时间序列分析是数据科学和机器学习领域最广泛的主题之一:无论是预测金融事件、能源消耗、产品销售还是股票市场趋势,这一领域一直是企业非常感兴趣的领域。
随着机器学习模型的不断进步,使除了传统的统计预测方法(如回归模型、ARIMA模型、指数平滑)外,与机器学习(如基于树的模型)和深度学习(如LSTM网络、cnn、基于Transformer的模型)相关的技术已经出现了一段时间。
尽管这些技术之间存在巨大差异,但无论模型是什么,都必须完成一个初步步骤:探索性数据分析。
在统计学中,探索性数据分析(Exploratory Data Analysis, EDA)是对数据进行分析和可视化,以总结数据的主要特征并从中获得相关信息的一门学科。这在数据科学领域非常重要,因为它可以为另一个重要步骤奠定基础:特征工程。
所以我们今天这篇文章将总结一个时间序列数据的分析模板,可以总结和突出数据集的最重要特征。我们将使用一些常见的Python库,如Pandas、Seaborn和Statsmodel。
为了方便演示,将使用Kaggle的小时能耗数据。该数据集与PJM小时能源消耗数据有关,PJM是美国的一个区域输电组织,为几个州提供电力。每小时的电力消耗数据来自PJM的网站,单位是兆瓦。
我在本文中我们将EDA总结为六个步骤:描述性统计、时间图、季节图、箱形图、时间序列分解、滞后分析。

描述性统计
描述性统计是一种汇总统计,用于定量地描述或总结结构化数据集合中的特征。
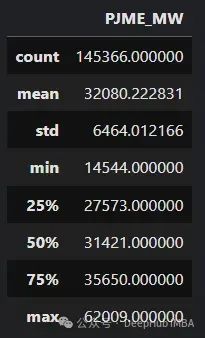
一些通常用于描述数据集的度量是:集中趋势度量(例如平均值,中位数),分散度量(例如范围,标准差)和位置度量(例如百分位数,四分位数)。所有这些都可以用所谓的五数总结来概括,即分布的最小值、第一四分位数(Q1)、中位数或第二四分位数(Q2)、第三四分位数(Q3)和最大值。
在Python中,这些信息可以使用Pandas中众所周知的describe方法轻松检索:
import pandas as pd
# Loading and preprocessing steps
df = pd.read_csv('../input/hourly-energy-consumption/PJME_hourly.csv')
df = df.set_index('Datetime')
df.index = pd.to_datetime(df.index)
df.describe()
时间曲线图
最明显且直观的图表是时间图。观测结果是根据观测时间绘制的,连续的观测结果用线条连接起来。
在Python中,我们可以使用Pandas和Matplotlib:
import matplotlib.pyplot as plt
# Set pyplot style
plt.style.use("seaborn")
# Plot
df['PJME_MW'].plot(title='PJME - Time Plot', figsize=(10,6))
plt.ylabel('Consumption [MW]')
plt.xlabel('Date')

这张图可以为我们提供一下的信息:
- 模式显示出每年的季节性。
- 如果只关注一年,似乎会发现更多的规律。由于用电量较大,冬季和夏季的用电量可能会出现高峰。
- 这个数据多年来没有明显的增加/减少趋势,平均消费量保持平稳。
- 2013年前后有一个异常值,可以进行特殊的分析
季节性
季节性图基本上是一个时间图,其中数据是根据它们所属的系列的各个“季节”绘制的。
关于能源消耗,我们通常有每小时可用的数据,因此可以有几个季节性:每年,每周,每天。在深入研究这些图之前,让我们首先在Pandas中设置一些变量:
# Defining required fields
df['year'] = [x for x in df.index.year]
df['month'] = [x for x in df.index.month]
df = df.reset_index()
df['week'] = df['Datetime'].apply(lambda x:x.week)
df = df.set_index('Datetime')
df['hour'] = [x for x in df.index.hour]
df['day'] = [x for x in df.index.day_of_week]
df['day_str'] = [x.strftime('%a') for x in df.index]
df['year_month'] = [str(x.year) + '_' + str(x.month) for x in df.index]
1、年消耗量
一个非常有趣的图是按年按月分组的能源消耗,这突出了年度季节性,可以告诉我们多年来的上升/下降趋势。
import numpy as np
# Defining colors palette
np.random.seed(42)
df_plot = df[['month', 'year', 'PJME_MW']].dropna().groupby(['month', 'year']).mean()[['PJME_MW']].reset_index()
years = df_plot['year'].unique()
colors = np.random.choice(list(mpl.colors.XKCD_COLORS.keys()), len(years), replace=False)
# Plot
plt.figure(figsize=(16,12))
for i, y in enumerate(years):
if i > 0:
plt.plot('month', 'PJME_MW', data=df_plot[df_plot['year'] == y], color=colors[i], label=y)
if y == 2018:
plt.text(df_plot.loc[df_plot.year==y, :].shape[0]+0.3, df_plot.loc[df_plot.year==y, 'PJME_MW'][-1:].values[0], y, fontsize=12, color=colors[i])
else:
plt.text(df_plot.loc[df_plot.year==y, :].shape[0]+0.1, df_plot.loc[df_plot.year==y, 'PJME_MW'][-1:].values[0], y, fontsize=12, color=colors[i])
# Setting labels
plt.gca().set(ylabel= 'PJME_MW', xlabel = 'Month')
plt.yticks(fontsize=12, alpha=.7)
plt.title("Seasonal Plot - Monthly Consumption", fontsize=20)
plt.ylabel('Consumption [MW]')
plt.xlabel('Month')
plt.show()
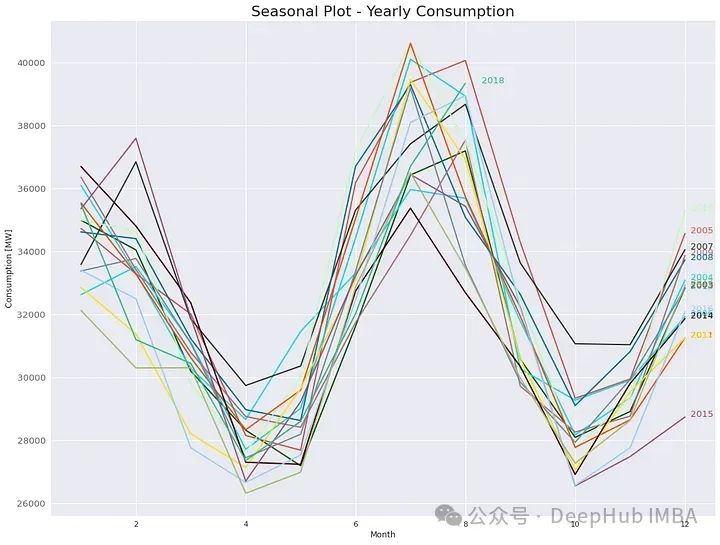
这张图显示,每年都有一个预定义的模式:冬季消耗显著增加,夏季达到峰值(由于供暖/制冷系统),而春季和秋季通常不需要供暖或制冷时消耗最小。这张图还告诉我们,在多年的总消费量中,并没有明显的增加/减少模式。
2、周消耗量
另一个有用的图表是每周图表,它描述了几个月来每周的消费情况,还可以表明每周在一年内是否以及如何变化。
# Defining colors palette
np.random.seed(42)
df_plot = df[['month', 'day_str', 'PJME_MW', 'day']].dropna().groupby(['day_str', 'month', 'day']).mean()[['PJME_MW']].reset_index()
df_plot = df_plot.sort_values(by='day', ascending=True)
months = df_plot['month'].unique()
colors = np.random.choice(list(mpl.colors.XKCD_COLORS.keys()), len(months), replace=False)
# Plot
plt.figure(figsize=(16,12))
for i, y in enumerate(months):
if i > 0:
plt.plot('day_str', 'PJME_MW', data=df_plot[df_plot['month'] == y], color=colors[i], label=y)
if y == 2018:
plt.text(df_plot.loc[df_plot.month==y, :].shape[0]-.9, df_plot.loc[df_plot.month==y, 'PJME_MW'][-1:].values[0], y, fontsize=12, color=colors[i])
else:
plt.text(df_plot.loc[df_plot.month==y, :].shape[0]-.9, df_plot.loc[df_plot.month==y, 'PJME_MW'][-1:].values[0], y, fontsize=12, color=colors[i])
# Setting Labels
plt.gca().set(ylabel= 'PJME_MW', xlabel = 'Month')
plt.yticks(fontsize=12, alpha=.7)
plt.title("Seasonal Plot - Weekly Consumption", fontsize=20)
plt.ylabel('Consumption [MW]')
plt.xlabel('Month')
plt.show()
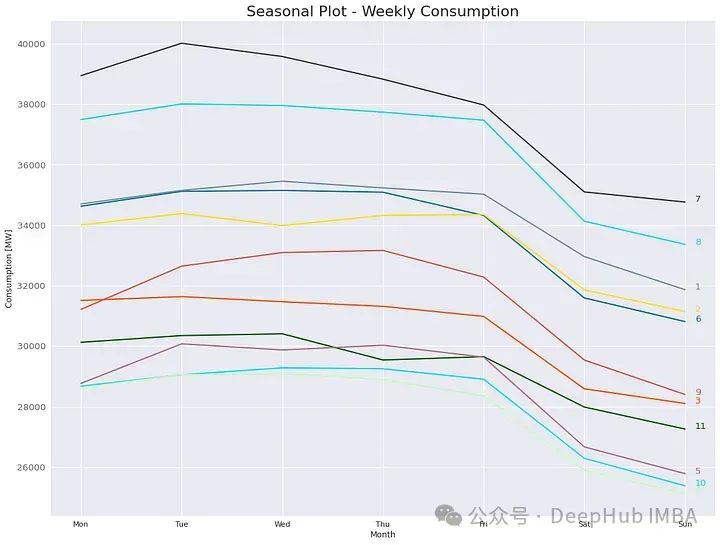
3、每日消费量
最后,我们看看每日消费量。它代表了一天中消费的变化。数据首先按星期进行分组,然后按平均值进行汇总。
import seaborn as sns
# Defining the dataframe
df_plot = df[['hour', 'day_str', 'PJME_MW']].dropna().groupby(['hour', 'day_str']).mean()[['PJME_MW']].reset_index()
# Plot using Seaborn
plt.figure(figsize=(10,8))
sns.lineplot(data = df_plot, x='hour', y='PJME_MW', hue='day_str', legend=True)
plt.locator_params(axis='x', nbins=24)
plt.title("Seasonal Plot - Daily Consumption", fontsize=20)
plt.ylabel('Consumption [MW]')
plt.xlabel('Hour')
plt.legend()
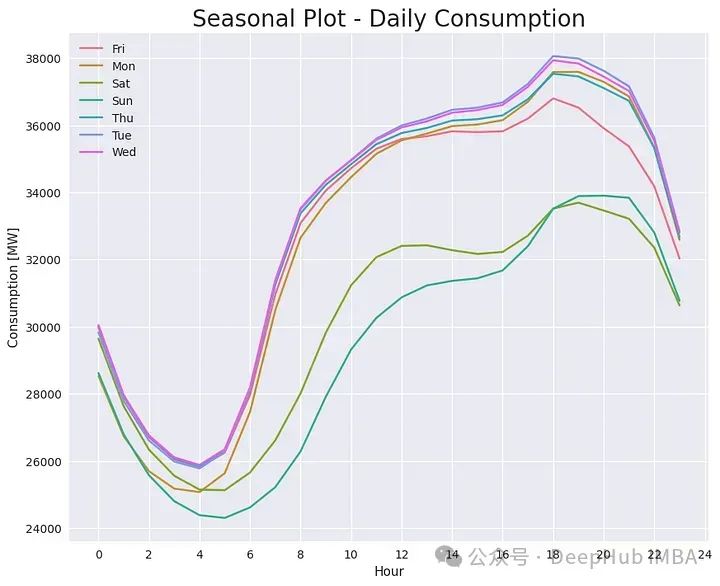
这张图显示了一个非常典型的模式,有人称之为“M轮廓”,因为日消耗似乎描绘了一个“M”。有时这种模式是清晰的
这些图通常在一天的中间(从上午10点到下午2点)显示一个相对峰值,然后是一个相对最小值(从下午2点到下午6点)和另一个峰值(从下午6点到晚上8点)。它还显示了周末和其他日期的消费差异。
4、特征工程
我们如何将这些信息用于特征工程呢?假设我们正在使用一些需要高质量特征的ML模型(例如ARIMA模型或基于树的模型)。
- 年消费量多年来变化不大这表明如果可能的话,可以使用来自滞后或外生变量的年季节性特征。
- 每周消费在几个月内遵循相同的模式,可以使用来自滞后或外生变量的每周特征。
- 每天的消费可以使用工作日和周末的分类特征来进行编码
箱线图
箱线图是识别数据分布的有效方法。箱线图描绘了百分位数,它代表了分布的第一个(Q1)、第二个(Q2/中位数)和第三个(Q3)四分位数,而箱须则代表了数据的范围。超过须的每一个值都可以被认为是一个离群值,更深入地说,须通常被计算为:

让我们首先计算总消耗的箱线图,这可以很容易地在Seaborn中完成:
plt.figure(figsize=(8,5))
sns.boxplot(data=df, x='PJME_MW')
plt.xlabel('Consumption [MW]')
plt.title(f'Boxplot - Consumption Distribution');

这个图看起来没有多少信息,但是它能告诉我们数据是一个类似高斯分布的分布,尾巴更向右突出。
下面是日/月箱形图。它是通过创建一个“日/月”变量并根据它对消费进行分组而获得的。以下是2017年以后的代码
df['year'] = [x for x in df.index.year]
df['month'] = [x for x in df.index.month]
df['year_month'] = [str(x.year) + '_' + str(x.month) for x in df.index]
df_plot = df[df['year'] >= 2017].reset_index().sort_values(by='Datetime').set_index('Datetime')
plt.title(f'Boxplot Year Month Distribution');
plt.xticks(rotation=90)
plt.xlabel('Year Month')
plt.ylabel('MW')
sns.boxplot(x='year_month', y='PJME_MW', data=df_plot)
plt.ylabel('Consumption [MW]')
plt.xlabel('Year Month')
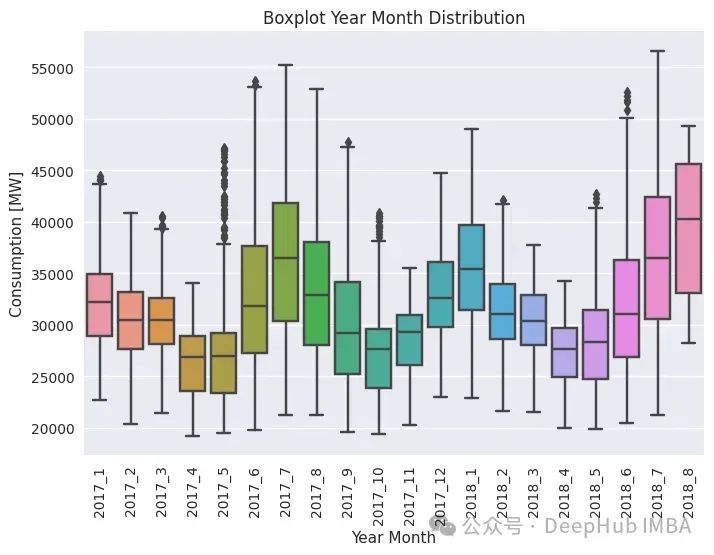
可以看到,在夏季/冬季(即当我们有高峰时)的不确定性较小,而在春季/秋季(即当温度变化较大时)则更加分散。2018年夏季的消费量高于2017年,这可能是由于夏季更温暖。当进行特征工程时,记得包括(如果可用的话)温度曲线,可能它可以用作外生变量。
另一个有用的图是一周内的分布,这类似于每周消费季节性图。
df_plot = df[['day_str', 'day', 'PJME_MW']].sort_values(by='day')
plt.title(f'Boxplot Day Distribution')
plt.xlabel('Day of week')
plt.ylabel('MW')
sns.boxplot(x='day_str', y='PJME_MW', data=df_plot)
plt.ylabel('Consumption [MW]')
plt.xlabel('Day of week')
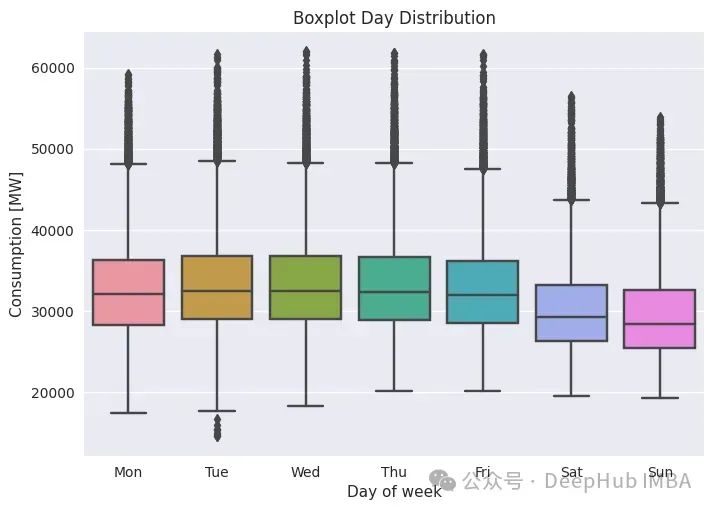
如前所述,周末的消费明显较低。有几个异常值能够看到,像“星期几”这样的日历特征肯定是有用的,但又不能完全解释。
最后我们来看小时图。它类似于日消费季节性图,因为它提供了一天中消费的分布情况。代码如下:
plt.title(f'Boxplot Hour Distribution');
plt.xlabel('Hour')
plt.ylabel('MW')
sns.boxplot(x='hour', y='PJME_MW', data=df)
plt.ylabel('Consumption [MW]')
plt.xlabel('Hour')
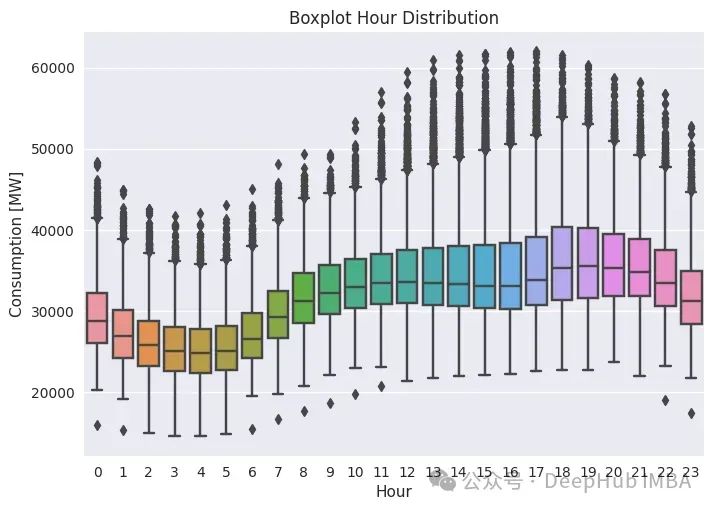
之前看到的“M”形现在更碎了。此外,还有很多异常值,这告诉我们数据不仅依赖于日常季节性(例如,今天12点的消费量与昨天12点的消费量相似),还依赖于其他一些东西,可能是一些外生气候特征,如温度或湿度。
时间序列分解
时间序列数据可以显示各种模式。将时间序列分成几个组件是有帮助的,每个组件表示一个潜在的模式类别。
我们可以认为一个时间序列由三个部分组成:趋势部分,季节部分和剩余(偏差)部分(包含时间序列中的任何其他部分)。对于某些时间序列(例如,能源消耗序列),可以有多个季节分量,对应于不同的季节周期(日、周、月、年)。
分解有两种主要类型:加性分解和乘法分解。
对于加性分解,我们将一个序列(整数)表示为季节分量(𝑆)、趋势分量(𝑇)和余数(𝑅)的和:
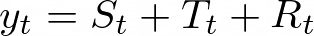
类似地,乘法分解可以写成:

一般来说,加性分解最适合方差恒定的序列,而乘法分解最适合方差非平稳的时间序列。
在Python中,时间序列分解可以通过Statsmodel库轻松实现:
df_plot = df[df['year'] == 2017].reset_index()
df_plot = df_plot.drop_duplicates(subset=['Datetime']).sort_values(by='Datetime')
df_plot = df_plot.set_index('Datetime')
df_plot['PJME_MW - Multiplicative Decompose'] = df_plot['PJME_MW']
df_plot['PJME_MW - Additive Decompose'] = df_plot['PJME_MW']
# Additive Decomposition
result_add = seasonal_decompose(df_plot['PJME_MW - Additive Decompose'], model='additive', period=24*7)
# Multiplicative Decomposition
result_mul = seasonal_decompose(df_plot['PJME_MW - Multiplicative Decompose'], model='multiplicative', period=24*7)
# Plot
result_add.plot().suptitle('', fontsize=22)
plt.xticks(rotation=45)
result_mul.plot().suptitle('', fontsize=22)
plt.xticks(rotation=45)
plt.show()
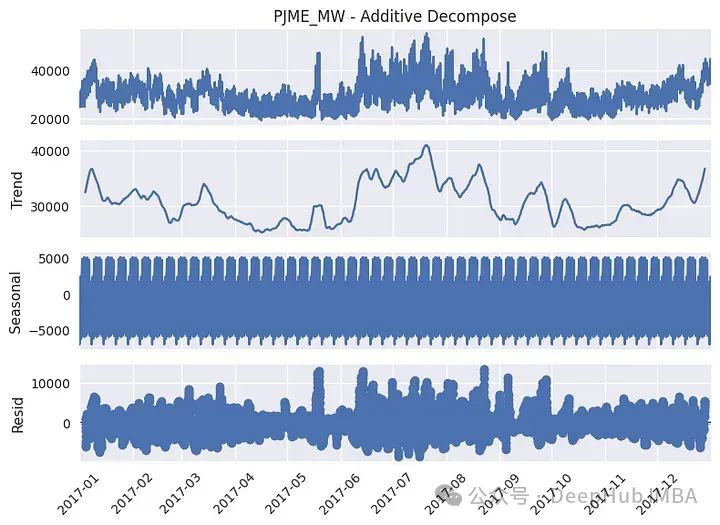
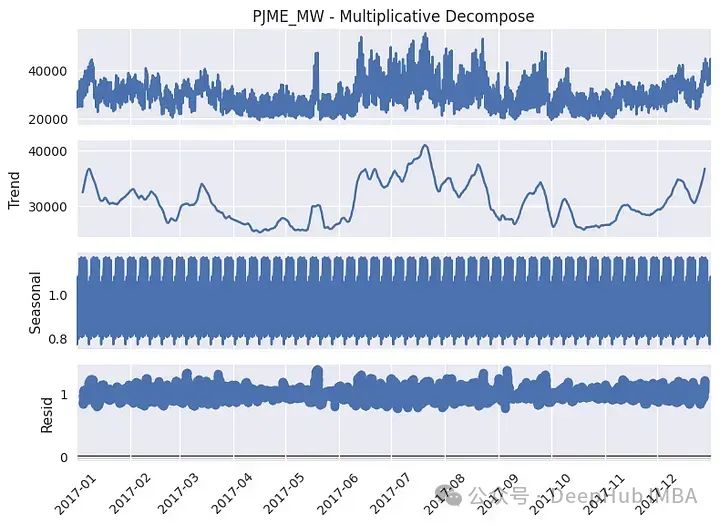
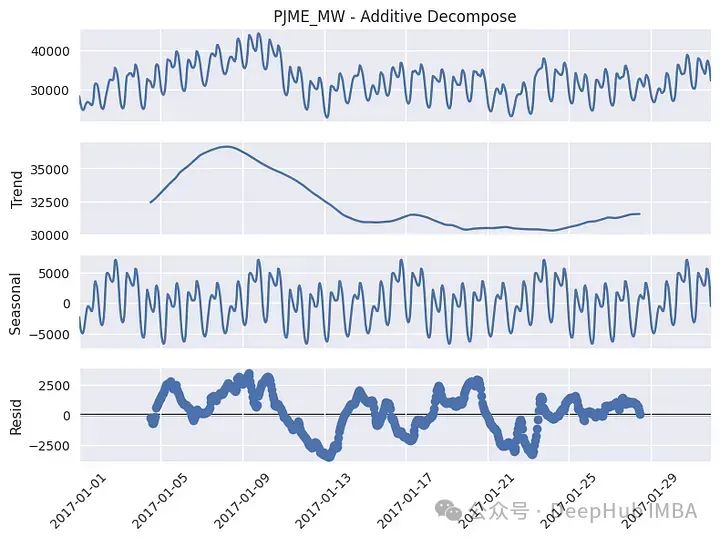
以上图为2017年的数据。我们看到趋势有几个局部峰值,夏季的值更高。从季节成分来看,可以看到实际上有几个周期性,该图更突出了周周期性,但如果我们关注同年的一个特定月份(1月),也会出现日季节性:
df_plot = df[(df['year'] == 2017)].reset_index()
df_plot = df_plot[df_plot['month'] == 1]
df_plot['PJME_MW - Multiplicative Decompose'] = df_plot['PJME_MW']
df_plot['PJME_MW - Additive Decompose'] = df_plot['PJME_MW']
df_plot = df_plot.drop_duplicates(subset=['Datetime']).sort_values(by='Datetime')
df_plot = df_plot.set_index('Datetime')
# Additive Decomposition
result_add = seasonal_decompose(df_plot['PJME_MW - Additive Decompose'], model='additive', period=24*7)
# Multiplicative Decomposition
result_mul = seasonal_decompose(df_plot['PJME_MW - Multiplicative Decompose'], model='multiplicative', period=24*7)
# Plot
result_add.plot().suptitle('', fontsize=22)
plt.xticks(rotation=45)
result_mul.plot().suptitle('', fontsize=22)
plt.xticks(rotation=45)
plt.show()

滞后分析
在时间序列预测中,滞后仅仅是序列的过去值。例如,对于每日序列,第一个滞后是指该序列前一天的值,第二个滞后是指再前一天的值,以此类推。
滞后分析是基于计算序列和序列本身的滞后版本之间的相关性,这也称为自相关。对于一个序列的k滞后版本,我们定义自相关系数为:

其中y 表示序列的平均值,k表示滞后值。
自相关系数构成了序列的自相关函数(ACF),描绘了自相关系数与考虑的滞后数的关系。
当数据具有趋势时,小滞后的自相关通常很大且为正,因为时间上接近的观测值在值上也相近。当数据显示季节性时,季节性滞后(及其季节周期的倍数)的自相关值会比其他滞后的大。具有趋势和季节性的数据将显示这些效应的组合。
在实践中,更有用的函数是偏自相关函数(PACF)。它类似于ACF但是它只显示两个滞后之间的直接自相关。例如,滞后3的偏自相关指的是滞后1和2无法解释的唯一相关性。或者说偏相关指的是某个滞后对当前时间值的直接影响。
如果序列是平稳的,则自相关系数会更清晰地显现,因此通常最好先对序列进行差分以稳定信号。
下面是绘制一天中不同时段PACF的代码:
from statsmodels.graphics.tsaplots import plot_pacf
actual = df['PJME_MW']
hours = range(0, 24, 4)
for hour in hours:
plot_pacf(actual[actual.index.hour == hour].diff().dropna(), lags=30, alpha=0.01)
plt.title(f'PACF - h = {hour}')
plt.ylabel('Correlation')
plt.xlabel('Lags')
plt.show()
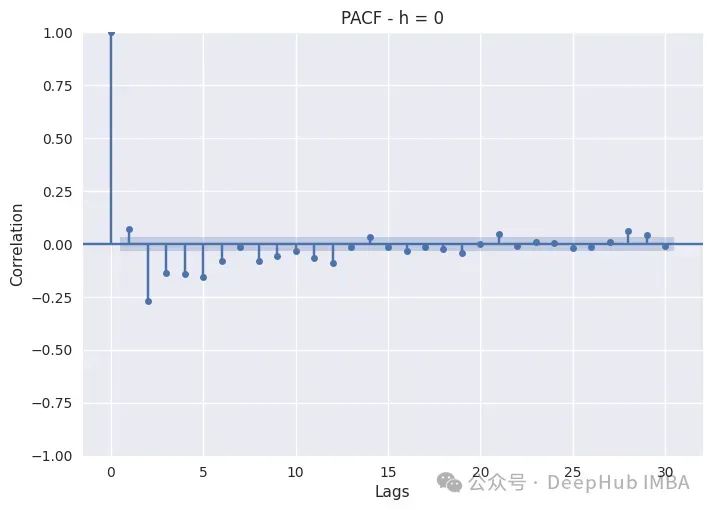

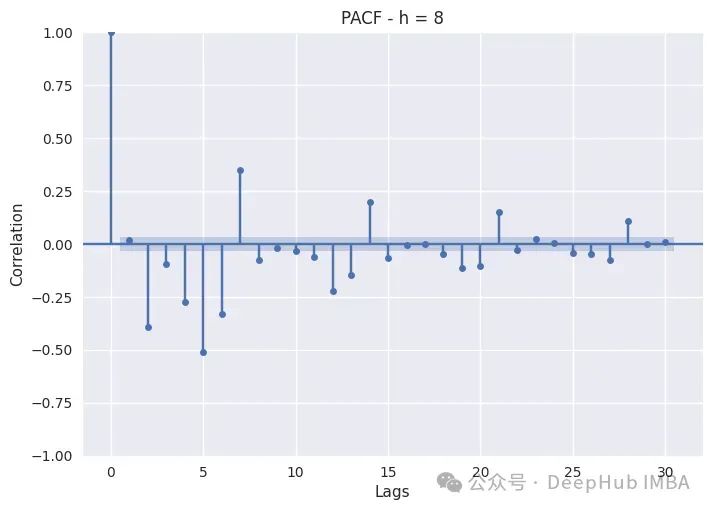
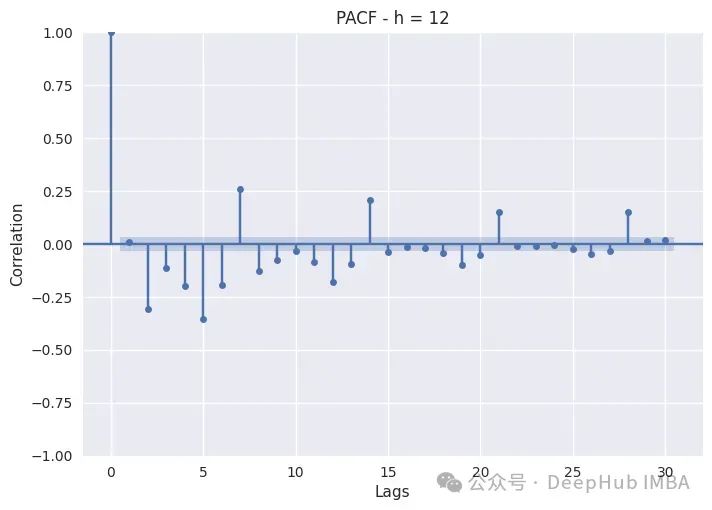
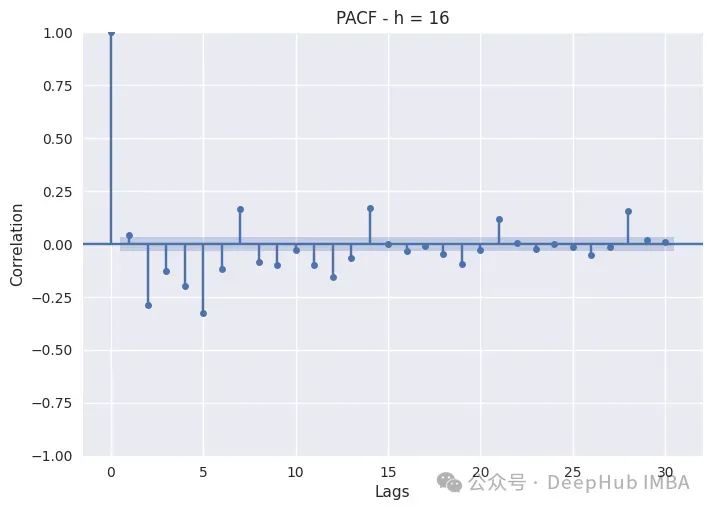
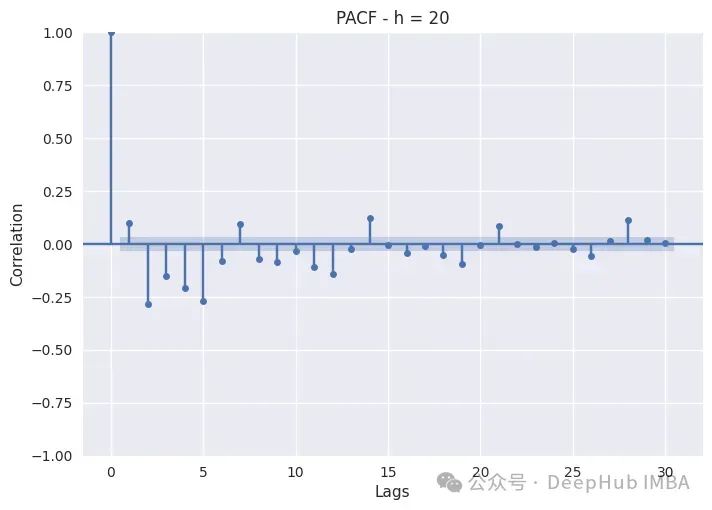
PACF只是绘制不同滞后的Pearson偏自相关系数。非滞后序列显示出与自身完美的自相关,因此滞后0将始终为1。蓝色带表示置信区间:如果滞后超过该带,则它具有统计显著性,我们可以断言它具有非常重要的意义。
工程特性
滞后分析是时间序列特征工程中最具影响力的研究之一。具有高相关性的滞后是序列中重要的特征,因此应该考虑在内。
一个广泛使用的特征工程技术是对数据集进行按小时划分。将数据分成24个子集,每个子集对应一天中的一个小时。这样做可以规范和平滑信号,使预测变得更简单。
然后应对每个子集进行特征工程、训练和微调。最终的预测将通过结合这24个模型的结果来实现。每个小时模型都有其特点,大多数将涉及重要的滞后。
我们简单介绍在进行滞后分析时可以处理的两种类型的滞后:
- 自回归滞后:接近滞后0的滞后,我们预期这些滞后值较高(最近的滞后更有可能预测当前值)。它们是序列显示趋势的表现。
- 季节性滞后:指季节周期的滞后。在按小时分割数据时,它们通常代表周度季节性。
自回归滞后1也可以被认为是序列的日度季节性滞后。
以我们看到的上图为例:
夜间时间(0,4)的消耗更多地依赖于自回归,而不是每周滞后,因为最相关的都在前五个小时。像7、14、21、28这样的季节似乎并不太重要,所以特征工程师时特别注意滞后1到滞后5。
白天时间(8,12,16,20)的消耗表现出自回归和季节性滞后。这在8小时和12小时尤其如此,因为这两个小时的消耗量特别高,而随着夜幕降临,季节性滞后变得不那么重要了。对于这些子集,我们还应该包括季节性滞后和自回归。
最后还有一些特征工程滞后的提示:
不要考虑太多的滞后,因为这可能会导致过度拟合。一般自回归滞后为1 ~ 7,周滞后为7、14、21、28。但并不是必须把它们都当作特征。
考虑非自回归或季节性的滞后通常是一个坏主意,因为它们也可能导致过拟合。
对滞后进行一些简单的转换通常可以产生更强大的特征。例如,季节性滞后可以使用加权平均值进行汇总,以创建代表该系列季节性的单个特征。
总结
本文的目的是为时间序列预测提供一个全面的探索性数据分析模板。
EDA是任何类型的数据科学研究的基本步骤,它允许理解数据的性质和特性,并为特征工程奠定基础,而特征工程反过来又可以显着提高模型性能。
我们描述了一些最常用的时间序列EDA分析,这些分析可以是统计/数学和图形。这项工作的目的只是提供一个实用的框架来开始,后续的调查需要根据所检查的历史系列的类型和业务背景进行。
数据集地址:
https://avoid.overfit.cn/post/a29fb376d9f145fcad2e9c82cea7ea51
作者:Maicol Nicolini





![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-15.6讲 GPIO中断实验-GPIO驱动添加中断处理函数](https://img-blog.csdnimg.cn/direct/4e2f4ef2de6d4ec3b75f70b6c63f79ec.png)