.Linear(mlp_dim, embedding_dim) self.act = act() def forward(self, x: torch.Tensor) -> torch.Tensor: return self.lin2(self.act(self.lin1(x))) -
upscaled
-
# 在MaskDecoder的__init__定义 self.output_upscaling = nn.Sequential( nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍 LayerNorm2d(transformer_dim // 4), activation(), nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2), activation(), ) # 在MaskDecoder的predict_masks添加位置编码 upscaled_embedding = self.output_upscaling(src) -
mask_MLP
-
# 在MaskDecoder的__init__定义 self.output_hypernetworks_mlps = nn.ModuleList( [ MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3) for i in range(self.num_mask_tokens) ] ) # 在MaskDecoder的predict_masks添加位置编码 for i in range(self.num_mask_tokens): # mask_tokens_out[:, i, :]: B,1,C # output_hypernetworks_mlps: B,1,c hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])) # B,n,c hyper_in = torch.stack(hyper_in_list, dim=1) b, c, h, w = upscaled_embedding.shape # B,n,c × B,c,N-->B,n,h,w masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w) -
iou_MLP
-
# 在MaskDecoder的__init__定义 self.iou_prediction_head = MLP( transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth ) # 在MaskDecoder的predict_masks添加位置编码 iou_pred = self.iou_prediction_head(iou_token_out) -
MaskDeco_MLP
-
class MLP(nn.Module): def __init__( self, input_dim: int, # 输入channel hidden_dim: int, # 中间channel output_dim: int, # 输出channel num_layers: int, # fc的层数 sigmoid_output: bool = False, ) -> None: super().__init__() self.num_layers = num_layers h = [hidden_dim] * (num_layers - 1) self.layers = nn.ModuleList( nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]) ) self.sigmoid_output = sigmoid_output def forward(self, x): for i, layer in enumerate(self.layers): x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x) if self.sigmoid_output: x = F.sigmoid(x) return x -
iou_MLP
-
# 在MaskDecoder的__init__定义 self.iou_prediction_head = MLP( transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth ) # 在MaskDecoder的predict_masks添加位置编码 iou_pred = self.iou_prediction_head(iou_token_out) -
MaskDeco_MLP
-
class MLP(nn.Module): def __init__( self, input_dim: int, # 输入channel hidden_dim: int, # 中间channel output_dim: int, # 输出channel num_layers: int, # fc的层数 sigmoid_output: bool = False, ) -> None: super().__init__() self.num_layers = num_layers h = [hidden_dim] * (num_layers - 1) self.layers = nn.ModuleList( nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]) ) self.sigmoid_output = sigmoid_output def forward(self, x): for i, layer in enumerate(self.layers): x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x) if self.sigmoid_output: x = F.sigmoid(x) return x
-
sam代码简析
news2026/4/8 9:39:48
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1683086.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

Arthas,应用诊断利器!【送源码】
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信…
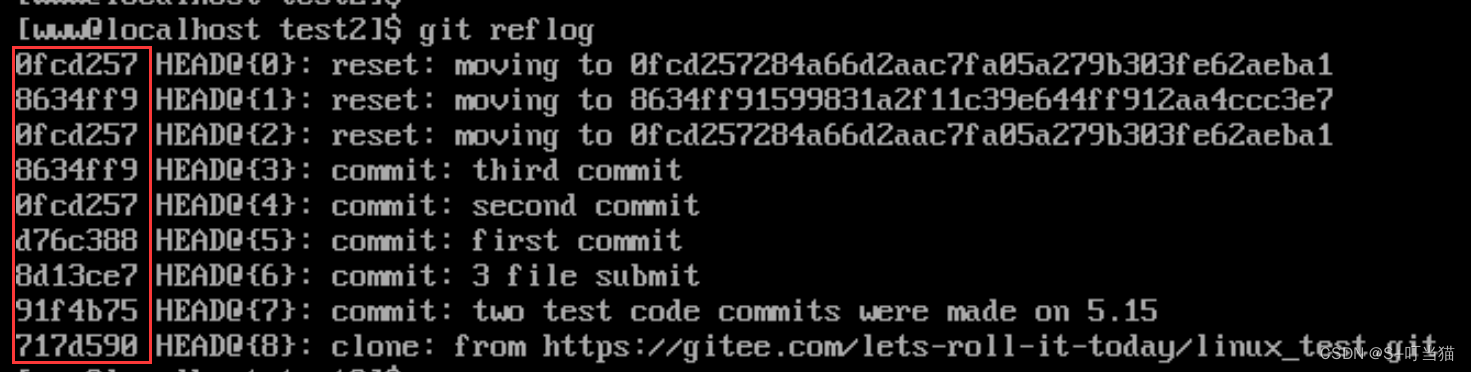
4---git命令详解第一部分
一、提交文件方面命令:
1.1第一步:将需要提交的文件放进暂存区:
添加单个文件到暂存区stage:
git add 文件名 添加多个文件到暂存区:
git add 文件名1 文件名2 ... 将目录下所有文件添加到暂存区:
git…

基于BERT的医学影像报告语料库构建
大模型时代,任何行业,任何企业的数据治理未来将会以“语料库”的自动化构建为基石。因此这一系列精选的论文还是围绕在语料库的建设以及自动化的构建。
通读该系列的文章,犹如八仙过海,百花齐放。非结构的提取无外乎关注于非结构…

修改 ant design tour 漫游式导航的弹窗边框样式
一 说明 应项目要求,调整ant design tour 弹窗边框的样式。tour 原本样式是有遮罩层,因此没有边框看起来也不突兀。原图如下: 但是UI设计是取消遮罩层,并设置边框样式。当 取消 了遮罩层,没有设置边框样式的图片如下&a…

STM32开发学习——使用 Cortex-M3M4M7 故障异常原因与定位(三)
STM32开发学习——使用 Cortex-M3M4M7 故障异常原因与定位(三) 文章目录 STM32开发学习——使用 Cortex-M3M4M7 故障异常原因与定位(三)文档说明:官方参考文档线上链接(可在线阅读与下载)&#…
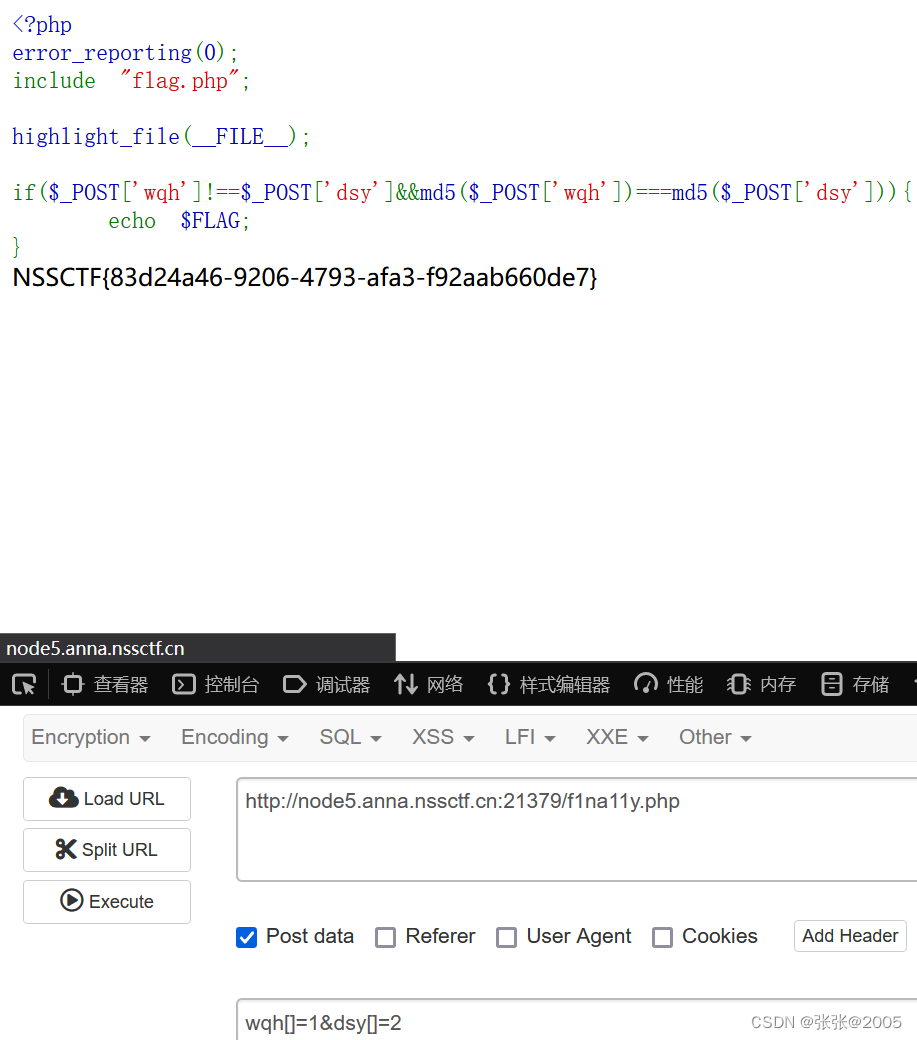
nssctf(Web刷题)
[SWPUCTF 2021 新生赛]gift_F12
打开题目是一个时间页面,不过看了一会儿发现没有什么用
直接F12打开网页源代码 CtrlF搜索flag 找到了flag
NSSCTF{We1c0me_t0_WLLMCTF_Th1s_1s_th3_G1ft}
[第五空间 2021]签到题
NSSCTF{welcometo5space}
[SWPUCTF 2021 新生赛…

MySQL备份与日志练习
1、创建对mysql数据库test1的定时备份任务,频率是每周一的2点
create database test1;crond -e0 2 * * 1 mysqldump -u root -pAdmin123 --databases test1 > /opt/test1.sql2、test1中有t1、t2、t3三张表,要求只备份t2这张表 mysqldump -u root -pA…
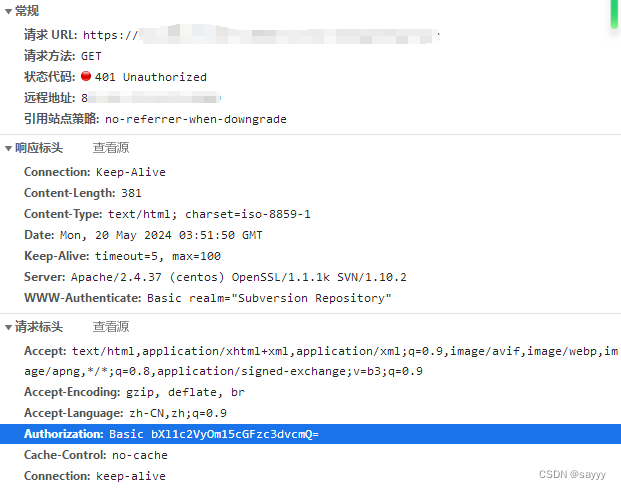
JAVA 中 HTTP 基本认证(Basic Authentication)
目录 服务端这么做服务端告知客户端使用 Basic Authentication 方式进行认证服务端接收并处理客户端按照 Basic Authentication 方式发送的数据 客户端这么做如果客户端是浏览器如果客户端是 RestTemplat如果客户端是 HttpClient 其它参考 服务端这么做
服务端告知客户端使用 …
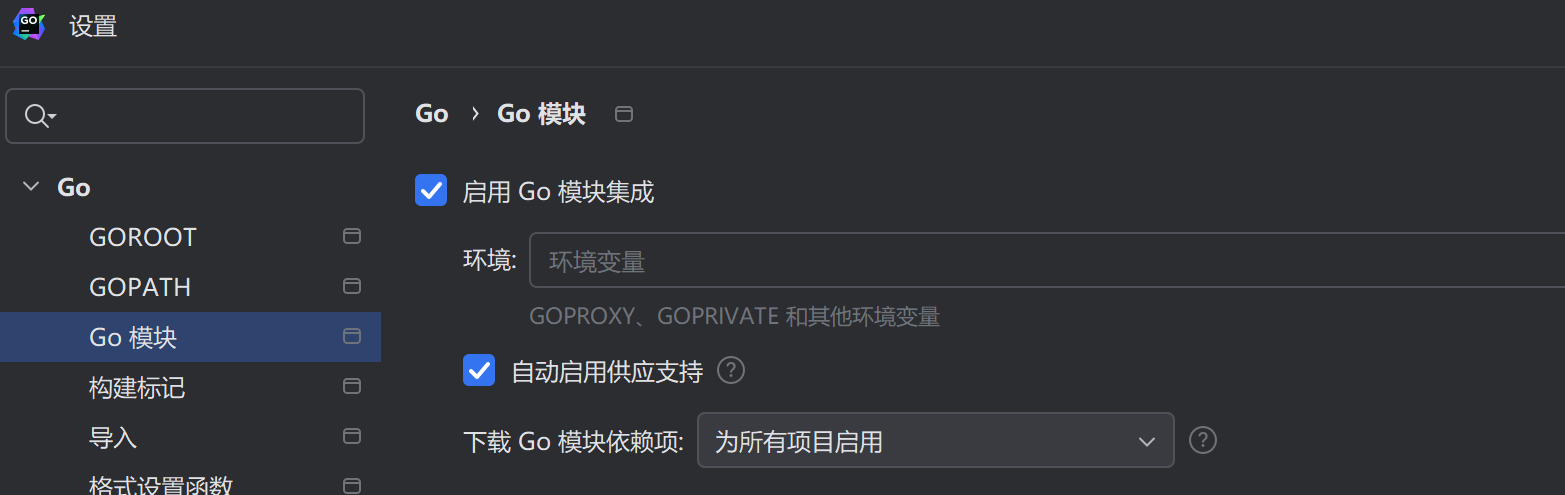
2.go环境配置与开发工具选择
go 环境配置
下载安装包
官网(https://go.dev/dl/) 下载地址(国内)(https://golang.google.cn/dl/)
根据自己的操作系统选择下载即可 下载后安装 记住地址
比如: D:\work\devtool\go
配置系统环境变量 PATH 指向 go 的安装 bin 目录
比如: D:\work…

如何将Docker容器打包并在其他服务器上运行
如何将Docker容器打包并在其他服务器上运行 我会幻想很多次我们的相遇,你穿着合身的T恤,一个素色的外套,搭配一条蓝色的牛仔裤,干净的像那天空中的云朵,而我,还是一个的傻傻的少年,我们相识而笑…
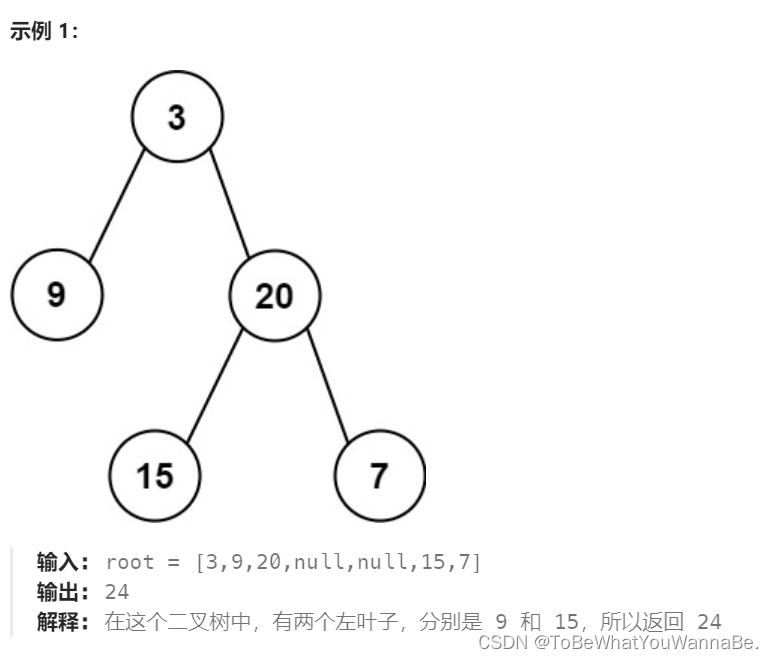
代码随想录-Day17
110. 平衡二叉树
这道题中的平衡二叉树的定义是:二叉树的每个节点的左右子树的高度差的绝对值不超过 111,则二叉树是平衡二叉树。根据定义,一棵二叉树是平衡二叉树,当且仅当其所有子树也都是平衡二叉树,因此可以使用递…

WPF水流动画(使用转换器模拟逻辑门控制水流信号)
前言
在使用WPF绘制流程图并模拟水流动画时,往往既需要控制阀泵的开合,又要控制动画启停。倘若能够将阀泵的开合与动画播放建立逻辑关系,这样就能够让业务代码“专心”地去控制阀泵开关,而不需要处理界面的展示。
动画示例 说明…

2024-5-4-从0到1手写配置中心Config之基于h2的config-server
添加依赖
新建的web工程中添加h2的依赖 添加h2的配置
设置数据源和密码设置初始化sql语句打开h2的控制台 初始化语句创建一个config表,保存服务配置信息。 完成CRUD接口
controller类 mapper接口 测试
在web控制台可以看到sql已经初始化完成,crud接口…
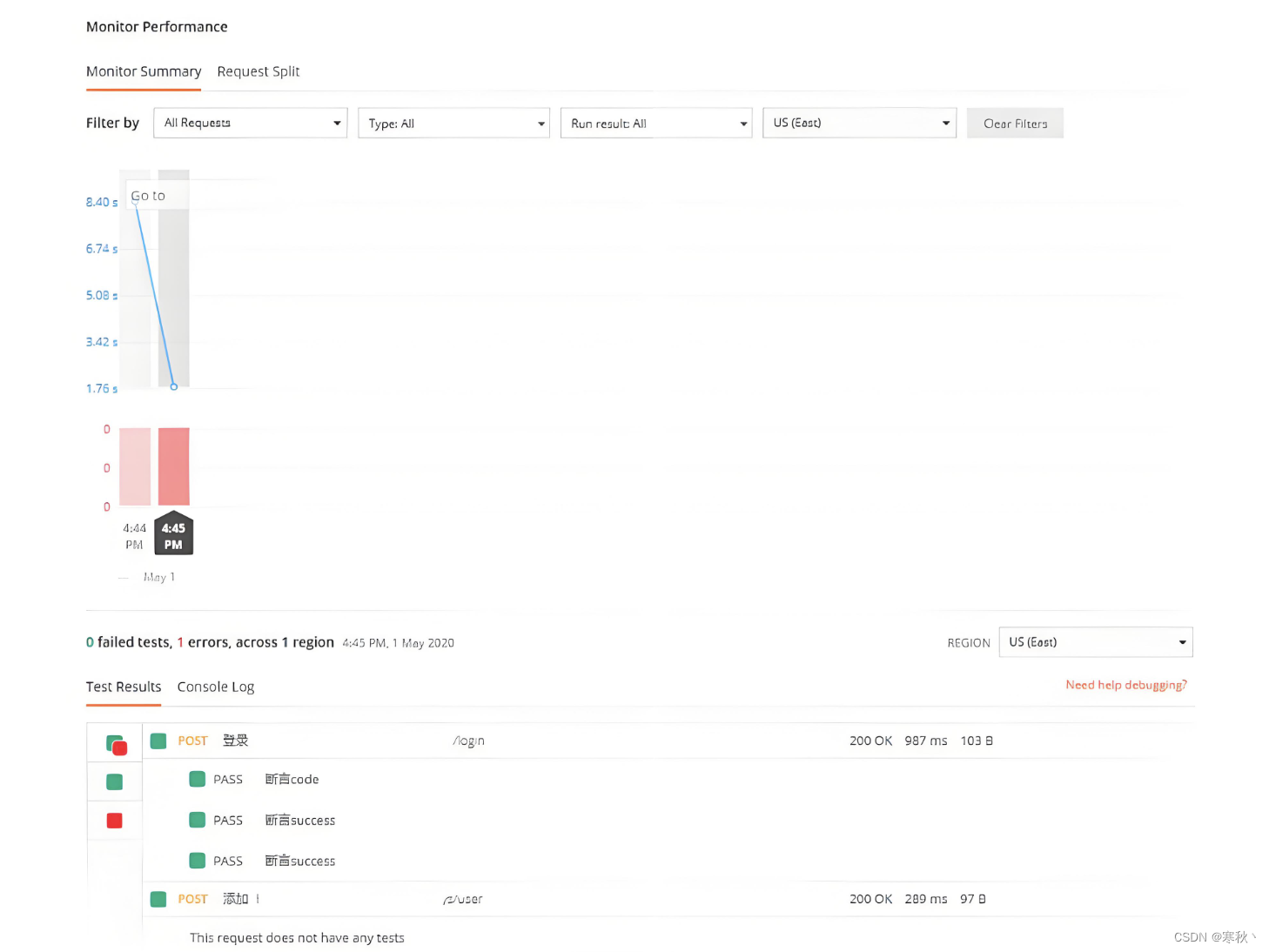
Postman进阶功能-Mock服务与监控
大家好,前面跟大家分享一些关于 Postman 的进阶功能,当我们深入探索 Postman 的进阶功能时,Mock 服务与监控这两个重要方面便跃然眼前。 首先,Mock 服务为我们提供了一种灵活便捷的方式,让我们在某些实际接口尚未准备好…
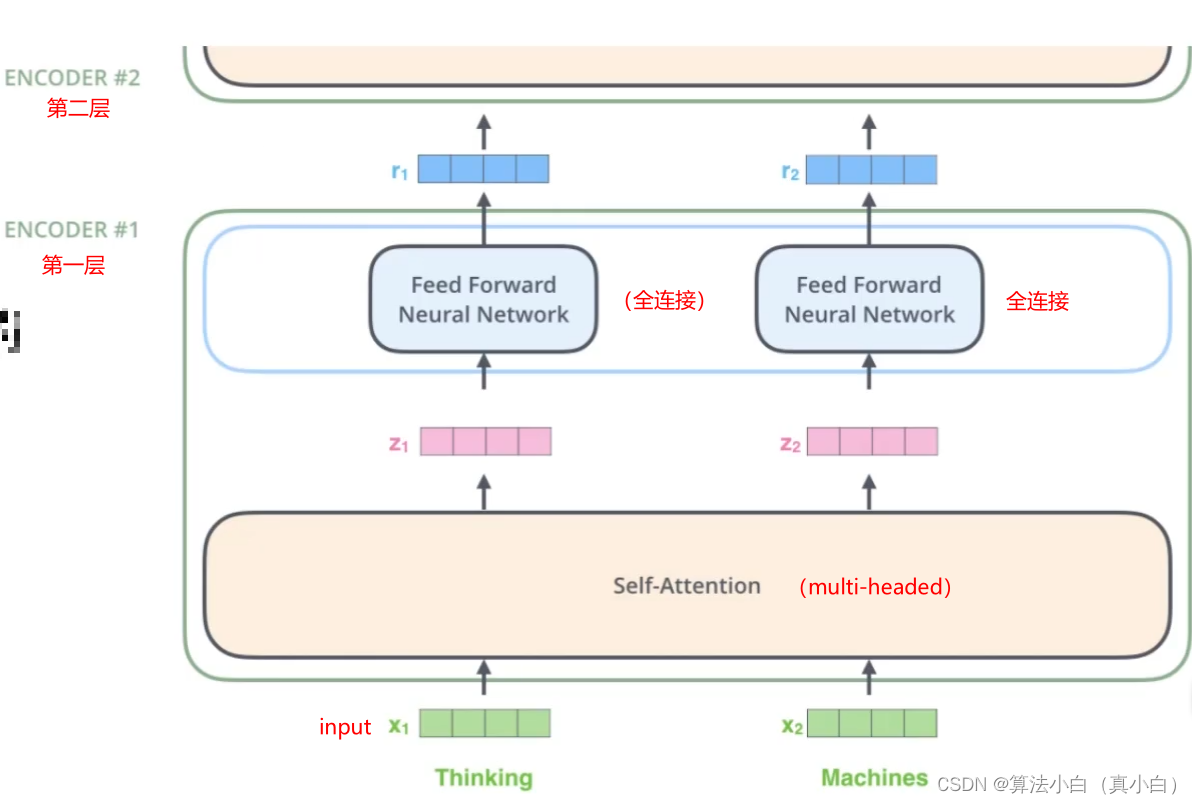
Transformer系列专题(二)——multi-headed多头注意力机制
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、什么是multi-headed(多头注意力机制)二、multi-headed三、multi-headed结果四、堆叠多层总结 前言
在实践中,当给定相同…

四川古力科技抖音小店,创新科技点亮购物新体验
在这个数字化浪潮汹涌的时代,四川古力科技以其前瞻性的战略眼光和创新能力,闪耀于抖音小店这片电商新蓝海,开启了未来购物的新纪元。作为一家集技术研发、产品创新、市场营销于一体的科技型企业,古力科技不仅为消费者带来了前所未…
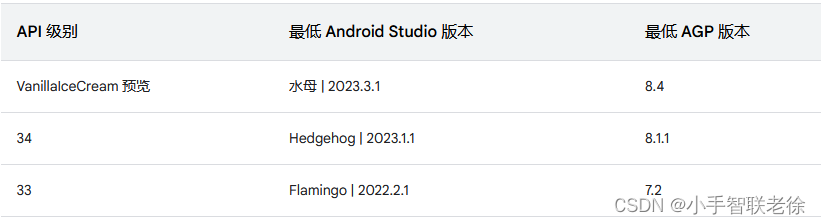
Android Studio 与 Gradle 及插件版本兼容性
Android Studio 开始新项目时,会自动创建其中部分文件,并为其填充合理的默认值。
项目文件结构布局: 一、Android Gradle 及插件作用:
Android Studio 构建系统以 Gradle 为基础,并且 Android Gradle 插件 (AGP) 添加…

游戏行业 2024 Q1报告 | 国内同比上升7.6%,海外收入同比环比双增长,码住!
作为中国音像与数字出版协会主管的中国游戏产业研究院的战略合作伙伴,伽马数据发布了《2024年1—3月中国游戏产业季度报告》。 数据显示, 2024年1—3月,中国游戏市场实际销售收入726.38亿元,同比增长7.60%,主要受移动游…

WXML模板语法-数据绑定
1.数据绑定的基本原则
(1)在data中定义数据
(2)在WXML中使用数据 2.在data页面中定义数据:在页面对应的.js文件中,把数据定义在data对象中即可 (这里打错了 应该是数组类型的数据... 报意思啊) 3.Mustache语法的格式
把data中的…

Element Plus/vue3 无限级导航实现
在使用element plus 时,最初要使用的就是导航组件了,官网上看到的也就是写死的一级/二级导航,那么如何设计一个无限级且动态的导航呢?毋庸置疑,递归。废话不多说,直接看代码和效果: 代码&#x…