24. Text2LIVE : Text-Driven Layered Image and Video Editing
本文提出一种文本驱动的图像和视频编辑方法。与其他方法直接对图像进行编辑的方式不同,本文提出的方法并不是基于扩散模型的,更像是一个自编码器,通过对原图编码解码输出一个新的编辑图层,再与原图进行融合得到编辑后的图像。因此本文提出的方法更多适用于修改图中某个对象的纹理,或者增加一些特效,如火焰、烟雾等,而不能修改物体的动作、布局等等。另一方面,本文将提出的方法应用到了视频的编辑应用中。

本文主要完成了如下工作的:
- 分层编辑,根据输入原图输出一个包含RGBA通道的可编辑图层,并与原图融合后得到编辑图像
- 显示计算内容保留和定位损失,能够更好的保留原有图像内容不被改变,且能够引导编辑的位置
- 内部生成先验,通过对输入的图像和文本进行数据增强,从而构建一个内部样本数据集用于生成器的训练

我们先来看一下他是如何进行图像编辑的,正如前文所说,将原图
I
s
I_s
Is输入到一个生成器中,输出一个包含RGBA四个通道的可编辑图层
E
=
{
C
,
α
}
\mathcal{E}=\{C,\alpha\}
E={C,α},其中
C
C
C表示RGB图像,
α
\alpha
α表示透明度层,将可编辑图层
E
\mathcal{E}
E与原图
I
s
I_s
Is进行融合,得到编辑后的图像
I
o
I_o
Io:
I
o
=
α
⋅
C
+
(
1
−
α
)
⋅
I
s
I_o=\alpha\cdot C+(1-\alpha)\cdot I_s
Io=α⋅C+(1−α)⋅Is文中没有明确说生成器是如何实现的,但看起来像是一个自编码器模型,那么如何让生成器输出我们想要编辑的内容呢?这里就需要通过损失函数引入文本条件的引导了。对于一个文本描述
T
T
T,作者在其基础上提出两个辅助的文本提示:
T
s
c
r
e
e
n
T_{screen}
Tscreen描述了目标编辑层和
T
R
O
I
T_{ROI}
TROI描述了待编辑的位置。例如,
T
T
T=“fire out of the bear’s mouth”,,
T
s
c
r
e
e
n
T_{screen}
Tscreen =“fire over a green screen”,
T
R
O
I
T_{ROI}
TROI =“mouth”。利用这些文本描述,作者提出了一系列的损失函数,包括内容损失
L
c
o
m
p
\mathcal{L}_{\mathrm{comp}}
Lcomp,绿幕损失
L
s
c
r
e
e
n
\mathcal{L}_{\mathrm{screen}}
Lscreen,结构损失
L
s
t
r
u
c
t
u
r
e
\mathcal{L}_{\mathrm{structure}}
Lstructure和一个正则化项
L
r
e
g
\mathcal{L}_{\mathrm{reg}}
Lreg,总的损失函数如下:
L
T
e
x
t
2
L
I
V
E
=
L
c
o
m
p
+
λ
g
L
s
c
r
e
e
n
+
λ
s
L
s
t
r
u
c
t
u
r
e
+
λ
r
L
r
e
g
\mathcal{L}_{\mathrm{Text2LIVE}}=\mathcal{L}_{\mathrm{comp}}+\lambda_{g}\mathcal{L}_{\mathrm{screen}}+\lambda_{s}\mathcal{L}_{\mathrm{structure}}+\lambda_{r}\mathcal{L}_{\mathrm{reg}}
LText2LIVE=Lcomp+λgLscreen+λsLstructure+λrLreg其中内容损失通过计算生成图像特征和文本描述特征之间的余弦距离损失和方向损失,来评估生成结果与文本描述之间的匹配程度
L
c
o
m
p
=
L
cos
(
I
o
,
T
)
+
L
d
i
r
(
I
s
,
I
o
,
T
R
O
I
,
T
)
\mathcal{L}_{{\mathrm{comp}}}=\mathcal{L}_{\cos}\left(I_{o},T\right)+\mathcal{L}_{{\mathrm{dir}}}(I_{s},I_{o},T_{{\mathrm{ROI}}},T)
Lcomp=Lcos(Io,T)+Ldir(Is,Io,TROI,T)其中
L
c
o
s
=
D
cos
(
E
i
m
(
I
o
)
,
E
t
x
t
(
T
)
)
\mathcal{L}_{\mathsf{cos}} = \mathcal{D}_{\cos} (E_{\mathrm{im}}(I_{o}),E_{\mathrm{txt}}(T))
Lcos=Dcos(Eim(Io),Etxt(T))
D
cos
\mathcal{D}_{\cos}
Dcos表示余弦距离,
E
i
m
E_{\mathrm{im}}
Eim和
E
t
x
t
E_{\mathrm{txt}}
Etxt分别表示CLIP中的图像和文本编码器。第二项
L
d
i
r
\mathcal{L}_{\mathsf{dir}}
Ldir则用于控制在CLIP空间中编辑的方向
L
d
i
r
=
D
cos
(
E
i
m
(
I
o
)
−
E
i
m
(
I
s
)
,
E
t
x
t
(
T
)
−
E
t
x
t
(
T
R
O
I
)
)
\mathcal{L}_{\mathsf{dir}}=\mathcal{D}_{\cos}(E_{\mathrm{im}}(I_{o})-E_{\mathrm{im}}(I_{s}),E_{\mathrm{txt}}(T)-E_{\mathrm{txt}}(T_{\mathsf{ROI}}))
Ldir=Dcos(Eim(Io)−Eim(Is),Etxt(T)−Etxt(TROI))
绿幕损失则是参考了在电影工业中常用的绿幕特效技术,通过将可编辑图层融和到一个纯绿色背景
I
g
r
e
e
n
I_{green}
Igreen中,并使其与特定的文本模板匹配,
T
s
c
r
e
e
n
T_{screen}
Tscreen=“{ }” over a green screen
L
s
c
r
e
e
n
=
L
cos
(
I
s
c
r
e
e
n
,
T
s
c
r
e
e
n
)
\mathcal{L}_{{\mathrm{screen}}}=\mathcal{L}_{\cos}\left(I_{{\mathrm{screen}}},T_{{\mathrm{screen}}}\right)
Lscreen=Lcos(Iscreen,Tscreen)其中
I
s
c
r
e
e
n
=
α
⋅
C
+
(
1
−
α
)
⋅
I
g
r
e
e
n
I_{\mathsf{screen}}=\alpha\cdot C+(1-\alpha)\cdot I_{\mathsf{green}}
Iscreen=α⋅C+(1−α)⋅Igreen这个损失函数的好处在于它可以直接对所编辑的内容进行监督,而不会影响图像中其他的内容。结构损失
L
s
t
r
u
c
t
u
r
e
\mathcal{L}_{\mathrm{structure}}
Lstructure则是为了保证所编辑对象的空间布局、形状、感观语义等不发生变化,作者首先利用CLIP中的ViT提取得到
K
K
K个空间tokens,然后计算这
K
K
K个tokens之间的自相似矩阵
S
(
I
)
S(I)
S(I):
S
(
I
)
i
j
=
1
−
D
cos
(
t
i
(
I
)
,
t
j
(
I
)
)
S(I)_{ij}=1-\mathcal{D}_{\cos}\left(\mathbf{t}^i(I),\mathbf{t}^j(I)\right)
S(I)ij=1−Dcos(ti(I),tj(I))最后计算输入图像和输出图像的自相似矩阵之间的F范数作为结构损失
L
structure
=
∥
S
(
I
s
)
−
S
(
I
o
)
∥
F
\mathcal{L}_\text{structure}=\left\|S(I_s)-S(I_o)\right\|_F
Lstructure=∥S(Is)−S(Io)∥F
为了控制所编辑区域的空间范围,作者希望输出的透明度图尽可能的稀疏一些,也就是让大部分的透明度值
α
\alpha
α全为0,以保证生成的图像
I
o
I_o
Io与原图
I
s
I_s
Is在大部分区域上都是一致的。为了实现这种稀疏的特性,作者使用了L1和近似L0正则化项:
L
r
e
g
=
γ
∣
∣
α
∣
∣
1
+
Ψ
0
(
α
)
\mathcal{L}_{\mathrm{reg}}=\gamma||\alpha||_1+\Psi_0(\alpha)
Lreg=γ∣∣α∣∣1+Ψ0(α)其中
Ψ
0
(
x
)
≡
2
Sigmoid
(
5
x
)
−
1
\Psi_0(x)\equiv2\text{Sigmoid}(5x)-1
Ψ0(x)≡2Sigmoid(5x)−1为了实现编辑区域的准确定位,作者还提出一种文本驱动的相关性损失来对透明度图进行初始化。首先按照Chefer等人【1】提出的方法计算相关性图
R
(
I
s
)
R(I_s)
R(Is)来粗略的估计图像中与
T
R
O
I
T_{ROI}
TROI最相关的区域
[1] Chefer, H., Gur, S., Wolf, L.: Generic attention-model explainability for interpret- ing bi-modal and encoder-decoder transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2021)
然后通过最小化下式,来对透明度图
α
\alpha
α进行初始化
L
i
n
i
t
=
M
S
E
(
R
(
I
s
)
,
α
)
\mathcal{L}_{\mathsf{init}}=\mathrm{MSE}\left(R(I_{s}),\alpha\right)
Linit=MSE(R(Is),α)
在训练过程中,每次输入一个图像
I
s
I_s
Is和一个文本描述
T
T
T,然后对图像和文本描述进行数据增强,得到一组训练样本
{
(
I
s
i
,
T
i
)
}
i
=
1
N
\{(I_s^i,T^i)\}_{i=1}^N
{(Isi,Ti)}i=1N,图像增强包括全局裁剪、颜色变换、反转等,文本增强则使用一系列预定义的文本模板进行采样,例如“a photo of { }”。这就是前文所提到的内部数据集,使用这个小数据集对生成器进行训练,得到对应的编辑结果。
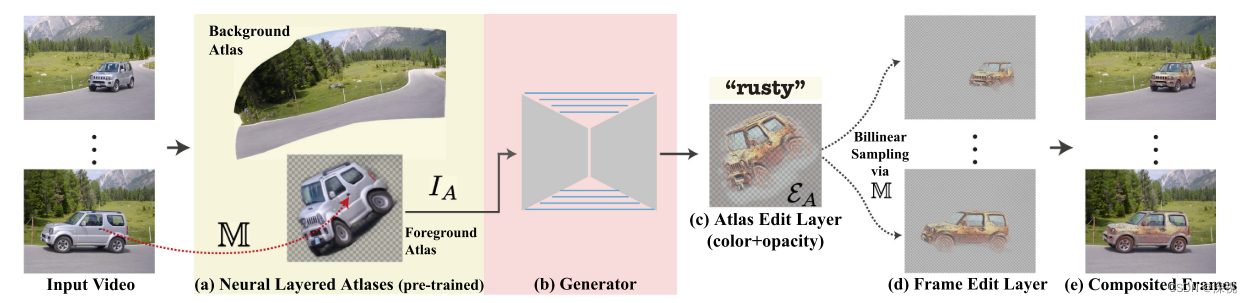
了解了本文的图像编辑方式,我们再来简单看一下针对视频的编辑方式。相比于图像编辑,视频编辑需要考虑时间上的连续性,而不是简单的对每张图进行编辑。这里作者使用了一种叫做神经分层图集的方法(Neural Layered Atlases,NLA),NLA将视频分解成一组2D的图集分别表示前景物体和背景图像,每个图集都可以看作是一幅2D的图像。NLA本质上是由多个MLP构成的,给定一个视频中的像素坐标
p
=
(
x
,
y
,
t
)
p=(x,y,t)
p=(x,y,t),
x
,
y
x,y
x,y分别表示横纵坐标,
t
t
t表示时间,NLA将其分别转化为前景和背景图集上的二维坐标点以及一个前景的不透明度值。
M
b
(
p
)
=
(
u
b
p
,
v
b
p
)
,
M
f
(
p
)
=
(
u
f
p
,
v
f
p
)
\mathbb{M}_b(p)=(u_b^p,v_b^p),\mathbb{M}_f(p)=(u_f^p,v_f^p)
Mb(p)=(ubp,vbp),Mf(p)=(ufp,vfp)其中
M
b
(
p
)
\mathbb{M}_b(p)
Mb(p)和
M
f
(
p
)
\mathbb{M}_f(p)
Mf(p)分别对应背景和前景的映射网络,
(
u
b
p
,
v
b
p
)
(u_b^p,v_b^p)
(ubp,vbp)和
(
u
f
p
,
v
f
p
)
(u_f^p,v_f^p)
(ufp,vfp)分别对应背景和前景图集上的坐标点。通过在二维图集上对坐标点进行编辑,并将其反向映射到视频中的像素坐标
p
p
p,从而实现对视频的编辑。
本文使用一个预训练好的NLA模型对视频进行分解,然后对2D离散的图集
I
A
I_A
IA进行编辑得到图集编辑层
E
A
=
{
C
A
,
α
A
}
\mathcal{E}_A=\{C_A,\alpha_A\}
EA={CA,αA},接着使用预训练好的映射网络
M
\mathbb{M}
M对
E
A
\mathcal{E}_A
EA进行双线性采样
E
t
=
S
a
m
p
l
e
r
(
E
A
,
S
)
\mathcal{E}_\mathrm{t}=\mathrm{Sampler}(\mathcal{E}_A,\mathcal{S})
Et=Sampler(EA,S)其中
S
=
{
M
(
p
)
∣
p
=
(
⋅
,
⋅
,
t
)
}
\mathcal{S}=\{\mathbb{M}(p)\mid p=(\cdot,\cdot,t)\}
S={M(p)∣p=(⋅,⋅,t)}是第
t
t
t帧图像对应的UV坐标集合。最后将
E
t
\mathcal{E}_\mathrm{t}
Et与原始图像帧做融合得到编辑后的视频。
与其他当时流行的图像编辑方法,如GLIDE、Blended-Diffusion、CLIPStyler等相比,本文提出的方法在指定物体的编辑效果上有明显的提升。但本文提出的方法需要对每个输入的图像和文本都进行训练,这制约了该方法的应用。