笔记
- 什么是nerf
- 一些值得注意的理论点
什么是nerf
Nerf 是可以理解成是一种隐式的3D表达方式。 隐式表达可以理解成是用一个条件或者方程来表示一个3D几何,没有实实在在的几何形状。相反,显式表达就诸如mesh, 点云,体素这类的,能够实实在在看到的。Nerf的网络结构非常简单,也就是一个mlp。Nerf主要的目的,就是从给到的大量照片中学习,从而可以渲染任意视角下的RGB图像。它的输入数据是(x,y,z, ϕ \phi ϕ, θ \theta θ), ϕ \phi ϕ, θ \theta θ可以理解成相机位姿,分别代表的是当前相机对世界坐标系的旋转和平移。(x,y,z)表示的是跟着从当前视角发出的光线经常采样得到的离散的点。因为不知道3D物体的边界在哪里,所以要在3D空间种进行离散采样。 它的应用, 包括新视点合成,输入稀疏的视点输出连续的RGB信息,360重建,大场景重建,人体重建,3D 风格迁移。镜面反射场景重建。(镜子和透明场景是很难用传统的方式重建的。)
Nerf的一些问题:
- 需要足够多的图像
- 光照条件要一致,不能差距太大。
- 没有泛化能力。
- 渲染速度慢
- 对输入图像要求很高,不能模糊或者有畸变
- 位姿必须要准
一些值得注意的理论点
Nerf输出的东西是density和RGB颜色。所谓的density就是表示了有没有光线或者有多少光线和3D边界相交了,可以理解成density表示了nerf学到的3D信息,所以一些学术论文会称nerf学到3Dshape为soft shape。Nerf 的步骤可以分成以下几步
- 层级采样 hierarchical sampling
- 位置编码 positional encoding
- MLP 学习
- volume rendering
首先为什么是层级采样。这个就是一个coarse-to-fine的过程,也通常是3D任务当中很常见的处理方式。因为Nerf如果使用大量的均匀采样点,第一会导致计算资源不够,第二呢就是也许有很多点都没有意义,因为离3D物体的边界很远。所以先使用稀疏采样,然后计算光到这个点的不透明度来作为权重,来判断这个点离物体边界远不远。这个很好理解,就是如果一个点离目标边界很远的话,光穿过它,不透明度是没有影响的。选择权重最大的那个点,在它周围进行稠密采样,这样采到的点,就大部分是在目标周围的了。

就这样直接让MLP学习的话,他是学习不到一些高频信息的。也就是说学习不到细节,输出的结果都是只有大致的形状,细节都很模糊。通过这样一个位置编码,它可以将这样低纬度的信息映射到更高纬度上去,从而使用高频函数将颜色和几何形状映射到高维空间拟合包含高频变化的数据。这个就是为什么要使用位置编码的原因。
MLP学习的过程是很简单,但是这里的本质其实是在过拟合这个MLP。让训练的这个MLP完全记住输入中的所有信息。当给到任意视角,就相当于在查询 MLP拟合的参数中表达的信息。所以这也是为什么最早的nerf是没有泛化性可言的原因。
最后volume rendering 目的就是将输出的每一个离散点的density和颜色做一个积分得到当前 ray的颜色,然后对每一条ray都这么做,就可以得到图像了。
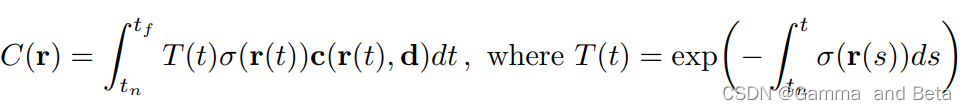
nerf的损失函数也就是两个L2 loss 相加。
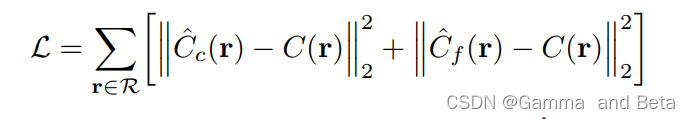
表达的是coarse 和 fine 两个阶段的渲染图像和GT之间的差值。
最后简单记一下metrics
PSNR (Peak signal-to-Noise Ratio) , 信噪比越大,差异就越小。
SSIM(structural similarity index) 越大差异越小 。
LPIPS (learned Perceptual image patch similarity)