目录
RAG概述
RAG架构
Trieve
Trieve介绍
Trieve使用
初始化
自行搭建RAG
Trieve是什么,RAG是什么,本文来带你了解。其实在很多产品应用里面都会有RAG,比如ai客服,针对性的智能问答,都是基于RAG实现的
RAG概述
RAG 是一种使用额外数据增强 LLM 知识的技术。
LLM 可以对广泛的主题进行推理,但他们的知识仅限于他们接受培训的特定时间点之前的公共数据。如果要构建可以推理私有数据或模型截止日期后引入的数据的 AI 应用程序,则需要使用模型所需的特定信息来增强模型的知识。引入适当信息并将其插入模型提示符的过程称为检索增强生成 (RAG)。
如果用白话来说,就是ai+数据知识库
RAG架构
典型的 RAG 应用程序有两个主要组件:
索引:用于从源引入数据并对其进行索引的管道。这通常发生在离线状态。
检索和生成:实际的 RAG 链,它在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型。
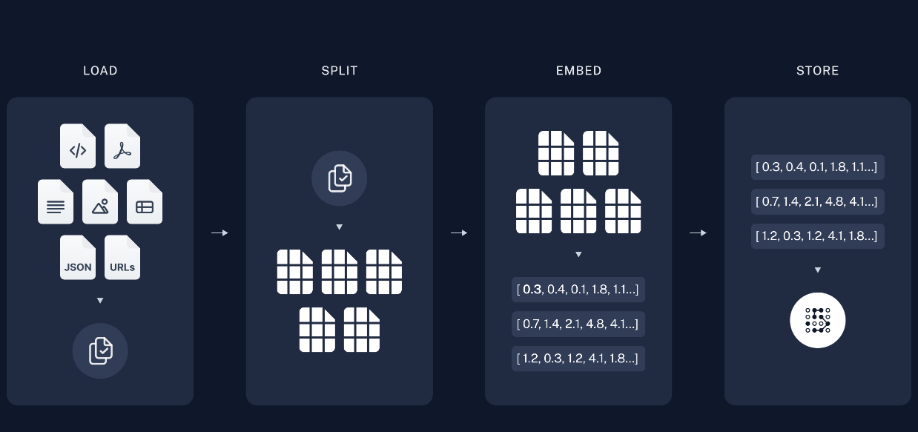
从原始数据到答案最常见的完整序列如下所示:
索引
- 加载:首先我们需要加载数据。这是使用 DocumentLoaders 完成的。
- 拆分:文本拆分器将大块拆分为更小的块。这对于索引数据和将数据传递到模型都很有用,因为大块更难搜索,并且不适合模型的有限上下文窗口。Documents
- 存储:我们需要某个地方来存储和索引我们的拆分,以便以后可以搜索它们。这通常是使用 VectorStore 和 Embeddings 模型完成的。
检索和生成
- 检索:给定用户输入,使用 Retriever 从存储中检索相关拆分。
- 生成:ChatModel / LLM 使用包含问题和检索数据的提示生成答案
Trieve
Trieve介绍
Trieve是RAG的一个开源的实现项目, 是一个用于将 AI 搜索构建到应用程序中的基础设施。Trieve 将强大的语言模型与人类微调工具相结合。在单个服务中获取密集向量语义搜索、稀疏向量全文搜索、交叉编码器重新排名模型、RAG 端点、相关性加权等功能。开源地址:https://github.com/devflowinc/trieve
Trieve使用
Trieve是一个小公司开发的开源项目,目前来看github上部署流程还不是很完善,如果需要使用需要阅读代码后自行部署。或者联系官方获取支持,可以获得官方的docker运行。
当然本文主要介绍如何在Trieve官方的平台去试用RAG搜索功能。RAG核心其实就是llm+自有数据
初始化
Trieve Dashboard 在trieve官方平台注册一个账号,进来后可以看到Datasets这里就是数据集,把我们要的知识库在这里上传即可
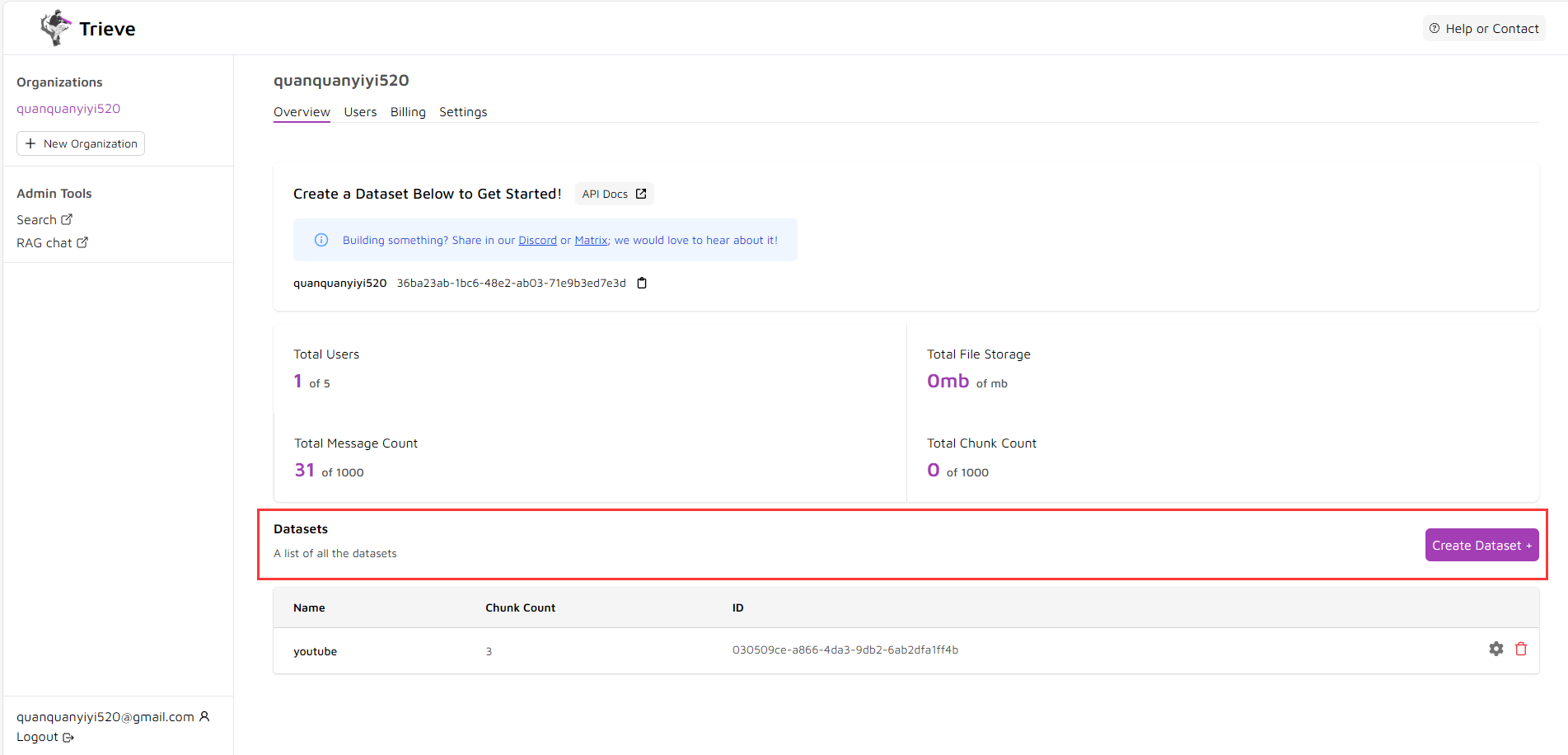
可以看到这里需要输入数据集的一个名字,然后选择Embedding Model,为了测试方便可以直接用openai的。如果小伙伴还不知道Embedding Model的作用,可以去网上搜索一下

这里我创建了一个叫youtube的集合。那么如何上传数据到这个集合呢?
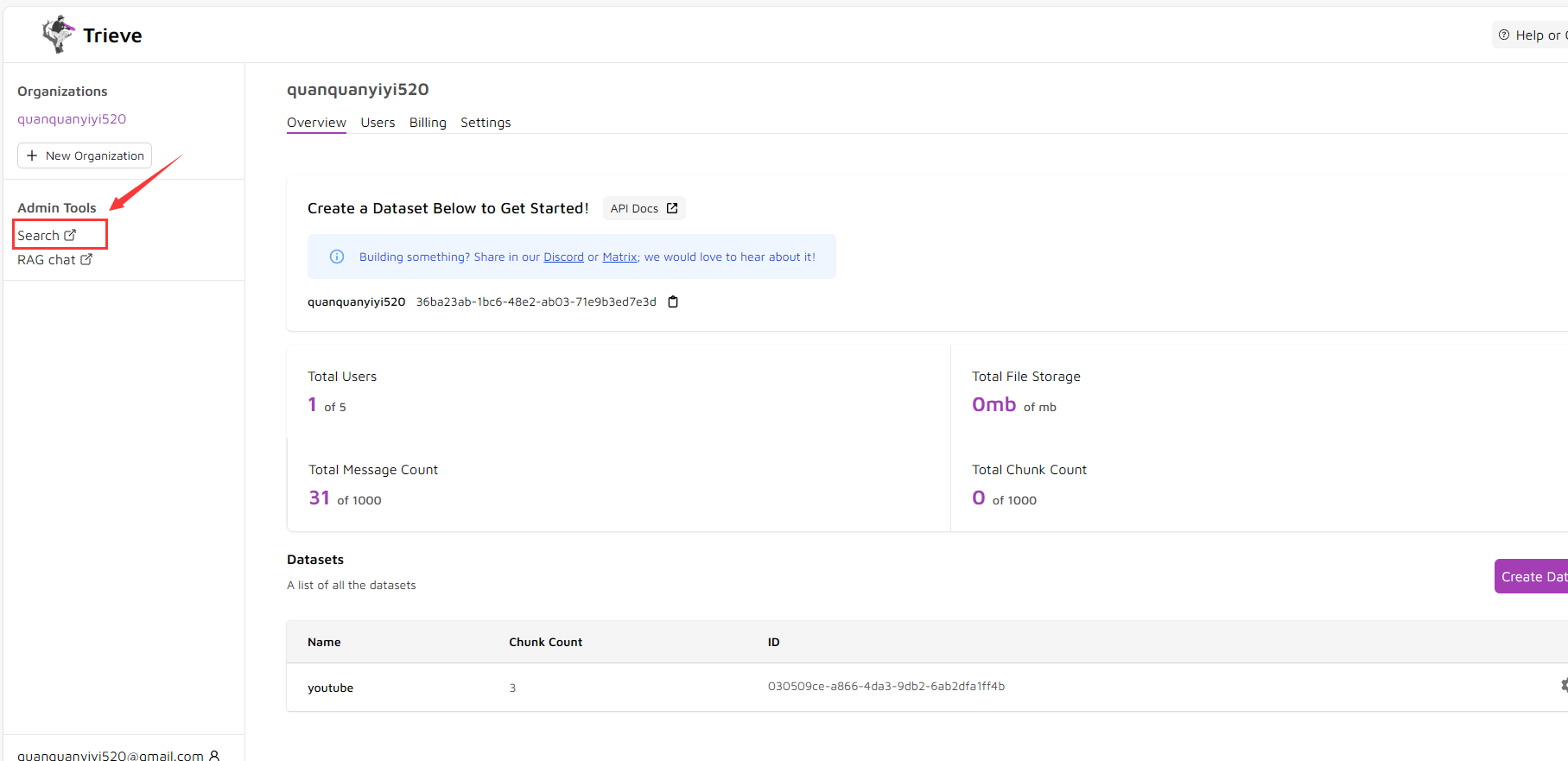
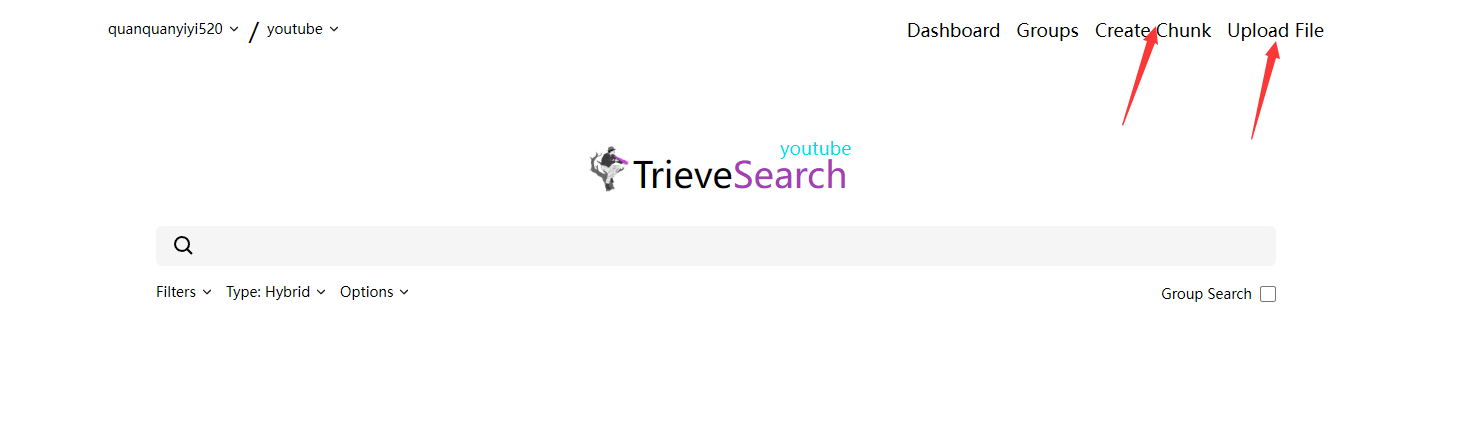
点击这个search,会发现上面有两个模块,Create Chunk和Upload File,Create Chunk是可以直接创建一个块,也就是RAG介绍里面拆分的块,然后Upload File是可以直接上传一个大文件,然后trieve用默认的拆分段落给你拆分块
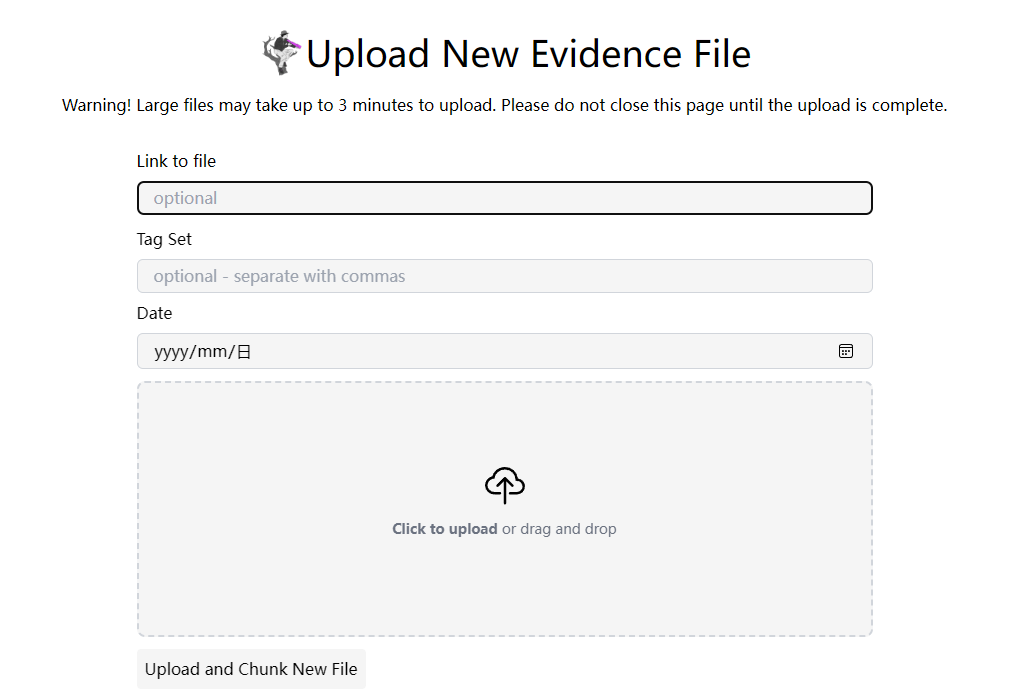
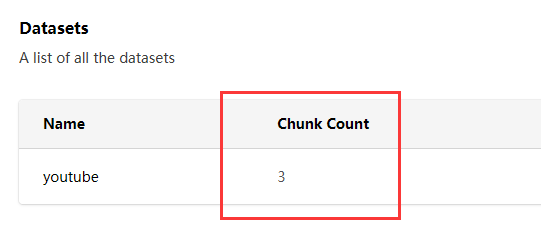
上传完数据块或者文件后,过一段时间,会在我们的数据集这里看见区块增加了,这时候就可以搜索或者提问了。
点击左侧栏目的RAG chat,然后左下角选择你对应的知识库集合。就可以提问了,这个提问一般来说是chatgtp根据你的数据集来回答的,会比直接问chatgpt会好很多,一般客服系统什么的就是基于这个做的
自行搭建RAG
自行搭建一个RAG也很简答,一般用python的LangChain框架来做。这个是官网https://python.langchain.com/,安卓官网的介绍来就可以了