在机器学习中,为了评估模型的性能,我们通常会将数据集划分为训练集(Training Set)、验证集(Validation Set)和测试集(Test Set)。这种划分有助于我们更好地理解模型在不同数据上的表现,并据此调整模型参数,避免过拟合和欠拟合。本文将详细介绍这三个集合的作用,并通过代码演示如何进行数据集的划分。
目录
一、训练集、验证集与测试集的作用
二、为什么需要这样的划分
三、如何划分数据集
四、注意事项
五、总结

一、训练集、验证集与测试集的作用
-
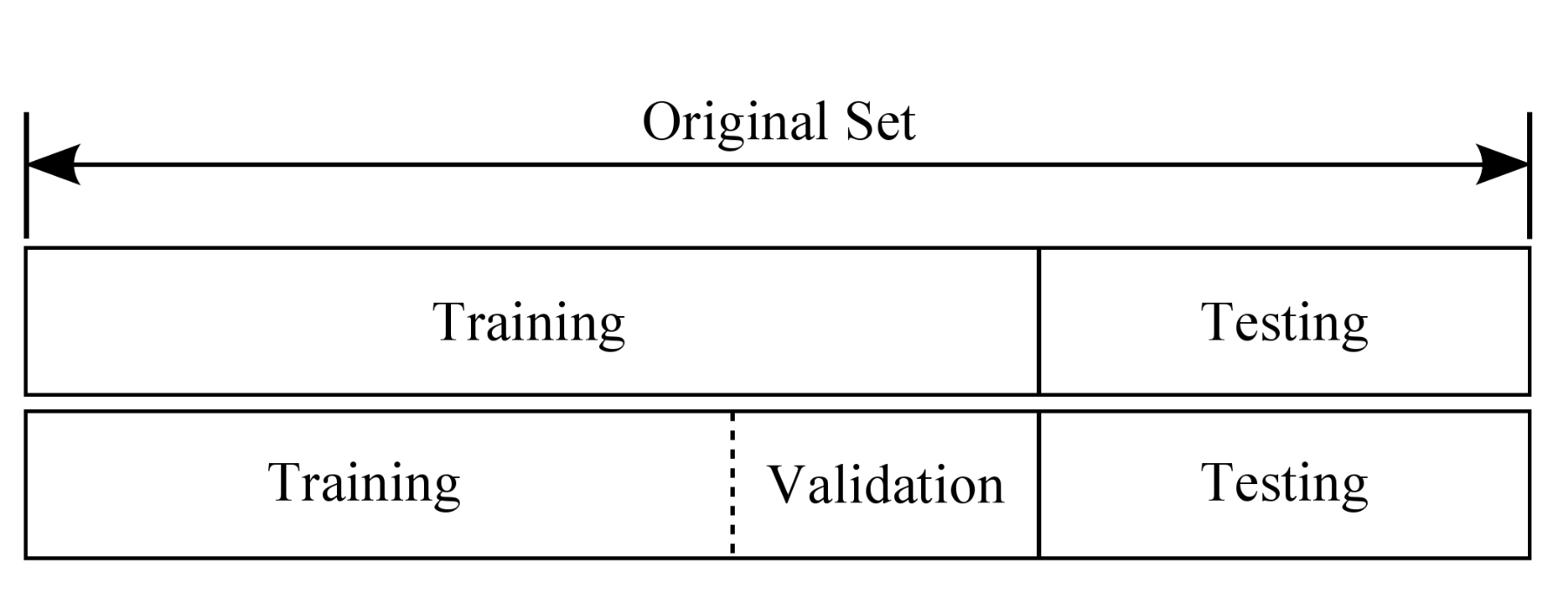
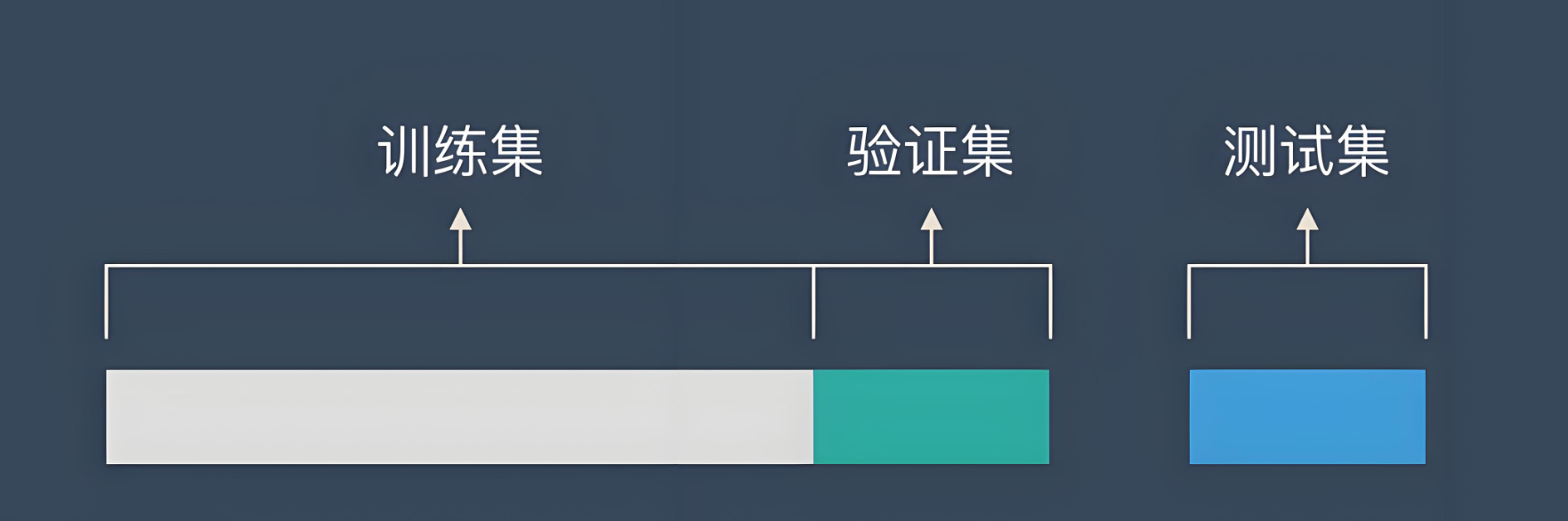
训练集(Training Set):
- 用于训练模型,即调整模型的参数以拟合数据。
- 通常占整个数据集的70%左右。
-
验证集(Validation Set):
- 用于在训练过程中评估模型的性能,帮助调整超参数和防止过拟合。
- 通常占整个数据集的15%左右。
-
测试集(Test Set):
- 用于评估训练完成的模型在未见过的数据上的性能。
- 通常占整个数据集的15%左右。
二、为什么需要这样的划分
- 通过将数据集划分为不同的部分,我们可以更准确地评估模型的泛化能力,即模型对未见过的数据的预测能力。
- 训练集用于训练模型,验证集用于调整模型参数和超参数,测试集则用于评估模型的最终性能。
三、如何划分数据集
在Python中,我们可以使用sklearn.model_selection库中的train_test_split函数来划分数据集。以下是一个简单的示例:
from sklearn.model_selection import train_test_split
import numpy as np
# 假设 X 是特征数据,y 是标签数据
X, y = np.arange(10).reshape((5, 2)), range(5)
# 首先将数据集划分为训练集和测试集,测试集大小为20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 然后将训练集进一步划分为实际的训练集和验证集,验证集大小为训练集的20%
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
print("训练集特征:", X_train)
print("训练集标签:", y_train)
print("验证集特征:", X_val)
print("验证集标签:", y_val)
print("测试集特征:", X_test)
print("测试集标签:", y_test)四、注意事项
- 数据集的划分应该具有代表性,即各集合中的数据分布应该与原始数据集相似。
- 为了避免数据泄露,验证集和测试集的数据在训练过程中应该是不可见的。
- 可以使用交叉验证(Cross-validation)等技术来更准确地评估模型性能。
五、总结
训练集、验证集和测试集的合理划分是机器学习模型评估的关键步骤。通过这三个集合,我们可以更全面地了解模型的性能,并据此进行优化。在实际应用中,我们应该根据具体问题和数据集的特点来选择合适的划分比例和方法。