参考视频:https://www.bilibili.com/video/BV1aP4y147gA/?p=2&spm_id_from=pageDriver&vd_source=7a1a0bc74158c6993c7355c5490fc600
(这实际上是 “序列标注任务”)
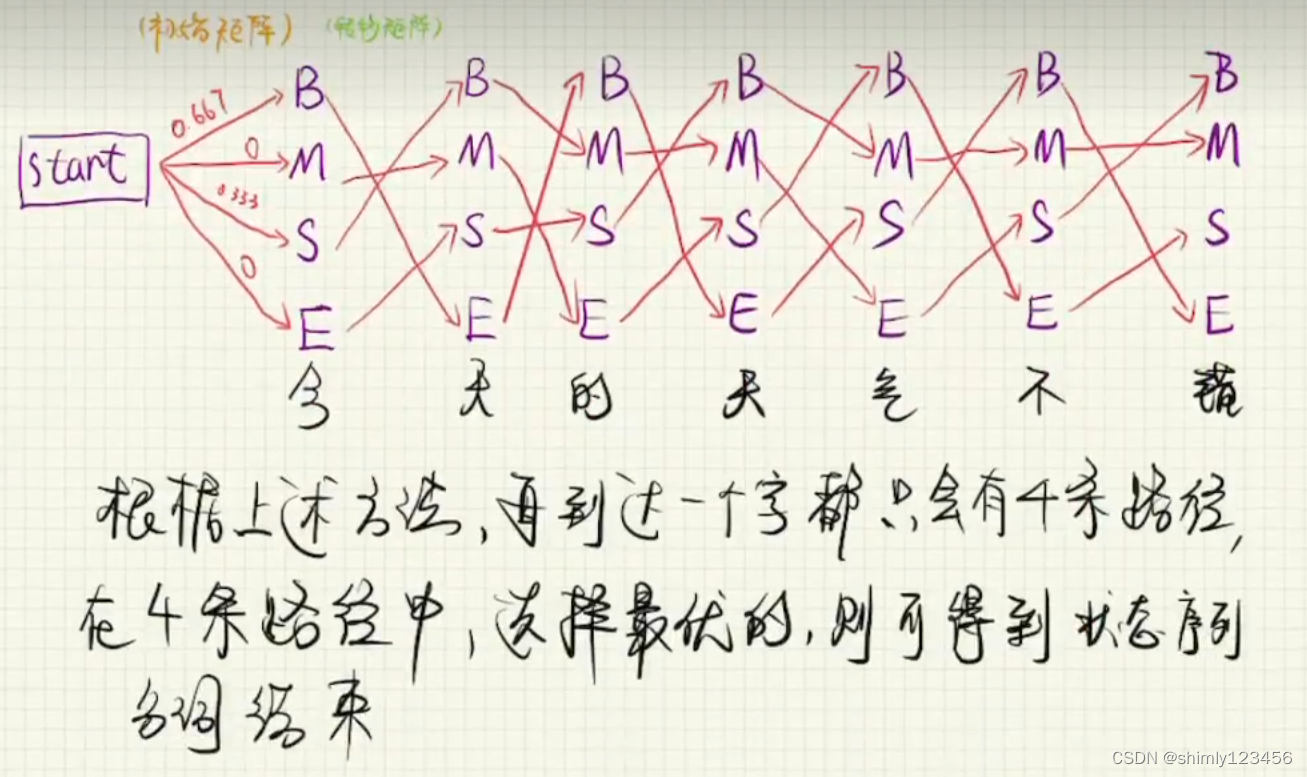
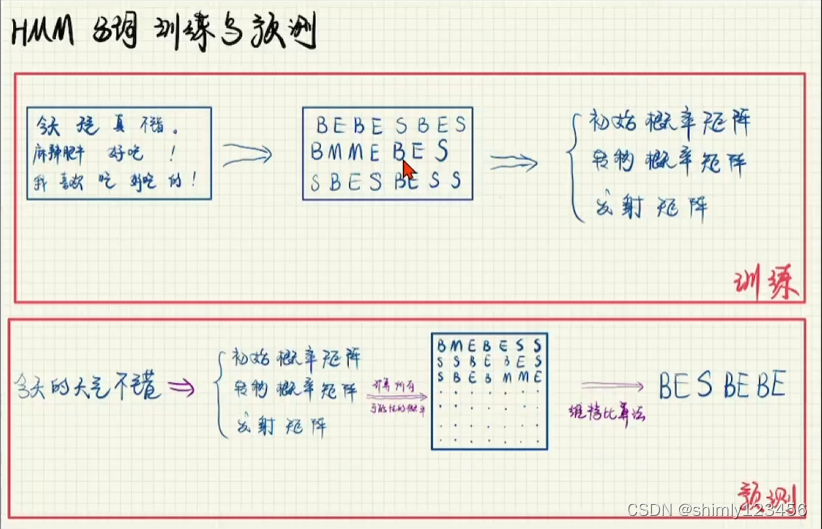
HMM 的训练和预测如下图
训练过程:我们首先先给出一个语料文本,这个语料文本每个词组都分配了一个“词性”。在训练过程中,我们会得到三个矩阵,分别是,1.初始概率矩阵 2.转移概率矩阵 3.发射矩阵
预测过程:给出 “今天的天气不错” 作为输入,发给三个矩阵,这三个矩阵最终输出一个标注序列
我们先来看看三个矩阵是怎么训练/计算出来的
首先是初始矩阵,我们会统计每篇文章第一个字的词性
语料库一共三句话,分别是:
1.今天 天气 真 不错 。 B E B E S B E S
2.麻辣肥牛 好吃 ! B M M E B E S
3.我 喜欢 吃 好吃 的 ! S B E S BE S S
经过统计,有两个 B 和一个 S,经过正则化,概率分别是 0.667 和 0.333

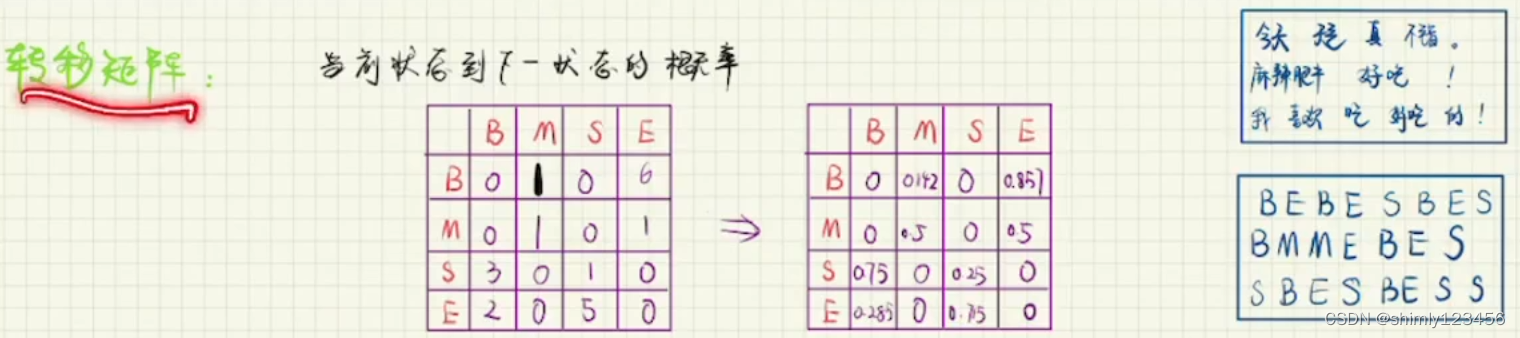
接下来我们看转移矩阵,我们统计每一个词性的 next property,随后画出转移矩阵
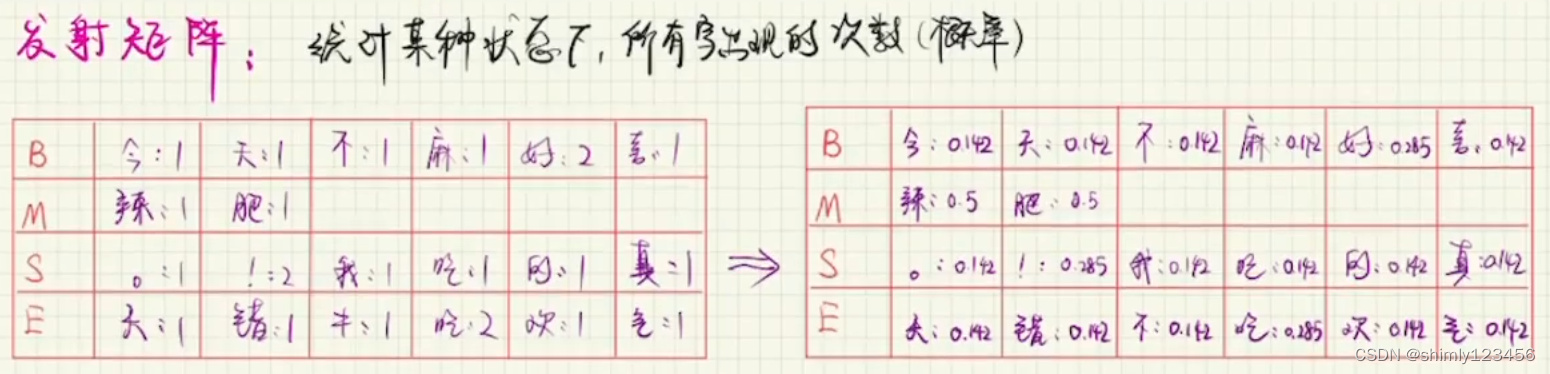
最后是发射矩阵,我们统计每一个词性对应的单词(字)概率,如下图
接下来,我们再看看得到这三个矩阵后,如何使用
这里长度为 7,一共有 4^7 条路径,我们选择其中一条最优路径作为最终结果
但这种选最优的方法的计算复杂度是随着文本长度呈指数增长的,我们需要更好的算法,比如 维特比算法
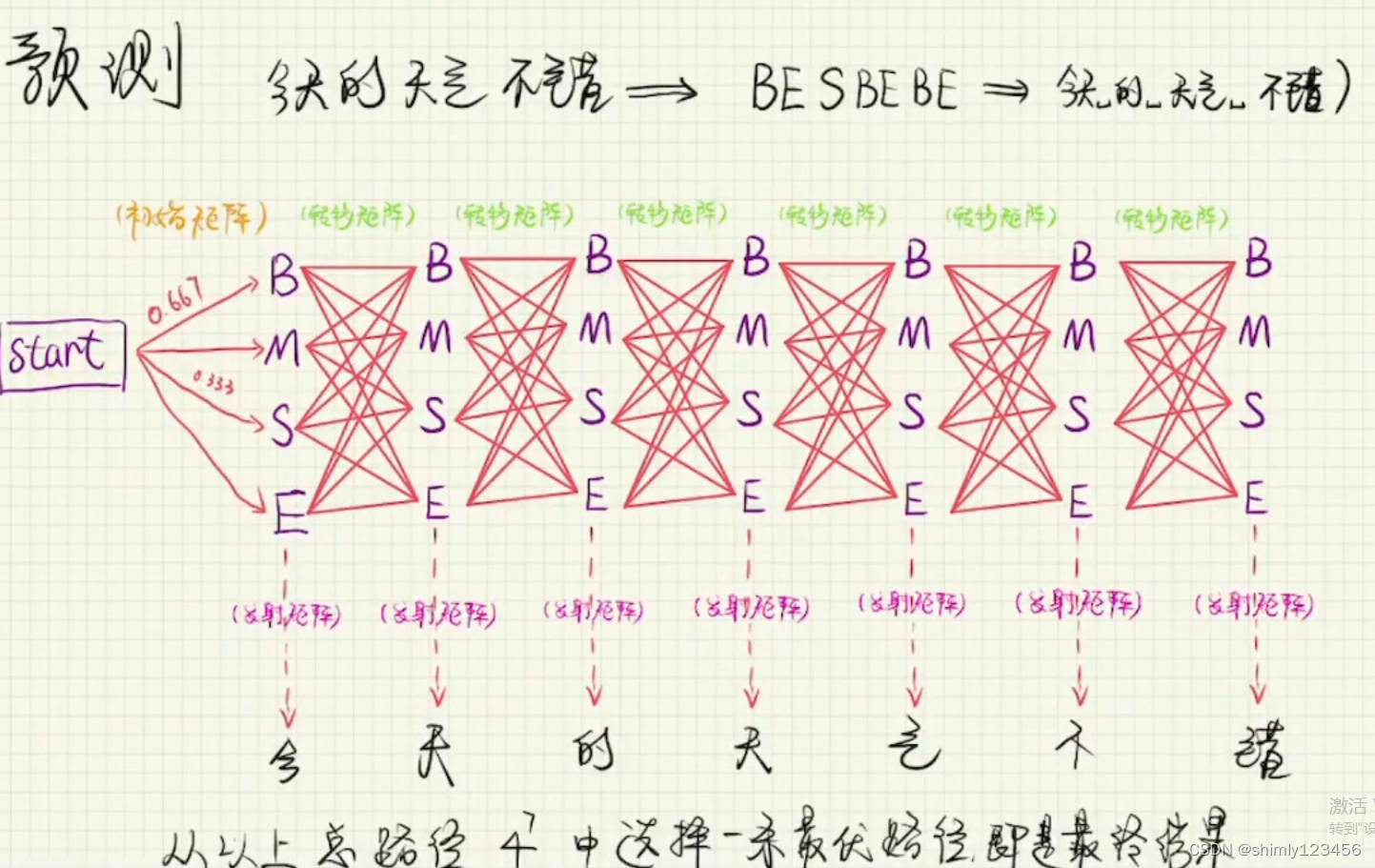
维特比算法:其实就是不断剪枝,每一个全连接层只保留最优的四条路径,直到最后。这样最终得到的路径只有四条。
最后在这四条里选择最优的路径