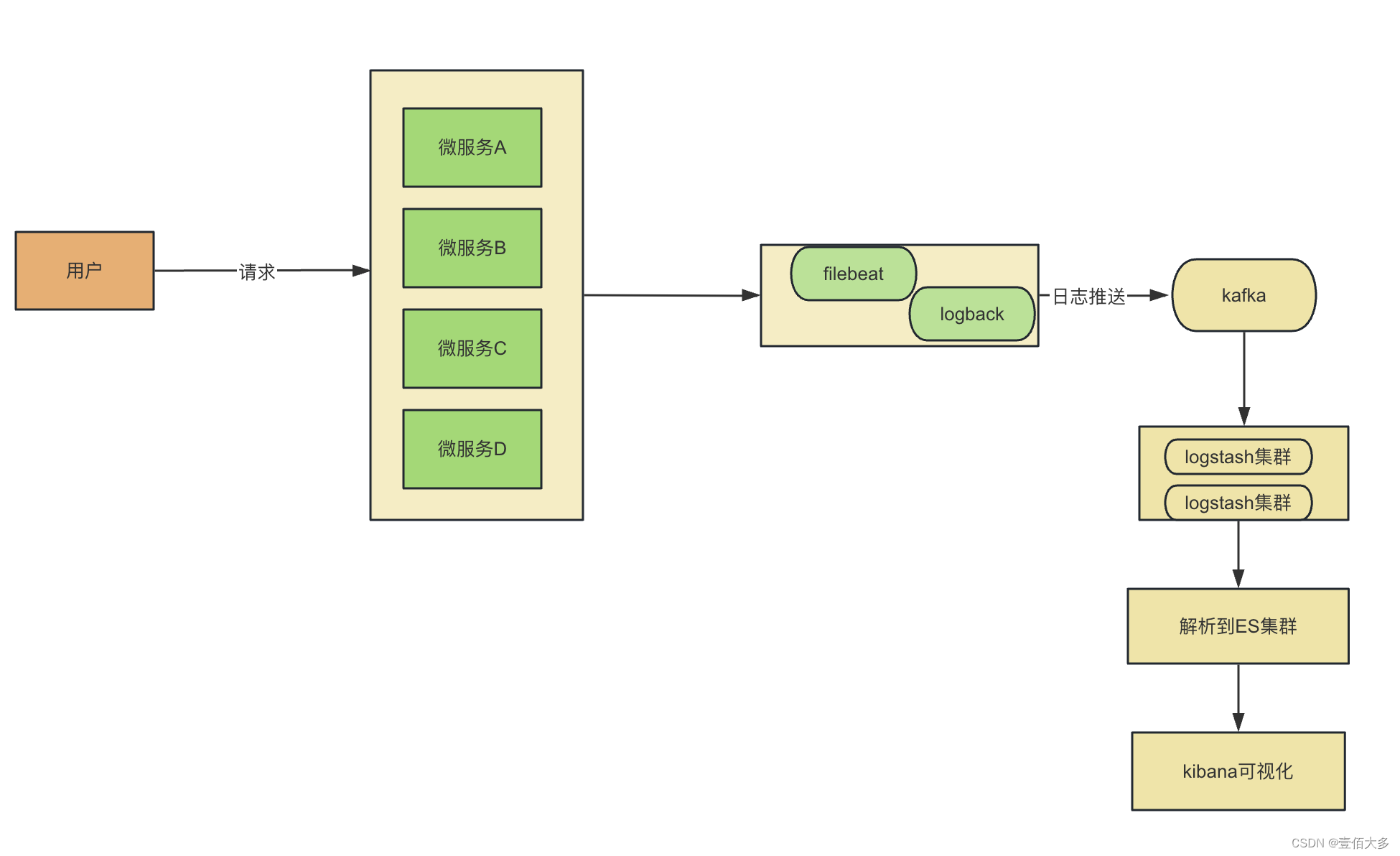
在测试的工作过程中,很多场景是需要构造一些数据在项目里的,方便测试工作的进行,构造的方法有很多,难度和技术深度也不一样。本文提供方法供你选择。
在测试的工作过程中,很多场景是需要构造一些数据在项目里的,方便测试工作的进行。比如下面的场景:
-
项目需要做性能测试,需要大量的数据
-
就算是功能测试,比如测试搜索功能,需要有数据做搜索测试
-
需要检查数据的一致性的检查的时候,也需要项目有大量的数据
-
如果项目有一些统计表和图,需要测试数据统计正确性的时候,也需要构造海量的测试数据;
那么,测试如何快速的构造测试数据呢?
构造的方法有很多,难度和技术深度也不一样,可以根据数量级的不同可以采取不同的方法。
方法一:如果项目要求的数据不多,几十条或者十几条即可,可以手动页面操作构成
这种方法虽然原始,但是简单没有技术门槛,如果是少量的数据,手动操作也不太费时间。不过如果数据的数量级上来了,那么这种方法就不太靠谱了。
方法二:直接调用接口 批量发送接口请求
这种方法会比纯页面添加要快速一些,使用一个接口测试工具,比如Jmeter,postman的CSV的方法,批量读取数据发送接口请求,实现数据的构造;或者Python的requests库的都可以比较快的实现。
但是这种方法有一定的技术门槛,你必须熟练使用至少一款接口测试的工具。
而且还有一些功能接口要处理接口的依赖,或者有接口本地的一些bug阻塞或者性能瓶颈问题。
既然不管是页面操作还是接口操作,都是本质上把数据插入到数据库中,那我们是否可以直接去数据库插入数据呢?
答案是可以的。
方法三:直接使用sql insert 插入数据
使用使用SQL语句,比如:insert into tuser (username,phone) values ("tricy","13444444444")插入数据。
但是这种方法虽然是对数据库直接操作,奈何效率太低,一条一条的插入,所以这种方法在实际操作中是不可取的。
方法四:一次性从外部导入excel表格数据
第一步:本地电脑准备好一个excel表格,按照数据库的表的字段填入一行数据,然后在excel表格里进行下拉拖拽实现数据的快速复制。如下图:

然后保存好这个excel文件。
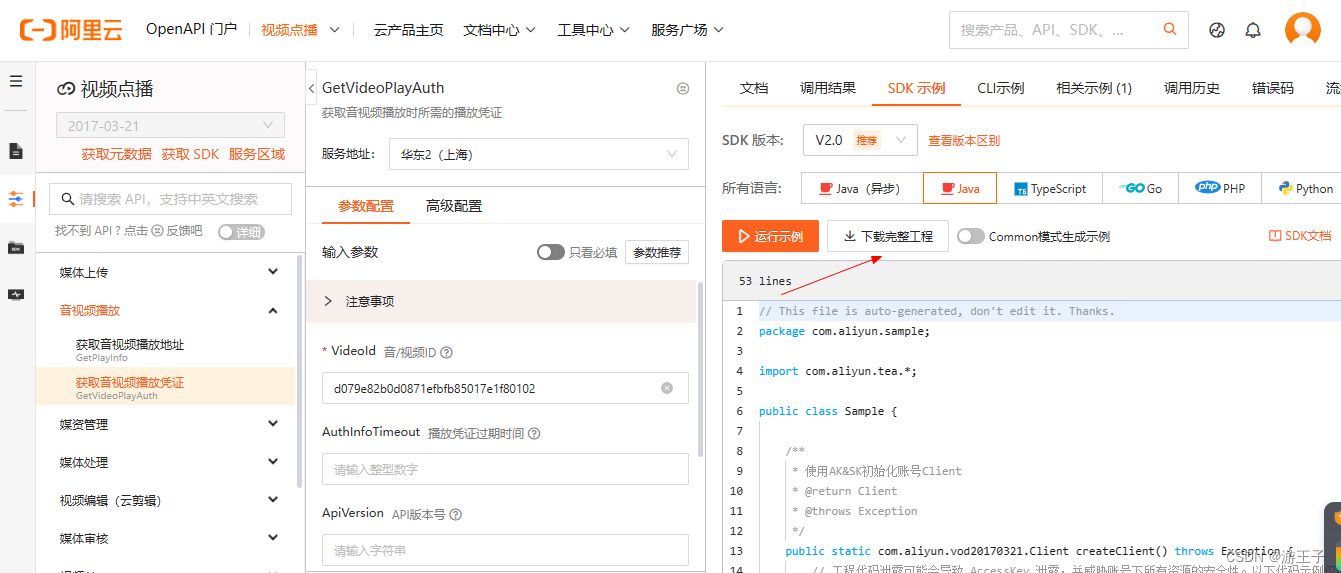
第二步:打开连接上MySQL数据库的Navicat,右键我们数据库的表,选择导入向导-->选择excel文件类型进行导入,具体步骤如下图所示:

完成导入操作后,数据库表里就会插入所有excel的数据。
然后这种方式,可以在excel表格手动拖拽复制出来千条数量级的数据,但是如果数据量更大,就也不太方便了。需要有更加高效的方法。
方法五:数据库的存储过程实现快速构建百万级的数据
存储过程其实就是数据库的编程,可以通过编程控制数据插入的次数。如下案例:
-
drop procedure if exists proc_batch_insert; # 如果存在存储过程就先删除 -
create procedure proc_batch_insert() # 创建存储过程 -
begin -
declare i int; # 定义一个变量用来计数 -
declare _name varchar(25); # 定义一个变量用来计数参数化用户名 -
declare _phone char(11); # 定义一个变量用来计数参数化手机号码 -
set i=1; # 设置计时器的初始值为1 -
while i<=1000000 do # while循环控制插入数据的次数 -
set _name = concat('tom-',i); # 拼接用户名,i为变化的保证用户名的差异性 -
set _phone = 13000000000+i; # 拼接手机号码,i为变化的保证手机号码的差异性 -
insert into tuser(username,phone) values(_name,_phone); # 插入数据 -
set i=i+1; # 每次循环计时器加1 -
end while; -
end -
call proc_batch_insert(); # 运行存储过程
方法六:Python代码实现构造百万的数据
如果有代码基础的同学,也可以使用Python代码编程实现这个过程:
-
import random -
import string -
import pymysql -
# 数据库连接信息 -
host = '139.224.61.195' -
user = 'root' -
port = 3307 -
password = '123456' -
database = 'test' -
# 建立数据库连接 -
connection = pymysql.connect(host=host, user=user,port=port, password=password, database=database) -
cursor = connection.cursor() -
# 构造百万数据 -
batch_size = 10000 # 每批插入的数据量 -
total_records = 1000000 # 总共需要生成的数据量 -
# 获取当前表中最大的id值 -
cursor.execute("SELECT MAX(id) FROM tuser") -
max_id = cursor.fetchone()[0] or 0 -
for i in range(total_records // batch_size): #是整数除法,它计算出需要进行多少批次的数据生成和插入。 -
# 生成批量数据 -
batch_data = [] -
for i in range(batch_size): -
max_id += 1 -
user_id = max_id # 使用自增长方式生成唯一id -
username = ''.join(random.choices(string.ascii_lowercase, k=10)) -
phone = ''.join(random.choices(string.digits, k=11)) -
batch_data.append((user_id, username, phone)) -
# 批量插入数据 -
sql = "INSERT INTO tuser (id, username, phone) VALUES (%s, %s, %s)" -
cursor.executemany(sql, batch_data) -
connection.commit() -
# 关闭数据库连接 -
cursor.close() -
connection.close(
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。