目录
前言
一、MyDataset文件
二、完整代码:
三、结果展示:
四、添加accuracy值
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
本周的学习内容是,使用pytorch实现车牌识别。
前言
之前的案例里面,我们大多是使用的是datasets.ImageFolder函数,直接导入已经分类好的数据集形成Dataset,然后使用DataLoader加载Dataset,但是如果对无法分类的数据集,我们应该如何导入呢。
这篇文章主要就是介绍通过自定义的一个MyDataset加载车牌数据集并完成车牌识别。
一、MyDataset文件
数据文件是这样的,没有进行分类的。

# 加载数据文件
class MyDataset(data.Dataset):
def __init__(self, all_labels, data_paths_str, transform):
self.img_labels = all_labels # 获取标签信息
self.img_dir = data_paths_str # 图像目录路径
self.transform = transform # 目标转换函数
def __len__(self):
return len(self.img_labels) # 返回数据集的长度,即标签的数量
def __getitem__(self, index):
image = Image.open(self.img_dir[index]).convert('RGB') # 打开指定索引的图像文件,并将其转换为RGB模式
label = self.img_labels[index] # 获取图像对应的标签
if self.transform:
image = self.transform(image) # 如果设置了转换函数,则对图像进行转换(如,裁剪、缩放、归一化等)
return image, label # 返回图像和标签二、完整代码:
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import torch
from PIL import Image
from torch import nn
from torch.utils import data
from torchvision import transforms
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib as mpl
mpl.use('Agg') # 在服务器上运行的时候,打开注释
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
data_dir = './data'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split('/')[1].split('_')[1].split('.')[0] for path in data_paths]
# print(classNames) # '沪G1CE81', '云G86LR6', '鄂U71R9F', '津G467JR'....
data_paths_str = [str(path) for path in data_paths]
# 数据可视化
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(14,5))
plt.suptitle('data show', fontsize=15)
for i in range(18):
plt.subplot(3, 6, i+1)
# 显示图片
images = plt.imread(data_paths_str[i])
plt.imshow(images)
plt.show()
# 3、标签数字化
char_enum = ["京","沪","津","渝","冀","晋","蒙","辽","吉","黑","苏","浙","皖","闽","赣","鲁","豫","鄂","湘","粤","桂","琼","川","贵","云","藏","陕","甘","青","宁","新","军","使"]
number = [str(i) for i in range(0, 10)] # 0-9 的数字
alphabet = [chr(i) for i in range(65, 91)] # A到Z的字母
char_set = char_enum + number + alphabet
char_set_len = len(char_set)
label_name_len = len(classNames[0])
# 将字符串数字化
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
all_labels = [text2vec(i) for i in classNames]
# 加载数据文件
class MyDataset(data.Dataset):
def __init__(self, all_labels, data_paths_str, transform):
self.img_labels = all_labels # 获取标签信息
self.img_dir = data_paths_str # 图像目录路径
self.transform = transform # 目标转换函数
def __len__(self):
return len(self.img_labels)
def __getitem__(self, index):
image = Image.open(self.img_dir[index]).convert('RGB')
label = self.img_labels[index] # 获取图像对应的标签
if self.transform:
image = self.transform(image)
return image, label # 返回图像和标签
total_datadir = './data/'
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
total_data = MyDataset(all_labels, data_paths_str, train_transforms)
# 划分数据
train_size = int(0.8*len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data,[train_size, test_size])
print(train_size, test_size) # 10940 2735
# 数据加载
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=16, shuffle=True)
for X, y in test_loader:
print('Shape of X [N,C,H,W]:',X.shape) # ([16, 3, 224, 224])
print('Shape of y:', y.shape, y.dtype) # torch.Size([16, 7, 69]) torch.float64
break
# 搭建网络模型
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2, 2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24 * 50 * 50, label_name_len * char_set_len)
self.reshape = Reshape([label_name_len, char_set_len])
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24 * 50 * 50)
x = self.fc1(x)
# 最终reshape
x = self.reshape(x)
return x
class Reshape(nn.Module):
def __init__(self,shape):
super(Reshape, self).__init__()
self.shape = shape
def forward(self, x):
return x.view(x.size(0), *self.shape)
model = Network_bn().to(device)
print(model)
# 优化器与损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=0.0001)
loss_model = nn.CrossEntropyLoss()
def test(model, test_loader, loss_model):
size = len(test_loader.dataset)
num_batches = len(test_loader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in test_loader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_model(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
print(f'Avg loss: {test_loss:>8f}\n')
return correct, test_loss
def train(model,train_loader, loss_model, optimizer):
model = model.to(device)
model.train()
for i, (images, labels) in enumerate(train_loader, 0): # 0 是标起始位置的值
images = Variable(images.to(device))
labels = Variable(labels.to(device))
optimizer.zero_grad()
outputs = model(images)
loss = loss_model(outputs, labels)
loss.backward()
optimizer.step()
if i % 100 == 0:
print('[%5d] loss: %.3f' % (i, loss))
# 模型的训练
test_acc_list = []
test_loss_list = []
epochs = 30
for t in range(epochs):
print(f"Epoch {t+1}\n-----------------------")
train(model,train_loader, loss_model,optimizer)
test_acc,test_loss = test(model, test_loader, loss_model)
test_acc_list.append(test_acc)
test_loss_list.append(test_loss)
print('Done!!!')
# 结果分析
x = [i for i in range(1,31)]
plt.plot(x, test_loss_list, label="Loss", alpha = 0.8)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.savefig("/data/jupyter/deep_demo/p10_car_number/resultImg.jpg") # 保存图片在服务器的位置
plt.show()三、结果展示:



总结:从刚开始损失为0.077 到,训练30轮后,损失到了0.026。
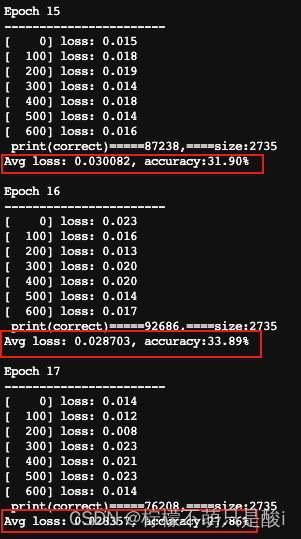
四、添加accuracy值
需求:对在上面的代码中,对loss进行了统计更新,请补充acc统计更新部分,即获取每一次测试的ACC值。
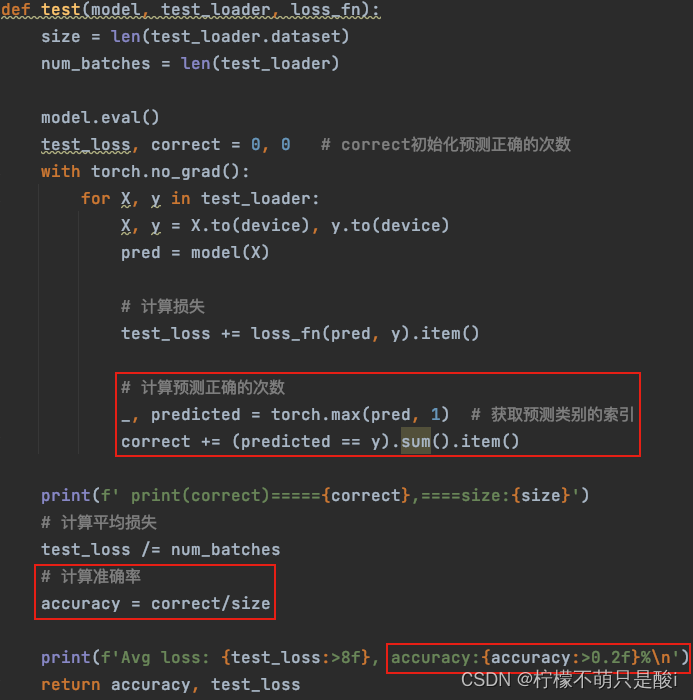
添加accuracy的运行过程: