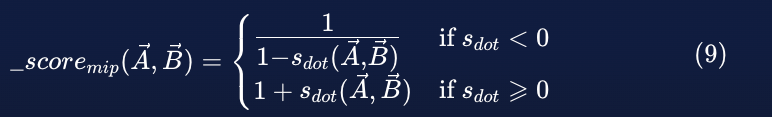北京时间5月14日1点整,OpenAI 召开了首场春季发布会,CTO Mira Murati 在台上和团队用短短不到30分钟的时间,揭开了最新旗舰模型 GPT-4o 的神秘面纱,以及基于 GPT-4o 的 ChatGPT,均为免费使用。
本文内容来自OpenAI网站对GPT-4o的详细介绍
我们宣布推出GPT-4o,这是我们的新型旗舰模型,可以在音频、视觉和文本之间进行实时推理。
GPT-4o(“o”代表“omni”)是实现更为自然人机交互的重要一步——它接受文本、音频、图像和视频任意组合的输入,并生成文本、音频和图像输出的任意组合。它可以在短至232毫秒内对音频输入做出响应,平均响应时间为320毫秒,这与人类在对话中的响应时间相似(新窗口中打开)。它在英语文本和代码方面与GPT-4 Turbo性能相匹配,在非英语文本方面有显著提升,同时在API中速度更快,成本降低了50%。与现有模型相比,GPT-4o在视觉和音频理解方面尤其出色。
在GPT-4o之前,您可以使用语音模式与ChatGPT进行对话,GPT-3.5和GPT-4的平均延迟分别为2.8秒和5.4秒。为了实现这一点,语音模式由三个单独的模型组成:一个简单模型将音频转录为文本,GPT-3.5或GPT-4接收文本并输出文本,第三个简单模型将该文本转换回音频。这个过程意味着,智能的主要来源GPT-4会丢失大量信息——它无法直接观察到语调、多个说话者或背景噪音,也无法输出笑声、歌声或表达情感。
通过GPT-4o,我们训练了一个单一的跨文本、视觉和音频的端到端新模型,这意味着所有的输入和输出都由同一个神经网络处理。由于GPT-4o是我们第一个结合所有这些模式的模型,我们仍在探索该模型能够做什么以及其局限性。
根据传统基准测试的结果,GPT-4o在文本、推理和编码智能方面达到了GPT-4 Turbo级别的性能,同时在多语言、音频和视觉能力方面创下了新的高标准。

改进推理能力 - GPT-4o在0次推理链MMLU(常识性问题)上创下了88.7%的新高分。所有这些评估都是通过我们新的简单评估库收集的。此外,在传统的5次无推理链MMLU上,GPT-4o创下了87.2%的新高分。(注:Llama3 400b仍在训练中)

音频ASR(自动语音识别)性能 - GPT-4o在所有语言上的语音识别性能都显著优于Whisper-v3,尤其是对于资源较少的语言。

音频翻译性能——GPT-4o在语音翻译方面树立了新的技术标杆,并在MLS基准测试中表现优于Whisper-v3。

M3Exam——M3Exam基准测试既是一项多语言评估,也是一项视觉评估,它包括来自其他国家标准化测试中的多项选择题,这些题目有时会包含图表和图示。GPT-4o在这个基准测试上的所有语言表现都优于GPT-4。(我们省略了斯瓦希里语和爪哇语的视觉结果,因为这些语言的视觉问题只有5个或更少。

视觉理解评估——GPT-4o在视觉感知基准测试中取得了最先进的性能。所有的视觉评估都是0次推理,其中MMMU、MathVista和ChartQA为0次推理链。
语言标记化
选择这20种语言是为了代表新标记器在不同语系中的压缩性
模型的安全性和局限性
GPT-4o在设计时就内置了跨模态的安全性,通过筛选训练数据和训练后精炼模型行为等技术来实现。我们还创建了新的安全系统,为语音输出提供保护。
我们根据我们的准备框架和自愿承诺对GPT-4o进行了评估。我们对网络安全、CBRN、说服力和模型自主性的评估表明,GPT-4o在这些类别中的任何一个都没有超过中等风险。这一评估涉及在整个模型训练过程中运行一套自动化和人工评估。我们测试了模型的安全缓解前和安全缓解后的版本,使用自定义的微调和提示,以更好地发挥模型的能力。
GPT-4o还经过了70多名外部专家的广泛外部红队测试,这些专家来自社会心理学、偏见和公平性以及虚假信息等领域,以识别新增模态引入或放大的风险。我们利用这些经验来建立我们的安全干预措施,以提高与GPT-4o交互的安全性。我们将继续缓解新发现的风险。
我们认识到,GPT-4o的音频模态带来了各种新的风险。今天,我们公开发布了文本和图像输入以及文本输出。在接下来的几周和几个月里,我们将致力于技术基础设施、训练后的可用性和发布其他模态所必需的安全性。例如,在发布时,音频输出将仅限于一组预设的声音,并将遵守我们现有的安全政策。我们将在即将发布的系统卡中分享更多关于GPT-4o全模态的详细信息。
通过我们对模型的测试和迭代,我们观察到了模型所有模态中存在的几个局限性,其中一些如下所示。
我们非常希望收到反馈,以帮助识别GPT-4 Turbo仍然优于GPT-4o的任务,这样我们可以继续改进模型。
模型可用性
GPT-4o是我们在深度学习领域推动边界的最新一步,这次是在实际可用性的方向上。在过去两年中,我们花费了大量精力改进堆栈每一层的效率。作为这项研究的第一个成果,我们能够更广泛地提供一个GPT-4级别的模型。GPT-4o的功能将迭代推出(从今天起扩大红队访问权限)。
GPT-4o的文本和图像功能今天开始在ChatGPT中推出。我们在免费层中提供GPT-4o,并为Plus用户提供高达5倍的信息限制。在未来几周内,我们将在ChatGPT Plus中以alpha版本推出带有GPT-4o的新版语音模式。
开发人员现在还可以通过API作为文本和视觉模型访问GPT-4o。与GPT-4 Turbo相比,GPT-4o的速度快2倍,价格低一半,并且速率限制高5倍。我们计划在未来几周内通过API向一小群可信赖的合作伙伴推出对GPT-4o新的音频和视频功能的支持。