机器学习-KNN算法
没有什么比顺其自然更有超凡的力量。没有什么比顺乎本性更具有迷人的魔力。
目录
机器学习-KNN算法
1.K近邻算法
2.KNN决策方式
1)KNN分类预测规则
1)KNN回归预测规则
3.KNN三要素
4.KNN算法实现方式
1)蛮力实现
2)KD树
3)KD树实例
1.K近邻算法
KNN(K-Nearest Neighbors)算法是一种简单而又强大的监督学习算法,常用于分类和回归问题。它的原理非常直观:预测一个样本的标签,就是找出距离该样本最近的 K 个邻居,然后根据这 K 个邻居的标签来决定该样本的标签。
让我用通俗易懂的方式来解释一下KNN算法的工作原理:
1. 收集数据:首先,我们需要收集有标签的训练数据,包括输入特征和对应的标签。
2. 选择邻居数量 K:确定一个合适的邻居数量 K,这是KNN算法中的一个重要参数。通常情况下,选择一个合适的 K 值可以通过交叉验证或者经验法则来确定。
3. 计算距离:对于给定的测试样本,计算它与训练集中所有样本的距离。常用的距离度量方法包括欧式距离、曼哈顿距离等。
4. 找出最近的邻居:根据计算得到的距离,找出距离测试样本最近的 K 个训练样本,这些样本就是该测试样本的邻居。
5. 投票表决:对于分类问题,采用多数表决的方式,即将这 K 个邻居中出现次数最多的类别作为测试样本的预测类别;对于回归问题,通常采用这 K 个邻居的平均值作为预测值。
6. 预测:根据投票结果或者平均值,确定测试样本的标签或者数值。
KNN算法简单易懂,不需要模型训练过程,而是直接利用训练集中的样本进行预测。然而,KNN算法的计算复杂度较高,特别是在处理大规模数据集时,计算距离的时间开销比较大。此外,KNN算法对数据的缩放和特征选择也比较敏感。
总的来说,KNN算法是一个适用于小型数据集且容易理解的强大工具,尤其适用于非线性和非参数化的问题。
2.KNN决策方式

1)KNN分类预测规则
①多数表决法
②加权多数表决法


1)KNN回归预测规则
①平均值法
②加权平均值法

3.KNN三要素

距离的度量:欧式距离
求被测点到所有点的距离 取最近的k个

4.KNN算法实现方式

1)蛮力实现
2)KD树
KD树是按照列的方差来构建的


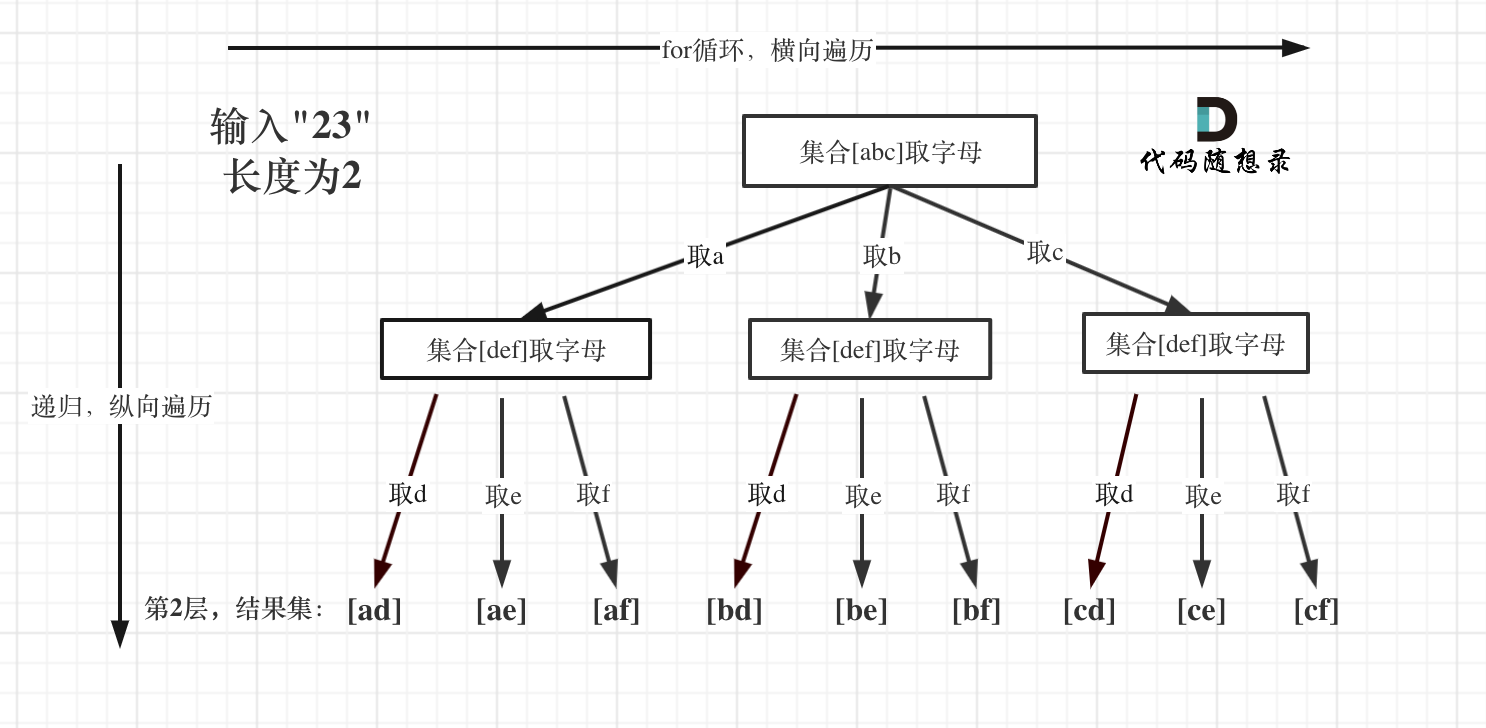
3)KD树实例
代码展示
#coding=UTF-8
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.preprocessing import label_binarize
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import matplotlib as mpl
import matplotlib.pyplot as plt
defaultencoding = 'utf-8'
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
#加载数据
datas=pd.read_csv("data/iris.data",header=None)#加载iris.data数据
#数据处理
datas=datas.replace("?",np.NaN)#把?号用NaN替换
datas=datas.dropna(how="any",axis=1)#删除NaN行
#提取X和Y
X=datas.iloc[:,0:-1]#取0到最后一列前一列
#对种类英文编码
Y=pd.Categorical(datas[4]).codes#对最后一列做编码
print(Y)
#对数据进行拆分
#逻辑回归是用来判断 y属于哪一个种类 1 0
train_x,test_x,train_y,test_y=train_test_split(X,Y,test_size=0.2,random_state=1)
#创建模型和训练模型
ss=StandardScaler()
train_x=ss.fit_transform(train_x)#把trainx数据标准化
test_x=ss.transform(test_x)#把testx数据标准化
logistic=LogisticRegressionCV(random_state=2,multi_class="ovr")
logistic.fit(train_x,train_y) #能够识别三种花模型 求theta
#评估
proba=logistic.predict_proba(test_x)#每条记录每个种类的概率 30 3
ymy=label_binarize(test_y,classes=(0,1,2))#转换成哑编码 30 3
fpr,tpr,threshold=metrics.roc_curve(ymy.ravel(),proba.ravel())#ravel拉平,变成一维
auc=metrics.auc(fpr,tpr)#根据fpr tpr计算面积
print("auc",auc)
knn=KNeighborsClassifier(n_neighbors=5,algorithm="kd_tree")
knn.fit(train_x,train_y) # 构建kd树
test_y_hat=knn.predict(test_x)
proba_knn=knn.predict_proba(test_x)
fpr1,tpr1,threshold1=metrics.roc_curve(ymy.ravel(),proba_knn.ravel())
auc1=metrics.auc(fpr1,tpr1)
print(auc1)
plt.figure()
#画逻辑回归算法ROC曲线
plt.plot(fpr,tpr,color='red',label='回归ROC auc:'+str(auc))
plt.plot(fpr1,tpr1,color='green',label='knnROC auc:'+str(auc1)) # kd树
plt.legend()
plt.show()
运行结果

5.目标函数 损失函数
目标函数和损失函数的区别就是用在什么地方

6.交叉验证