OpenAI 发布 ChatGPT-4o,意味着人机交互进入新的时代。Chat-GPT4o 是一个跨文本、视觉和音频端到端训练的新模型,所有输入和输出都由同一个神经网络处理。这也在告诉所有人,GenAI 连接非结构化数据,非结构化数据之间跨模态的交互正在变得越来越容易。
据 IDC 预测,到 2025 年,全球数据总量中将有超过 80% 的数据是非结构化数据,而向量数据库是处理非结构化数据的重要组件。回顾向量数据库的历史,2019 年,Zilliz 首次推出了 Milvus,提出了向量数据库的概念。2023 大语言模型(LLM)的爆火,将向量数据库正式从幕后被推到了台前,也因此赶上了发展的快速列车。
作为相关技术人员,我从技术发展上能清晰地感觉到向量数据库前进的速度,见证向量数据库如何逐渐从简单的 ANNS(https://zilliz.com.cn/glossary/%E8%BF%91%E4%BC%BC%E6%9C%80%E8%BF%91%E9%82%BB%E6%90%9C%E7%B4%A2%EF%BC%88anns%EF%BC%89) 套壳变得更加多变和复杂。今天,我想从技术的角度探讨一下向量数据库的发展方向。
技术的发展方向一定是跟随了产品的变化趋势,而后者则是由需求来决定。因此,顺着用户需求变化的脉络能帮我们找到技术变化的方向和目的。随着 AI 技术的日趋成熟,向量数据库的使用也逐渐从实验走到生产,从辅助产品走到主力产品,从小规模应用到大面积铺开。这产生大量不同的场景和问题,也同时推动了解决这些问题的相应技术。下面我们从成本和业务需求两个方面来展开讲述。
01.成本
AIGC 时代对于冷热储存的呼唤
成本一直是向量数据库获得更广泛使用的最大阻碍之一,这个成本来自两点:
-
储存,绝大多数向量数据库为了保证低延迟,需要把数据全量缓存到内存或者本地磁盘。在这个动辄百亿量级的AI 时代,意味着几十上百 TB 的资源消耗。
-
计算,数据需要划分成许多小片段来满足工程上分布式支持大规模数据集的需求。对于每个分片需要单独检索再做规避,带来了较大的查询计算放大问题。百亿级的数据如果按 10G 分片的话,会有一万个分片,也就意味着计算放大了一万倍。
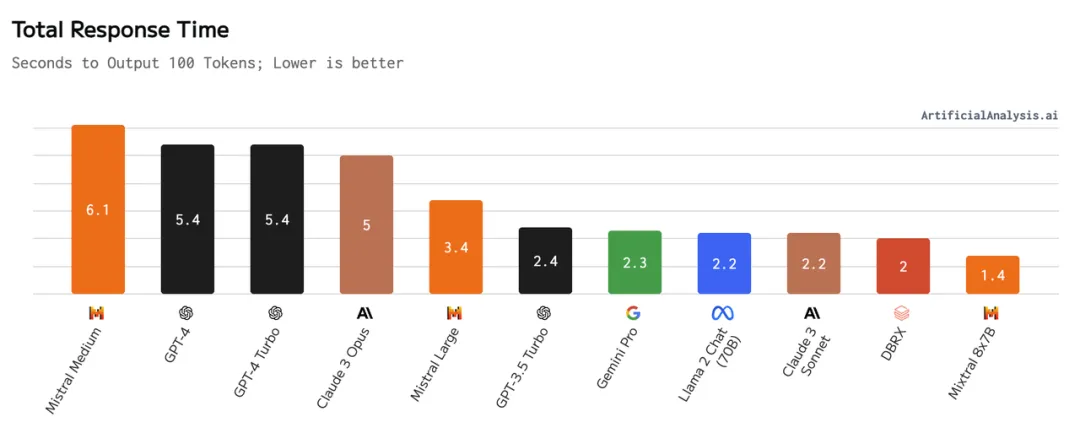 主流 LLM 的响应时间,图源:https://artificialanalysis.ai/models
主流 LLM 的响应时间,图源:https://artificialanalysis.ai/models
而在 AIGC 带来的 RAG 浪潮中,单个 RAG 用户(或者是 ToC 平台的单个 tenant)对于延迟的敏感度都极低。原因是相较于向量数据库几毫秒到几百毫秒的延迟,作为链路核心的大模型的延迟普遍超过秒级。加之云端对象储存的成本远远低于本地磁盘和内存,人们越来越需要一种技术,可以:
-
从储存上来看,在查询的时候数据放置在最便宜的云端对象作为冷存储,需要的时候加载到节点,转化为热储存提供查询。
-
从计算上来看,把每个查询需要的数据提前缩小范围,不用扩大到全局数据,保证热储存不会被击穿。
这种技术可以帮助用户在可接受的延迟下极大地缩减成本,也是我们 Zilliz Cloud (https://zilliz.com.cn/cloud)最近正准备推出的方案。
硬件迭代带来的机遇
硬件的是一切的基础,硬件的发展也直接决定了向量数据库技术发展的方向。如何去适配和在不同场景下利用这些硬件就成了一个很重要的发展方向。
-
高性价比的 GPU
向量检索是一个计算密集型的应用,这两年使用 GPU 进行计算加速的研究也越来越多。与昂贵的刻板印象相反的是,由于算法层面的逐渐成熟,加之向量检索场景适合内存延迟较低的且价格较为便宜的推理卡,基于 GPU 的向量检索展现出了出色的性价比。
 CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge Top 100 Recall: 98%
CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge Top 100 Recall: 98%
Dataset: https://github.com/zilliztech/VectorDBBench
我们使用支持了 GPU 索引的 Milvus 进行测试,在仅仅 2-3 倍的成本下,无论是构建索引还是向量检索,都展现出来了几倍到数十倍的性能差距。无论是支持高通量的场景,还是用以加速索引的构建,都能极大地降低向量数据库的使用成本。
-
日新月异的 ARM
各大云厂商基于ARM架构在不断地推出自己的 CPU,比如 AWS 的 Graviton,GCP 的 Ampere。我们在 AWS Graviton3 上做了相关测试,观察到相比 x86,在提供更加低价的硬件的同时还能带来更好的性能。而且这些 CPU 演进极快,比如在 2022 年推出 Graviton3 后,2023 年 AWS 发布了 30% 算力提升和 70% 内存带宽提升的 Graviton4(https://press.aboutamazon.com/2023/11/aws-unveils-next-generation-aws-designed-chips)。
-
强大的磁盘
将大部分数据储存在磁盘可以帮助向量数据库极大提高容量的同时达到百毫秒级别的延迟,而这个量级对大部分已经够用了,同时磁盘的成本是内存的几十甚至百分之一。
模型端的双向奔赴
模型产生向量,向量数据库支持向量的储存和查询。作为一个整体,除了向量数据库端在追求成本的降低外,模型端也在尝试降低向量的大小。
比如在向量的维度上,传统的在向量上引入的降维方案对于查询的准确度影响都比较大,而 OpenAI 发布的 ext-embedding-3-large (https://openai.com/index/new-embedding-models-and-api-updates/)模型可以通过参数控制输出向量的维度,在降低向量维度的同时,对下游任务的效果影响很小。还有在向量的数据类型上,Cohere 近期的博客(https://cohere.com/blog/int8-binary-embeddings)宣布了对于同时输出float,int8 和 binary 等数据类型的向量的支持。对于向量数据库来说,如何去适配这些改变也是需要积极去探索的方向。
02.业务需求
提升向量搜索准确程度
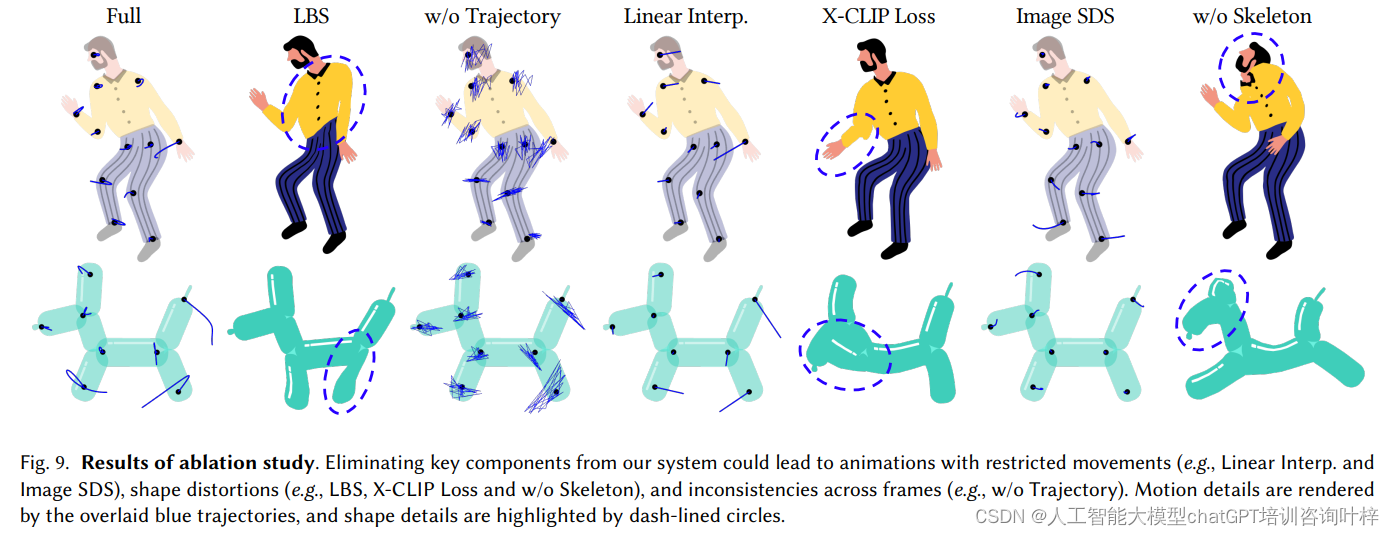
搜索的准确程度一直都是很重要的话题。无论是由于广泛的生产应用,还是 RAG 应用中对于相关性要求更高,向量数据库都在努力朝着更高的搜索质量发展。在这个过程中不断有新的技术涌现,比如为了解决 chunk 过大导致信息丢失的 ColBERT,还有解决域外信息检索的 Sparse。下图为 BGE 的 M3-Embedding 模型的评估结果,它能支持同时输出 Sparse、Dense 和 ColBERT 三种向量,表里为使用他们做 hybrid search 的搜索质量的对比结果。
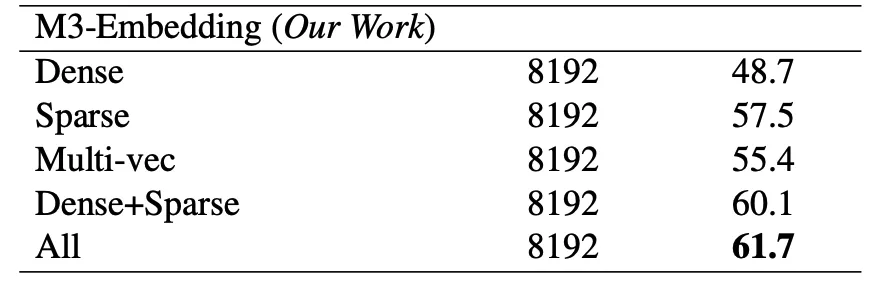
对于向量数据库来说,如何利用这些技术做混合搜索来提高检索质量也是重要的发展方向。
-
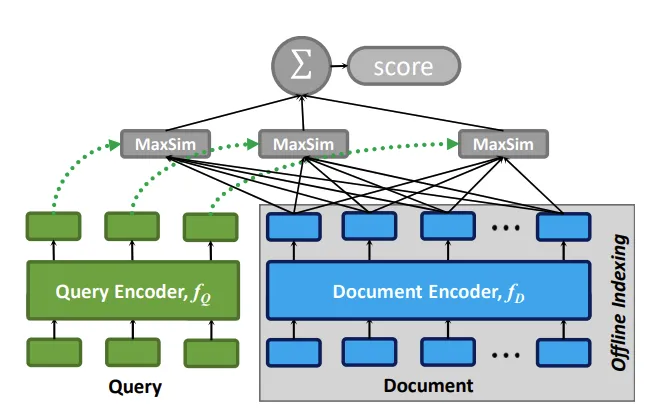
ColBERT
ColBERT 是一个检索模型,为了解决传统双塔模型大 chunk 导致的信息丢失问题,同时规避了常规检索模型全连接导致的搜索效率问题,ColBert 提出基于 token 向量的迟交互模式。ColBERTv2 中还引入了向量检索来加速最后的迟交互模式。
-
Sparse
传统的 dense 向量擅长捕捉语义信,但由于模型训练时只能学习训练数据中的知识,因此对于训练数据未覆盖的新词汇或专业术语,dense 向量的表达能力有限。而这在实际应用中很常见。一般模型微调能一定程度上解决这个问题,但是成本较高且实时性会面临挑战。
此时,基于传统关键词匹配的 BM25 生成的 sparse 向量反而表现出色。再有 SPLADE、BGE 的 M3-Embedding 等模型在保留 sparse 向量关键词匹配能力的同时,尝试把更多的信息编码进去,以进一步提高检索质量。
其实业界在基于关键词检索和向量检索的混合召回体系上已经应用了很久了。在向量数据库中集成新一代的 sparse 向量,并且支持混合检索能力也逐渐成为共识。Milvus 也在 2.4 版本正式支持了 sparse 向量的检索能力。
为离线场景进一步优化向量数据库
目前几乎所有的向量数据库都专注于在线的场景,包括 RAG(https://zilliz.com.cn/blog/ragbook-technology-development)、以图搜图(https://zilliz.com.cn/use-cases/image-similarity-search)等。
在线场景的特点是少量、高频,且对延迟有较高的要求。哪怕是成本最敏感,性能最不重要的场景往往也要求秒级别的延迟。
事实上,在许多大规模数据处理的离线场景中,向量检索扮演着重要角色。比如数据去重、特征挖掘等批处理任务,或者将向量相似性作为召回信号之一的搜推系统,通常会将向量检索作为离线预计算的环节,定期进行特征更新。这些离线场景的特点是批量查询、大量数据等,并且任务的耗时要求可能是分钟级甚至小时级。
为了支持好离线场景,向量数据库需要解决许多新的问题,试着举几个例子:
-
计算效率:很多离线场景需要高效地做对大量数据的大批量查询,比如一些搜推场景的离线计算部分。这种场景不要求单个数据的延迟,但是需要整体比在线场景更加高的计算效率。为了更好的支持这类问题,像GPU索引等提高计算密度的能力需要被支持。
-
大量返回:数据挖掘经常使用向量检索来帮助模型找到某一个类型的场景。这通常会需要返回大量数据,如何处理这些返回结果带来的带宽问题、大topK搜索的算法效率问题都是支持这类场景的关键。
如果能够解决上述这几点挑战,向量数据库能够广泛支持更多场景的应用,而非仅仅满足在线应用。
更丰富的向量数据库特性适应更多行业需求
随着向量数据库被越来越广泛地应用在生产端,产生了许多不同的使用方法,也被应用在了不同的行业。这些和行业、具体场景高度相关的需求指导向量数据库去支持越来越多的features。
-
生物制药行业:通常用 Binary 向量表达药物分子式进行检索。
-
风控行业:需要找到最离群的向量,而不是最相似的向量。
-
Range Search 功能:允许用户设定一个相似度阈值,返回相似度高于该阈值的所有结果。它可以在无法预估结果数量的情况下,确保返回的结果都具有较高的相关性。
-
Groupby 和 Aggregation 功能:对于较大对非结构化数据(电影、文章),我们通常分段生产向量,比如一帧画面、一段文字。为了能通过这些分段向量搜到符合要求的结果,向量数据库需要支持 Groupby 和对结果做 Aggregation 的能力。
-
支持多模态模型:模型向多模态发展的趋势会产生不同分布的向量,在现有的算法下难以满足检索需求。
上述这些面向各个行业的改进功能更突出了向量数据库动态发展的特点。向量数据库将不断升级优化,推出更丰富的特性以满足各行各业 AI 应用的复杂需求。
03.总结
向量数据库在过去的一年经历了快速成熟的过程,无论从使用场景到向量数据库自身能力都有了很大的发展。在越来越清晰可见的 AI 时代里,这个趋势只会越来越快。希望这些个人的总结和分析能够抛砖引玉,为向量数据库的发展提供一些思路和启发,一起拥抱未来更加激动人心的变化。
阅读原文
-
好消息,Milvus 社区正全网寻找「 北辰使者」!!! • -
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 • -
欢迎关注微信公众号“Zilliz”,了解最新资讯。
本文由 mdnice 多平台发布




![[Bootloader][uboot]code总结](https://img-blog.csdnimg.cn/direct/14408d46114b497998f3590c131f9e42.png)