目录
1、k8s相关网络类型
1.1 K8S中Pod网络通信
1.2 Overlay Network
1.3 VXLAN
1.3.1 vlan和vxlan的区别
2、Flannel
2.1 简介
2.2 Flannel工作原理
2.3 ETCD之Flannel提供说明
2.4 Flannel部署
2.4.1 在node节点上操作
2.4.2 在master01节点上操作
2.4.2.1 安装flannel
3、部署 Calico
3.1 k8s 组网方案对比
3.1.1 flannel方案
3.1.2 calico方案
3.2 Calico 主要由三个部分组成
3.3 Calico 工作原理
3.4 部署Calico
4、部署 CoreDNS
4.1 准备需要的镜像
4.2 准备yml文件启动coredns服务
4.3 DNS 解析测试
1、k8s相关网络类型
1.1 K8S中Pod网络通信
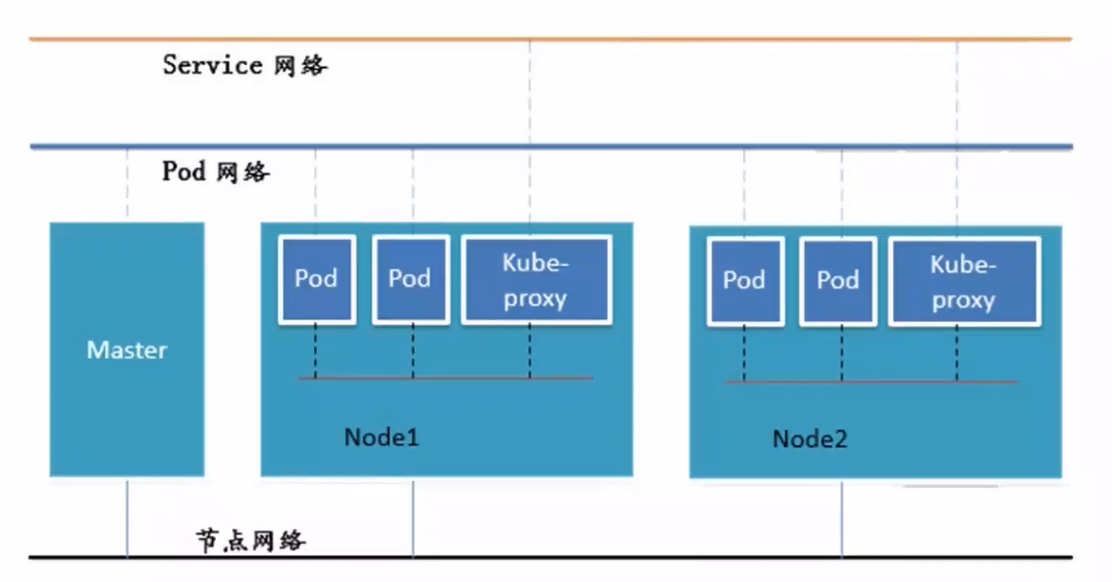
● Pod内容器与容器之间的通信 在同一个Pod内的容器(Pod内的容器是不会跨宿主机的)共享同一个网络命令空间,相当于它们在同一台机器上一样,可以用localhost地址访问彼此的端口。
● 同一个Node内Pod之间的通信 每个Pod都有一个真实的全局IP地址,同一个Node内的不同Pod之间可以直接采用对方Pod的IP地址进行通信,Pod1与Pod2都是通过Veth连接到同一个docker0网桥,网段相同,所以它们之间可以直接通信。
● 不同Node上Pod之间的通信 Pod地址与docker0在同一网段,docker0网段与宿主机网卡是两个不同的网段,且不同Node之间的通信只能通过宿主机的物理网卡进行。 要想实现不同Node上Pod之间的通信,就必须想办法通过主机的物理网卡IP地址进行寻址和通信。因此要满足两个条件:Pod的IP不能冲突,将Pod的IP和所在的Node的IP关联起来,通过这个关联让不同Node上Pod之间直接通过内网IP地址通信。
1.2 Overlay Network
叠加网络,在二层或者三层几乎网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来(类似于VPN)。
1.3 VXLAN
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址。
1.3.1 vlan和vxlan的区别
VLAN(Virtual Local Area Network)和VXLAN(Virtual Extensible LAN)在多个方面存在显著的区别,以下是它们的主要差异:
①定义与功能:
- VLAN,中文名为“虚拟局域网”,是一种将局域网(LAN)设备从逻辑上划分(而非物理上)成一个个网段(或者说是更小的局域网LAN)的技术,从而实现虚拟工作组(单元)的数据交换。VLAN主要工作在二层网络上,可以基于交换机的虚拟局域网解决冲突域、广播域、带宽问题。
- VXLAN,中文名为“虚拟可扩展局域网”,是一种网络虚拟化技术,基于IP网络并采用“MAC in UDP”封装形式的二层VPN技术。它试图改进大型云计算的部署时的扩展问题,可以说是对VLAN的一种扩展。VXLAN可以基于已有的服务提供商或企业IP网络,为分散的物理站点提供二层互联,并能够为不同的租户提供业务隔离。
②扩展性:
- VLAN在跨三层网络的场景中,其扩展性受到限制。
- VXLAN则是一种在三层网络上构建虚拟二层网络的技术,通过将二层报文封装在三层报文中进行传输,实现了跨三层网络的二层通信,从而具有良好的扩展性。
③虚拟网络空间:
- VLAN的vlanHeader头部限长是12bit,导致VLAN的限制个数是2^12=4096个,无法满足日益增长的需求。
- VXLAN使用24位的VNI(VXLAN Network Identifier)字段,理论上可以支持多达1600万个虚拟网络,解决了VLAN数量限制的问题。
④多租户支持:
- VLAN本身并不直接支持多租户隔离。
- VXLAN则通过引入MAC-in-UDP封装方式,使得不同租户之间的网络相互隔离,解决了地址冲突问题。
2、Flannel
2.1 简介
Flannel的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。 Flannel是Overlay网络的一种,也是将TCP源数据包封装在另一种网络包里面进行路由转发和通信,目前支持UDP、VXLAN、host-GW三种数据转发方式。
2.2 Flannel工作原理
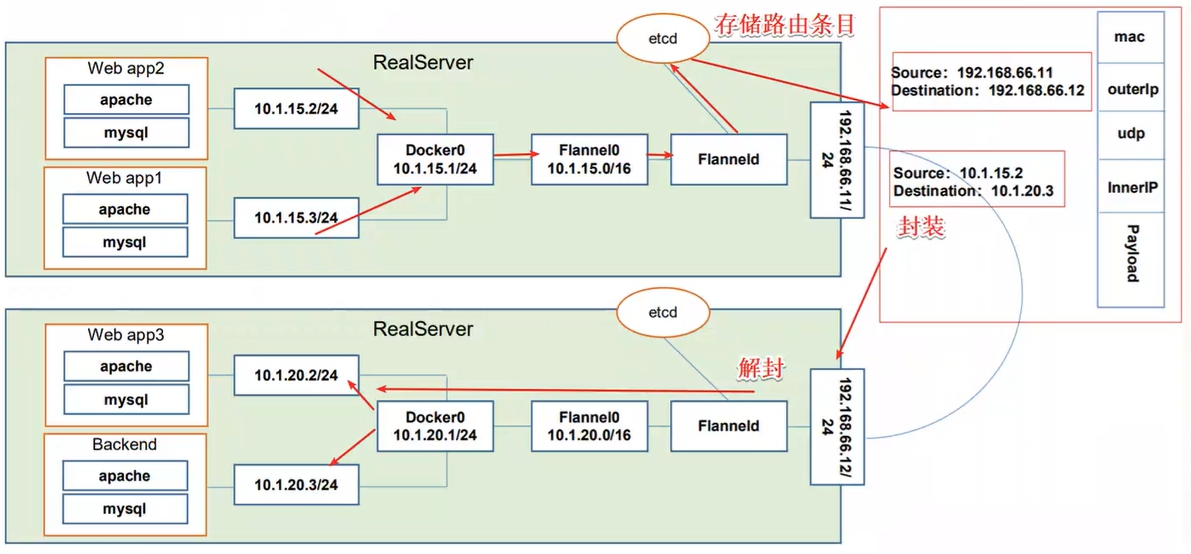
数据从node01上Pod的源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel.1虚拟网卡,flanneld服务监听在flanne.1数据网卡的另外一端。
Flannel通过Etcd服务维护了一张节点间的路由表。源主机node01的flanneld服务将原本的数据内容封装到UDP中后根据自己的路由表通过物理网卡投递给目的节点node02的flanneld服务,数据到达以后被解包,然后直接进入目的节点的dlannel.1虚拟网卡,之后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一样由docker0转发到目标容器。
2.3 ETCD之Flannel提供说明
存储管理Flannel可分配的IP地址段资源 监控ETCD中每个Pod的实际地址,并在内存中建立维护Pod节点路由表
2.4 Flannel部署
2.4.1 在node节点上操作
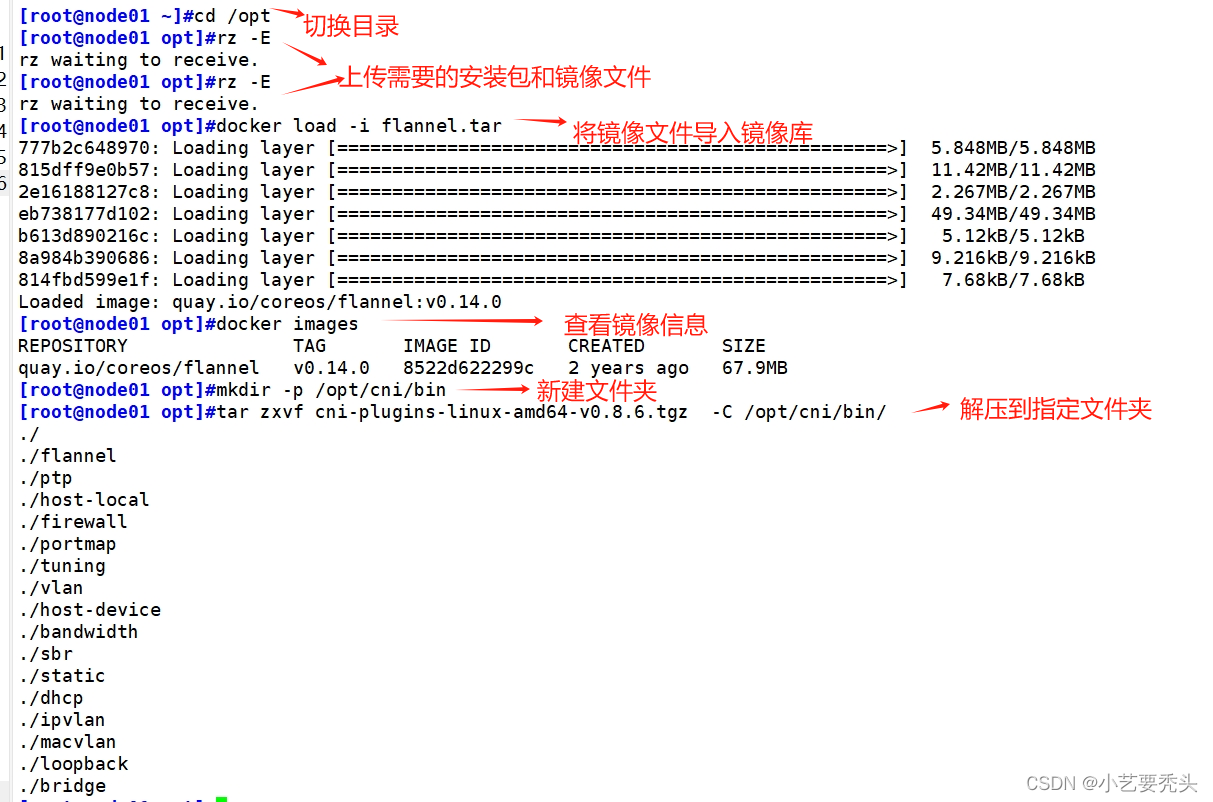
cd /opt/
#切换目录
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
docker load -i flannel.tar
#将镜像文件导入到镜像库中
docker images
#显示镜像信息
mkdir -p /opt/cni/bin
#新建目录
tar xf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
#解压到指定目录
ll /opt/cni/bin
#显示解压的文件
- node01和node02操作一样
2.4.2 在master01节点上操作
2.4.2.1 安装flannel
cd /opt/k8s
#切换目录
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
-------------------------------------------------------------------------------------------------------
#查看yml文件
vim /opt/k8s/kube-flannel.yml
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.14.0
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.14.0
#此处镜像与node节点的镜像是一致的
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
-------------------------------------------------------------------------------------------------------
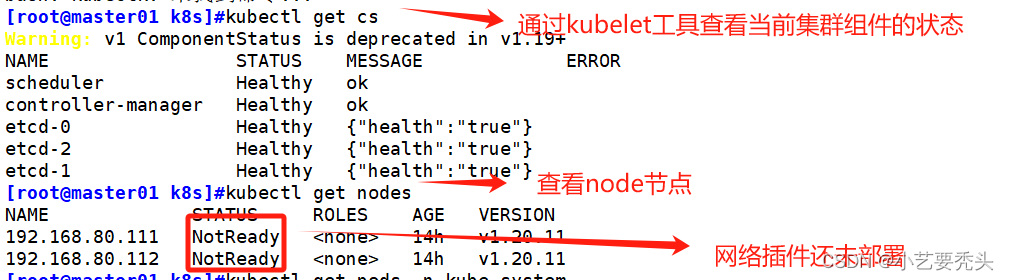
kubectl apply -f kube-flannel.yml
#指定yml文件启动flannel服务
kubectl get pods -n kube-system
#查询指定命名空间(namespace)下的 Pod 资源
#-n:指定命名空间(STATUS:Running)
kubectl get nodes
#查看集群所有节点信息(STATUS:Ready)



3、部署 Calico
3.1 k8s 组网方案对比
3.1.1 flannel方案
需要在每个节点上把发向容器的数据包进行封装后,再用隧道将封装后的数据包发送到运行着目标Pod的node节点上。目标node节点再负责去掉封装,将去除封装的数据包发送到目标Pod上。数据通信性能则大受影响。
3.1.2 calico方案
Calico不使用隧道或NAT来实现转发,而是把Host当作Internet中的路由器,使用BGP同步路由,并使用iptables来做安全访问策略,完成跨Host转发。
采用直接路由的方式,这种方式性能损耗最低,不需要修改报文数据,但是如果网络比较复杂场景下,路由表会很复杂,对运维同事提出了较高的要求。
3.2 Calico 主要由三个部分组成
- Calico CNI插件:主要负责与kubernetes对接,供kubelet调用使用。
- Felix:负责维护宿主机上的路由规则、FIB转发信息库等。
- BIRD:负责分发路由规则,类似路由器。
- Confd:配置管理组件。
3.3 Calico 工作原理
- Calico 是通过路由表来维护每个 pod 的通信。Calico 的 CNI 插件会为每个容器设置一个 veth pair 设备, 然后把另一端接入到宿主机网络空间,由于没有网桥,CNI 插件还需要在宿主机上为每个容器的 veth pair 设备配置一条路由规则, 用于接收传入的 IP 包。
- 有了这样的 veth pair 设备以后,容器发出的 IP 包就会通过 veth pair 设备到达宿主机,然后宿主机根据路由规则的下一跳地址, 发送给正确的网关,然后到达目标宿主机,再到达目标容器。
- 这些路由规则都是 Felix 维护配置的,而路由信息则是 Calico BIRD 组件基于 BGP 分发而来。
- calico 实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过 BGP 交换路由, 这些节点我们叫做 BGP Peer。
目前比较常用的CNI网络组件是flannel和calico,flannel的功能比较简单,不具备复杂的网络策略配置能力,calico是比较出色的网络管理插件,但具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多网络策略,则使用calico更好。
3.4 部署Calico
在nodes节点上操作
[root@node01 opt]#cd /opt
#切换路径并上传对应的镜像包
[root@node01 opt]#rz -E
rz waiting to receive.
#将镜像包导入镜像库
[root@node01 opt]#docker load -i calico-cni.tar
[root@node01 opt]#docker load -i calico-node.tar
[root@node01 opt]#docker load -i calico-kube-controllers.tar
[root@node01 opt]#docker load -i calico-pod2daemon-flexvol.tar
[root@node01 opt]#docker images

在 master01 节点上操作
cd /opt/k8s
#切换目录
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
------------------------------------------------------------------------------------------------------
vim calico.yaml
#修改里面定义 Pod 的网络(CALICO_IPV4POOL_CIDR),需与前面 kube-controller-manager 配置文件指定的 cluster-cidr 网段一样
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
#Calico 默认使用的网段为 192.168.0.0/16
------------------------------------------------------------------------------------------------------
kubectl apply -f calico.yaml
#指定yml文件启动calico服务
kubectl get pods -n kube-system
#查询指定命名空间(namespace)下的 Pod 资源
#等 Calico Pod 都 Running,节点也会准备就绪
kubectl get nodes
#查看集群所有节点信息(STATUS:Ready)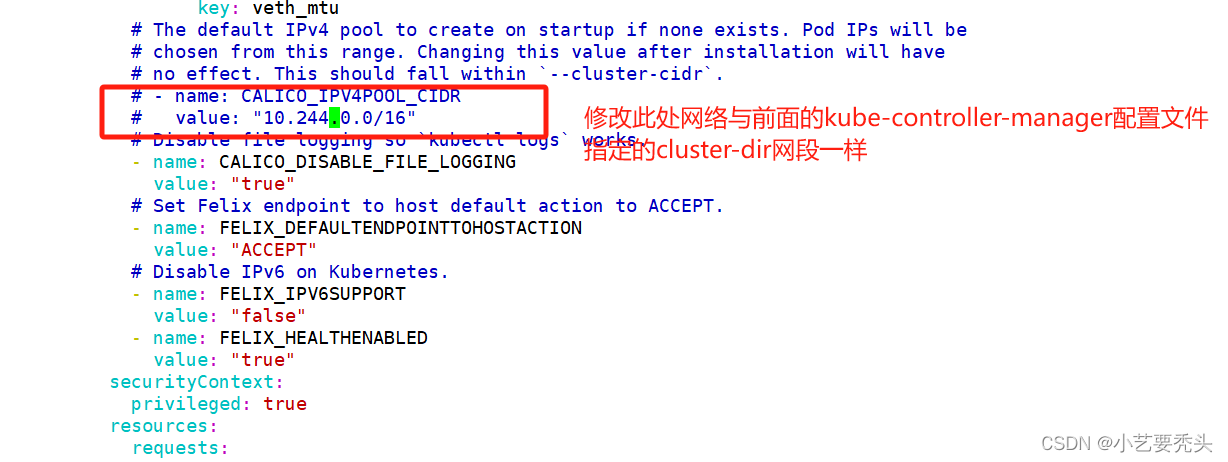

4、部署 CoreDNS
- CoreDNS:可以为集群中的 service 资源创建一个域名 与 IP 的对应关系解析
4.1 准备需要的镜像
在所有 node 节点上操作
cd /opt
#切换目录
#上传 coredns.tar 到 /opt 目录中
docker load -i coredns.tar
#将镜像文件导入到镜像库中node节点

4.2 准备yml文件启动coredns服务
在 master01 节点上操作
cd /opt/k8s
#切换目录
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
--------------------------------------------------------------------------------------------------------
# __MACHINE_GENERATED_WARNING__
apiVersion: v1
kind: ServiceAccount
metadata:
name: coredns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: Reconcile
name: system:coredns
rules:
- apiGroups:
- ""
resources:
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
priorityClassName: system-cluster-critical
serviceAccountName: coredns
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values: ["kube-dns"]
topologyKey: kubernetes.io/hostname
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
kubernetes.io/os: linux
containers:
- name: coredns
image: k8s.gcr.io/coredns:1.7.0
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /ready
port: 8181
scheme: HTTP
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.0.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
- name: metrics
port: 9153
protocol: TCP
--------------------------------------------------------------------------------------------------------
kubectl apply -f coredns.yaml
#指定yml配置文件启动coredns服务
kubectl get pods -n kube-system
#查询指定命名空间(namespace)下的 Pod 资源
4.3 DNS 解析测试
kubectl run -it --image=busybox:1.28.4 sh
#DNS 解析测试
-----------------------------------------------------------------------------------------------------
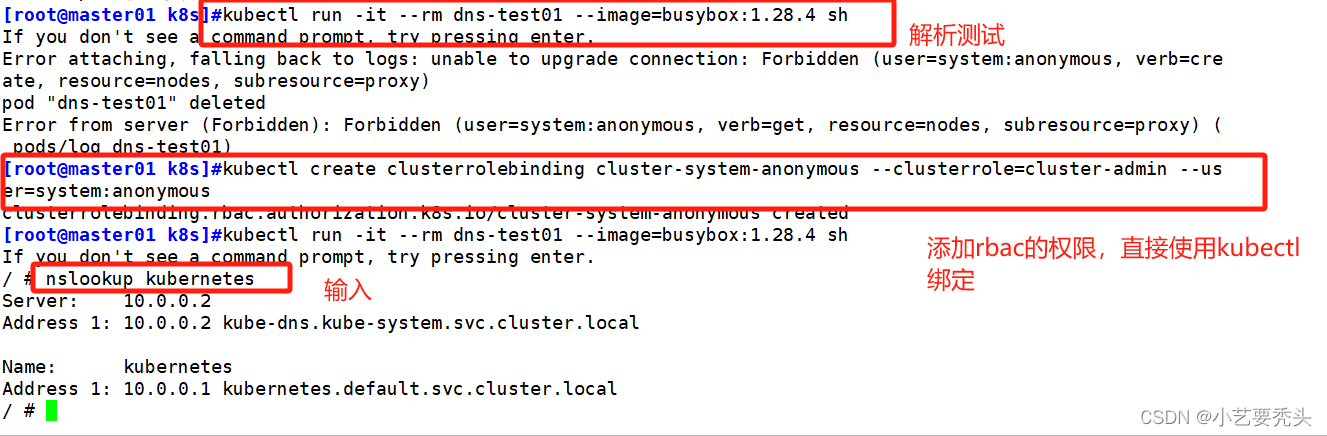
如果出现以下报错
[root@master01 k8s]#kubectl run -it --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
Error attaching, falling back to logs: unable to upgrade connection: Forbidden (user=system:anonymous, verb=create, resource=nodes, subresource=proxy)
Error from server (Forbidden): Forbidden (user=system:anonymous, verb=get, resource=nodes, subresource=proxy) ( pods/log sh)
-----------------------------------------------------------------------------------------------------
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
#需要添加 rbac的权限,直接使用kubectl绑定,clusteradmin 管理员集群角色,授权操作权限
#此时再次dns测试
kubectl run -it --rm dns-test01 --image=busybox:1.28.4 sh
#DNS 解析测试
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes
[root@master01 opt]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
nginx-test-7dc4f9dcc9-vs2p6 1/1 Running 0 4m3s 172.17.54.3 node01 <none>