| 实验名称 | 二元文法模型 | |||||||
1.掌握N-gram文法的公式; 2.理解语言模型的实现过程; 3.掌握简单的平滑方法; 4.用代码编程实现2元语言模型,即一阶马尔可夫链。
使用免费的中文分词语料库,如人民日报语料库PKU,使用语料库中的常见词编写一个句子,使用二元语法(即每个词只与和它相邻的前一个词有关)在语料库中对句子中的词进行词频统计,输出句子的出现概率。
统计语料库中每个词出现的次数并且得到相邻两个词语同时出现的的次数,便于概率的求解。因为是对数据进行分析,所以用python来写比较便捷。先定义两个字典,一个存储词出现的次数,另一个存储相连两个词出现的次数。读取文件中的语料集,为了保证条件概率在i=1时有意义,同时为了保证句子内所有字符串的概率为1,所以通过for循环将每一句话前加上标记‘BOS’,后加上标记‘EOS’。 读取语料进行每个词出现次数的查找,同时得到两个词语相连出现的次数,存储名称样式为{}-{},{}表示一个词语。将每个词及其出现次数存储到字典tmp_dic_single中,两个词的存到字典tmp_dic中,为了检测正确性且方便查看,将这两个字典存储到两个文件中。
每一个概率表达式中的分子表示一个词语和另一个词语相连出现在语料库的数,分母为该词在整个语料库单独出现的次数,这就存在概率为0的情况,所以要使用平滑方法,这里用到了拉普拉斯平滑方法: 总结来说就是对词的计数加1,由于词典大小为 V ,每个词的次数都增加了1,因此还需要为分母加 V。
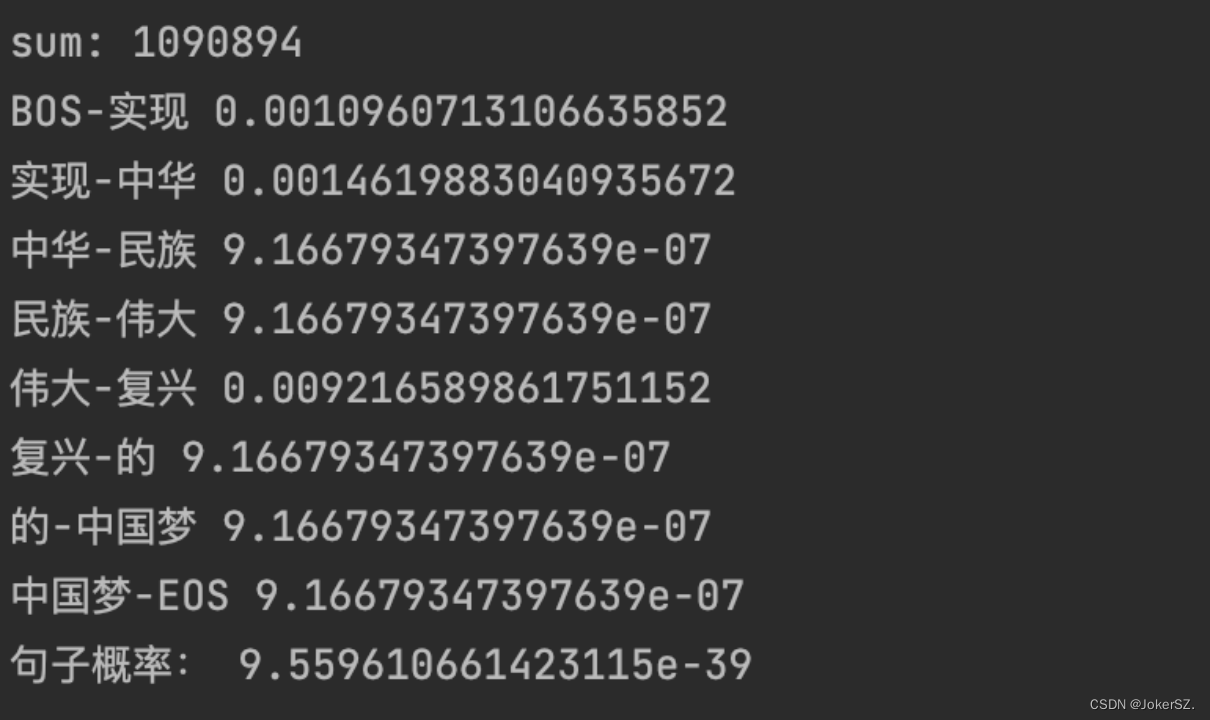
用句子“实现中华民族伟大复兴的中国梦”来进行检测: 得到的词分别为'BOS 实现 中华 民族 伟大 复兴 的 中国梦 EOS'。 运行结果如下(sum表示语料库中词数):
生成的词语出现的词数的文件部分内容如下:
参与本次二元文法语言模型实验,显著加深了对N-gram模型,特别是二元文法模型的理解。通过编程实践,掌握了对语料库进行数据分析并实现2-gram模型的技能。 实验中,深刻体会到数据平滑技术的重要性,该技术是确保概率计算不出现零值的关键,且有多种实施方法。分析生成的字典和文件,认识到2-gram模型样本空间为N^2,效果显著优于一元模型。这激发了对N-gram模型中N值与训练效果关系的进一步思考,将继续深入学习,巩固自然语言处理知识基础。 完成概率计算。同时,认识到在语言处理中实施数据平滑的必要性,有效解决了数据稀疏和零概率问题。计划通过持续学习,不断优化程序,提升其效率和完整性。 | ||||||||

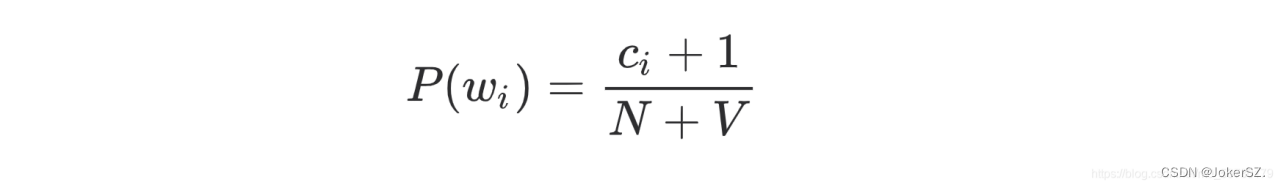

参考代码:
tmp_dic = {}
tmp_dic_single = {}
with open(r'/Users/songziang/Documents/pythonProject/pku_training.txt',encoding='GB18030') as f:
count = 0
current = 'BOS'
for line in f:
tmp = line.split()
if count == 0:
tmp.insert(0, 'BOS')
for index in range(len(tmp)-1, -1, -1):
if tmp[index] in set(['、', '——', ':', '。', '!', '“', '”', '?', '《', '》', '(', ')', '’', ':', ',']):
tmp[index] = 'EOS'
tmp.insert(index+1, 'BOS')
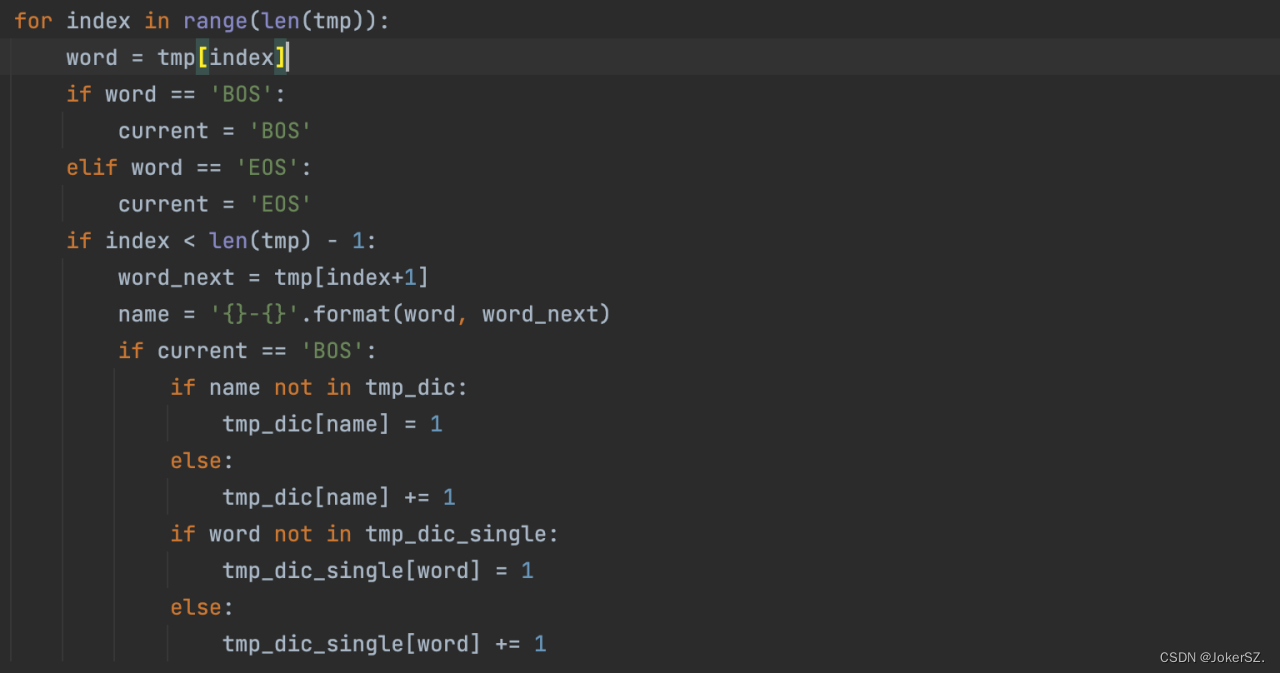
for index in range(len(tmp)):
word = tmp[index]
if word == 'BOS':
current = 'BOS'
elif word == 'EOS':
current = 'EOS'
if index < len(tmp) - 1:
word_next = tmp[index+1]
name = '{}-{}'.format(word, word_next)
if current == 'BOS':
if name not in tmp_dic:
tmp_dic[name] = 1
else:
tmp_dic[name] += 1
if word not in tmp_dic_single:
tmp_dic_single[word] = 1
else:
tmp_dic_single[word] += 1
count += 1
print('sum:', sum(tmp_dic.values()))
with open(r'/Users/songziang/Documents/pythonProject/training_double.txt', 'w',encoding='GB18030') as f:
f.write(str(tmp_dic))
with open(r'/Users/songziang/Documents/pythonProject/training_single.txt', 'w',encoding='GB18030') as f:
f.write(str(tmp_dic_single))
sentence = 'BOS 实现 中华 民族 伟大 复兴 的 中国梦 EOS'
sentence = sentence.split()
probability = 1
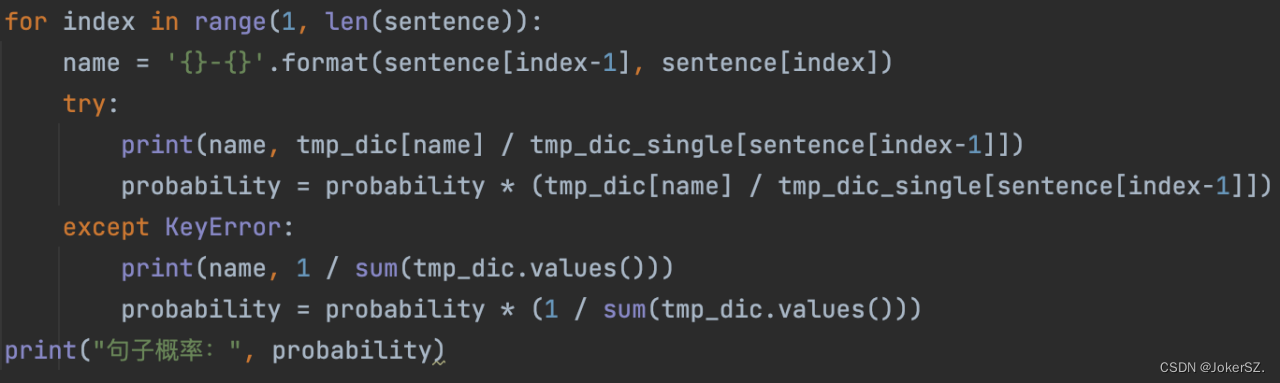
for index in range(1, len(sentence)):
name = '{}-{}'.format(sentence[index-1], sentence[index])
try:
print(name, tmp_dic[name] / tmp_dic_single[sentence[index-1]])
probability = probability * (tmp_dic[name] / tmp_dic_single[sentence[index-1]])
except KeyError:
print(name, 1 / sum(tmp_dic.values()))
probability = probability * (1 / sum(tmp_dic.values()))
print("句子概率:", probability)





![[牛客网]——C语言刷题day3](https://img-blog.csdnimg.cn/direct/9c77aa01fd304b11a0e1020f76cdc9b2.png)