通过深度学习入门到放弃系列 - 魔搭社区完成开源大模型部署调用 ,大概掌握了开源模型的部署调用,但是魔搭社区有一个弊端,关闭实例后数据基本上就丢了,本地的电脑无法满足大模型的配置,就需要去租用一些高性价比的GPU机器长期运行,起码数据和环境能长期存在。以我在阿里云人工智能平台 PAI部署和大家分享一下经验,其他平台自行尝试、选择。
免费算力平台
- 阿里云人工智能平台 PAI
- 阿里天池实验室
- Kaggle平台
- Colab(需要梯子)
付费算力平台
- AutoDL
- Gpushare Cloud
- Featurize
- AnyGPU
阿里云人工智能平台 PAI试用申请流程
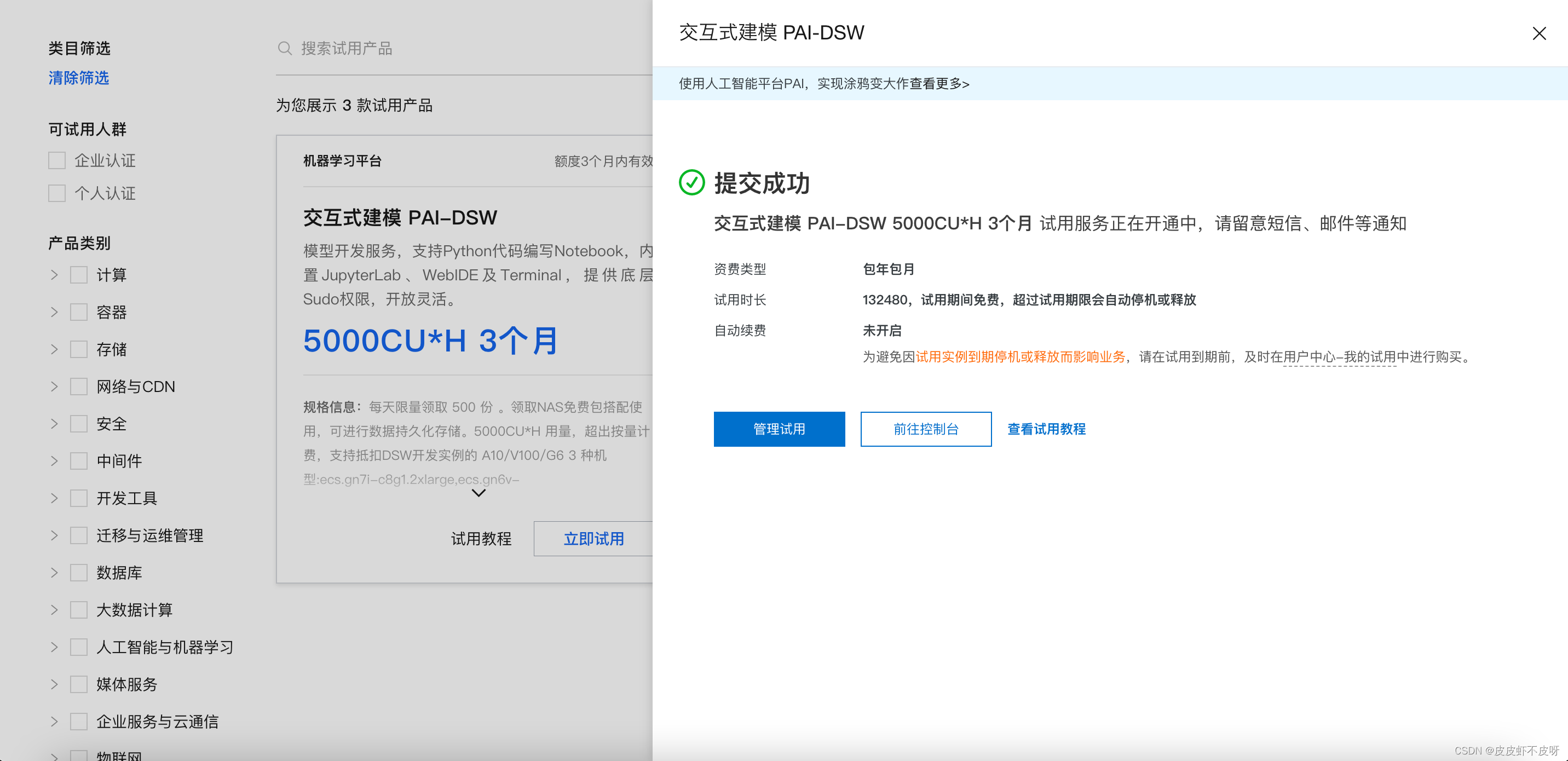
我选择的是阿里云人工智能平台 PAI平台的免费算力平台,免费使用三个月,截止目前还很好抢,每天500份传送门。同时,也推荐一些其他的算力平台给大家自行选择。
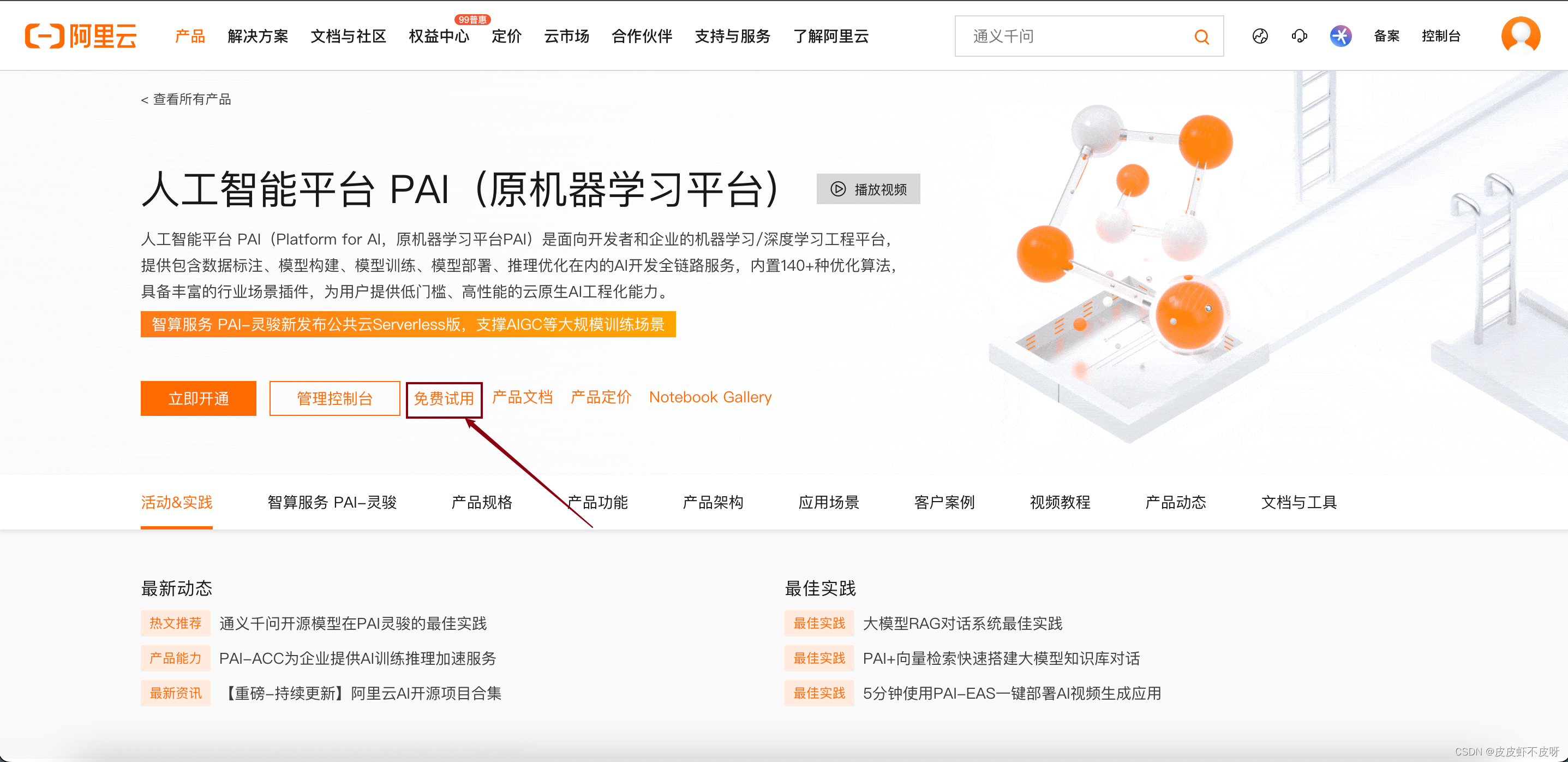
建议选交互式建模PAI-DSW
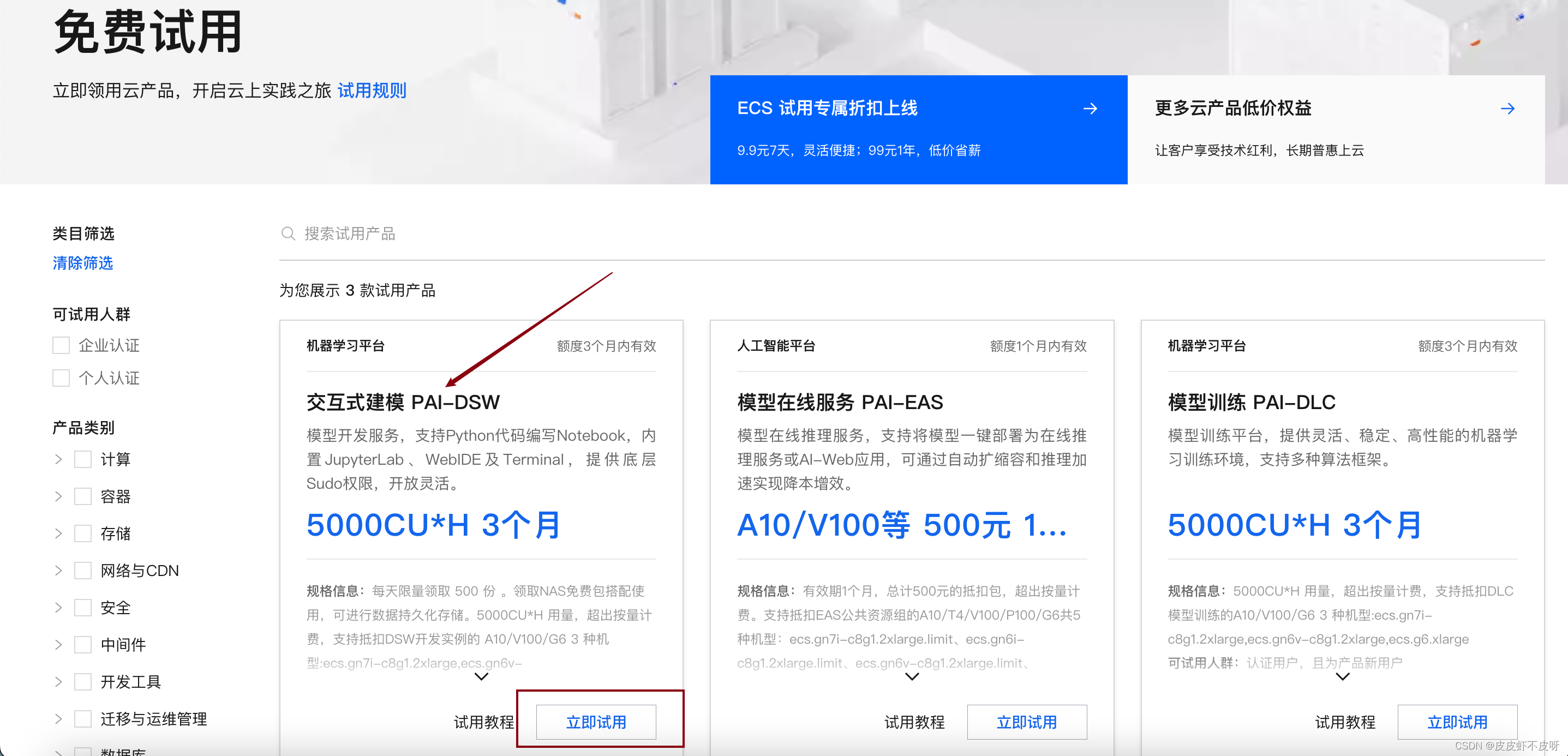
立即试用!
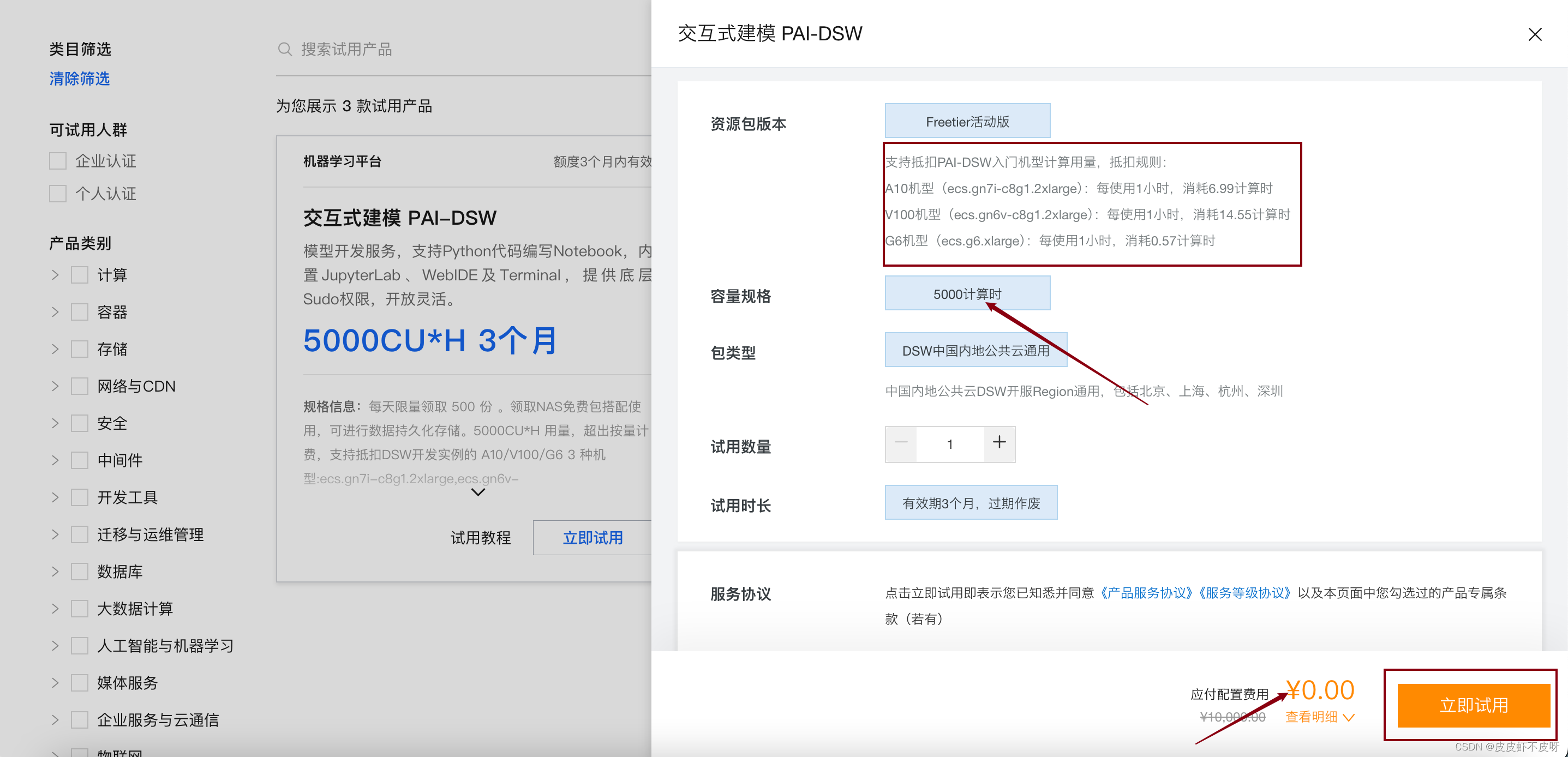
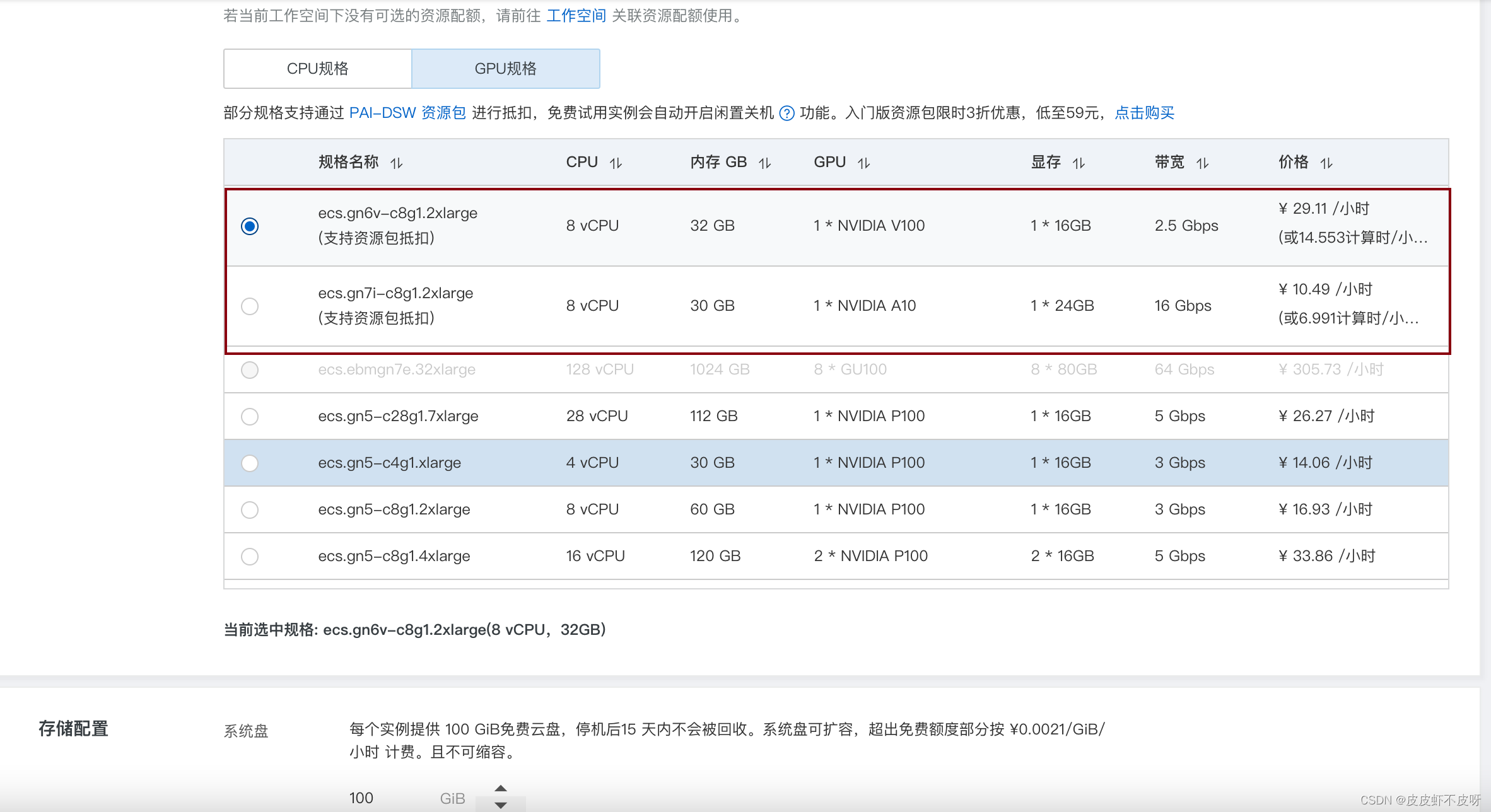
创建规格的时候千万注意选择GPU-支持资源包抵扣的这种。
创建实例!
启动实例!
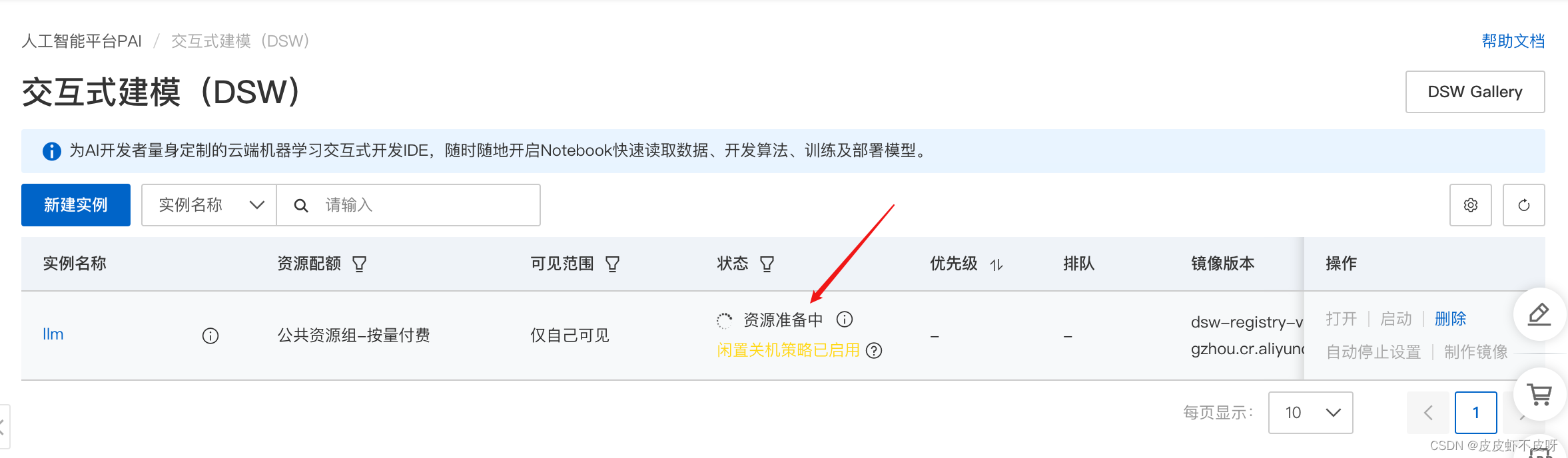
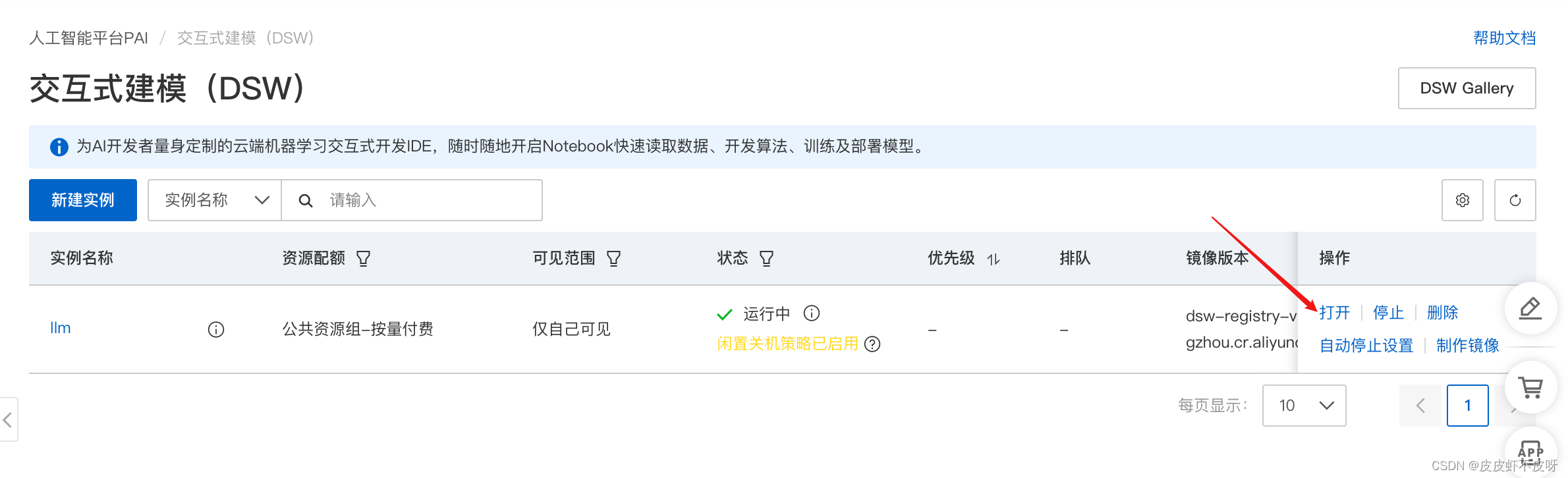 打开后界面和魔搭社区就比较类似了,有命令行、Notebook等。
打开后界面和魔搭社区就比较类似了,有命令行、Notebook等。
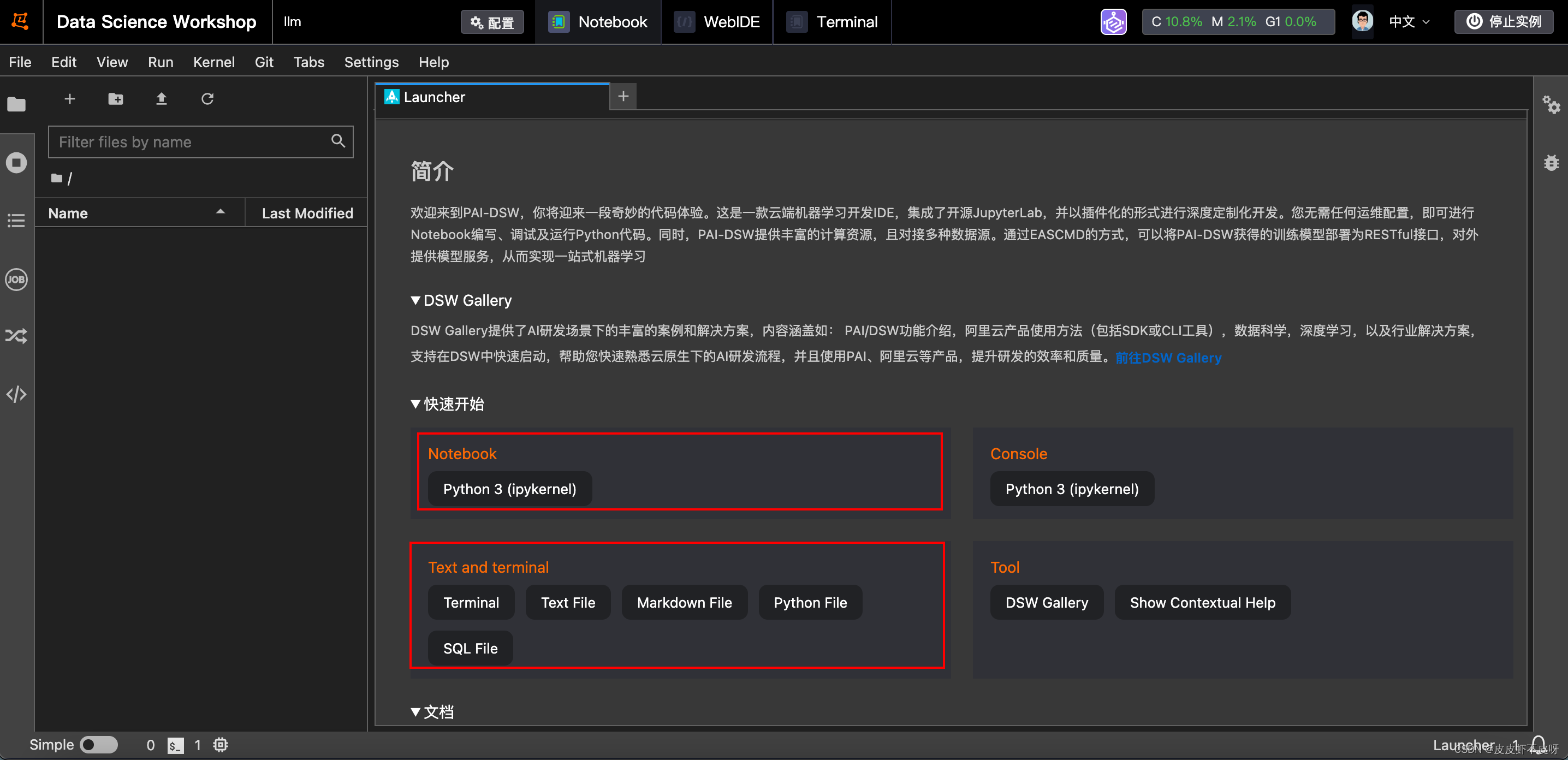
环境搭建
- 新建账号:进来就已经是root账户了,需要创建一个用户。
# 添加一个新用户(如用户名为csdn)遇到执行
adduser csdn
# 将用户添加到 sudo 组
adduser csdn sudo
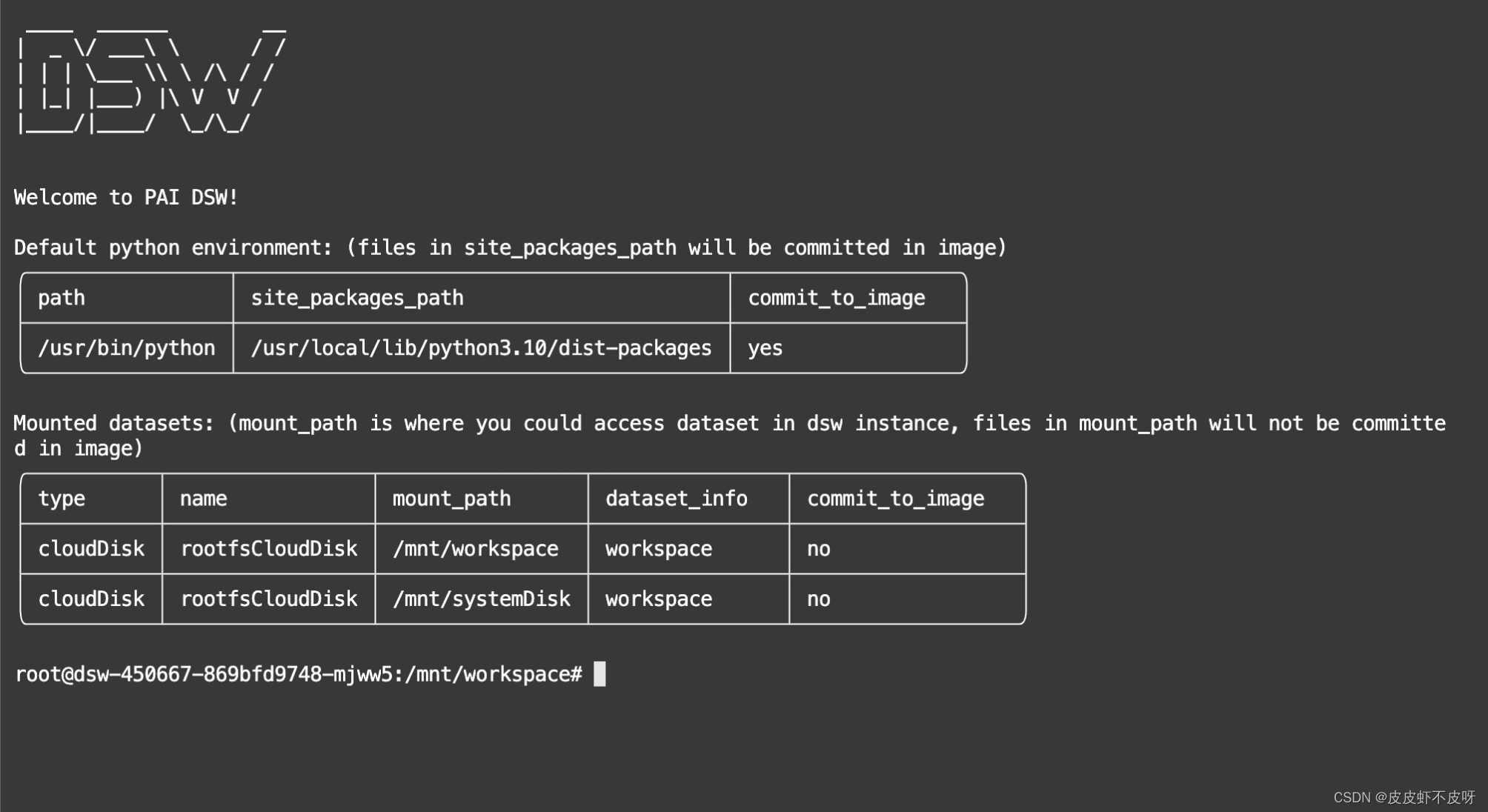
- 进来以后发现ll、source等命令都不能用,需要先把dash改成bash命令,参考source: not found问题处理。解决完重新打开命令行以后就是我现在的界面。
- 更换国内软件源
cd /ect/apt
# 备份sources.list,以免出问题
sudo cp sources.list sources.list.backup
vim sources.list
# 复制到sources.list文件末尾
deb https://mirrors.ustc.edu.cn/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu/ focal-security main restricted universe multiverse
- 安装vim编辑器、git
# 使用vi可跳过
sudo apt-get install vim
sudo apt-get install git
- 系统软件更新
# 更新软件包列表
sudo apt update
# 执行更新命令
sudo apt upgrade
- 安装anaconda
# 下载安装包
wget https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh
# 执行安装命令
bash Anaconda3-2023.09.0-Linux-x86_64.sh
直到出现 yes no 选项,选择yes,再然后遇到路径/root/anaconda3,然后按“Enter”键使用Anaconda的默认安装位置/root/anaconda3下,然后等待安装结束。
- 配置环境变量
# 印象中不创建账号好像就没有bashrc的文件
vim ~/.bashrc
# 末尾添加anaconda3所在路径,和第六步路径一致
export PATH=/root/anaconda3/bin:$PATH
# 使环境变量的修改立即生效
source ~/.bashrc
- 安装之前需要配置一下conda,都说用国内镜像源,我试了没用
# 我用的这种方法
conda install -n base conda-libmamba-solver
# 设置全局使用libmamba
conda config --set solver libmamba
- conda创建虚拟环境
conda create --n chatglm3_test python=3.11
conda activate chatglm3_test
# 如果中间报错找不到activate命令,使用下面的命令试试
source /root/anaconda3/etc/profile.d/conda.sh
- 安装pytorch等依赖
nvidia-msi查看目前的cuda版本来选择对应的pytorch
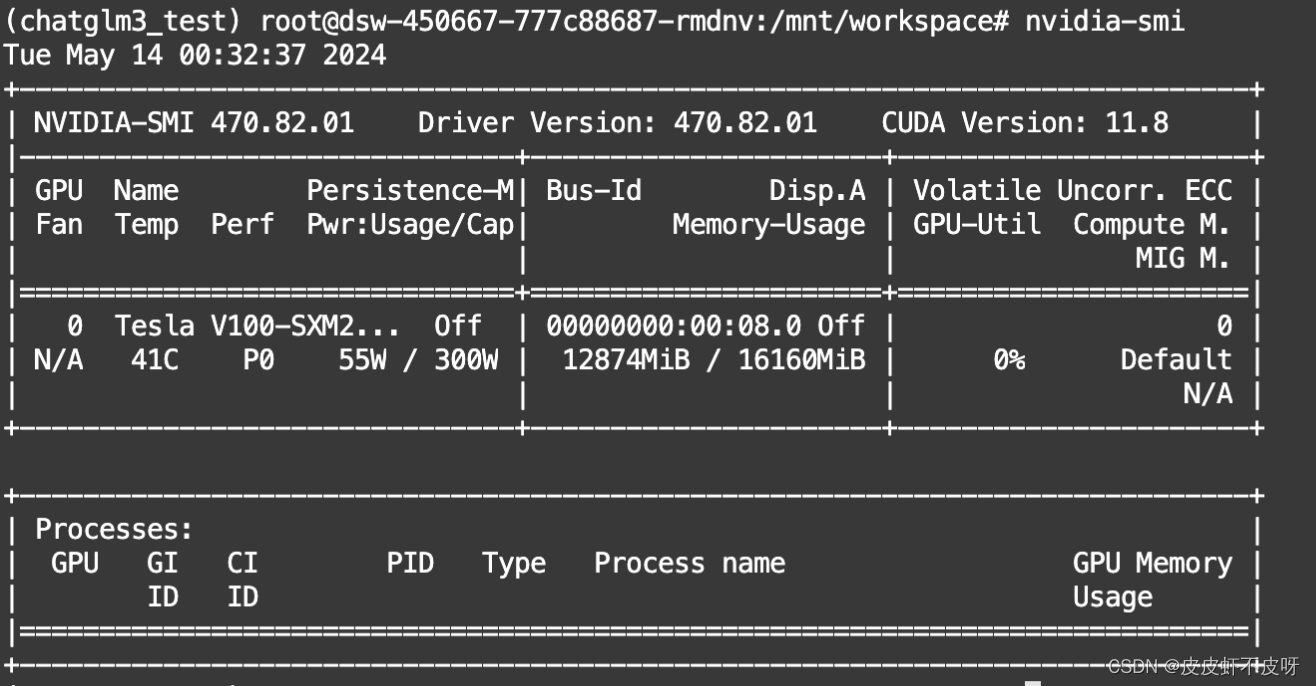
# CUDA 11.8 根据我自己的版本我选择第一个就好了
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=12.1 -c pytorch -c nvidia
# CPU Only
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 cpuonly -c pytorch
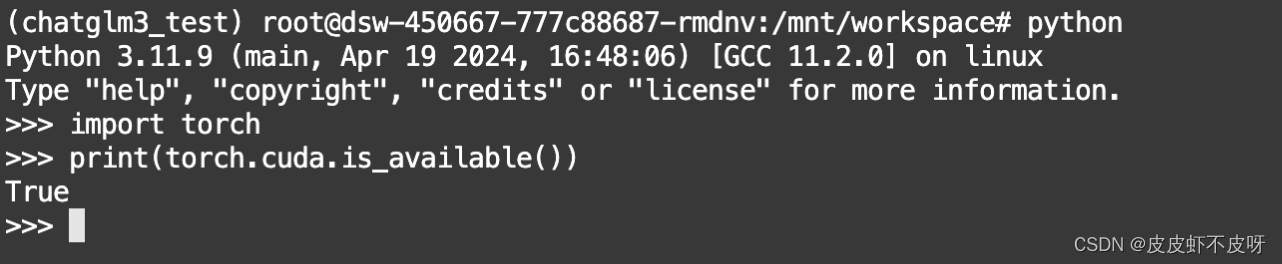
- 验证GPU版本的PyTorch
import torch
print(torch.cuda.is_available())
如下图说明安装成功。
12. 下载ChatGLM3项目文件
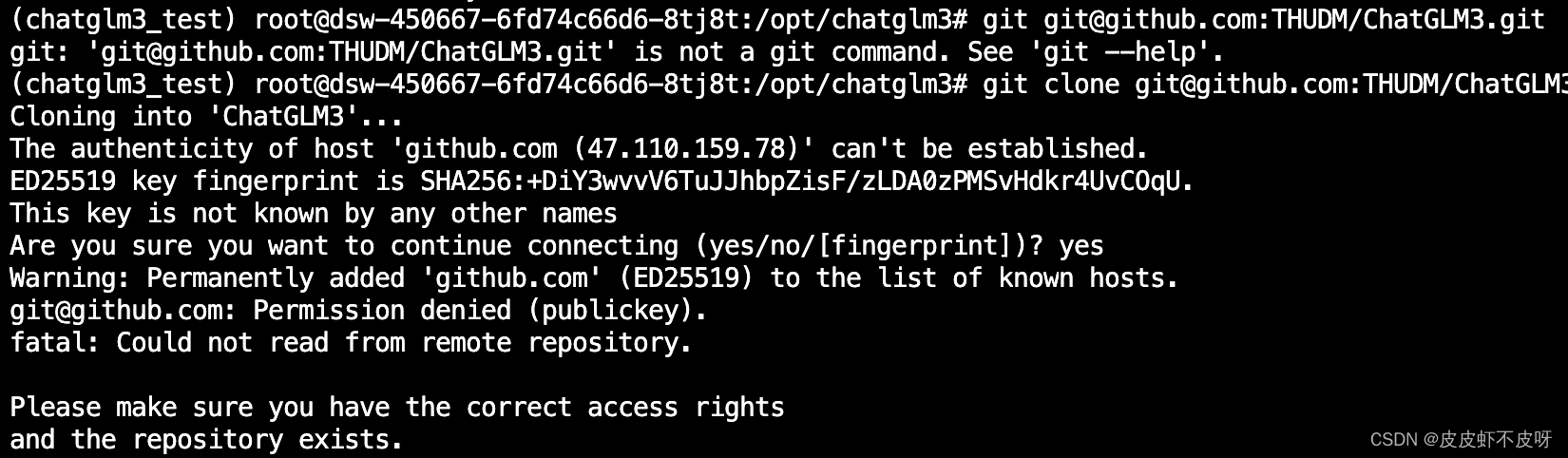
git下载ChatGLM3项目文件时可能会出现Permission denied,参考解决办法 git报错Permission denied的解决方法
# 创建文件夹
mkdir /opt/chatglm3
# 切换到新建的目录下
cd /opt/chatglm3
# 下载ChatGLM3
git clone git@github.com:THUDM/ChatGLM3.git
# 升级pip版本
python -m pip install --upgrade pip
- 安装ChatGLM运行的项目依赖
cd /opt/chatglm3/ChatGLM3
# 安装依赖
pip install -r requirements.txt
- 安装模型权重文件
Git Large File Storage(Git LFS)是一种用于处理大文件的工具,在 Hugging Face等平台下载大模型时,通常需要安装 Git LFS,主要的原因是:Git 本身并不擅长处理大型文件,因为在 Git 中,每次我们提交一个文件,它的完整内容都会被保存在 Git 仓库的历史记录中。但对于非常大的文件,这种方式会导致仓库变得庞大而且低效。而 Git LFS, 就不会直接将它们的内容存储在仓库中。相反,它存储了一个轻量级的“指针”文件,它本身非常小,它包含了关于大型文件的信息(如其在服务器上的位置),但不包含文件的实际内容。当我们需要访问或下载这个大型文件时,Git LFS 会根据这个指针去下载真正的文件内容
实际的大文件存储在一个单独的服务器上,而不是在 Git 仓库的历史记录中。所以如果不安装 Git LFS 而直接从 Hugging Face 或其他支持 LFS 的仓库下载大型文件,通常只会下载到一个包含指向实际文件的指针的小文件,而不是文件本身。
# 安装git-lfs
sudo apt-get install git-lfs
# 初始化
git lfs install
# 魔搭平台下载模型权重文件,Hugging Face太慢了
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
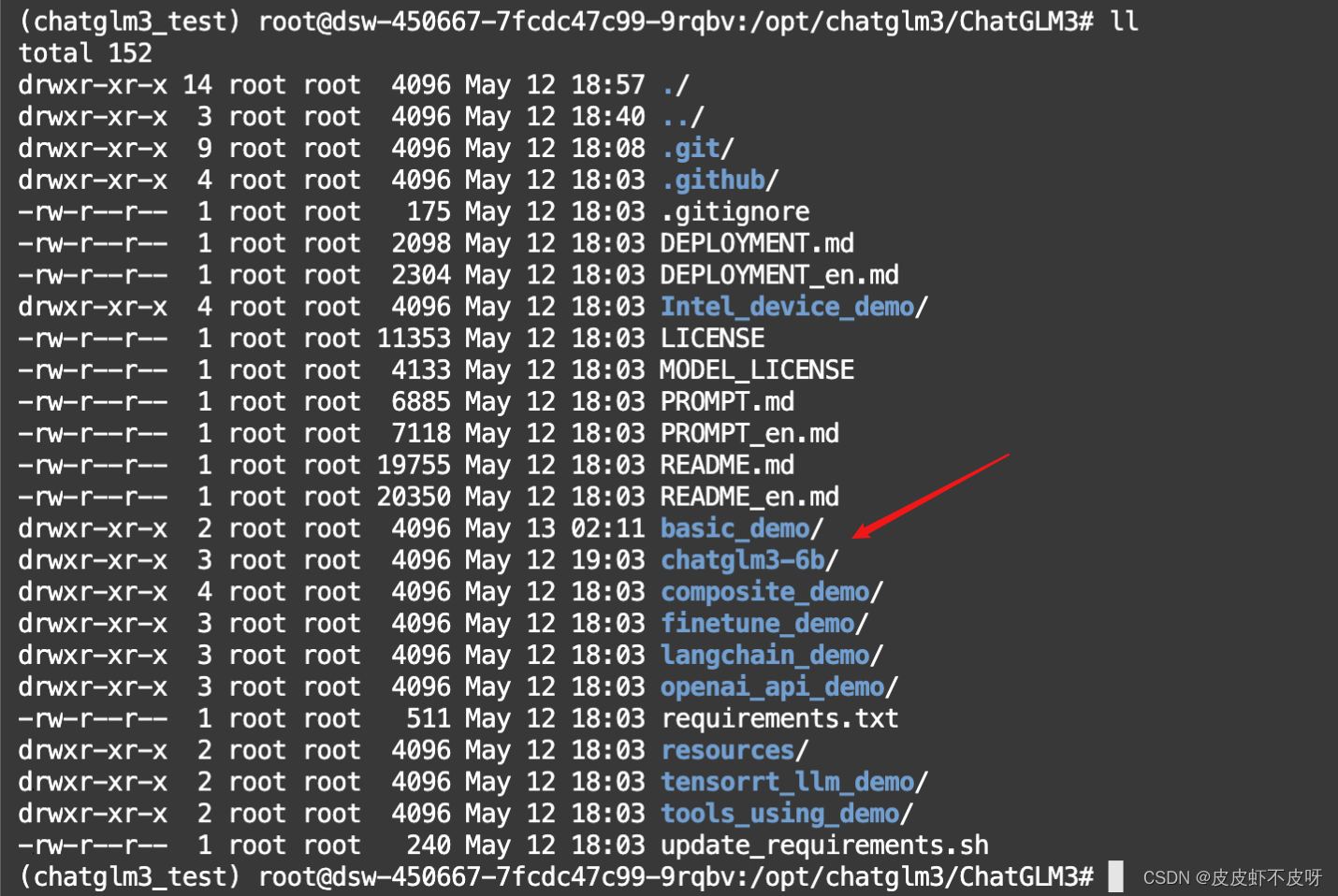
目录结构如下图所示,chatglm3-6b目录为模型权重文件
- 运行ChatGLM3-6B模型
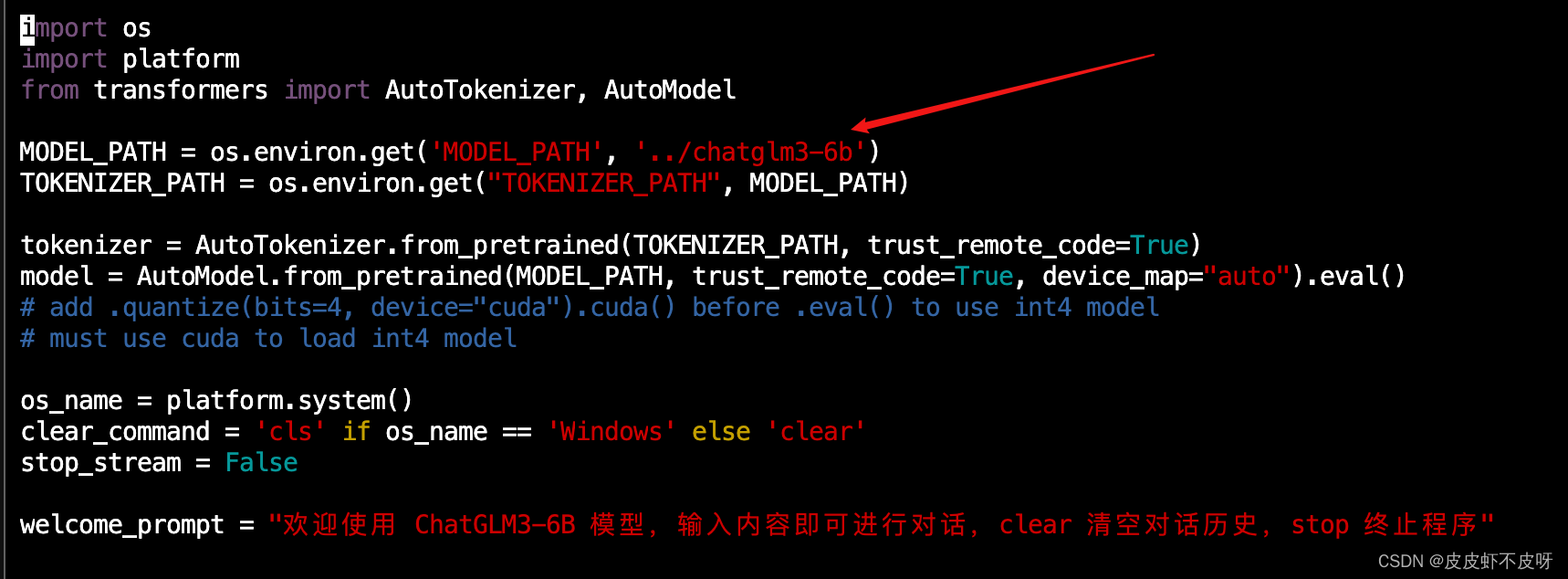
运行前需要改一下模型权重文件的路径,我们提前下载,改成本地的路径,否则会重新下载。
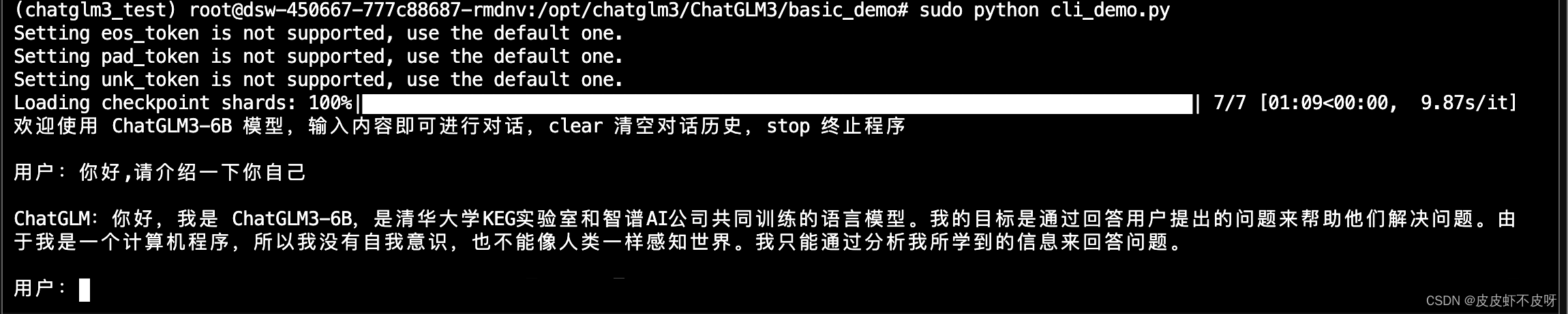
在basic_demo目录下运行cli_demo.py文件,能正常对话说明大功告成了!千万注意要sudo运行哈!
遇到的问题
问题一:Ubuntu下shell执行source命令报source: not found问题处理
问题二:conda: error: argument COMMAND: invalid choice: ‘activate‘

问题三:git报错Permission denied
问题四:conda下载文件慢
![[MRCTF2020]PixelShooter](https://img-blog.csdnimg.cn/direct/5c0eb4f93e6a405f8408b2c8762ac683.png)