目录
一、C/C++中程序的内存区域划分
为什么会存在内存区域划分?
二、new关键字
1、内置类型的new/delete使用方法:
2、new和delete的本质
3、常见面试题——malloc/free和new/delete的区别
三、模版
1、泛型编程
2、函数模版
(1)、引言
(2)、概念
3、模版原理
4、模版的实例化
5、类模版
6、匹配调用规则:
7、类模板注意事项:
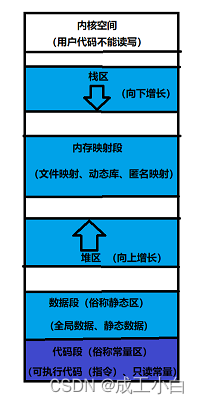
一、C/C++中程序的内存区域划分
为什么会存在内存区域划分?
因为不同数据有不同的存储需求,各区域满足不同的需求。
例如:
(1)、一些临时变量,局部变量存储在栈区
(2)、常用数据结构或一些算法(如归并排序)中会用到动态内存开辟,该内存是在堆区申请。
(3)、全局变量、静态变量存储在数据段(静态区)。
(4)、一些只读数据,如字符常量、可执行代码(指令)存储在代码段(常量区)。
二、new关键字
C语言中动态内存管理方式使用malloc/calloc/realloc/free函数来实现,C语言内存管理方式在C++中可以继续使用,但有些地方就无能为力,而且使用起来比较麻烦,因此C++又提出了自己的内存管理方式:通过new和delete操作符进行动态内存管理。
1、内置类型的new/delete使用方法:
//动态申请一个int型 int* a = new int; //动态申请一个int型,并初始化为10 int* a1 = new int(10); //动态申请一个int型数组 int* arr1 = new int[10]; //动态申请一个int型数组,并初始化 int* arr2 = new int[3] {1, 2, 3}; //若为完全初始化,则后面的值会默认初始化为0 int* arr3 = new int[10] {1, 2, 3}; //每new一个变量,用完后一定要delete delete a; delete a1; //注意数组的区别 delete[] arr1; delete[] arr2; delete[] arr3;注意:使用new未初始化时,不会有默认值,而是随机值。
2、new和delete的本质
new的本质是为了解决动态申请的自定义类型对象的初始化问题。
因为C语言中malloc函数不能给自定义类型进行初始化:
//malloc不能给自定义类型初始化 A* p1 = (A*)malloc(sizeof(A));所以这时就可以用new和delete:
(1)、new的本质:开空间+调用构造函数初始化;
(2)、delete的本质:先调用析构函数+释放空间。
如下:
//new给自定义类型初始化 //调用默认构造函数 A* p2 = new A(); //调用带参数构造函数 A* p3 = new A(1); //给对象数组初始化 //(1)、有名对象 A aa1, aa2, aa3; A* arr1 = new A[3]{ aa1,aa2,aa3 }; //(2)、匿名对象 A* arr2 = new A[3]{ A(),A(),A()}; //(3)、隐式类型转换 A* arr3 = new A[3]{ 1,2,3 };注意:
(1)、内置类型的底下申请释放,new和malloc除了用法上,没有区别;
(2)、malloc申请失败会返回NULL,而new申请失败会抛异常;
3、常见面试题——malloc/free和new/delete的区别
从用法+原理角度区分:
malloc/free和new/delete共同点是:都是从堆上申请空间,并且需要用户手动释放。不同点是:1. malloc和free是函数,new和delete是操作符2. malloc申请的空间不会初始化,new可以初始化3. malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可, 如果是多个对象,[]中指定对象个数即可4. malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型5. malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需 要捕获异常6. 申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new 在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成 空间中资源的清理。
三、模版
1、泛型编程
泛型编程通俗来讲就是写跟具体类型无关的代码,广泛的编程。是代码复用的一种手段。模板是泛型编程的基础。
2、函数模版
(1)、引言
我们以交换函数为例,看下列代码:
void Swap(int& p1, int& p2) { int tmp = p1; p1 = p2; p2 = p1; } void Swap(char& p1, char& p2) { char tmp = p1; p1 = p2; p2 = p1; } void Swap(double& p1, double& p2) { double tmp = p1; p1 = p2; p2 = p1; }这是用函数重载的知识,但函数重载也有不好的地方:
1. 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数。2. 代码的可维护性比较低,一个出错可能所有的重载均出错。正如上述各函数,我们发现好像只有类型不同,这时我们就可以用模版来减少代码的冗余。
(2)、概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。格式:template<typename T1, typename T2,......,typename Tn>返回值类型 函数名(参数列表){}例如上述代码,我们可以写成:template<typename T> void Swap(T& p1, T& p2) { T tmp = p1; p1 = p2; p2 = tmp; }当有多种类型时,就可以写多个typename(或class):
注意:
typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
3、模版原理
注意一点: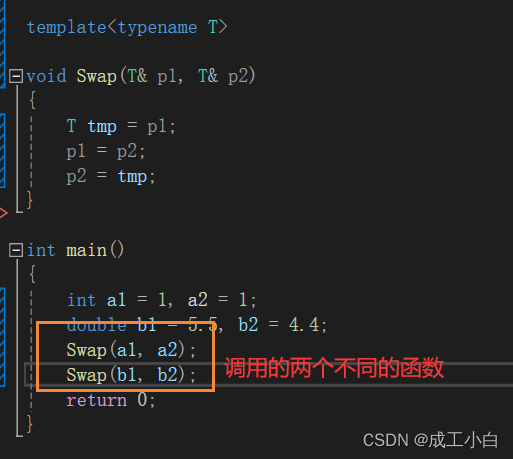 模版处只有一个函数,为什么会是调用的两个函数?这就是模版的原理所造成的现象:原理:函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器。在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供 调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然 后产生一份专门处理double类型的代码,对于字符类型也是如此。
模版处只有一个函数,为什么会是调用的两个函数?这就是模版的原理所造成的现象:原理:函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器。在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供 调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然 后产生一份专门处理double类型的代码,对于字符类型也是如此。
4、模版的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。模版参数语法很类似函数参数,只是函数参数定义的是形参对象,而模版定义的是类型。
(1)、推演实例化:例如上述内容
,是编译器自己识别模版是什么类型,就叫推演实例化。
(2)、显示实例化:
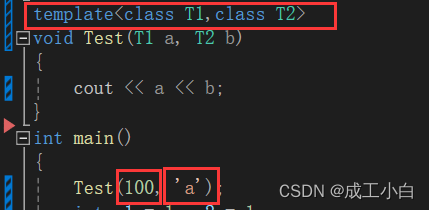
//单类型模版显示调用 Swap<int>(1, 1); //多类型模版显示调用 Test<int, double>(1, 5.5);有一些情况只能用显示实例化,比如无参函数,传不了参数,就不能靠推演确定类型,这时只能显示实例化模版:

5、类模版
(1)、类模版定义格式
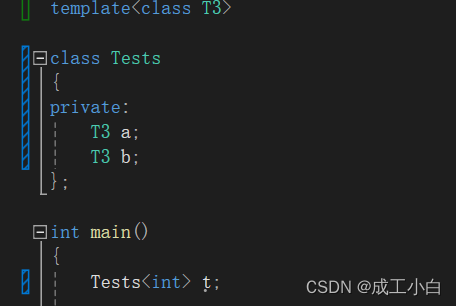
template<class T1, class T2, ..., class Tn> class 类模板名 { // 类内成员定义 };特别注意:类模版必须显示实例化:
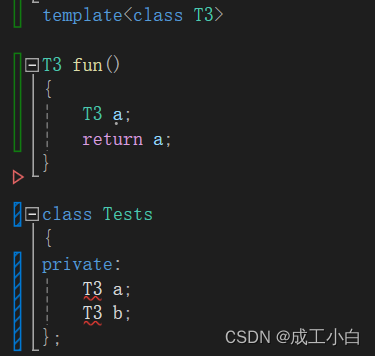
然后模版与类之间不能存在函数使用模版,同理想要函数模版,中间也不能穿插类使用模版。
6、匹配调用规则:
1、有现成的函数可以匹配就调用现成。
2、有合适的就调用合适的,没有就将就。
7、类模板注意事项:
(1)、使用类模版后,当成员函数的声明与定义分开写时,会有改变:
template<class T> class Test { public: //构造函数 //声明 Test(T i); private: int _i; }; //定义 template<class T> Test<T>::Test(T i) { T tmp; }(2)、特别注意:
普通类:类名就是类型。
类模板实例化的类:类名不是类型,类名<数据类型>才是整个类的类型。
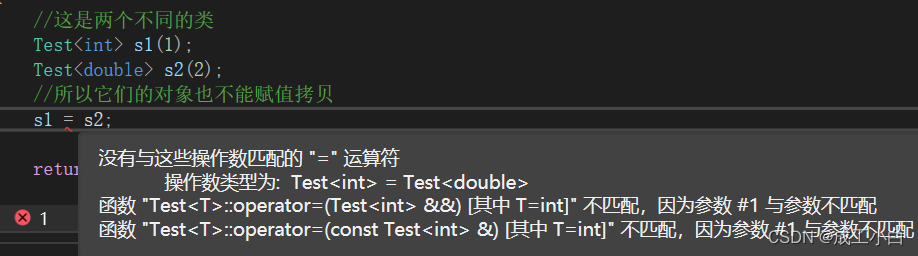
也就是说:显示实例化类模板的类型不同,它们就是不同的类: