关注微信公众号 “程序员小胖” 每日技术干货,第一时间送达!
引言
在构建大型分布式系统时,数据一致性是我们必须面对的挑战之一。随着业务的增长和系统规模的扩大,如何保证在多个节点间复制的数据保持一致,成为了一个关键问题。Zab一致性协议,专为解决这一问题而生,它为分布式协调服务ZooKeeper提供了数据一致性保障。
Zab 一致性协议
ZAB协议是一种基于领导者(Leader)和跟随者(Follower)模式的共识算法。在ZAB协议中,整个集群中的服务器分为三种角色:领导者、跟随者和观察者。领导者负责处理客户端的请求,并将数据同步给跟随者和观察者。跟随者接收领导者的数据同步,并在领导者故障时参与新的领导者选举。观察者则不参与投票,仅接收数据同步。
ZooKeeper 是通过 Zab 协议来保证分布式事务的最终一致性。Zab(ZooKeeper Atomic Broadcast,ZooKeeper 原子广播协议)支持崩溃恢复,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间数据一致性。
在 ZooKeeper 集群中,所有客户端的请求都是写入到 Leader 进程中的,然后,由 Leader 同步到其他节点,称为 Follower。在集群数据同步的过程中,如果出现 Follower 节点崩溃或者 Leader 进程崩溃时,都会通过 Zab 协议来保证数据一致性。

算法原理
ZAB协议是基于原子广播协议的一个变种,它保证了分布式系统中的数据一致性。ZAB协议通过一系列的流程来确保数据的一致性,其中包含了以下三个阶段
-
崩溃恢复阶段:如果在同步过程中出现 Leader 节点宕机,会进入崩溃恢复阶段,重新进行 Leader 选举,崩溃恢复阶段还包含数据同步操作,同步集群中最新的数据,保持集群的数据一致性。整个 ZooKeeper 集群的一致性保证就是在上面两个状态之前切换,当 Leader 服务正常时,就是正常的消息广播模式;当 Leader 不可用时,则进入崩溃恢复模式,崩溃恢复阶段会进行数据同步,完成以后,重新进入消息广播阶段。
-
消息广播阶段:Leader 节点接受事务提交,并且将新的 Proposal 请求广播给 Follower 节点,收集各个节点的反馈,决定是否进行 Commit,在这个过程中,也会使用前面提到的 Quorum 选举机制。
-
选举阶段:在ZAB协议中,集群中的节点分为领导者(Leader)和跟随者(Follower)。当集群启动或领导者失效时,会触发选举过程,选举出一个新的领导者。
Zxid
Zxid 是 Zab 协议的一个事务编号,Zxid 是一个 64 位的数字,其中低 32 位是一个简单的单调递增计
数器,针对客户端每一个事务请求,计数器加 1;而高 32 位则代表 Leader 周期年代的编号。

Zab 流程分析
Zab 的具体流程可以拆分为消息广播、崩溃恢复和数据同步三个过程,下面我们分别进行分析。
消息广播
在 ZooKeeper 中所有的事务请求都由 Leader 节点来处理,其他服务器为 Follower,Leader 将客户端
的事务请求转换为事务 Proposal,并且将 Proposal 分发给集群中其他所有的 Follower。
完成广播之后,Leader 等待 Follwer 反馈,当有过半数的 Follower 反馈信息后,Leader 将再次向集
群内 Follower 广播 Commit 信息,Commit 信息就是确认将之前的 Proposal 提交。
Leader 节点的写入也是一个两步操作,第一步是广播事务操作,第二步是广播提交操作,其中过半数
指的是反馈的节点数 >=N/2+1,N 是全部的 Follower 节点数量。

- 客户端的写请求进来之后,Leader 会将写请求包装成 Proposal 事务,并添加一个递增事务 ID,也就是 Zxid,Zxid 是单调递增的,以保证每个消息的先后顺序;
- 广播这个 Proposal 事务,Leader 节点和 Follower 节点是解耦的,通信都会经过一个先进先出的消息队列,Leader 会为每一个 Follower 服务器分配一个单独的 FIFO 队列,然后把 Proposal 放到队列中;
- Follower 节点收到对应的 Proposal 之后会把它持久到磁盘上,当完全写入之后,发一个 ACK 给 Leader;
- 当 Leader 收到超过半数 Follower 机器的 ack 之后,会提交本地机器上的事务,同时开始广播 commit,Follower 收到 commit 之后,完成各自的事务提交。
崩溃恢复
消息广播通过 Quorum 机制,解决了 Follower 节点宕机的情况,但是如果在广播过程中 Leader 节点崩溃呢?
这就需要 Zab 协议支持的崩溃恢复,崩溃恢复可以保证在 Leader 进程崩溃的时候可以重新选出Leader,并且保证数据的完整性。崩溃恢复和集群启动时的选举过程是一致的,也就是说,下面的几种情况都会进入崩溃恢复阶段:
- 初始化集群,刚刚启动的时候
- Leader 崩溃,因为故障宕机
- Leader 失去了半数的机器支持,与集群中超过一半的节点断连
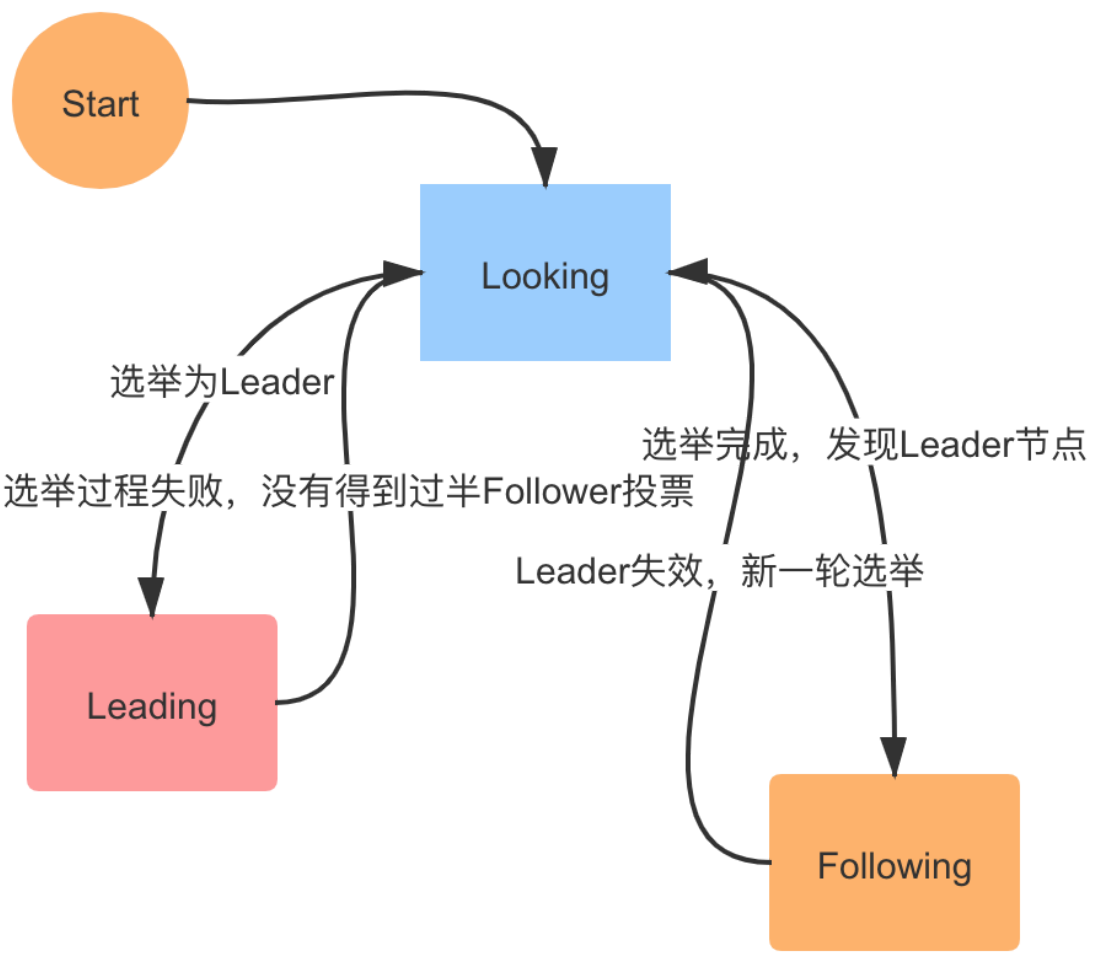
崩溃恢复模式将会开启新的一轮选举,选举产生的 Leader 会与过半的 Follower 进行同步,使数据一致,当与过半的机器同步完成后,就退出恢复模式, 然后进入消息广播模式。Zab 中的节点有三种状态,伴随着的 Zab 不同阶段的转换,节点状态也在变化:
- following: 当前节点是跟随者,服从Leader节点的命令
- leading: 当前节点是Leader,负责协调事务
- looking: 节点处于选举状态
我们通过一个模拟的例子,来了解崩溃恢复阶段,也就是选举的流程。
假设正在运行的集群有五台 Follower 服务器,编号分别是 Server1、Server2、Server3、Server4、Server5,当前 Leader 是 Server2,若某一时刻 Leader 挂了,此时便开始 Leader 选举。
选举过程如下:
- 各个节点变更状态,变更为 Looking
ZooKeeper 中除了 Leader 和 Follower,还有 Observer 节点,Observer 不参与选举,Leader 挂后,余下的 Follower 节点都会将自己的状态变更为 Looking,然后开始进入 Leader 选举过程。
- 各个 Server 节点都会发出一个投票,参与选举
在第一次投票中,所有的 Server 都会投自己,然后各自将投票发送给集群中所有机器,在运行期间,每个服务器上的 Zxid 大概率不同。
- 集群接收来自各个服务器的投票,开始处理投票和选举
处理投票的过程就是对比 Zxid 的过程,假定 Server3 的 Zxid 最大,Server1 判断 Server3 可以成为Leader,那么 Server1 就投票给 Server3,判断的依据如下:
- 首先选举 epoch 最大的
- 如果 epoch 相等,则选 zxid 最大的
- 若 epoch 和 zxid 都相等,则选择 server id 最大的,就是配置 zoo.cfg 中的 myid
在选举过程中,如果有节点获得超过半数的投票数,则会成为 Leader 节点,反之则重新投票选举。
4.选举成功,改变服务器的状态
数据同步
崩溃恢复完成选举以后,接下来的工作就是数据同步,在选举过程中,通过投票已经确认 Leader 服务
器是最大Zxid 的节点,同步阶段就是利用 Leader 前一阶段获得的最新Proposal历史,同步集群中所有
的副本。
Leader选举的概念示例:
public interface Proposal {
int getZxid();
void apply();
}
public class ZabLeaderElection {
private volatile boolean isLeader = false;
private int leaderId;
private List<Proposal> proposals = new ArrayList<>();
public synchronized void startElection() {
// 选举逻辑,简化为直接假设当前节点为Leader
leaderId = this.hashCode();
isLeader = true;
System.out.println("Leader elected: " + leaderId);
}
public synchronized boolean isLeader() {
return isLeader;
}
public synchronized void onProposalReceived(Proposal proposal) {
if (isLeader()) {
proposals.add(proposal);
applyProposal(proposal);
} else {
// 如果当前节点不是Leader,转发提案到Leader
forwardProposalToLeader(proposal);
}
}
private void applyProposal(Proposal proposal) {
// 应用提案到状态机
proposal.apply();
// 持久化提案
persistProposal(proposal);
// 发送提案给其他Follower节点
sendProposalToFollowers(proposal);
}
private void forwardProposalToLeader(Proposal proposal) {
// 转发提案到Leader的逻辑
}
private void persistProposal(Proposal proposal) {
// 持久化提案的逻辑
}
private void sendProposalToFollowers(Proposal proposal) {
// 发送提案给Follower的逻辑
}
}
结语
ZAB协议是Zookeeper中实现数据一致性的核心算法。通过选举、原子广播和崩溃恢复等流程,ZAB协议保证了分布式系统中的数据一致性。ZAB协议在分布式锁、服务发现、配置管理等场景中有广泛的应用,为分布式系统提供了一种可靠的数据一致性保障机制。