你好 GPT-4o!
OpenAI公司宣布推出 GPT-4o,这是OpenAI的新旗舰模型,可以实时对音频、视觉和文本进行推理。

GPT-4o(“o”代表“omni”)是迈向更自然的人机交互的一步——它接受文本、音频、图像和视频的任意组合作为输入,并生成文本、音频和图像的任意组合输出。它可以在短至 232 毫秒的时间内响应音频输入,平均为 320 毫秒,与人类的响应时间相似(在新窗口中打开)在一次谈话中。它在英语文本和代码上的性能与 GPT-4 Turbo 的性能相匹配,在非英语文本上的性能显着提高,同时 API 的速度也更快,成本降低了 50%。与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。
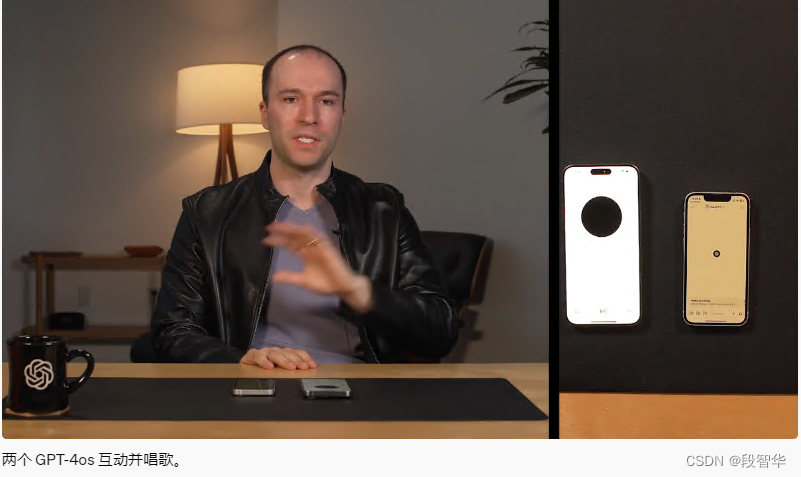
在 GPT-4o 之前,您可以使用语音模式与 ChatGPT 对话,平均延迟为 2.8 秒 (GPT-3.5) 和 5.4 秒 (GPT-4)。为了实现这一目标,语音模式是由三个独立模型组成的管道:一个简单模型将音频转录为文本,GPT-3.5 或 GPT-4 接收文本并输出文本,第三个简单模型将该文本转换回音频。这个过程意味着主要智能来源GPT-4丢失了大量信息——它无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
借助 GPT-4o,OpenAI跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一神经网络处理。由于 GPT-4o 是OpenAI第一个结合所有这些模式的模型,因此OpenAI仍然只是浅尝辄止地探索该模型的功能及其局限性。
能力探索
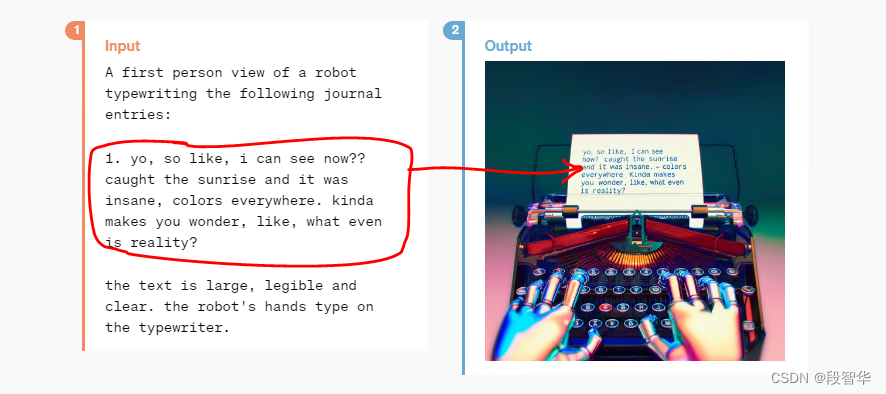
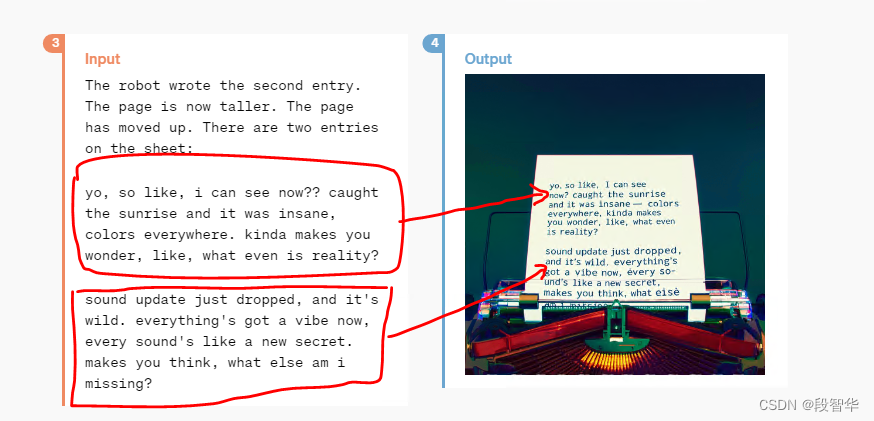

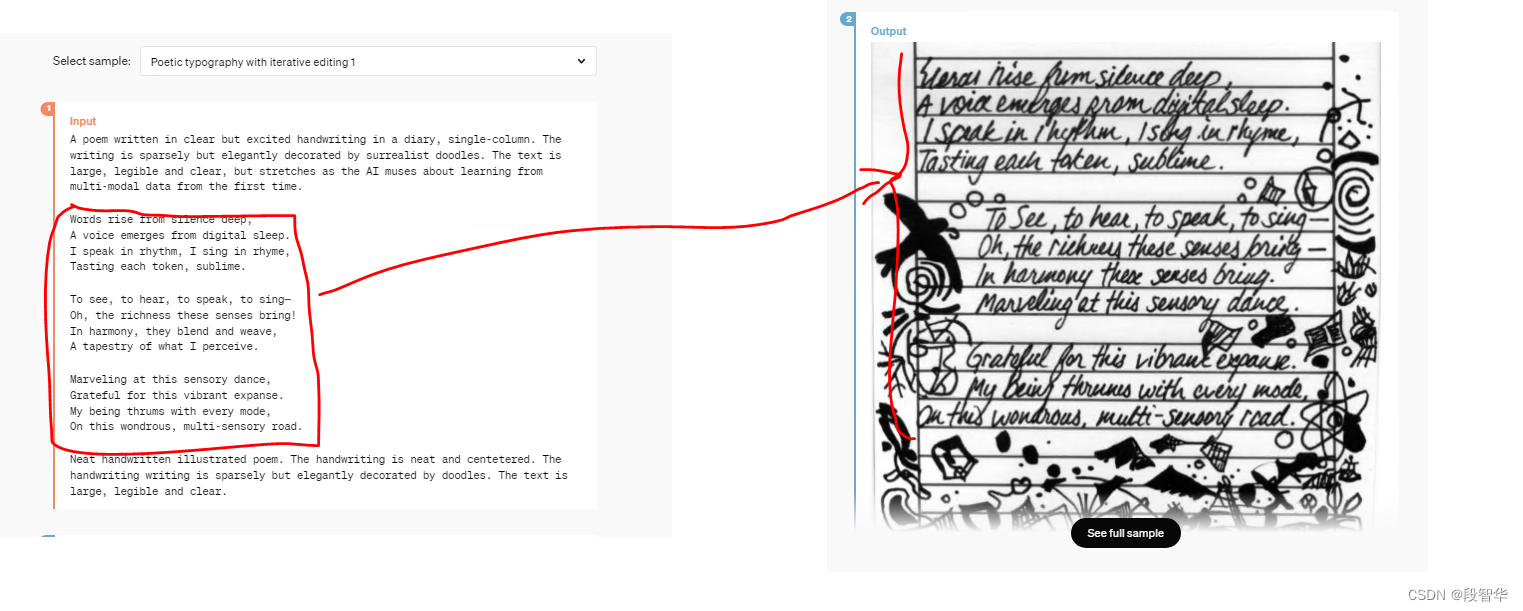
中文翻译的内容

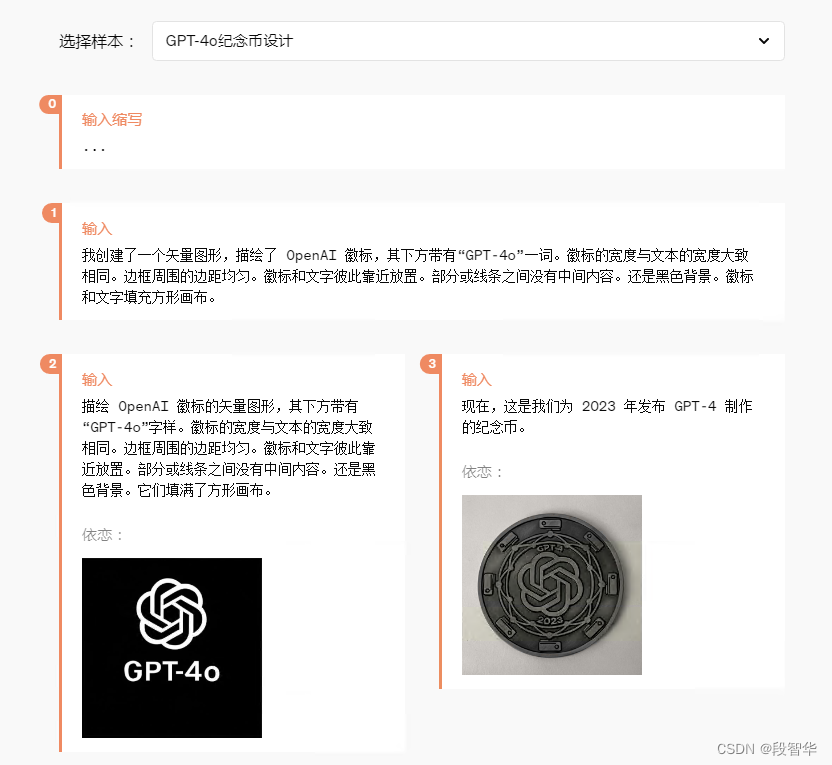

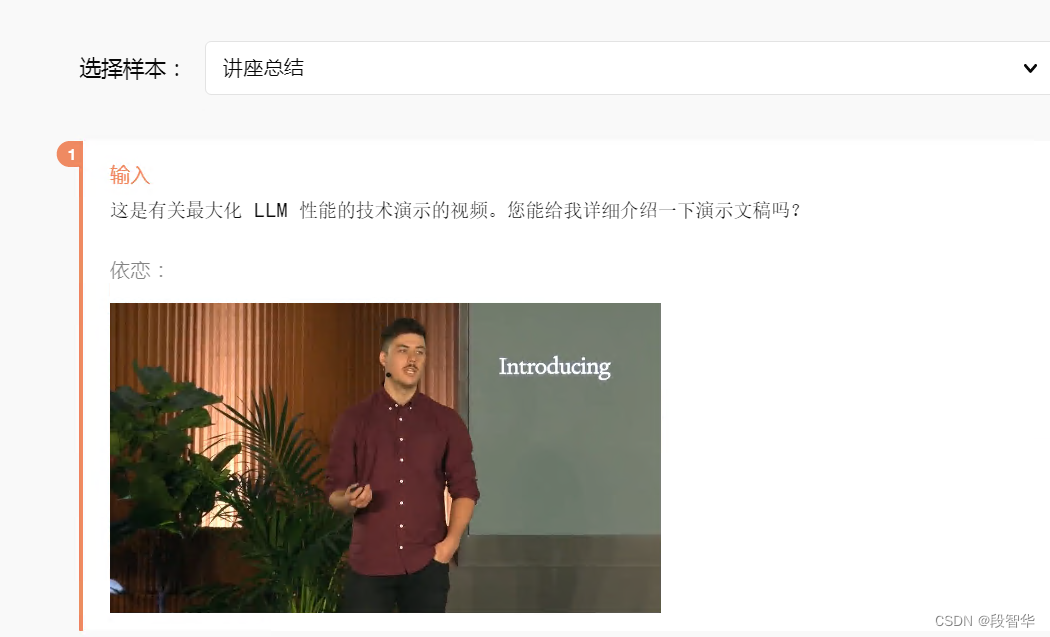
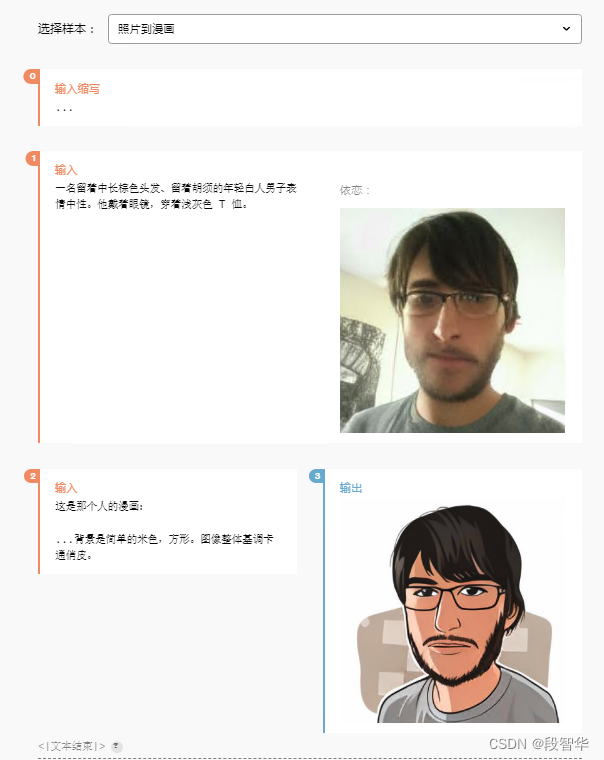
输出
当然!该演讲的重点是最大化大型语言模型 (LLM) 性能的技术,由 OpenAI 的 Colin Jarvis 和 John Allard 发表。该会议是 OpenAI 首届开发者大会的一部分,旨在提供针对特定任务优化法学硕士的见解。
介绍
Colin Jarvis是 OpenAI 欧洲解决方案实践的负责人,**John Allard** 是微调产品团队的工程主管。
该演讲强调了优化法学硕士的挑战,强调不存在一刀切的解决方案。
优化法学硕士的挑战
**从噪声中分离信号**:确定确切的问题非常具有挑战性。
**抽象性能指标**:测量性能可能很困难。
**选择正确的优化**:很难知道要使用哪种方法。
优化流程
演讲者介绍了一个基于两个轴优化法学硕士的框架:
**上下文优化**:模型需要知道什么。
**LLM 优化**:模型需要如何运作。
该框架包括四个象限:
**即时工程**:优化的起点。
**检索增强生成(RAG)**:用于上下文优化。
**微调**:用于 LLM 优化。
**以上所有**:结合所有技术。
及时工程
策略:
写下清晰的说明。
将复杂的任务拆分为更简单的子任务。
给模型时间思考。
系统地测试变更。
适合:
尽早测试和学习。
设定基线。
不适合:
介绍新信息。
复制复杂的风格。
最大限度地减少代币使用。
检索增强生成 (RAG)
概述:
RAG 涉及检索相关文档并使用它们生成响应。
适合:
介绍新信息。
减少幻觉。
不适合:
嵌入广泛的领域知识。
教授新的格式或风格。
最大限度地减少代币使用。
成功的故事:
演示者分享了一个成功案例,他们使用 RAG 将准确率从 45% 提高到 98%。
微调
概述:
微调涉及在较小的特定领域数据集上继续训练过程。
好处:
提高特定任务的性能。
提高效率。
适合:
强调现有知识。
定制结构或语气。
教授复杂的指令。
不适合:
增加新知识。
快速迭代。
成功的故事:
演示者分享了 Canva 的成功故事,其中微调显着提高了性能。
最佳实践
**从快速工程和少量学习开始**。
**建立基线**。
**从小事做起,注重质量**。
结合微调和 RAG
演讲者强调了将微调和 RAG 相结合以获得最佳性能的好处。
理论应用
演讲者将该理论应用于实际挑战,即 Spider 1.0 基准测试,使用 RAG 和微调实现了高精度。
结论
演讲最后总结了优化流程,并强调了使用所讨论的技术迭代提高 LLM 性能的重要性。
问答
演讲者邀请观众提问并进行进一步讨论。
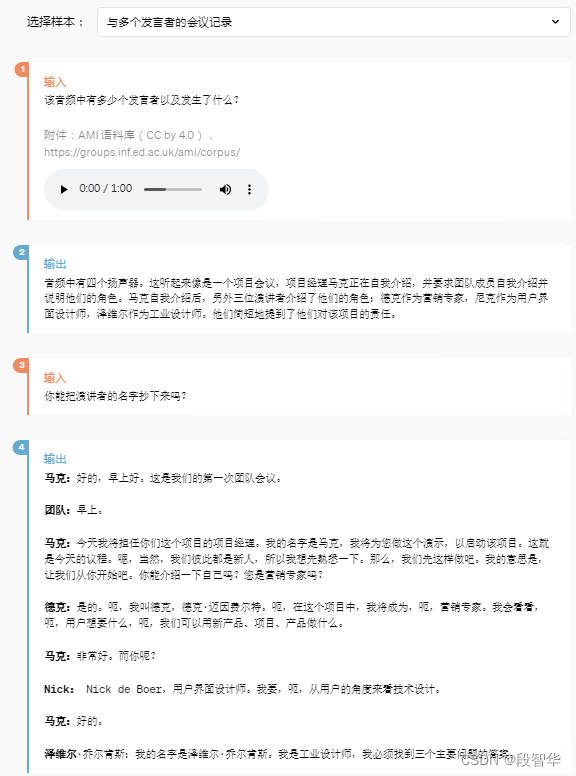
模型评估
根据传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上设置了新的高水位线。
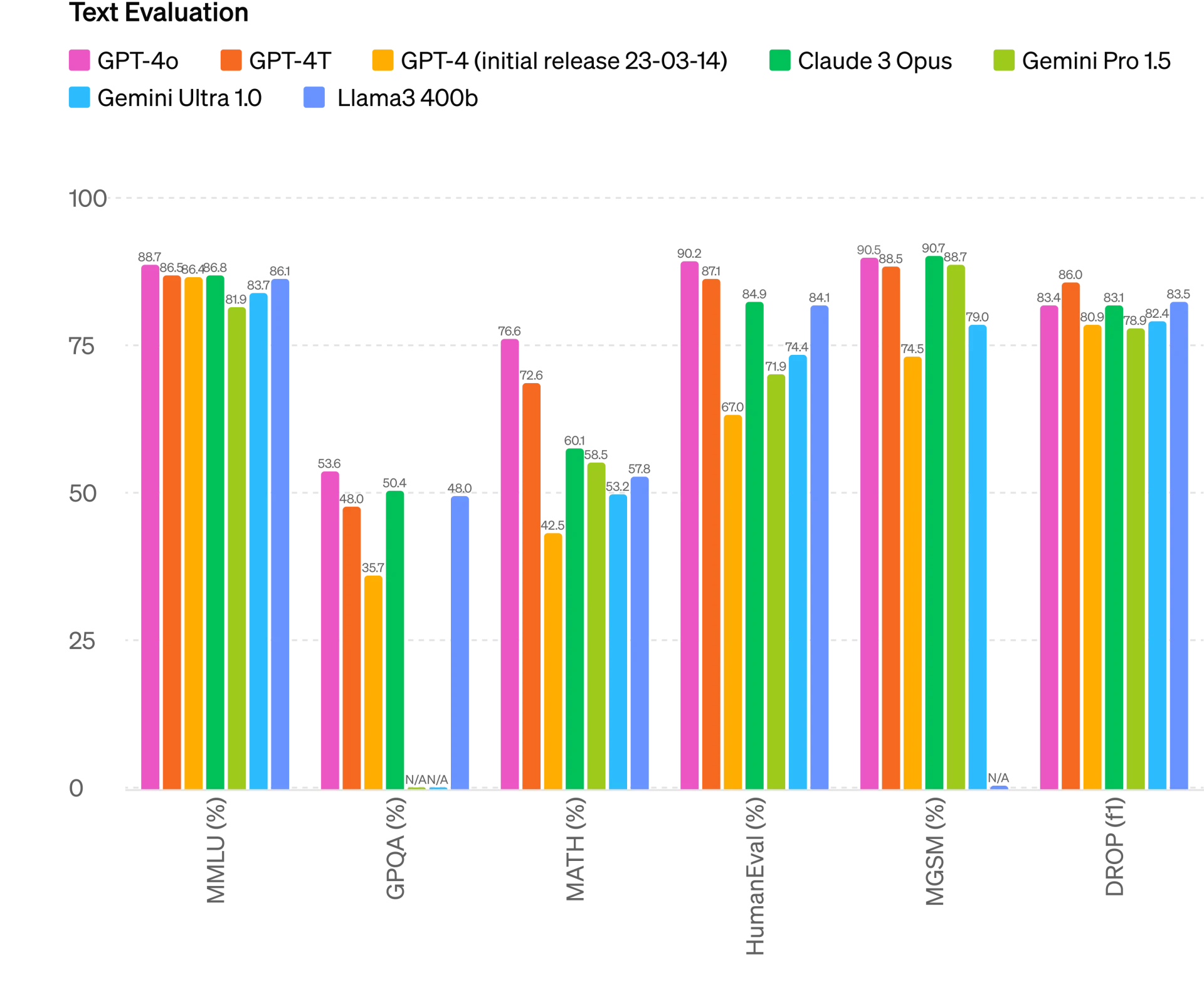
改进推理
GPT-4o 在 0-shot COT MMLU(常识问题)上创下了 88.7% 的新高分。所有这些评估都是通过 新的简单评估收集的(在新窗口中打开)图书馆。此外,在传统的5-shot no-CoT MMLU上,GPT-4o创下了87.2%的新高分。 (注:Llama3 400b(在新窗口中打开)还在训练中)
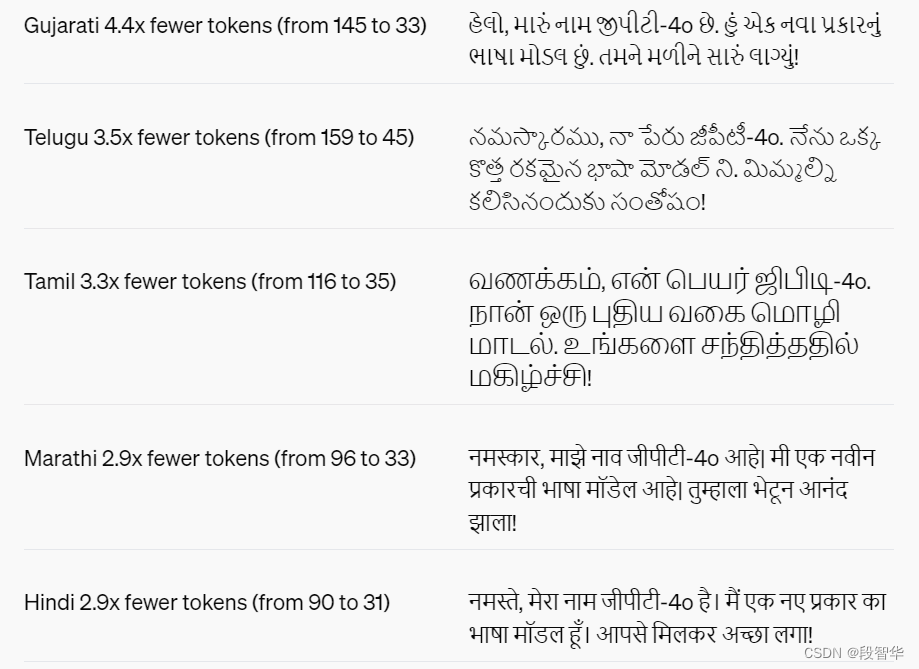
语言标记化
这 20 种语言被选为新分词器跨不同语系压缩的代表



模型安全与局限性
GPT-4o在设计时就通过跨模态的技术手段内置了安全性,例如通过过滤训练数据和通过后训练来完善模型的行为。OpenAI还创建了新的安全系统,以在语音输出上提供防护措施。
OpenAI根据OpenAI的准备框架评估了GPT-4o,并与OpenAI的自愿承诺保持一致。OpenAI对网络安全、化学、生物、放射性和核(CBRN)、说服以及模型自主性的评估表明,GPT-4o在这些类别中的任何一项都没有超过中等风险。这项评估涉及在模型训练过程中运行一系列自动化和人工评估。OpenAI测试了安全缓解前后的模型版本,使用自定义的微调和提示,以更好地引出模型的能力。
GPT-4o还经历了广泛的外部红队测试,超过70名外部专家参与了社会心理学、偏见与公平、以及错误信息等领域的测试,以识别由新增加的模态引入或放大的风险。OpenAI利用这些学习成果来构建OpenAI的安全干预措施,以提高与GPT-4o交互的安全性。OpenAI将继续在发现新风险时减轻它们。
OpenAI认识到GPT-4o的音频模态带来了多种新的风险。今天,OpenAI公开发布了文本和图像输入以及文本输出。在接下来的几周和几个月里,OpenAI将致力于技术基础设施、通过后训练的可用性以及发布其他模态所需的安全性。例如,在启动时,音频输出将限制为一组预设的声音,并将遵守OpenAI现有的安全政策。OpenAI将在即将发布的系统卡中分享更多细节,以解决GPT-4o模态的全范围。
通过OpenAI对模型的测试和迭代,OpenAI观察到所有模型模态中都存在几个局限性,其中一些如下所示。

OpenAI非常希望收到反馈,以帮助OpenAI识别。GPT-4 Turbo仍然优于GPT-4o的任务,这样OpenAI就可以继续改进模型。
模型可用性
GPT-4o是OpenAI在推动深度学习边界方面的最新步骤,这一次是在实用性方面。在过去的两年里,OpenAI投入了大量的努力,在堆栈的每个层面上进行效率改进。作为这项研究的首个成果,OpenAI能够使GPT-4级别的模型更加广泛地可用。GPT-4o的能力将逐步推出(今天开始提供扩展的红队访问权限)。
GPT-4o的文本和图像能力今天开始在ChatGPT中推出。OpenAI正在免费层级中提供GPT-4o,并为Plus用户提供高达5倍的消息限制。在未来几周内,OpenAI将在ChatGPT Plus中推出带有GPT-4o的语音模式的新版本。
开发者现在也可以在API中以文本和视觉模型的形式访问GPT-4o。与GPT-4 Turbo相比,GPT-4o的速度提高了2倍,价格降低了一半,速率限制提高了5倍。OpenAI计划在未来几周内向API中的一小部分信任合作伙伴推出对GPT-4o新音频和视频能力的支持。
GPT-4o贡献者
Pre-training leads
Aidan Clark, Alex Paino, Jacob Menick
Post-training leads
Liam Fedus, Luke Metz
Architecture leads
Clemens Winter, Lia Guy
Optimization leads
Sam Schoenholz, Daniel Levy
Long-context lead
Nitish Keskar
Pre-training Data leads
Alex Carney, Alex Paino, Ian Sohl, Qiming Yuan
Tokenizer lead
Reimar Leike
Human data leads
Arka Dhar, Brydon Eastman, Mia Glaese
Eval lead
Ben Sokolowsky
Data flywheel lead
Andrew Kondrich
Inference leads
Felipe Petroski Such, Henrique Ponde de Oliveira Pinto
Inference Productionzation lead
Henrique Ponde de Oliveira Pinto
Post-training infrastructure leads
Jiayi Weng, Randall Lin, Youlong Cheng
Pre-training organization lead
Nick Ryder
Pre-training program lead
Lauren Itow
Post-training organization leads
Barret Zoph, John Schulman
Post-training program lead
Mianna Chen
Core contributors
Adam Lerer, Adam P. Goucher, Adam Perelman, Akila Welihinda, Alec Radford, Alex Borzunov, Alex Carney, Alex Chow, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexi Christakis, Ali Kamali, Allison Moyer, Allison Tam, Amin Tootoonchian, Ananya Kumar, Andrej Karpathy, Andrey Mishchenko, Andrew Cann, Andrew Kondrich, Andrew Tulloch, Angela Jiang, Antoine Pelisse, Anuj Gosalia, Avi Nayak, Avital Oliver, Behrooz Ghorbani, Ben Leimberger, Ben Wang, Blake Samic, Brian Guarraci, Brydon Eastman, Camillo Lugaresi, Chak Li, Charlotte Barette, Chelsea Voss, Chong Zhang, Chris Beaumont, Chris Hallacy, Chris Koch, Christian Gibson, Christopher Hesse, Colin Wei, Daniel Kappler, Daniel Levin, Daniel Levy, David Farhi, David Mely, David Sasaki, Dimitris Tsipras, Doug Li, Duc Phong Nguyen, Duncan Findlay, Edmund Wong, Ehsan Asdar, Elizabeth Proehl, Elizabeth Yang, Eric Peterson, Eric Sigler, Eugene Brevdo, Farzad Khorasani, Francis Zhang, Gene Oden, Geoff Salmon, Hadi Salman, Haiming Bao, Heather Schmidt, Hongyu Ren, Hyung Won Chung, Ian Kivlichan, Ian O'Connell, Ian Osband, Ilya Kostrikov, Ingmar Kanitscheider, Jacob Coxon, James Crooks, James Lennon, Jason Teplitz, Jason Wei, Jason Wolfe, Jay Chen, Jeff Harris, Jiayi Weng, Jie Tang, Joanne Jang, Jonathan Ward, Jonathan McKay, Jong Wook Kim, Josh Gross, Josh Kaplan, Joy Jiao, Joyce Lee, Juntang Zhang, Kai Fricke, Kavin Karthik, Kenny Hsu, Kiel Howe, Kyle Luther, Larry Kai, Lauren Itow, Leo Chen, Lia Guy, Lien Mamitsuka, Lilian Weng, Long Ouyang, Louis Feuvrier, Lukas Kondraciuk, Lukasz Kaiser, Lyric Doshi, Mada Aflak, Maddie Simens, Madeleine Thompson, Marat Dukhan, Marvin Zhang, Mateusz Litwin, Max Johnson, Mayank Gupta, Mia Glaese, Michael Janner, Michael Petrov, Michael Wu, Michelle Fradin, Michelle Pokrass, Miguel Oom Temudo de Castro, Mikhail Pavlov, Minal Khan, Mo Bavarian, Natalia Gimelshein, Natalie Staudacher, Nick Stathas, Nik Tezak, Nithanth Kudige, Noel Bundick, Ofir Nachum, Oleg Boiko, Oleg Murk, Olivier Godement, Owen Campbell-Moore, Philip Pronin, Philippe Tillet, Rachel Lim, Rajan Troll, Randall Lin, Rapha gontijo lopes, Raul Puri, Reah Miyara, Reimar Leike, Renaud Gaubert, Reza Zamani, Rob Honsby, Rohit Ramchandani, Rory Carmichael, Ruslan Nigmatullin, Ryan Cheu, Scott Gray, Sean Grove, Sean Metzger, Shantanu Jain, Shengjia Zhao, Sherwin Wu, Shuaiqi (Tony) Xia, Sonia Phene, Spencer Papay, Steve Coffey, Steve Lee, Steve Lee, Stewart Hall, Suchir Balaji, Tal Broda, Tal Stramer, Tarun Gogineni, Ted Sanders, Thomas Cunninghman, Thomas Dimson, Thomas Raoux, Tianhao Zheng, Tina Kim, Todd Underwood, Tristan Heywood, Valerie Qi, Vinnie Monaco, Vlad Fomenko, Weiyi Zheng, Wenda Zhou, Wojciech Zaremba, Yash Patil, Yilei, Qian, Yongjik Kim, Youlong Cheng, Yuchen He, Yuchen Zhang, Yujia Jin, Yunxing Dai, Yury Malkov
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。