👨🎓博主简介
🏅CSDN博客专家
🏅云计算领域优质创作者
🏅华为云开发者社区专家博主
🏅阿里云开发者社区专家博主
💊交流社区:运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
文章目录
- 前言
- 声明式流水线
- 如何创建一个node节点?
- agent
- stages
- stage
- steps
- post
- environment
- tools
- input
- parameters
- options
- parallel
- tiggers
- when
- script
- 总结
- 参考文献:
- 相关专栏
- 相关文章
前言
Jenkins提供了两种开发Pipeline的方式:脚本式和声明式。
- 脚本式流水线(也称为“传统”流水线)基于Groovy作为其特定于域的语言。
- 而声明式流水线提供了简化且更友好的语法,并带有用于定义它们的特定语句,而无需学习Groovy。声明式流水线语法错误在脚本开始时报告。这是一个很好的功能,因为您不会浪费时间,直到某个步骤未能意识到拼写错误或拼写错误。如前所述,流水线可以以声明式或脚本式编写。而且,声明式方法建立在脚本式方法的基础之上,通过添加”script”步骤,可以很容易地进行扩展。
声明式流水线 vs 脚本式流水线共同点:
- 两者都是
pipeline代码的持久实现,都能够使用pipeline内置的插件或者插件提供的steps,两者都可以利用共享库扩展。
区别:
-
两者不同之处在于语法和灵活性。
-
Declarative pipeline对用户来说,语法更严格,有固定的组织结构,更容易生成代码段,使其成为用户更理想的选择。
-
但是Scripted pipeline更加灵活,因为Groovy本身只能对结构和语法进行限制,对于更复杂的pipeline来说,用户可以根据自己的业务进行灵活的实现和扩展
声明式流水线
声明式流水线
必须使用pipeline语句定义有效的声明式流水线,并包括以下必需的部分:
-
agent
-
stages
-
stage
-
steps
另外,还有这些可用的指令:
- environment (用于设置环境变量,可定义在stage或pipeline部分。)
- post(整个pipeline执行完成或者单个stage完成后需要执行的动作。)
- tools(可定义在pipeline或stage部分。它会自动下载并安装我们指定的工具,并将其加入PATH变量中。)
- input(定义在stage部分,会暂停pipeline,提示你输入内容。)
- options(用于配置Jenkins pipeline本身的选项,比如options {retry(3)}指当pipeline失败时再重试2次。options指令可定义在stage或pipeline部分。)
- parallel(并行执行多个step。在pipeline插件1.2版本后,parallel开始支持对多个阶段进行并行执行。)
- parameters(与input不同,parameters是执行pipeline前传入的一些参数。)
- script(用于执行一段 Groovy 脚本代码)
- triggers(用于定义执行pipeline的触发器。)
- when(当满足when定义的条件时,阶段才执行。)
在使用指令时,需要注意的是每个指令都有自己的“作用域”。如果指令使用的位置不正确,Jenkins将会报错。
更多的配置案例可参考:流水线语法(jenkins.io)
现在,我们将从所需的指令/部分开始,对列出的每个指令/部分进行描述。
这里我们就拿hello world的pipeline脚本举例,我们来看看pipeline脚本的组成;
hello world脚本就是明显的声明式流水线。
pipeline {
agent any
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
}
}
}
脚本都是以pipeline的关键字开头,接着看下pipeline内部具体由哪几部分组成。
如何创建一个node节点?
为什么要创建node节点呢?因为下面要用到;简单来说,创建node节点打标签方便对服务器进行分类,在写jenkinsfile的时候便于管理服务器,对指定服务器进行指定操作;
如何创建呢?我们来讲一下;
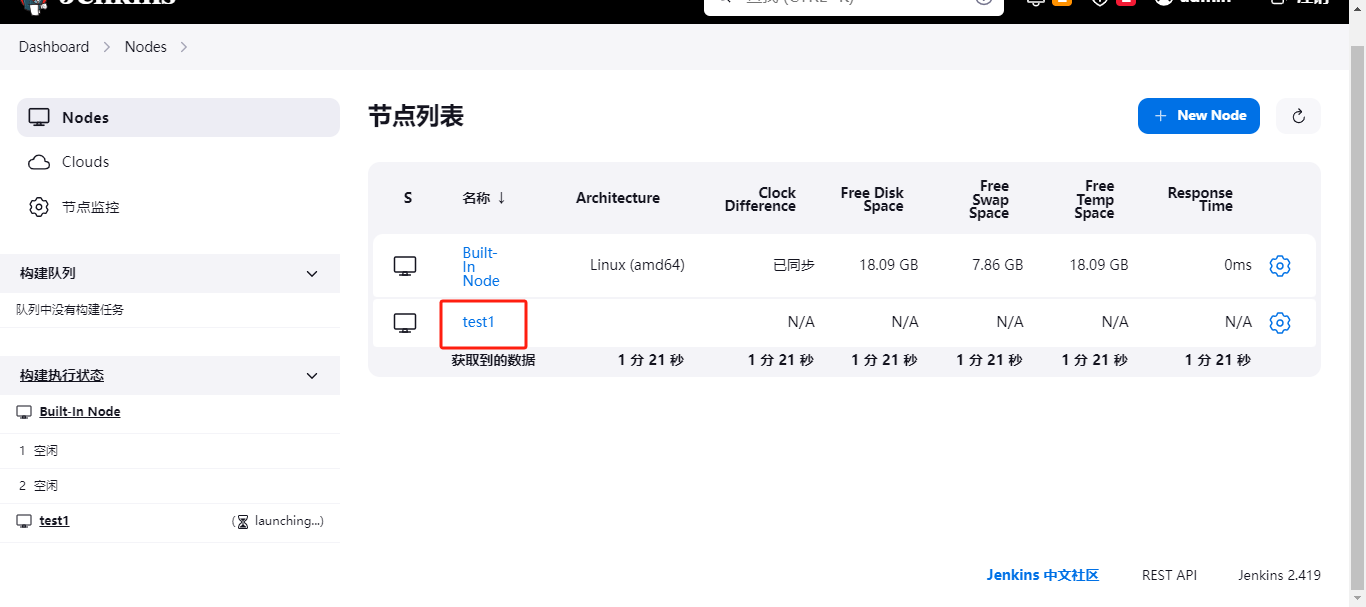
首先,登录jenkins – > Manage Jenkins --> nodes,在里面配置。
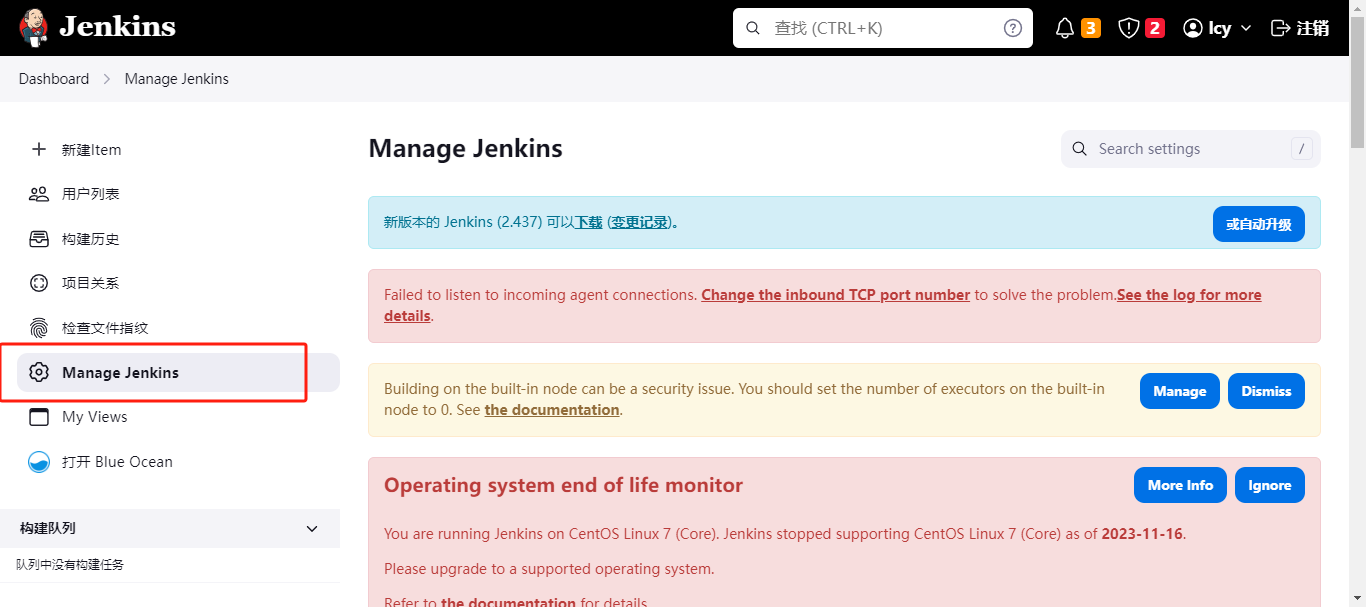
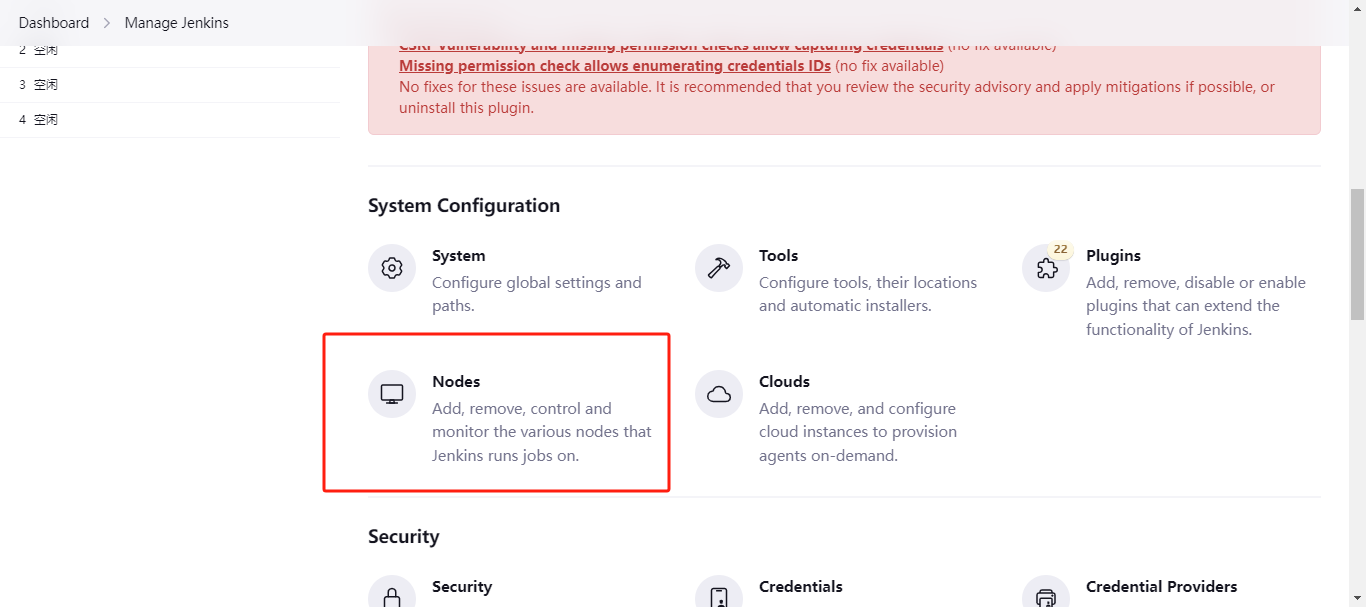
点进来之后,直接new node创建即可。
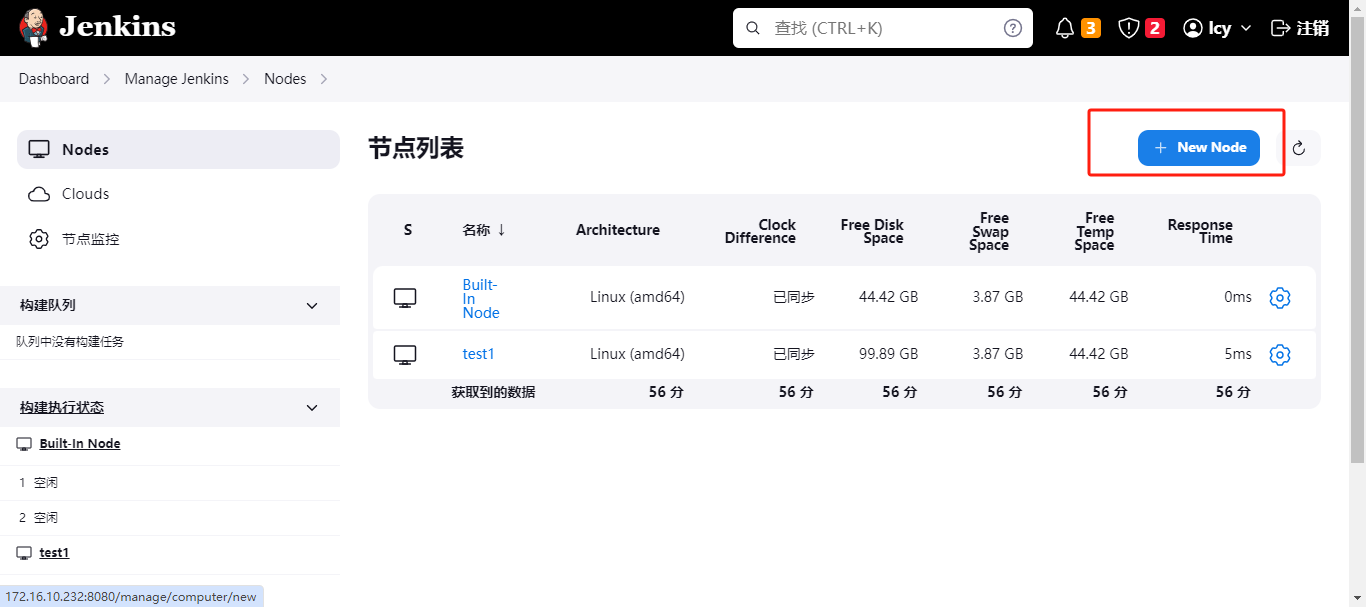
这里可以自己写节点名称,这里测试我就写test1了。
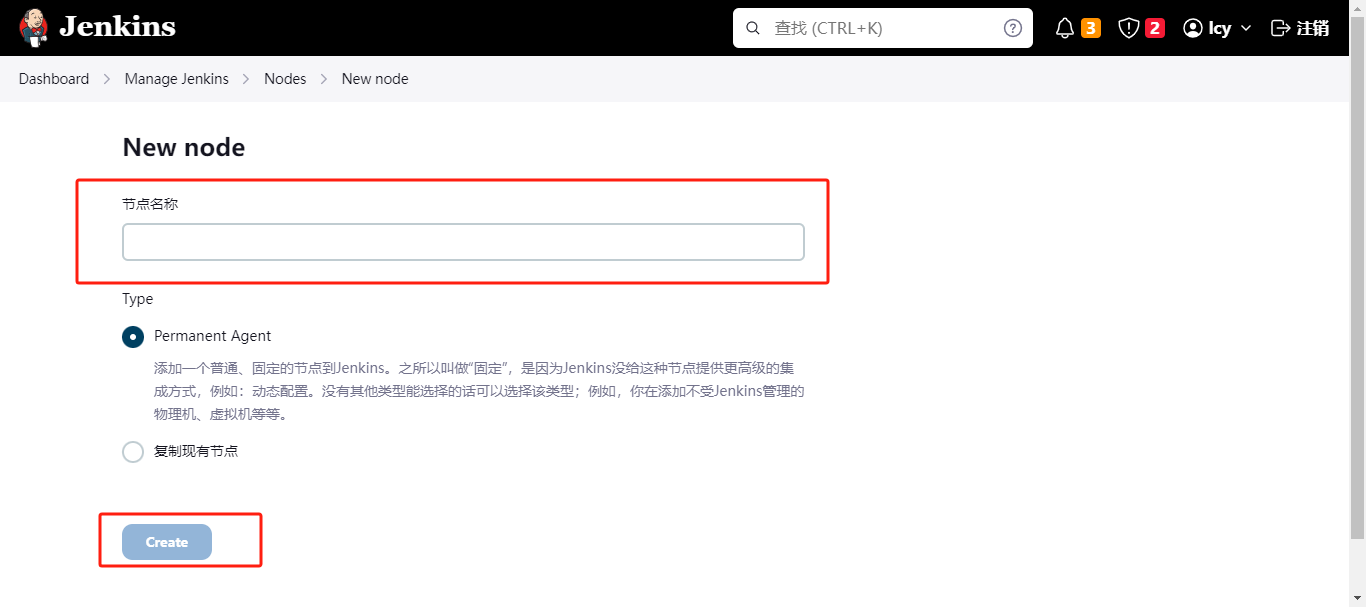
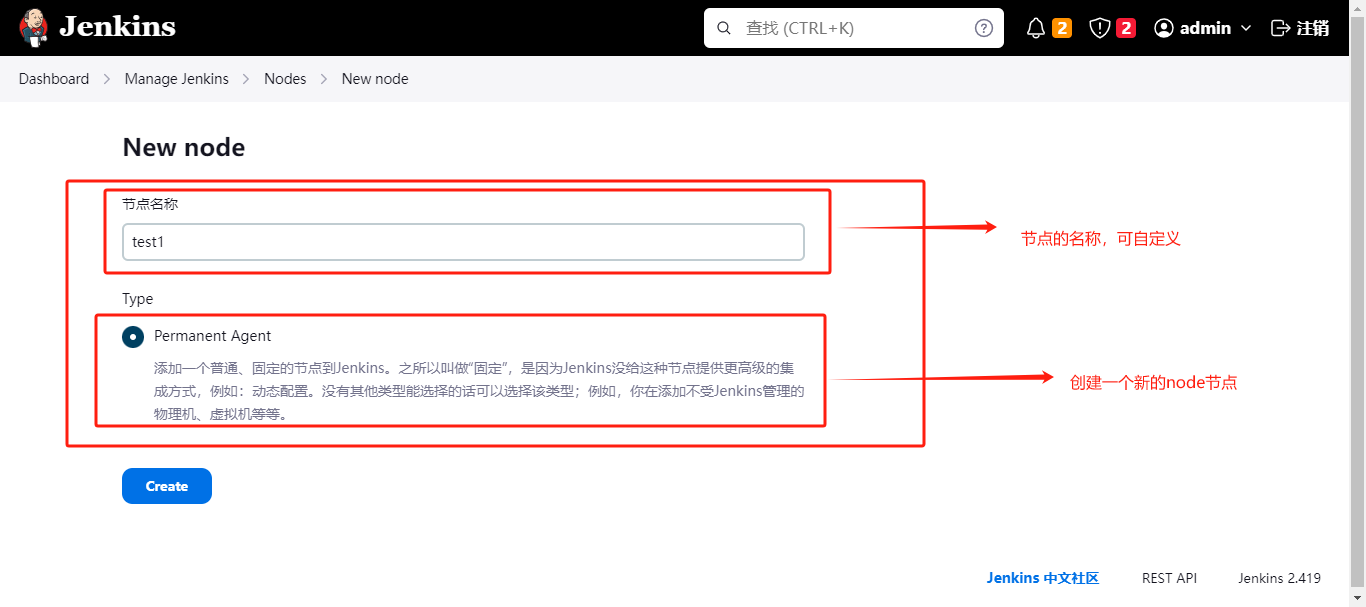
写完之后点击create创建即可,创建完之后会跳转到里面进行配置node信息。
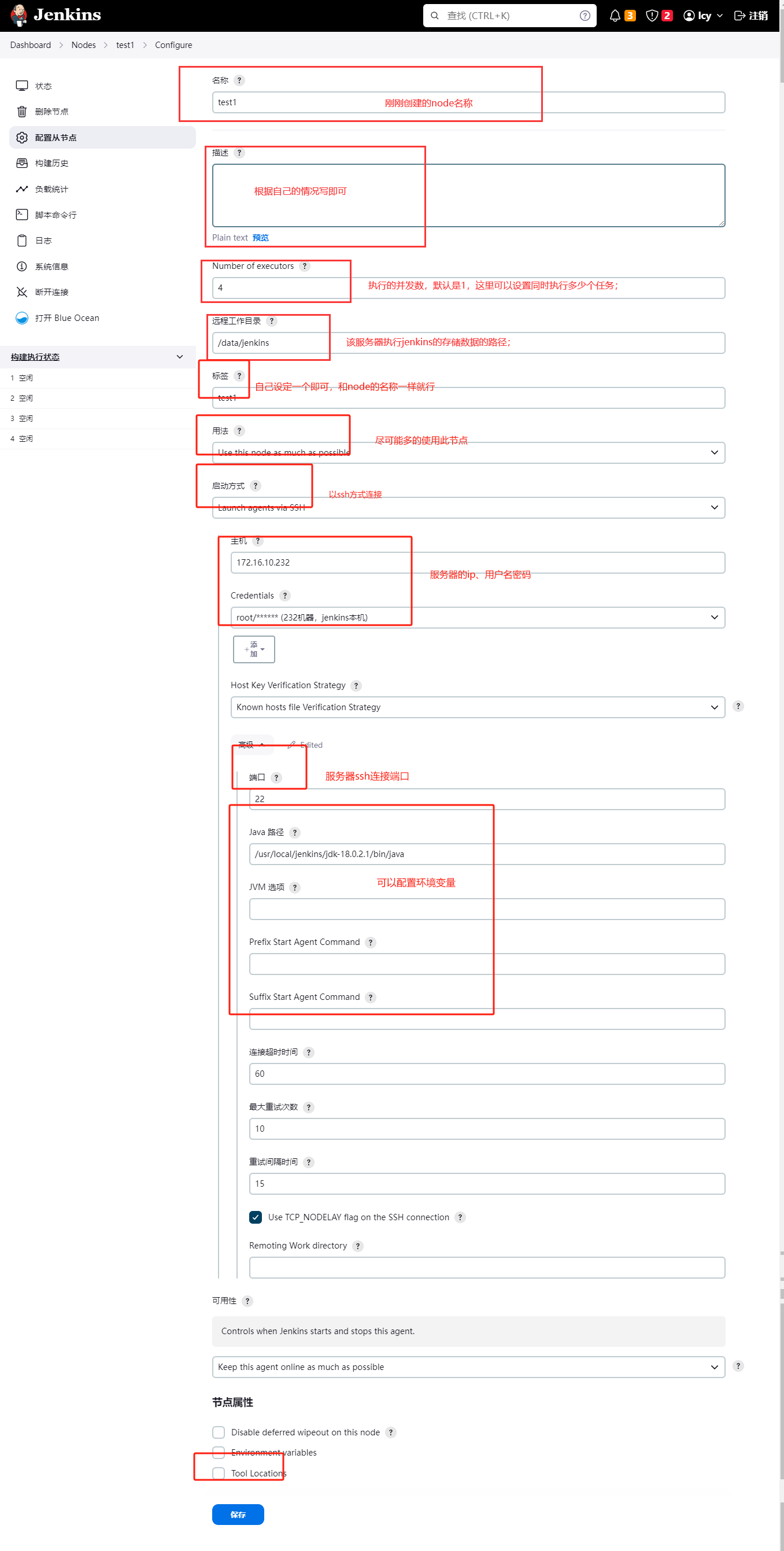
点击保存即可;
- 使用ssh登录需要设置两台服务器之间免密登录;否则会报错连接失败;
双方都需要配置免密登录。
免密登录命令:
1.进入.ssh目录: cd ~/.ssh # 如果新机器没有这个命令,可以直接生产密钥,最自动创建这个目录。
2.生成一对密钥: ssh-keygen -t rsa
3.发送公钥: ssh-copy-id 172.16.xx.xxx
4.免密登录测试: ssh 172.16.xx.xxx
配置完之后可以进行连接了。
保存完点击刚刚创建的node节点,点进去,然后点击侧边的日志,可以看到连接情况;
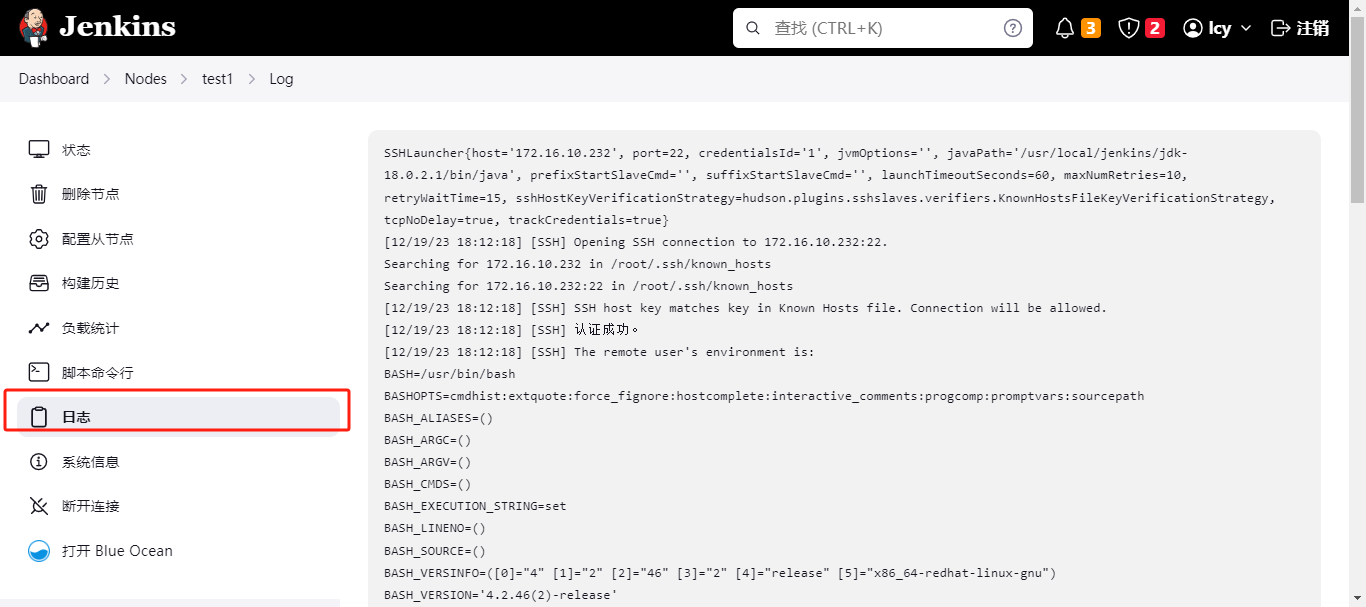
连接成功会显示已同步:

agent
agent 部分指明了pipeline脚本在哪台机器或者容器内执行,因为jenkins的工作模式是master-agent模式,master可以把流水线任务的执行放到其代理节点上执行。
同时jenkins的节点(master节点或者agent代理节点)可以打上标签,如下表示的是pipeline脚本需要在标签为test1的节点上运行。 – > 测试前需要有这个test1节点,如果没有会报错,或根据自己的节点标签来修改一下。
pipeline {
agent {
label 'test1'
}
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
}
}
}
agent模块也可以写到stage里,表示特定stage模块都在指定的agent节点上运行,如下所示:
pipeline {
agent any
stages {
stage('Hello') {
agent {
label 'test1'
}
steps {
echo 'Hello World'
}
}
}
}
在文章开头的hello world的脚本中,agent我们指定了any,这表示可以在任意节点上运行pipeline脚本。agent模块不可省略不写。
stages
接着来看下stages模块,stages模块由多个stage组成,一个stage表示一个阶段,比如我们通常将发布的整个流程分为编译,传输,部署等几个阶段。
stage
一个stages可以有多个stage;一个stage表示一个阶段,比如我们通常将发布的整个流程分为编译,传输,部署等几个阶段。
steps
一个阶段由多个步骤组成,在pipeline语法中,步骤通过steps模块表示,steps包含了一个或多个步骤,在上述hello world的pipeline脚本中,echo ‘Hello World’ 就是一个步骤,比如我们想要执行shell命令就要运行sh步骤,如下所示:
- 一个steps包含
一个执行步骤
pipeline {
agent any
stages {
stage('Hello') {
steps {
sh 'ping 127.0.0.1 -c 10'
}
}
}
}
- 一个steps包含
多个执行步骤
pipeline {
agent any
stages {
stage('Hello') {
steps {
sh 'ping 127.0.0.1 -c 10'
sh 'hostname -I'
}
}
}
}
pipeline的步骤是可插拔的,可以通过安装某些插件来执行特定的步骤。【Blue Ocean】
post
除了上述模块,还可以在stages或者steps模块后面定义post模块来表示整个pipeline执行完成或者单个stage完成后需要执行的动作。
pipeline {
agent any
stages {
stage('post') {
steps {
sh 'ping 127.0.0.1 -c 5 && hostname -I'
}
post{
}
}
}
}
此时的post模块是不可以构建的,因为里面是空的什么条件都没有,会报错,所以里面需要加一些条件块(根据自己的情况来定义);
post模块可以定义多个条件块,条件块里写上要执行的步骤,条件块有以下几种,
- always: 无论当前执行结果是什么状态都执行
- emailext:邮件服务,执行发送邮件(需要安装mail插件)
- changed: 只有当前流水线或阶段的完成状态与它之前的运行不同时,才允许在
post部分运行该步骤。 - fixed: 上一步为失败或不稳定(unstable) ,当前状态为成功时
- regression: 上一次完成状态为成功,当前完成状态为失败、不稳定或中止(aborted)时执行。
- aborted: 当前执行结果是中止状态时(一般为人为中止)执行,通常web UI是灰色。
- failure:当前完成状态为失败时执行,通常web UI是红色。
- success:当前完成状态为成功时执行,通常web UI是蓝色或绿色。
- unstable:当前完成状态为不稳定时执行,通常由于测试失败,代码违规等造成。通常web UI是黄色。
- cleanup:清理条件块。不论当前完成状态是什么,在其他所有条件块执行完成后都执行。
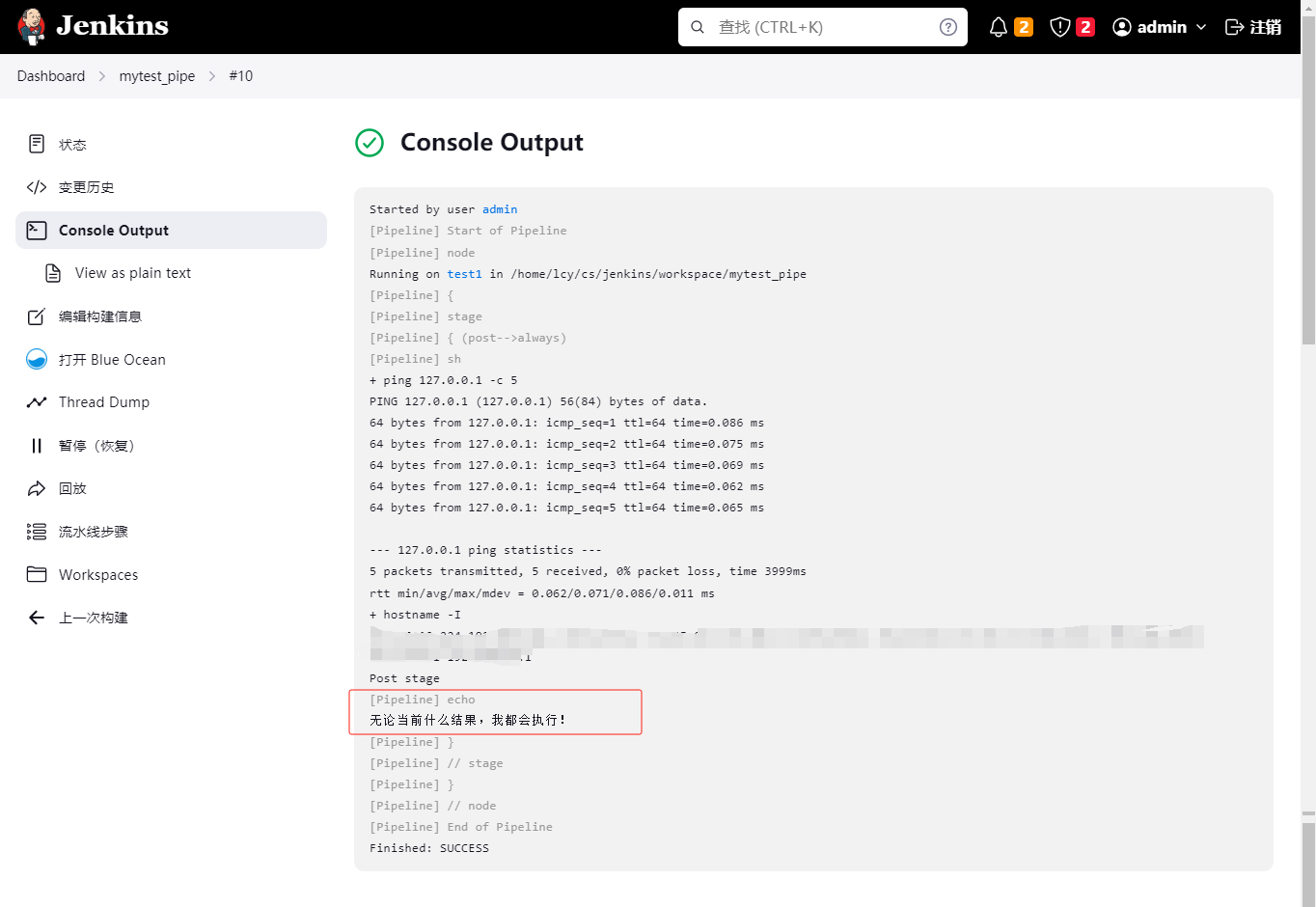
- post - always
pipeline {
agent any
stages {
stage('post-->always') {
steps {
sh 'ping 127.0.0.1 -c 5 && hostname -I'
}
post{
always{
echo "无论当前什么结果,我都会执行!"
}
}
}
}
}
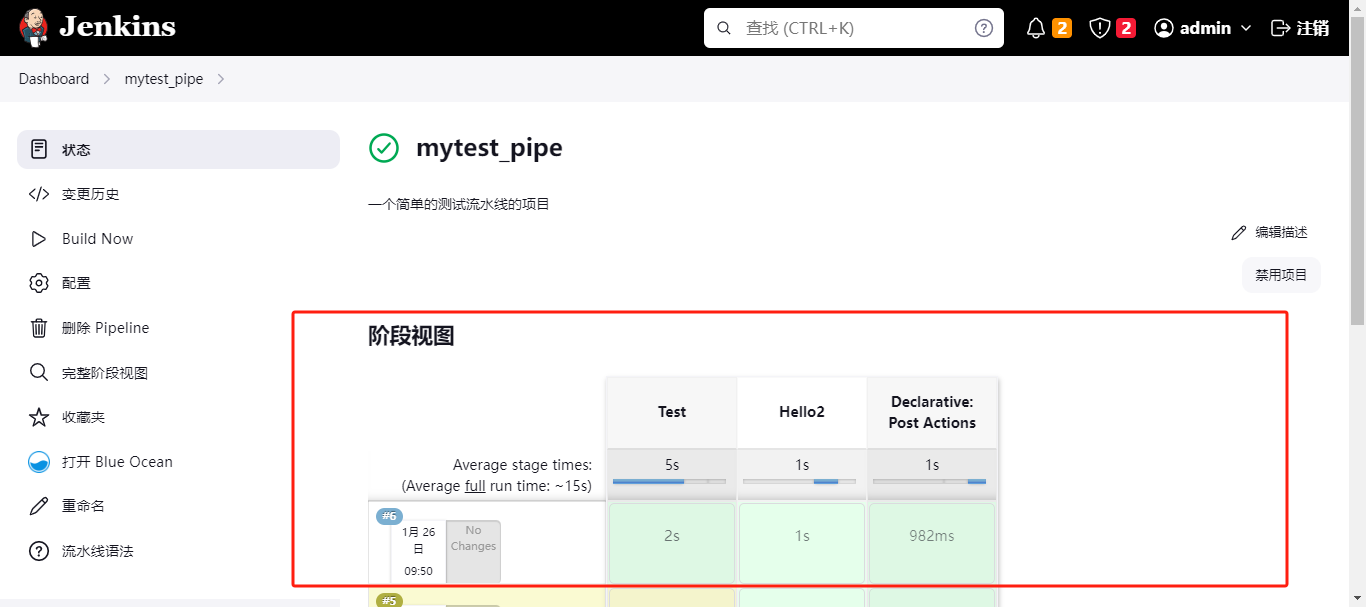
- post - failure/success/unstable
这里再着重解释下unstable 状态,通常我们将测试失败的状态设定为unstable,可以把它理解成日志等级的warn状态。如下我们可以主动设置stage和构建结果为unstable状态。
pipeline {
agent any
stages {
stage('Test') {
steps {
echo "Test"
}
}
stage('Hello2') {
steps {
echo 'hello'
}
}
}
post {
failure {
echo "failure"
}
success {
echo "success"
}
unstable {
echo "unstable"
}
}
}
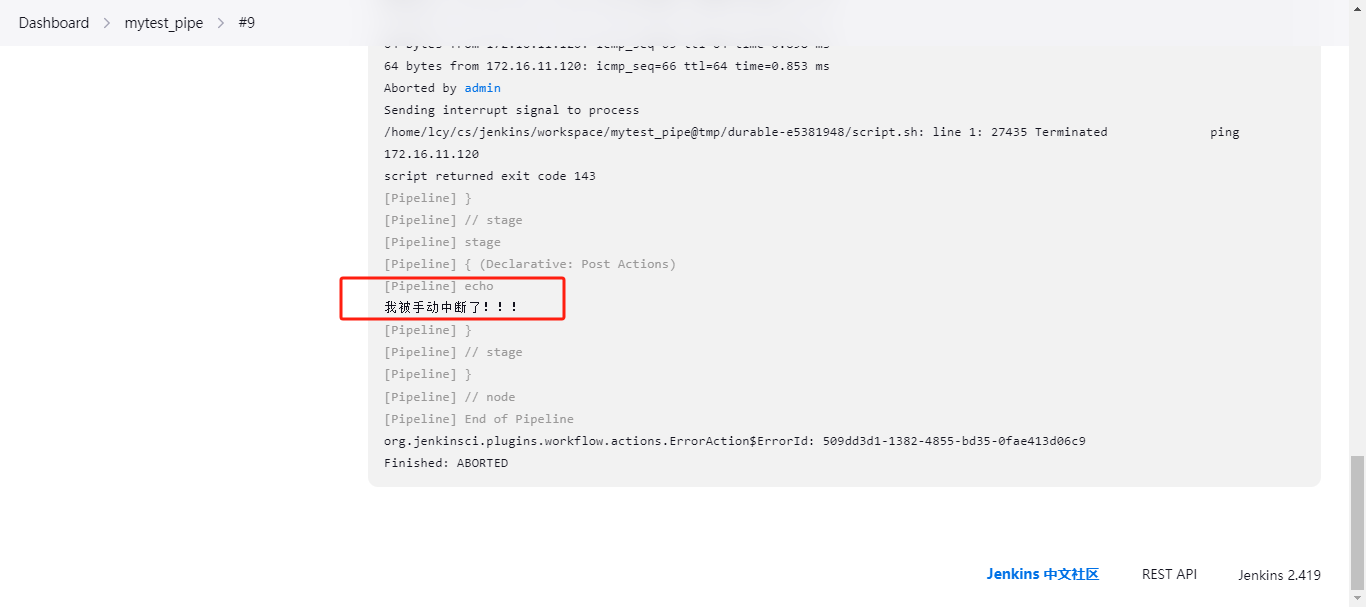
- post - aborted
手动终端运行中的服务;
pipeline {
agent any
stages {
stage('ping') {
steps {
sh 'ping 172.16.11.120'
}
}
}
post {
aborted {
echo "我被手动中断了!!!"
}
failure {
echo "failure"
}
success {
echo "success"
}
unstable {
echo "unstable"
}
}
}
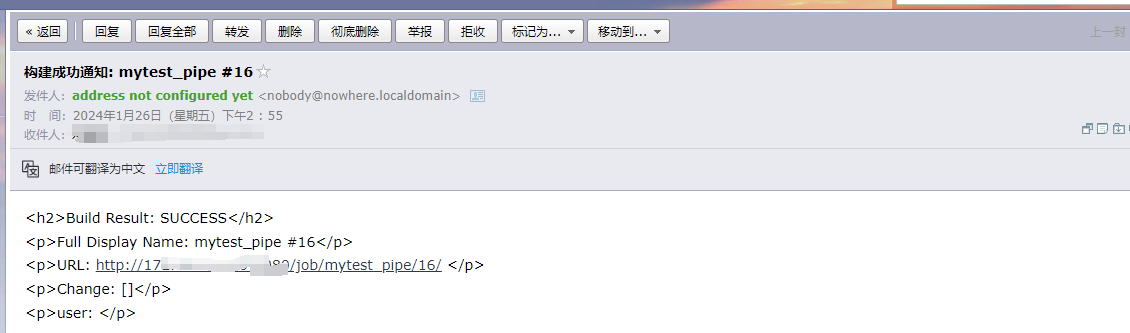
- post - always - emailext
发送邮件测试。需要提前安装好 mail 邮件的插件。
pipeline {
agent any
stages {
stage('post-->always') {
steps {
sh 'ping 127.0.0.1 -c 5 && hostname -I'
}
post{
always{
echo "无论当前什么结果,我都会执行!"
sh 'hostname -I | awk -F " " \'{print $1}\''
emailext(
to: "*********@qq.com",
subject: "执行成功通知: " + currentBuild.fullDisplayName,
body:
"""
<h2>Build Result: ${currentBuild.result}</h2>
<p>Full Display Name: ${currentBuild.fullDisplayName}</p>
<p>URL: ${currentBuild.absoluteUrl} </p>
<p>Change: ${currentBuild.changeSets}</p>
<p>user: </p>
"""
)
}
}
}
}
}
① 按照惯例,
post部分应该放在流水线的底部。
environment
environment 用于设置环境变量,可定义在stage或pipeline部分。
- 在 pipeline 中定义 environment, 表示 pipeline 全局使用的环境变量
- 在 stage 中定义 environment, 表示当前 stage 的环境变量
environment 指令指定一系列键值对,这些键值对将被定义为所有step或stage-specific step的环境变量,具体取决于environment指令在Pipeline中的位置。
该指令支持一种特殊的方法credentials(),可以通过其在Jenkins环境中的标识符来访问预定义的凭据。
对于类型为“Secret Text”的凭据,该 credentials()方法将确保指定的环境变量包含Secret Text内容;对于“标准用户名和密码”类型的凭证,指定的环境变量将被设置为username:password。
- 在“pipeline”级别中:(全局都可以用:全局变量)
pipeline {
agent any
environment {
IP = '127.0.0.1'
IP_Port = '8080'
}
stages {
stage('environment-->pipeline') {
steps {
sh 'ping ${IP} -c 5 && hostname -I'
sh 'curl ${IP}:${IP_Port}'
}
}
}
}
-
在“stage”级别中:(只可以在写environment 的 stage 中使用)
-
stage – > environment 正确示范
pipeline {
agent any
stages {
stage('environment-->stage1') {
environment {
IP = '127.0.0.1'
}
steps {
sh 'ping ${IP} -c 5 && hostname -I'
}
}
stage('environment-->stage2') {
environment {
IP2 = '127.0.0.1'
IP_Port = '8080'
}
steps {
sh 'curl ${IP2}:${IP_Port}'
}
}
}
}
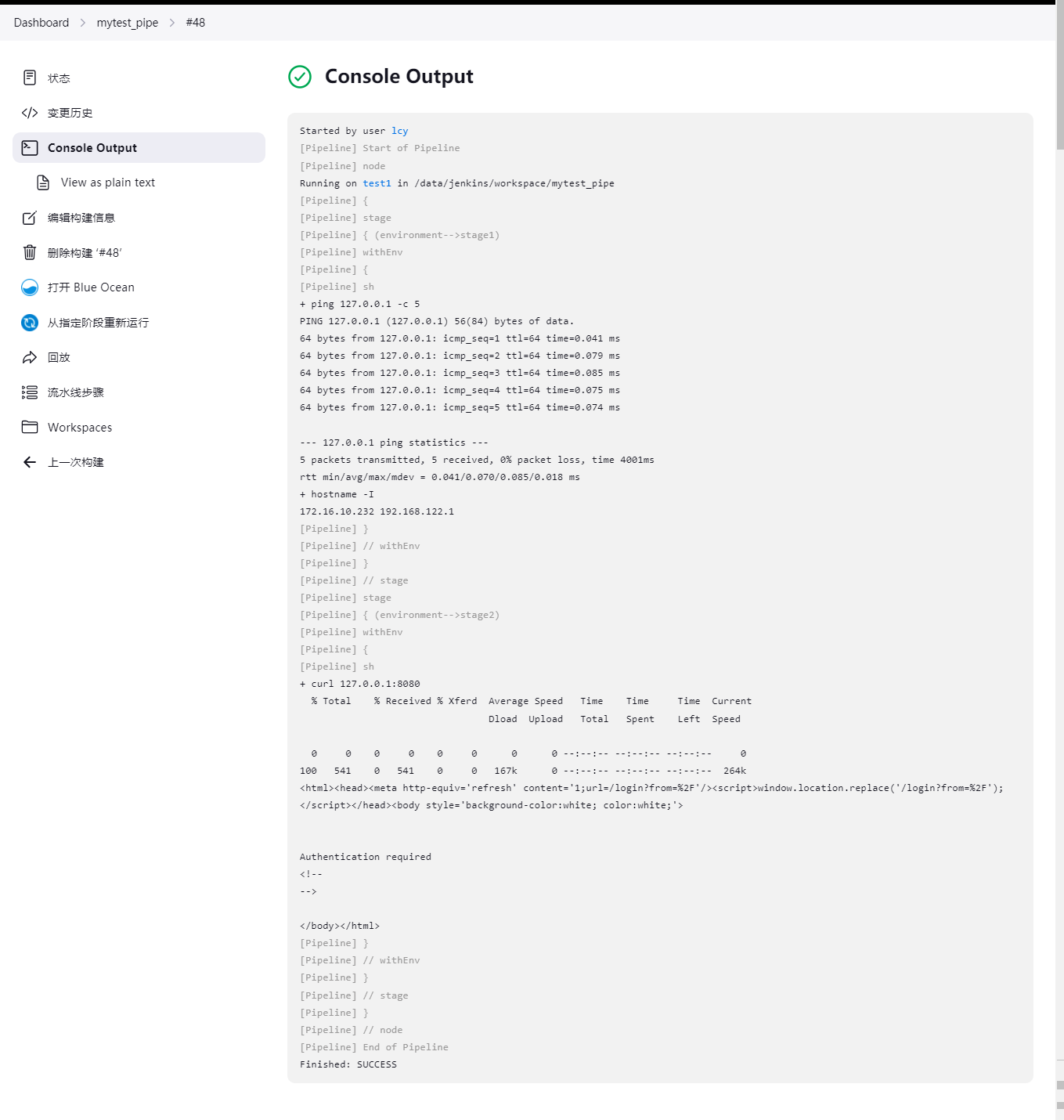
代码分析:

- stage – > environment 错误示范
pipeline {
agent any
stages {
stage('environment-->stage1') {
environment {
IP = '127.0.0.1'
}
steps {
sh 'ping ${IP} -c 5 && hostname -I'
}
}
stage('environment-->stage2') {
steps {
sh 'ping ${IP} -c 5 && hostname -I'
}
}
}
}
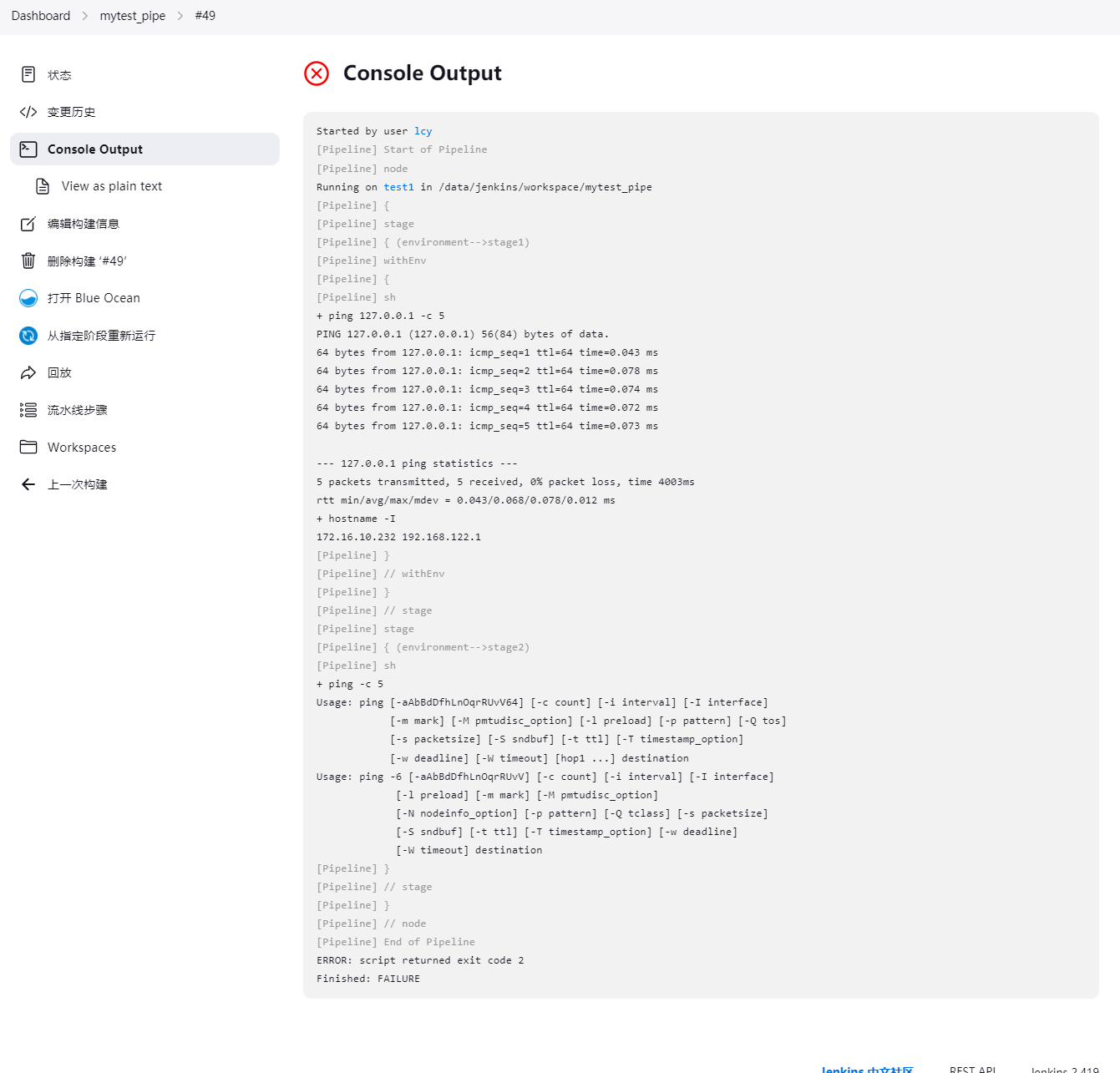
代码分析:

除了自定义的这几个环境变量之后,我们还有系统自带的全局环境变量,可访问:http://ip:port/job/项目名/pipeline-syntax/globals
注:ip:port 替换为自己的ip和端口;项目名就换成自己的项目名就行;
也可以通过其他方式进入:进入到流水线编辑页面,翻到最下面点击流水线语法,点进去会跳转到一个新的页面,展示的是一个生产流水线语法的脚本,再往下面翻,到最后,可以看到一个全局变量,点击文字中有一段: Global Variables Reference即可进入全局环境变量的页面;这里有使用说明,下面给大家说一些常用的。
-
系统的环境变量有三种引用方式:
-
${env.BUILD_NUMBER} 方式一,(推荐使用)
-
$env.BUILD_NUMBER 方式二,
-
${BUILD_NUMBER} 方式三,(不推荐使用)
-
内置的环境变量
| 变量 | 说明 |
|---|---|
| BUILD_ID | 当前构建的 ID,与 Jenkins 版本 1.597+ 中创建的构建号 UILD_NUMBER 是完全相同的。 |
| BUILD_NUMBER | 当前构建号,比如 “153”。 |
| BUILD_TAG | 字符串 jenkins-${JOB_NAME}-${BUILD_NUMBER}。可以放到源代码、jar 等文件中便于识别。 |
| BUILD_URL | 可以定位此次构建结果的 URL(比如 http://buildserver/jenkins/job/MyJobName/17/ ) |
| EXECUTOR_NUMBER | 用于识别执行当前构建的执行者的唯一编号(在同一台机器的所有执行者中)。这个就是你在“构建执行状态”中看到的编号,只不过编号从 0 开始,而不是 1。 |
| JAVA_HOME | 如果你的任务配置了使用特定的一个 JDK,那么这个变量就被设置为此 JDK 的 JAVA_HOME。当设置了此变量时,PATH 也将包括 JAVA_HOME 的 bin 子目录。 |
| JENKINS_URL | Jenkins 服务器的完整 URL,比如 https://example.com:port/jenkins/ (注意:只有在“系统设置”中设置了 Jenkins URL 才可用)。 |
| JOB_NAME | 本次构建的项目名称,如 “foo” 或 “foo/bar”。 |
| NODE_NAME | 运行本次构建的节点名称。对于 master 节点则为 “master”。 |
| WORKSPACE | workspace 的绝对路径。 |
tools
可以在流水线级别或阶段级别添加“tools”指令。它允许您指定要在脚本上使用的Maven,JDK或Gradle版本。必须在“全局工具配置”Jenkins菜单上配置这些工具中的任何一个,在撰写本文时,这三个工具都受支持。另外,Jenkins将尝试安装列出的工具(如果尚未安装)。通过使用此指令,可以确保安装了项目所需的特定版本。
pipeline {
agent any
tools {
maven 'apache-maven-3.0.1' 工具名称必须在Jenkins 管理Jenkins → 全局工具配置中预配置。
}
stages {
stage("tools") {
steps {
echo 'do something'
}
}
}
}
这个一般用的好像很少,我基本没用过。
input
“input”指令在阶段级别(stage)定义,提供提示输入的功能。该阶段将被暂停,直到用户手动确认为止。以下为配置选项可用于此指令:
- message:这是必需的选项,其中指定了要显示给用户的消息。
- id:可选标识符。默认情况下,使用“阶段”名称。
- ok:“确定”按钮的可选文本。
- submitter:参数允许你指定哪些用户或用户组可以提交输入以继续 Pipeline 的执行。这个参数可以是一个以逗号分隔的用户列表或用户组名。如果你不提供
submitter参数,那么默认情况下,任何用户都可以提交输入来继续 Pipeline。通过设置submitter参数,你可以实现权限控制,确保只有特定的用户或用户组能够批准 Pipeline 的继续执行。这对于需要特定人员审批或审核的 Pipeline 流程非常有用。 - submitterParameter:要使用提交者名称设置的环境变量的可选名称(如果存在)。
- parameters:允许你指定一个参数列表,这些参数会在
input表单中显示,并要求用户在提交输入时提供相应的值。这些参数可以是各种类型,如单行文本、布尔值、选项参数等。它们为用户提供了一个界面,以便在继续 Pipeline 执行之前输入必要的信息。
这是包含此指令的示例流水线:
pipeline {
agent any
stages {
stage ('input') {
input{
message "请输入用户名密码:"
submitter "user1,user2"
parameters {
string(name:'username', defaultValue: 'user', description: 'Username of the user pressing Ok')
string(name:'passwd', defaultValue: '123123123', description: 'Username of the user pressing Ok')
}
}
steps {
echo "User: ${username} said Ok."
echo "User: ${passwd} said OK."
}
}
}
}
- 解析:
input:存在于阶段级别(stage)中定义;
message:这个是必须的选项,没有此参数就会运行失败;用于给用户提示输入什么;
submitter:允许提交的用户名,如果不是
submitter中的用户名提交则失败;parameters:提供一个新的界面输入指定参数。
执行构建查看运行台,会卡到这,让你点进去输入执行参数,此input requested是parameters设定的。
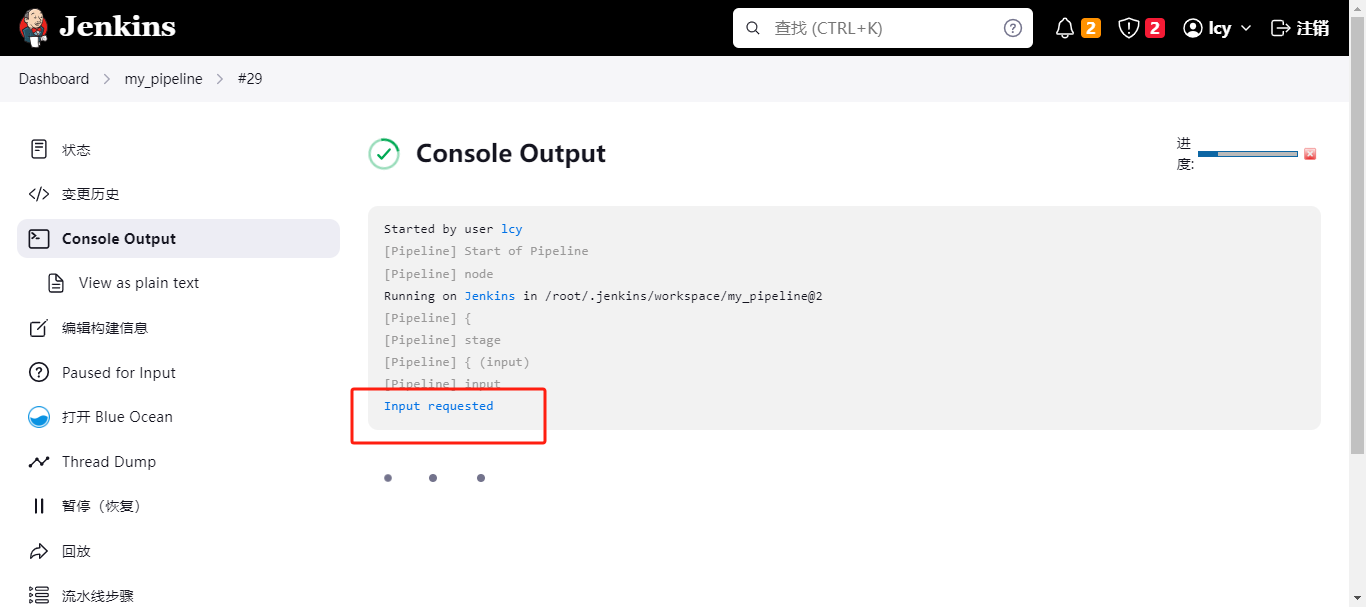
点击进入跳转到此,会有一个默认的用户名和密码,是在parameters中设定的默认值。
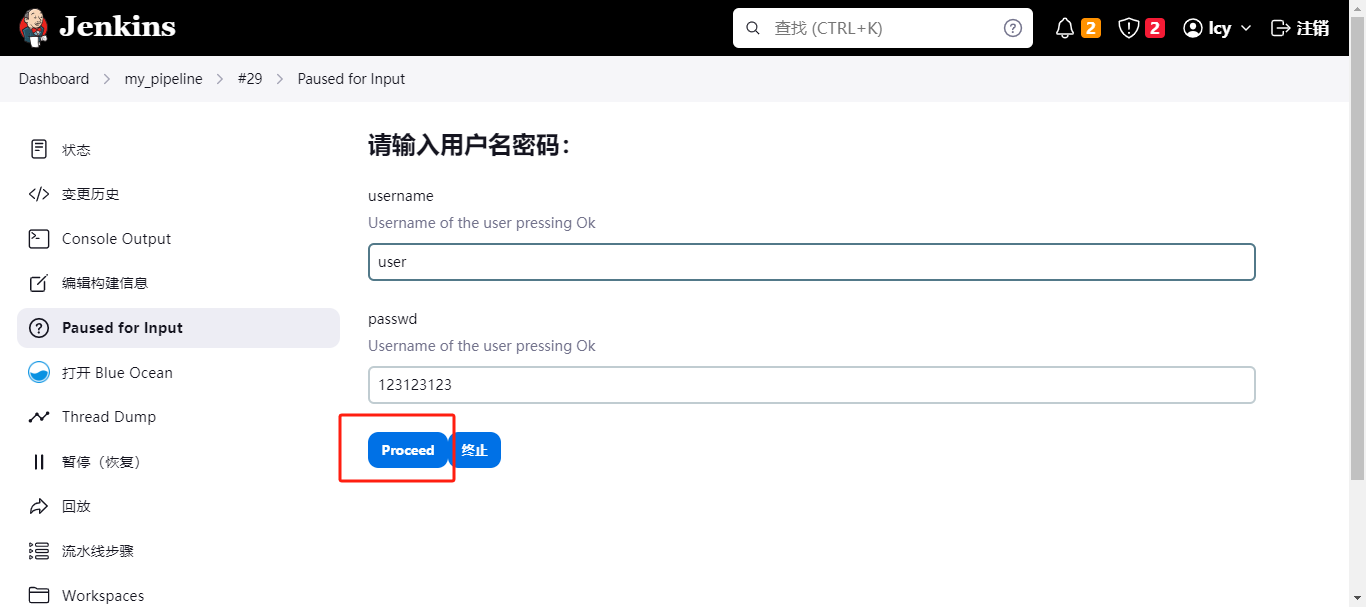
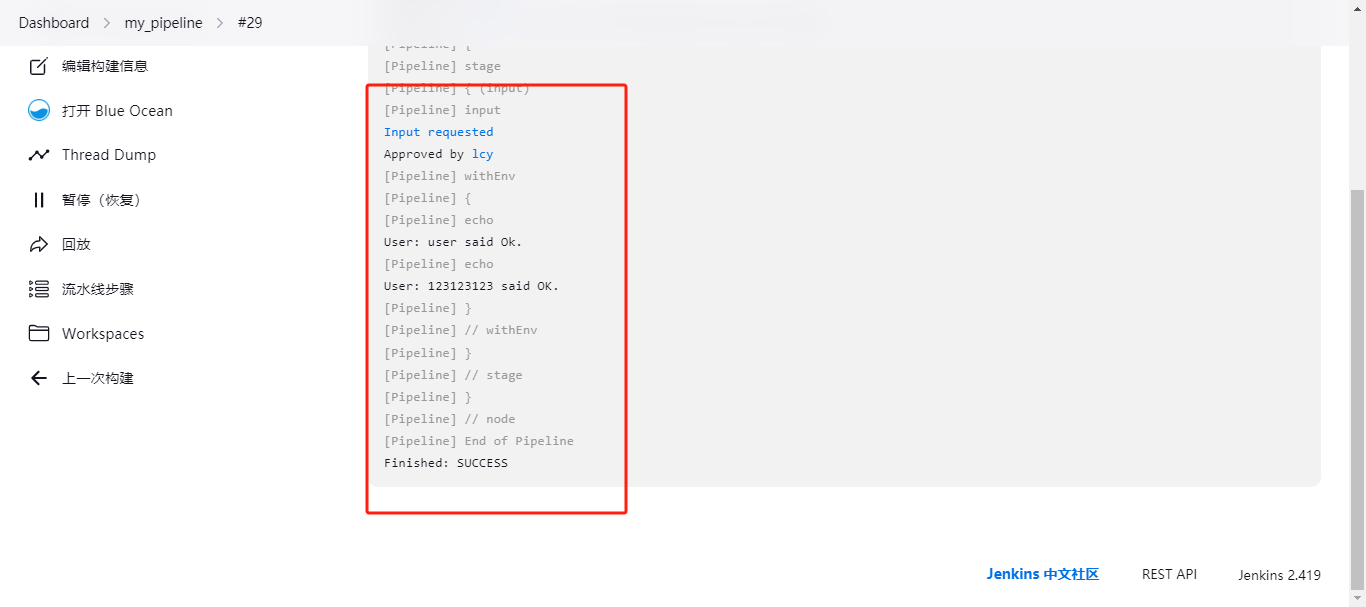
点击继续即可;
parameters
parameters与input不同,parameters是执行pipeline前传入的一些参数。parameters 指令通常定义在 pipeline 的顶层,也就是不在任何 stage 或 step 内部。这意味着这些参数在 pipeline 开始执行之前就需要被指定,并且可以在整个 pipeline 中访问。parameters指令提供用户在触发Pipeline时的参数列表。这些参数值通过该params对象可用于Pipeline步骤
目前只支持[booleanParam, choice, credentials, file, text, password, run, string]这几种参数类型,其他高级参数化类型还需等待社区支持。
Jenkins 支持多种类型的参数,包括:
string:单行文本输入。boolean:布尔值选择(通常是复选框)。choice:从预定义选项列表中选择。password:密码输入,通常用于敏感信息的输入。file:允许用户上传文件。
下面是一个简单的示例,展示了如何在 Jenkins Pipeline 中使用 parameters 指令:
pipeline {
agent any
// 定义参数
parameters {
string(name: 'PERSON', defaultValue: 'World', description: '输入你的名字')
choice(name: 'GREETING', choices: ['Hello', 'Hi', 'Good morning'], description: '选择问候语')
}
stages {
stage('Greeting') {
steps {
// 使用参数
echo "Hello, ${PERSON}, nice to meet you."
echo "Using greeting: ${GREETING}"
}
}
}
}
在这个例子中,我们定义了两个参数:PERSON 和 GREETING。PERSON 是一个字符串参数,默认值为 ‘World’,用户可以在执行 pipeline 时输入自己的名字。GREETING 是一个选择参数,提供了三个预定义选项。
在 Greeting 阶段中,我们使用 echo 步骤来输出这些参数的值。${PERSON} 和 ${GREETING} 是参数的引用,它们会被替换为用户在执行 pipeline 时输入的实际值。
通过在 pipeline 中使用 parameters 指令,你可以让用户提供自定义输入,使得 pipeline 更加灵活和可配置。
- 保存点击构建
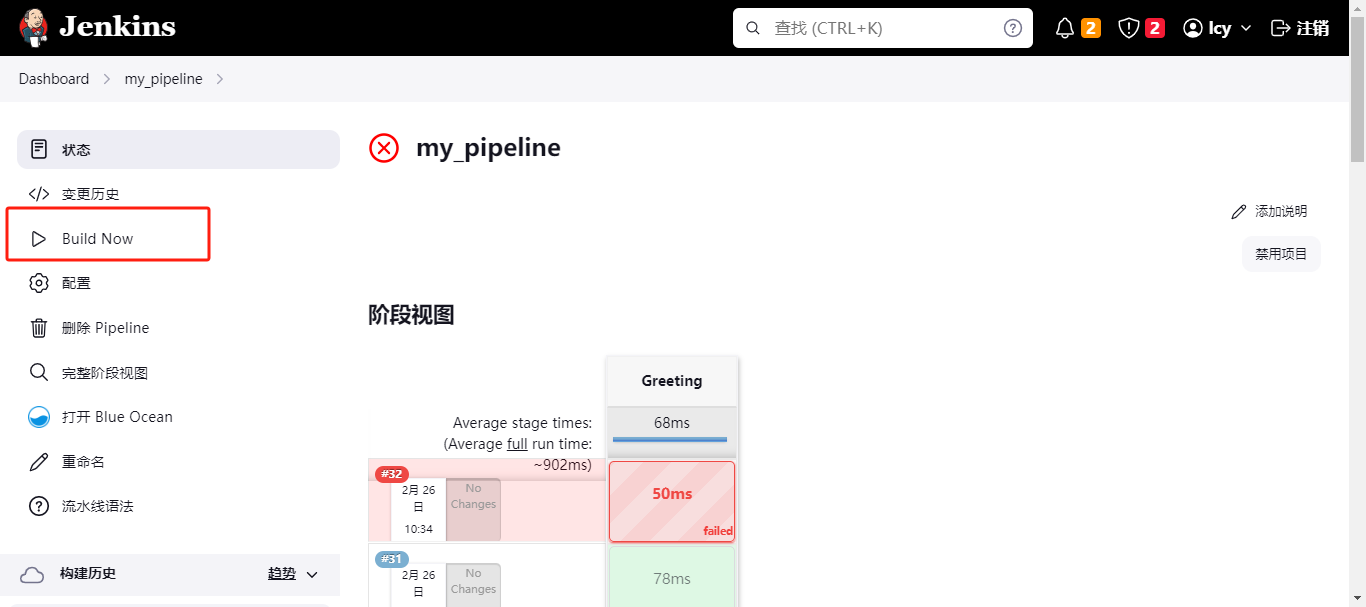
- 第一次会构建失败,然后我们可以看到,构建的标志变了,变成了
Build with Parameters,然后再次点击一下即可,就会跳到以下界面;
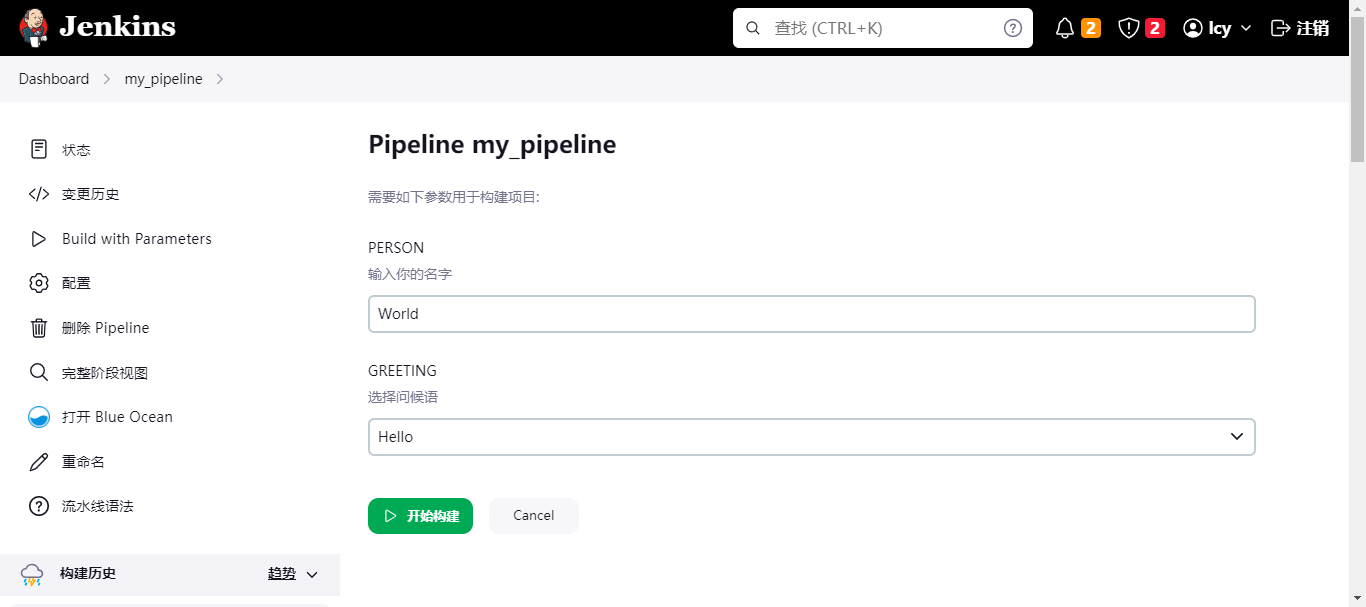
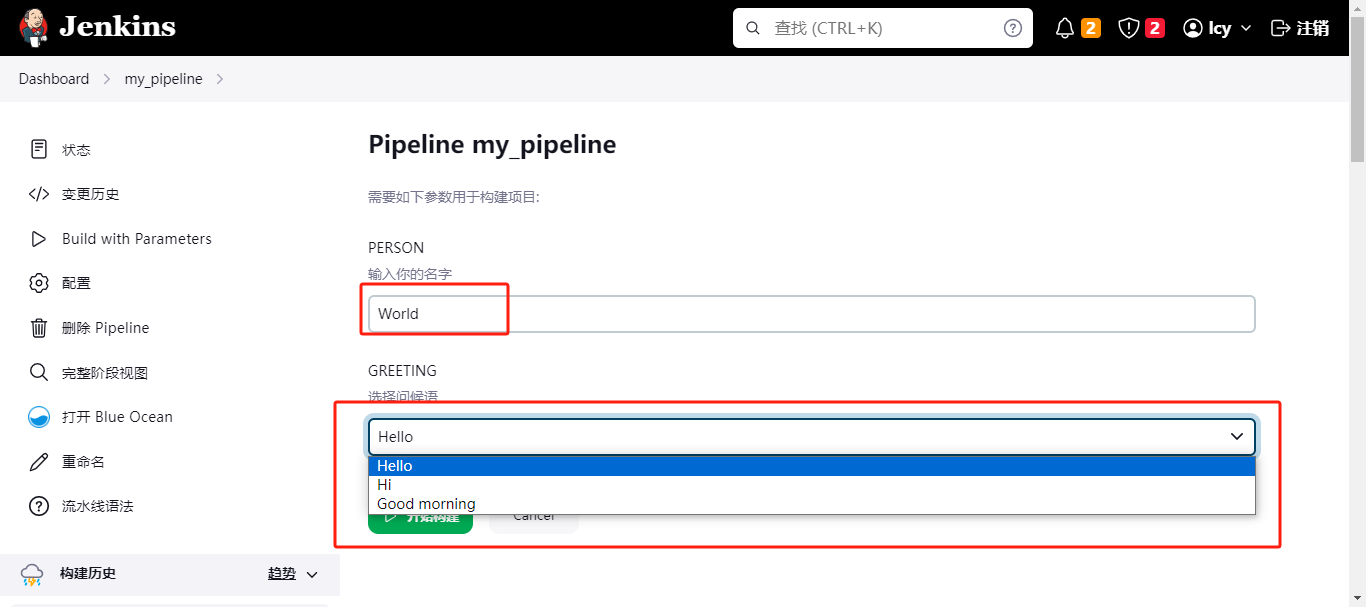
- 第一个是输入你的名字,可以随便写一个;第二个是一个选项框,提供了三个选项,可以任意选;
- 然后在开始点击构建,就会输入echo里的数据及变量信息;
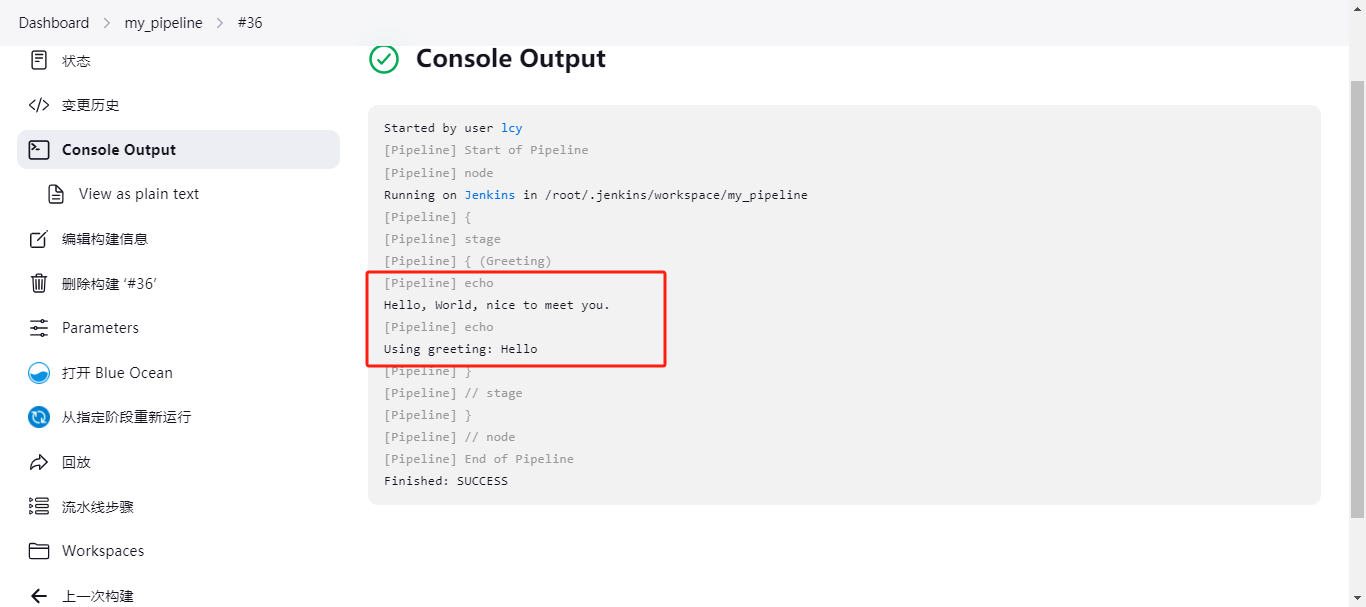
执行成功。
options
用于配置Jenkins pipeline本身的选项,比如options {retry(3)}指当pipeline失败时再重试2次。options指令可定义在stage或pipeline部分。
disableConcurrentBuilds
- 不允许并行执行Pipeline,可用于防止同时访问共享资源等。例如:options { disableConcurrentBuilds() }
skipDefaultCheckout
- 默认跳过来自源代码控制的代码。例如:options { skipDefaultCheckout() }
skipStagesAfterUnstable
一旦构建状态进入了“Unstable”状态,就跳过此stage。例如:options { skipStagesAfterUnstable() }
timeout
- 设置Pipeline运行的超时时间。例如:options { timeout(time: 1, unit: ‘HOURS’) }
retry
- 失败后,重试整个Pipeline的次数。例如:options { retry(3) }
timestamps
- 预定义由Pipeline生成的所有控制台输出时间。例如:options { timestamps() } |
pipeline {
agent any
options {
retry(3) //将流水线配置为在失败前重试3次:
}
stages {
echo 'do something'
}
}
parallel
parallel 并行执行多个step。在pipeline插件1.2版本后,parallel开始支持对多个阶段进行并行执行。
Jenkins流水线阶段可以在内部嵌套其他阶段,这些阶段将并行执行。我们来举一个简单的例子:
注意:在Jenkins的Pipeline语法中,
parallel应该被放置在stages块内部的一个stage的steps块中。所以要非常注意!
pipeline {
agent any
stages {
stage('Example Stage') {
steps {
// 第一个步骤
echo 'This is the first step.'
// 第二个步骤,依赖于第一个步骤成功执行
sh 'echo This step runs after the first one.'
// 第三个步骤,与前两个步骤并行执行(需要使用 parallel)
parallel {
stage('Parallel_test 1') {
steps {
echo 'This is parallel test1.'
}
}
stage('Parallel_test 2') {
steps {
sh 'echo "This is parallel test2."'
}
}
}
// 第四个步骤,依赖于所有并行步骤成功执行
echo 'All parallel steps have completed.'
}
}
}
}
tiggers
tiggers主要用于定义执行pipeline的触发器。
触发器允许Jenkins通过使用以下任何一个可用的方式自动触发流水线:
- cron:通过使用cron语法,它可以定义何时重新触发管道。
- pollSCM:通过使用cron语法,它允许您定义Jenkins何时检查新的源存储库更新。如果检测到更改,则将重新触发流水线。(从Jenkins 2.22开始可用)。
- upstream:将Jenkins任务和阈值条件作为输入。当列表中的任何任务符合阈值条件时,将触发流水线。
带有可用触发器的示例流水线如下所示(需要注意的是,第一次执行了之后会在每分钟都执行一遍任务):
- cron:按照cron给的时间执行;
pipeline {
agent any
triggers {
//每分钟执行一次
cron('* * * * *')
}
stages {
stage('test tiggers-cron') {
steps {
echo 'Tish is test tiggers project -- cron.'
}
}
}
}
- pollSCM:如果检测到更改,则将重新触发流水线;
pipeline {
agent any
triggers {
//每分钟执行一次
pollSCM('* * * * *')
}
stages {
stage('test tiggers-pollSCM') {
steps {
echo 'Tish is test tiggers project -- pollSCM.'
}
}
}
}
- upstream:当列表中的任何任务符合阈值条件时,将触发流水线。
pipeline {
agent any
triggers {
//Execute when either job1 or job2 are successful
upstream(upstreamProjects: 'job1, job2', threshold: hudson.model.Result.SUCCESS)
}
stages {
stage('test tiggers-upstream') {
steps {
echo 'Tish is test tiggers project -- upstream.'
}
}
}
}
when
当满足when定义的条件时,阶段才执行(相当于一个判断)。when指令必须至少包含一个条件。如果when指令包含多个条件,则所有子条件必须为stage执行返回true。这与子条件嵌套在一个allOf条件中相同更复杂的条件结构可使用嵌套条件建:not,allOf或anyOf。嵌套条件可以嵌套到任意深度
-
内置条件
-
branch
- 当正在构建的分支与给出的分支模式匹配时执行,例如:when { branch ‘master’ }。请注意,这仅适用于多分支Pipeline。
可读方式解析:相当于指定一个分支,如果是这个分支就执行此操作;
- environment
- 当指定的环境变量设置为给定值时执行,例如: when { environment name: ‘DEPLOY_TO’, value: ‘production’ }
可读方式解析:相当于,当使用此环境变量时,环境变量的值等于设置的值就会执行;
- expression
- 当指定的Groovy表达式求值为true时执行,例如: when { expression { return params.DEBUG_BUILD } }
可读方式解析:表达式返回的值为true(真)时就执行此操作;
- not
- 当嵌套条件为false时执行。必须包含一个条件。例如:when { not { branch ‘master’ } }
可读方式解析:当指定的值不是not里的值就可以执行;
- allOf
- 当所有嵌套条件都为真时执行。必须至少包含一个条件。例如:when { allOf { branch ‘master’; environment name: ‘DEPLOY_TO’, value: ‘production’ } }
可读方式解析:相当于
或者,只要满足某一个条件的值就可以执行此操作;条件最少要写两个。
- 使用方法:
1.when 仅用于stage内部 2. when 的内置条件
- when {branch ‘master’} #当是master的时候,才执行某些事情
- when {envionment name:‘DEPLOY_TO’,value:‘production’} #当环境变量name 的值是production的时候,才执行某些事情
- when {expression {return params.DEBUG_BUILD}} #表达式的返回值是真的情况下,才执行
- when {not {branch ‘master’}}#不是master的情况下,执行
- when {allOf {branch ‘master’; environment name: ‘DEPLOY_TO’,value:‘production’}} #当大括号中所有的项都成立,才去做某些事情
- when {anyOf {branch ‘master’; branch ‘staging’}} #只要满足大括号里面的某一个条件,才去做某些事情
例如,流水线使您可以在具有多个分支的项目上执行任务。这被称为多分支流水线,其中可以根据分支名称(例如“master”,“ feature*”,“development”等)采取特定的操作。这是一个示例流水线,它将运行master分支的步骤:
- branch
pipeline {
agent any
stages {
stage('when - branch') {
when {
branch 'master'
}
steps {
echo 'Deploy master to stage'
}
}
}
}
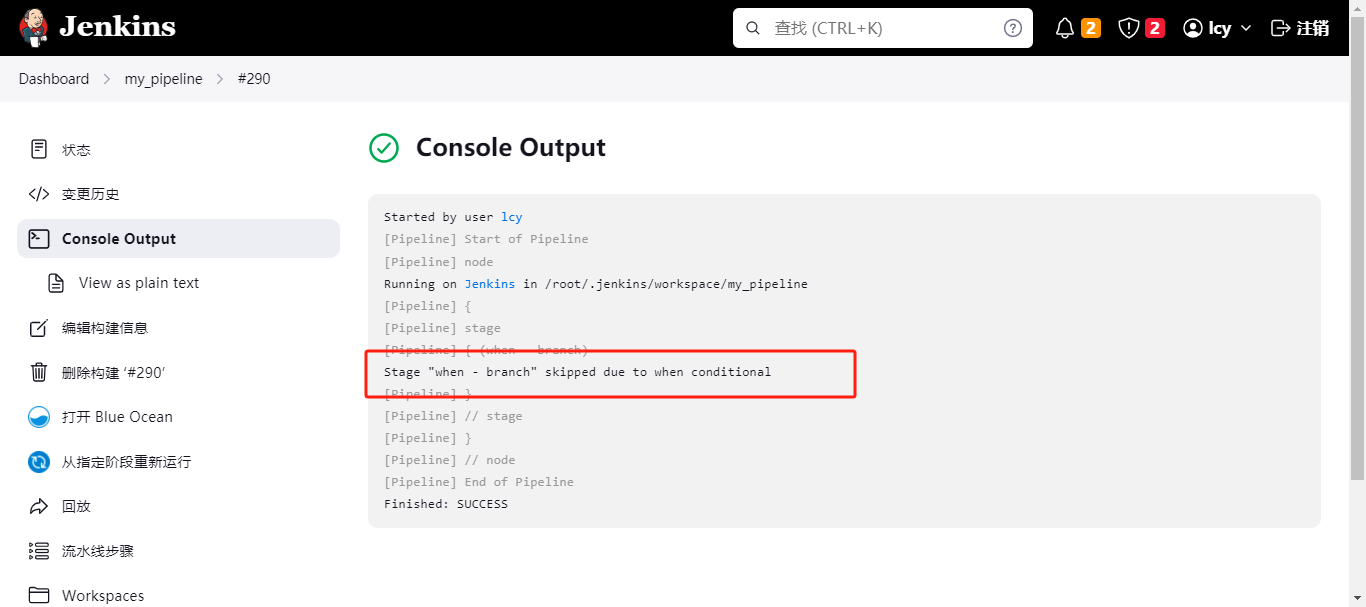
如果是在master分支上执行,就执行此操作;因为我们没有使用多分支,所以这个执行结果是跳过此执行操作;
- not - branch
pipeline {
agent any
stages {
stage('when - not - branch') {
when {
not {
branch 'master'
}
}
steps {
echo 'This is not a master node'
}
}
}
}
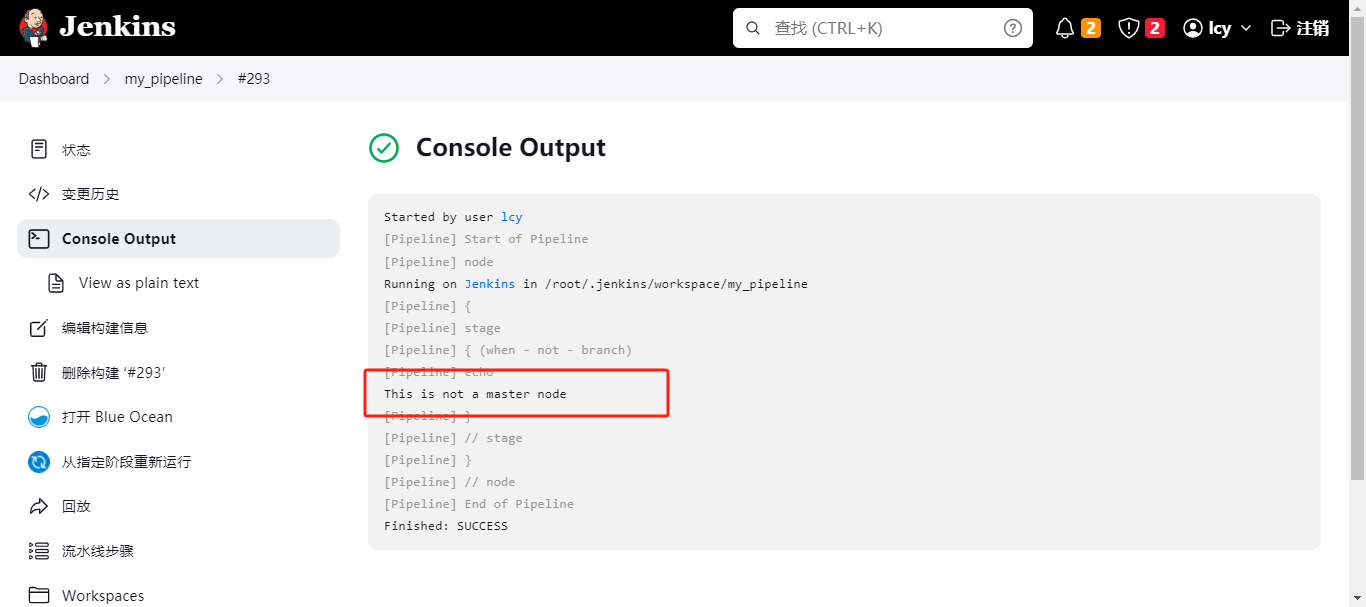
如果此任务不是在master分支上执行的,就执行steps中的内容;因为我们没有设置分支,所以就会执行输出steps中的内容;
- allOf
pipeline {
agent any
stages {
stage('when - allOf') {
when {
allOf {
branch 'master';environment name: 'DEPLOY_TO', value: 'production'
}
}
steps {
echo '包含以上其中一个条件!'
}
}
}
}
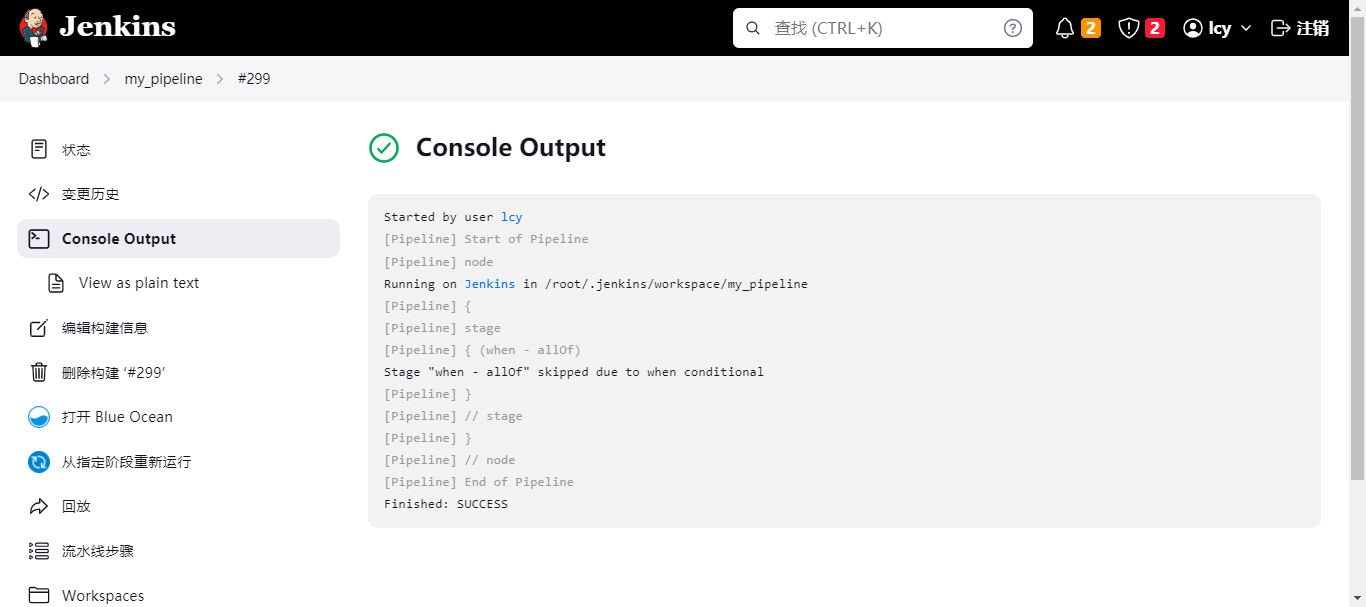
此执行结果为跳过此操作;因为没有分支,所以没有master,此条件为false;环境变量没有用到所以结果也为false;所以最终此条件为跳过;
script
在pipeline 声明式语法中,当需要执行代码块条件判断时可以使用when指令,那么除了when,我们还可以使用groovy语法的脚本,脚本内还可以执行for循环、if判断还有异常处理等操作,配置代码如下,脚本需要被script块包括起来;
那么学习
script块,我们就还需要学习groovy语法,所以,首先我们就需要先来了解一下语法,也就是脚本式流水线,可以查看下一章:【Jenkins】Pipeline流水线语法解析全集 – 脚本式流水线、groovy语法
总结
这一节,基本上对
jenkins的pipeline声明式流水线语法做了比较完整的介绍,在以后再看pipeline脚本时,可能还会接触到许多插件提供的函数或更多的指令,但是它们都逃不开pipeline脚本的基本结构,掌握了基础语法,后面才能更上一层楼。
参考文献:
文章参考与:
【Jenkins系列】-Pipeline语法全集
jenkins 原理篇——pipeline流水线 声明式语法详解
Jenkins扩展篇-Groovy语法简介
相关专栏
| 专栏名称 | 专栏地址 |
|---|---|
| 《Jenkins》 | https://blog.csdn.net/liu_chen_yang/category_12493057.html |
| 《自动化运维》 | https://blog.csdn.net/liu_chen_yang/category_12473478.html |
| 《Linux从入门到精通》 | https://blog.csdn.net/liu_chen_yang/category_10887074.html |
相关文章
| 文章名称 | 文章链接 |
|---|---|
| 【Jenkins】Pipeline流水线语法解析全集 – 声明式流水线 | https://liucy.blog.csdn.net/article/details/136528857 |
| 【Jenkins】Pipeline流水线语法解析全集 – 脚本式流水线、groovy语法 | https://liucy.blog.csdn.net/article/details/136567517 |