大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
通过前面的文章,我们一起剖析了Guava Cache、Caffeine、Ehcache等本地缓存框架的原理与使用场景,也一同领略了以Redis为代表的集中式缓存在分布式高并发场景下无可替代的价值。
现在的很多大型高并发系统都是采用的分布式部署方式,而作为高并发系统的基石,缓存是不可或缺的重要环节。项目中使用缓存的目的是为了提升整体的运算处理效率、降低对外的IO请求,而集中式缓存是独立于进程之外部署的远端服务,需要基于网络IO的方式交互。如果一个业务逻辑中涉及到非常频繁的缓存操作,势必会导致引入大量的网络IO交互,造成过大的性能损耗、加剧缓存服务器的压力。另外,对于现在互联网系统的海量用户数据,如何压缩缓存数据占用容量,也是需要面临的一个问题。
本篇文章,我们就一起聊一聊如何来更好的使用缓存,探寻下如何降低缓存交互过程的性能损耗、如何压缩缓存的存储空间占用、如何保证多个操作命令原子性等问题的解决策略,让缓存在项目中可以发挥出更佳的效果。
通过BitMap降低Reids存储容量压力
在一些互联网类的项目中,经常会有一些签到相关功能。如果使用Redis来缓存用户的签到信息,我们一般而言会怎么存储呢?常见的会有下面2种思路:
- 使用Set类型,每天生层1个Set,然后将签到用户添加到对应的Set中;
- 还是使用Set类型,每个用户一个Set,然后将签到的日期添加到Set中。
对于海量用户的系统而言,按照上述的策略,那么每天仅签到信息这一项,就可能会有上千万的记录,一年累积下来的数据量更大 —— 这对Redis的存储而言是笔不小的开销。对于签到这种简单场景,只有签到和没签到两种情况,也即0/1的场景,我们也可以通过BitMap来进行存储以大大降低内存占用。
BitMap(位图)可以理解为一个bit数组,对应bit位可以存放0或者1,最终这个bit数组被转换为一个字符串的形式存储在Redis中。比如签到这个场景,我们可以每天设定一个key,然后存储的时候,我们可以将数字格式的userId表示在BitMap中具体的位置信息,而BitMap中此位置对应的bit值为1则表示该用户已签到。

Redis其实也提供了对BitMap存储的支持。前面我们提过Redis支持String、Set、List、ZSet、Hash等数据结构,而BitMap能力的支持,其实是对String数据结构的一种扩展,使用String数据类型来支持BitMap的能力实现。比如下面的代码逻辑:
public void userSignIn(long userId) {
String today = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd"));
String redisKey = "UserSginIn_" + today;
Boolean hasSigned = stringRedisTemplate.opsForValue().getBit(redisKey, userId);
if (Boolean.TRUE.equals(hasSigned)) {
System.out.println("今日已签过到!");
} else {
stringRedisTemplate.opsForValue().setBit("TodayUserSign", userId, true);
System.out.println("签到成功!");
}
}
对于Redis而言,每天就只有一条key-value数据。下面对比下使用BitMap与使用普通key-value模式的数据占用情况对比。模拟构造10亿用户数据量进行压测统计,结果如下:
- BitMap格式: 150M
- key-value格式: 41G
可以看出,在存储容量占用方面,BitMap完胜。

关于pipeline管道批处理与multi事务原子性
使用Pipeline降低与Reids的IO交互频率
在很多的业务场景中,我们可能会涉及到同时去执行好多条redis命令的操作,比如系统启动的时候需要将DB中存量的数据全部加载到Redis中重建缓存的时候。如果业务流程需要频繁的与Redis交互并提交命令,可能会导致在网络IO交互层面消耗太大,导致整体的性能降低。
这种情况下,可以使用pipeline将各个具体的请求分批次提交到Redis服务器进行处理。
private void redisPipelineInsert() {
stringRedisTemplate.executePipelined(new SessionCallback() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
try {
// 具体的redis操作,多条操作都在此处理,最后会一起提交到Redis远端去执行
} catch (Exception e) {
log.error("failed to execute pipelined...", e);
}
return null;
}
});
}
使用pipeline的方式,可以减少客户端与redis服务端之间的网络交互频次,但是pipeline也只是负责将原本需要多次网络交互的请求封装一起提交到redis上,在redis层面其执行命令的时候依旧是逐个去执行,并不会保证这一批次的所有请求一定是连贯被执行,其中可能会被插入其余的执行请求。

也就是说,pipeline的操作是不具备原子性的。

使用multi实现请求的事务
前面介绍pipeline的时候强调了其仅仅只是将多个命令打包一起提交给了服务器,然后服务器依旧是等同于逐个提交上来的策略进行处理,无法保证原子性。对于一些需要保证多个操作命令原子性的场景下,可以使用multi来实现。
当客户端请求执行了multi命令之后,也即开启了事务,服务端会将这个客户端记录为一个特殊的状态,之后这个客户端发送到服务器上的命令,都会被临时缓存起来而不会执行。只有当收到此客户端发送exec命令的时候,redis才会将缓存的所有命令一起逐条的执行并且保证这一批命令被按照发送的顺序执行、执行期间不会被其他命令插入打断。

代码示例如下:
private void redisMulti() {
stringRedisTemplate.multi();
stringRedisTemplate.opsForValue().set("key1", "value1");
stringRedisTemplate.opsForValue().set("key2", "value2");
stringRedisTemplate.exec();
}
需要注意的一点是,redis的事务与关系型数据库中的事务是两个不同概念,Redis的事务不支持回滚,只能算是Redis中的一种特殊标记,可以将这个事务范围内的请求以指定的顺序执行,中间不会被插入其余的请求,可以保证多个命令执行的原子性。

pipeline与multi区别
从上面分别对pipeline与multi的介绍,可以看出两者在定位与功能分工上的差异点:
-
pipeline是客户端行为,只是负责将客户端的多个请求一次性打包传递到服务器端,服务端依旧是按照和单条请求一样的处理,批量传递到服务端的请求之间可能会插入别的客户端的请求操作,所以它是无法保证原子性的,侧重点在于其可以提升客户端的效率(降低频繁的网络交互损耗)
-
multi是服务端行为,通过开启事务缓存,保证客户端在事务期间提交的请求可以被一起集中执行。它的侧重点是保证多条请求的原子性,执行期间不会被插入其余客户端的请求,但是由于开启事务以及命令缓存等额外的操作,其对性能略微有一些影响。

多级缓存机制
本地+远端的二级缓存机制
在涉及与集中式缓存之间频繁交互的时候,通过前面介绍的pipeline方式可以适当的降低与服务端之间网络交互的频次,但是很多情况下,依旧会产生大量的网络交互,对于一些追求极致性能的系统而言,可能依旧无法满足诉求。
回想下此前文章中花费大量篇幅介绍的本地缓存,本地缓存在分布式场景下容易造成数据不一致的问题,但是其最大特点就是快,因为数据都存储在进程内。所以可以将本地缓存作为集中式缓存的一个补充策略,对于一些需要高频读取且不会经常变更的数据,缓存到本地进行使用。
常见的本地+远端二级缓存有两种存在形式。
- 独立划分,各司其职
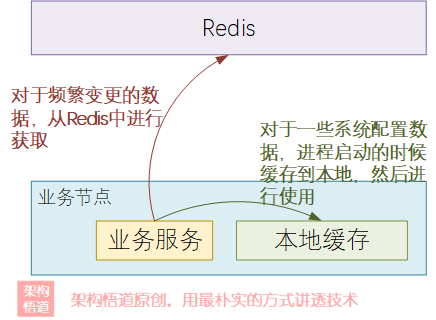
这种情况,将缓存数据分为了2种类型,一种是不常变更的数据,比如系统配置信息等,这种数据直接系统启动的时候从DB中加载并缓存到进程内存中,然后业务运行过程中需要使用时候直接从内存读取。而对于其他可能会经常变更的业务层面的数据,则缓存到Redis中。
- 混合存储,多级缓存
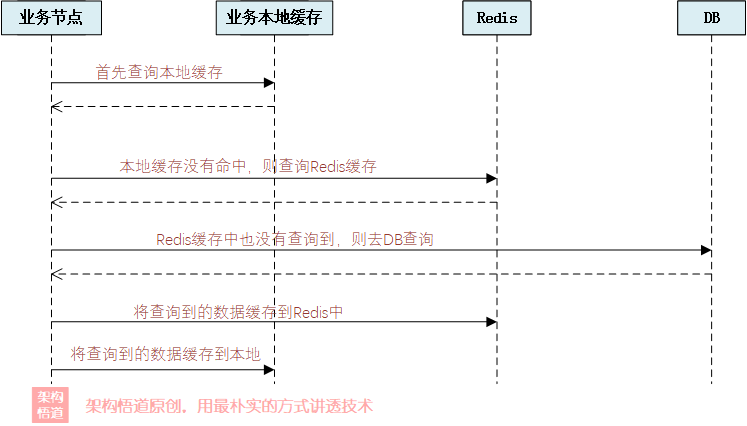
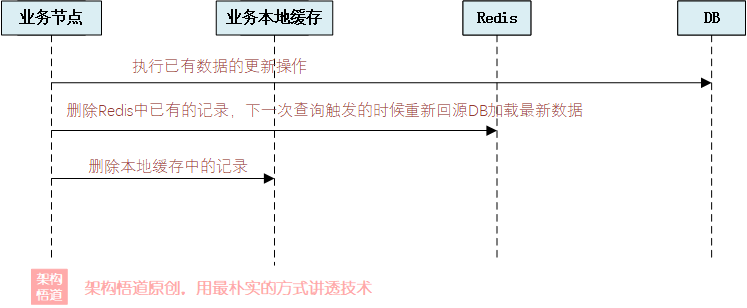
这种情况可以搭配Caffeine或者Ehcache等本地缓存框架一起实现。首先去本地缓存中执行查询,如果查询到则返回,查询不到则去Redis中尝试获取。如果Redis中也获取不到,则可以考虑去DB中进行回源兜底操作,然后将回源的结果存储到Redis以及本地缓存中。这种情况下需要注意下如果数据发生变更的时候,需要删除本地缓存,以确保下一次请求的时候,可以再次去Redis拉取最新的数据。
本地+远端的二级缓存机制有着多方面的优点:
-
主要操作都在本地进行,可以充分的享受到本地缓存的速度优势;
-
大部分操作都在本地进行,充分降低了客户端与远端集中式缓存服务器之间的IO交互,也降低了带宽占用;
-
通过本地缓存层,抵挡了大部分的业务请求,对集中式缓存服务器端进行减压,大大降低服务端的压力;
-
提升了业务的可靠性,本地缓存实际上也是一种额外的副本备份,极端情况下,及时集中式缓存的服务端宕机,因为本地还有缓存数据,所以业务节点依旧可以对外提供正常服务。

二级缓存的应用身影
其实,在C-S架构的系统里面,多级缓存的概念使用的也非常的频繁。经常Clinet端会缓存运行时需要的业务数据,然后采用定期更新或者事件触发的方式从服务端更新本地的数据。而Server端负责存储所有的数据,并保证数据更新的时候可以提供给客户端进行更新获取。
一个典型的例子,就是分布式系统中的配置中心或者是服务注册管理中心。比如SpringCloud家族的Eureka,或者是Alibaba开源的Nacos。它们都有采用客户端本地缓存+服务端数据统一存储的方式,来保证整体的处理效率,降低客户端对于Server端的实时交互依赖。
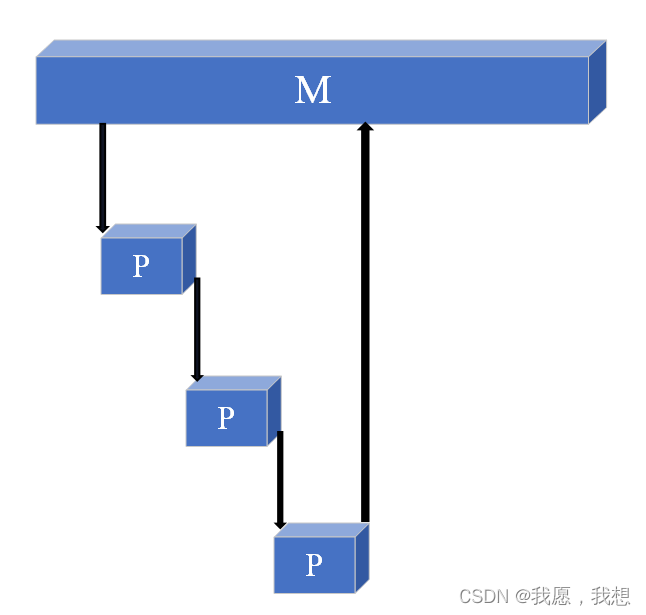
看一下Nacos的交互示意:
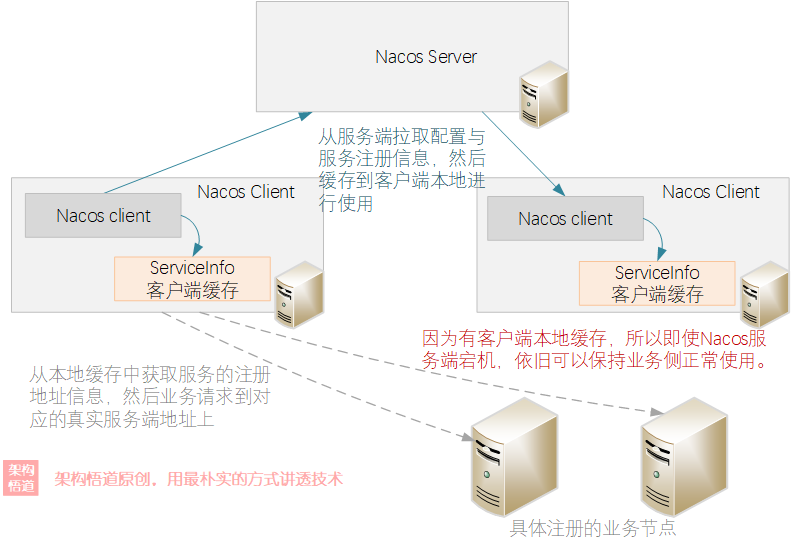
从图中可以表直观的看到,Client将业务数据缓存到各自本地,这样业务逻辑进行处理的时候就可以直接从本地缓存中查询到相关的业务节点映射信息,而Server端只需要负责在数据有变更的事后推送到Client端更新到本地缓存中即可,避免了Server端去承载业务请求的流量压力。整体的可靠性也得到了保证,避免了Server端异常对业务正常处理造成影响。

小结回顾
好啦,到这里呢,《深入理解缓存原理与实战设计》系列专栏的内容就暂告一段落咯。本专栏围绕缓存这个宏大命题进行展开阐述,从缓存各种核心要素、到本地缓存的规范与标准介绍,从手写本地缓存框架、到各种优秀本地缓存框架的上手与剖析,从本地缓存到集中式缓存再到最后的多级缓存的构建,一步步全方位、系统性地做了介绍。希望通过本专栏的介绍,可以让大家对缓存有个更加深刻的理解,可以更好的在项目中去使用缓存,让缓存真正的成为我们项目中性能提升的神兵利器。
看到这里,不知道各位小伙伴们对缓存的理解与使用,是否有了新的认识了呢?你觉得缓存还有哪些好的使用场景呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。

我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。全网同名,欢迎关注,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。