一、前言
通过学习代码专家模型,开发人员可以获得高效、准确和个性化的代码支持。这不仅可以提高工作效率,还可以在不同的技术环境中简化软件开发工作流程。代码专家模型的引入将为开发人员带来更多的机会去关注创造性的编程任务,从而推动软件开发的创新和进步。
通过使用langchain,用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。langchain会自动将任务分解为多个子任务,并将它们传递给适合的语言模型进行处理。
二、术语
2.1.CodeQwen1.5
基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~3T tokens 代码相关的数据进行预训练,共计支持 92 种编程语言、且最长支持 64K 的上下文输入。效果方面,CodeQwen1.5 展现出了非凡的代码生成、长序列建模、代码修改、SQL 能力等,该模型可以大大提高开发人员的工作效率,并在不同的技术环境中简化软件开发工作流程。
CodeQwen 是基础的 Coder
代码生成是大语言模型的关键能力之一,期待模型将自然语言指令转换为具有精确的、可执行的代码。仅拥有 70 亿参数的 CodeQwen1.5 在基础代码生成能力上已经超过了更尺寸的模型,进一步缩小了开源 CodeLLM 和 GPT-4 之间编码能力的差距。
CodeQwen 是长序列 Coder
长序列能力对于代码模型来说至关重要,是理解仓库级别代码、成为 Code Agent 的核心能力。而当前的代码模型对于长度的支持仍然非常有限,阻碍了其实际应用的潜力。CodeQwen1.5 希望进一步推进开源代码模型在长序列建模上的进展,我们收集并构造了仓库级别的长序列代码数据进行预训练,通过精细的数据配比和组织方式,使其最终可以最长支持 64K 的输入长度。
CodeQwen 是优秀的代码修改者
一个好的代码助手不仅可以根据指令生成代码,还能够针对已有代码或者新的需求进行修改或错误修复。
CodeQwen 是出色的 SQL 专家
CodeQwen1.5 可以作为一个智能的 SQL 专家,弥合了非编程专业人士与高效数据交互之间的差距。它通过自然语言使无编程专业知识的用户能够查询数据库,从而缓解了与SQL相关的陡峭学习曲线。
2.2.CodeQwen1.5-7B-Chat
CodeQwen1.5 is the Code-Specific version of Qwen1.5. It is a transformer-based decoder-only language model pretrained on a large amount of data of codes.
- Strong code generation capabilities and competitve performance across a series of benchmarks;
- Supporting long context understanding and generation with the context length of 64K tokens;
- Supporting 92 coding languages
- Excellent performance in text-to-SQL, bug fix, etc.
2.3.LangChain
是一个全方位的、基于大语言模型这种预测能力的应用开发工具。LangChain的预构建链功能,就像乐高积木一样,无论你是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain 提供的模块化组件则允许你根据自己的需求定制和创建应用中的功能链条。
LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。
LangChain的主要特性:
1.可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等
2.允许语言模型与其环境交互
3.封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件
4.可以使用链的方式组装这些组件,以便最好地完成特定用例。
5.围绕以上设计原则,LangChain解决了现在开发人工智能应用的一些切实痛点。
三、前置条件
3.1.基础环境
操作系统:centos7
Tesla V100-SXM2-32GB CUDA Version: 12.2
3.2.下载模型
huggingface:
https://huggingface.co/Qwen/CodeQwen1.5-7B-Chat/tree/main

ModelScope:
git clone https://www.modelscope.cn/qwen/CodeQwen1.5-7B-Chat.git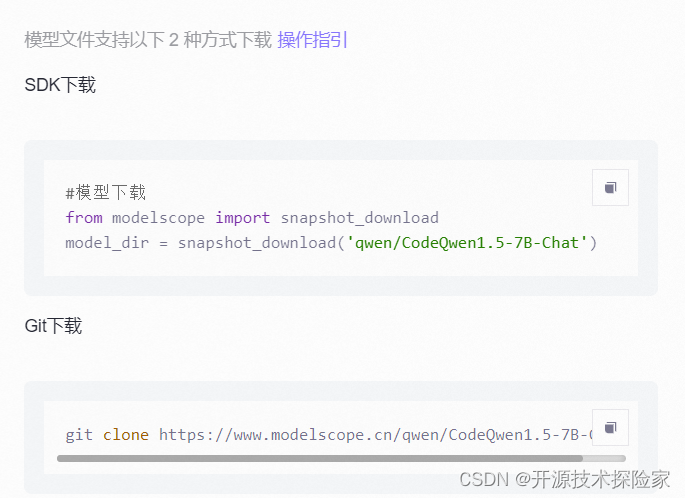
PS:
1. 根据实际情况选择不同规格的模型
3.3.安装虚拟环境
conda create --name langchain python=3.10
conda activate langchain
# -c 参数用于指定要使用的通道
conda install pytorch pytorch-cuda=11.8 -c pytorch -c nvidia
pip install langchain accelerate numpy transformers==4.38.1
ps: 注意在虚拟环境中安装
四、使用方式
4.1.生成代码能力
# -*- coding = utf-8 -*-
import warnings
from langchain import LLMChain
from langchain.llms import HuggingFacePipeline
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
warnings.filterwarnings("ignore")
model_path = "/model/CodeQwen1.5-7B-Chat"
local_llm = HuggingFacePipeline.from_model_id(
model_id=model_path,
task="text-generation",
device=0,
pipeline_kwargs={"max_new_tokens": 8192},
)
system_template = "You are a helpful assistant."
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = """Question: {question}
Answer: Let's think step by step."""
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
prompt = prompt_template.format_prompt(question="用Python写一个冒泡排序算法的例子").to_messages()
print(prompt)
llm_chain = LLMChain(prompt=prompt_template, llm=local_llm)
print(llm_chain.run(question="用Python写一个冒泡排序算法的例子"))
调用结果:
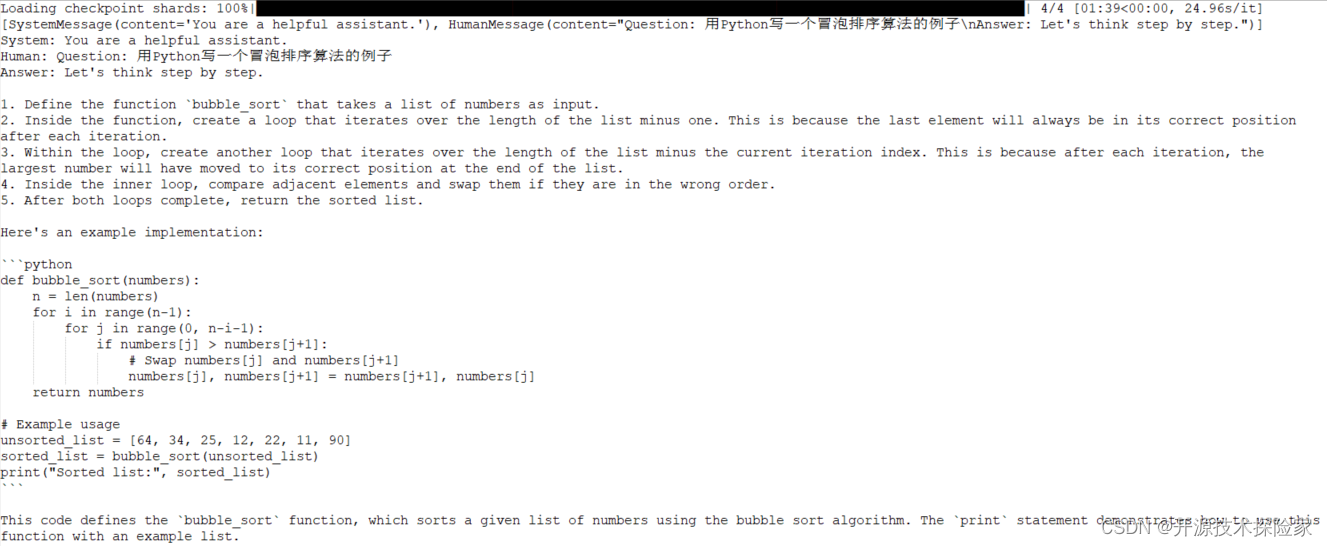
在IDEA中运行模型生成的代码
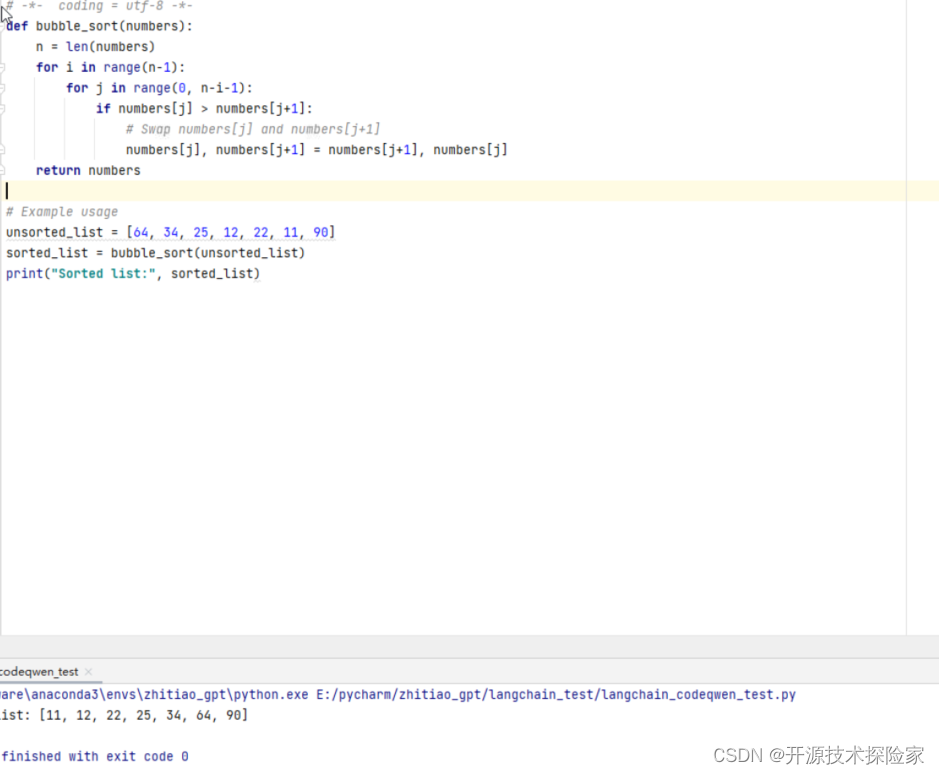
结论:
模型能根据需求生成可运行代码
4.2.修改代码的能力
示例说明:
把冒泡排序正确的代码故意修改为错误,异常为:UnboundLocalError: local variable 'j' referenced before assignment
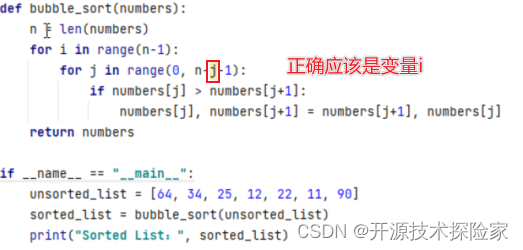
# -*- coding = utf-8 -*-
import warnings
from langchain import LLMChain
from langchain.llms import HuggingFacePipeline
from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate
warnings.filterwarnings("ignore")
model_path = "/model/CodeQwen1.5-7B-Chat"
local_llm = HuggingFacePipeline.from_model_id(
model_id=model_path,
task="text-generation",
device=0,
pipeline_kwargs={"max_new_tokens": 8192},
)
system_template = "You are a helpful assistant."
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = '我用Python写了一个冒泡排序的算法例子,但是运行结果不符合预期,请修改,具体代码如下: {code}'
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
code = '''
def bubble_sort(numbers):
n = len(numbers)
for i in range(n-1):
for j in range(0, n-j-1):
if numbers[j] > numbers[j+1]:
numbers[j], numbers[j+1] = numbers[j+1], numbers[j]
return numbers
if __name__ == "__main__":
unsorted_list = [64, 34, 25, 12, 22, 11, 90]
sorted_list = bubble_sort(unsorted_list)
print("Sorted List:", sorted_list)
'''
prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
llm_chain = LLMChain(prompt=prompt_template, llm=local_llm)
print(llm_chain.run(code=code))
调用结果:

结论:
模型能发现问题,并把异常修正