在当今复杂的数据驱动型应用中,理解和管理实体间的复杂关系变得日益重要。通过低代码平台进行配置的应用,因采用了DSL语言进行统一设计,要让专业开发者和非专业开发者都能快速实现复杂应用的构建,实体之间的数据逻辑和关系梳理就尤为重要,这里涉及到页面信息、事件信息、服务信息之间的数据流、业务流的追踪和理解。因此利用血缘关系图来实现数据、服务、流程等元素之间的依赖和影响链条,可以更好的帮助开发者理解和分析应用的开发过程。
01 实体血缘关系图的实现挑战
构建和维护复杂系统的实体血缘关系图会面临诸多挑战,主要包括以下几个方面:
数据模型复杂性:实体血缘关系图通常要展示数据在不同的事件、流程和服务之间的流转和变换逻辑,这要求我们能够处理复杂的业务逻辑和数据模型,尤其在低代码环境下,可能需要高度灵活且强大的数据建模能力。
集成能力:实体血缘关系图往往跨越多个模块、多个应用的服务,因此需要平台具备具备强大的集成能力,能够满足广泛连接器和适配器,同时还要求有高效的数据交换和同步能力。
高性能和高扩展性:随着应用的不断迭代,数据量和实体关系会持续增长,生成和实时更新血缘关系图对平台的性能和扩展性提出了更高的要求。
可视化复杂性:实体血缘关系图可能非常复杂,如何清晰、直观的呈现这种复杂性也是一个巨大的挑战。平台需要提供更高级的图表组件和布局组件,满足复杂的视图展示。
实体血缘关系图版本控制:随着应用和数据的架构演变,实体血缘关系也会随之变化,追踪实体血缘关系的历史和变更也是需要平台面临的挑战之一。
02 实体血缘关系图实现原理
在构建实体血缘关系图的时我们也尝试通过不同的方式和技术实现来解决面临的一系列挑战。最终我们发现可以将图数据库的实现原理和DDD领域驱动设计相结合,两者的结合也凸显了以下几个优势:
图数据库是以使用节点、边和属性来表示和存储数据。节点可以代表一个实体(如页面、服务),边则可以表示实体间的关系(如触发事件、依赖),而属性信息则可以为节点和边附加额外信息(如事件描述、时间戳)。图数据库体现的最大优势就是可以随时从任何一个节点找到与这个节点相关的所有数据,不管是自上而下还是自下而上查找,都可以快速检索到相关的关联和依赖数据。这种实现机制会让我们对数据的操作和检索会更加高效,而通过关系型数据库的逻辑去建立关系数据时,都是通过表数据之间进行关联,检索时也是根据某个特定条件进行多表jion的关联查询。
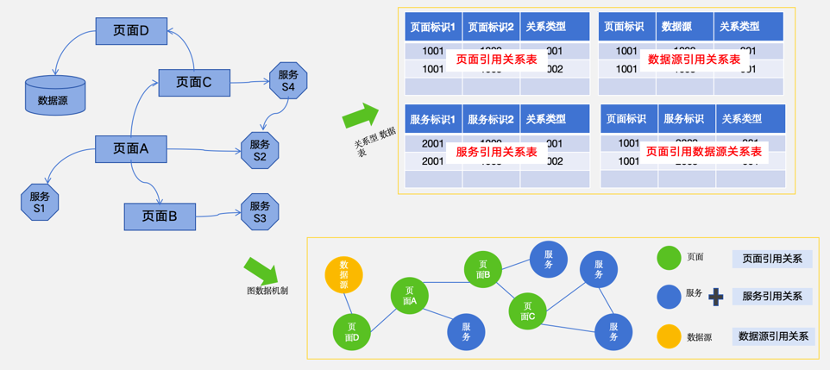
关系型数据库和图数据库实现原理分析
在实体血缘关系图的设计过程中,我们也充分使用了DDD领域驱动设计的模式,将系统的设计划分为不同的核心领域、子域和限界上下文。每个领域中也会定义实体、对象和实体关系,因此在实体血缘关系图建立过程中,可以将页面、服务、事件等与图数据库的节点、边和属性进行对应。
03 构建实体血缘关系图
在构建实体血缘关系图时,我们以页面作为节点,事件作为关系纽带,服务作为终点,参照图数据库的实现原理,在实体血缘关系图中明确标识出每个页面、事件和服务的名称,并描绘出它们之间的连接方向和触发顺序,确保逻辑流畅可见。
面对复杂应用的挑战,我们采取了层次化与模块化策略进行视觉优化,利用分层、分模块的方式进行可视化表示,以便清晰展示应用的整体结构和局部细节,从而能够增强实体血缘关系图的可读性和科维护性。
核心实现一:血缘关系模型设计
参考图数据库实现机制,我们在设计血缘关系图的关系数据模型时,会把涉及到的场景进行梳理并分类:
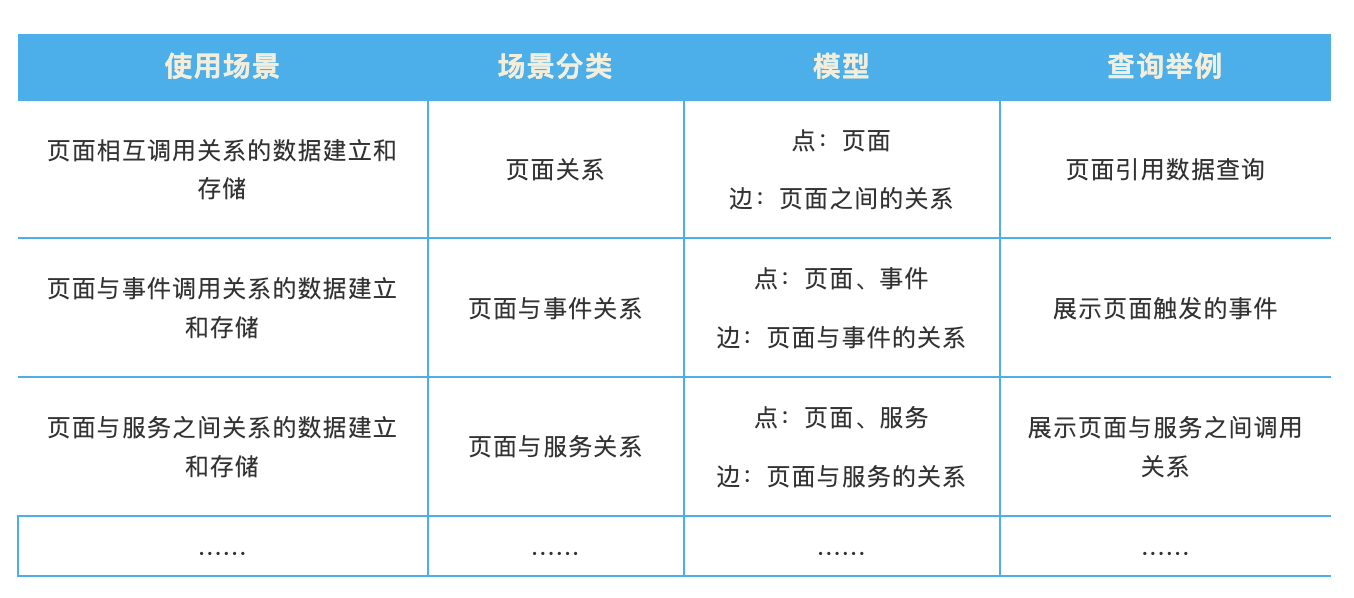
梳理完业务场景后,我们参考图数据库的模式,将关系模型全部梳理清楚,然后建模成一张图如下:
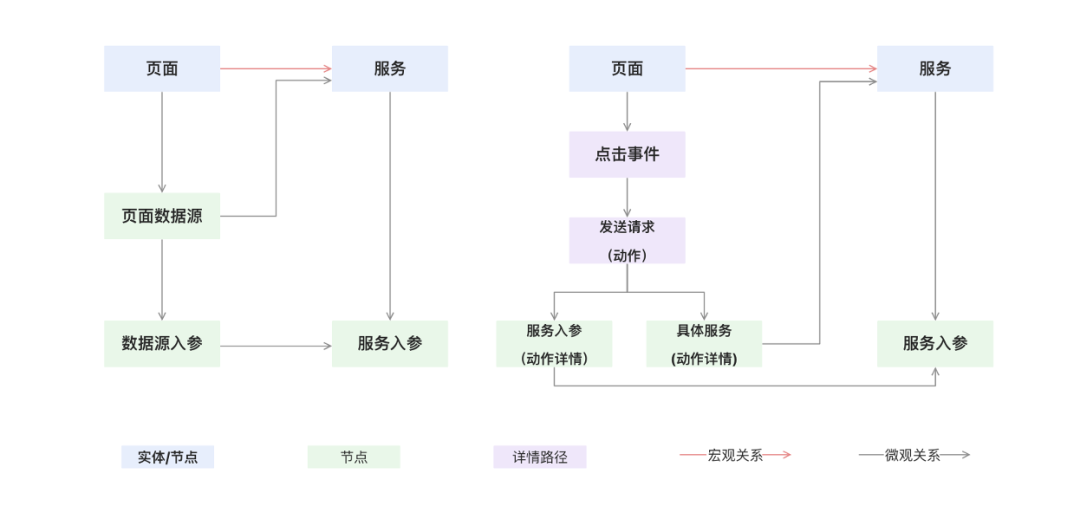
页面关系建模示意
由于不同实体类型的属性存在差异,采用为每种实体新增特定模型及其相关写入程序的方法在实践中显得不太可行。为了解决这一问题,我们开发了一种通用的数据模型。该模型旨在统一定义各种数据类型,同时确保数据实例化后能够顺利映射到目标数据库表中。
这种通用模型的设计允许我们以一种灵活且高效的方式处理不同实体的多样化属性,从而避免了频繁地为每种新实体创建和维护独立模型的繁琐过程。通过这种方式,我们能够实现数据存储和管理的标准化,同时保持对不同数据类型的兼容性和适应性。
核心实现二:DSL数据解析
要建立实体血缘关系图,就必须通过对低代码平台的DSL数据进行分析,对DSL各个数据节点进行充分理解,才能完整的建立页面与服务、页面与页面等之间的实体调用关系。而为了更好的解析DSL数据结构,平台构建了一套DSL解析的引擎,在该引擎中,我们首先定义了@Node和@NodeField 注解,前者用作 DSL 中的节点标识,定义了节点的 JSON Path 以及是否为根节点等信息;后者用作节点下字段标识,定义了字段在 DSL 中对应的键或 JSON Path。
平台在构建血缘关系模型的时候,就需要考虑将@Node和@NodeField注解标记的节点与节点下的字段与关系模型对应起来。通过DSL解析引擎针对不同实体的DSL数据进行各自的解析实现。而在采集到 DSL数据后,能够根据特征值自动匹配需要的解析逻辑,从而快速的将节点、边等关系进行建立,并转化成模型数据进行存储。
核心实现三:数据关系快速构建
1)实体类型识别:系统需要识别出数据属于哪种类型的实体。这是通过调用一个特定的解析器来完成的。
2) DSL片段定位:识别出实体类型后,解析器会利用JsonPath表达式来定位具有特定特征的领域特定语言(DSL)片段。
3) 数据匹配与实例化:接下来,解析器会根据规格表中定义的类型,将实例数据与这些类型进行匹配。一旦找到匹配项,系统将按照规格表中定义的实例化字段,将数据转换成相应的对象,并将其存储到数据库中。
4) 关系数据建立:至于节点之间的关系数据,系统会自动通过实体的ID以及实体属性的ID来建立。这些关系信息随后会被写入到关系表中,以此来维护实体/属性间的联系。
通过这个过程,系统能够灵活地处理不同实体类型的数据,同时自动维护实体间的关联关系,从而实现数据的高效管理和查询。
核心实现四:血缘关系数据快速检索
实体血缘关系图从数据解析、存储到查询,总共分成三层:查询引擎层、数据解析引擎层、存储引擎层。
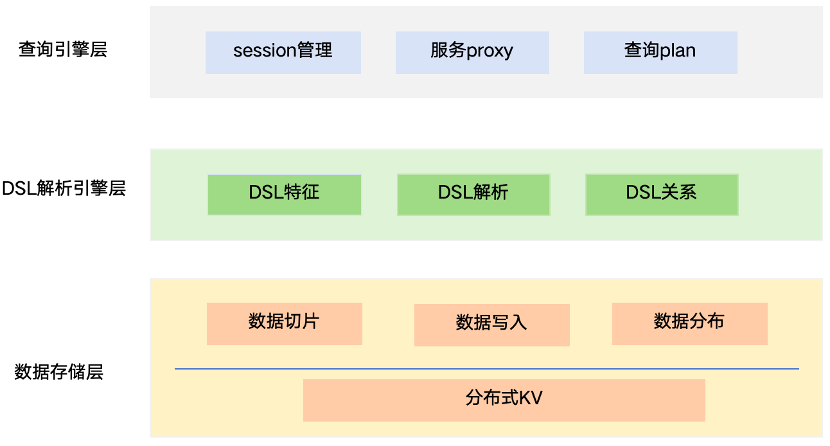
血缘关系图三层处理
- 查询引擎层
主要涉及到用户 session 管理、服务的 proxy,其核心的一个功能是基于用户发过来的请求,去做一个逻辑查询计划,并生成一个物理查询计划,然后通过执行器 executor 把对应的子查询给分发出去,重高并发问题。
- 数据存储层
我们会在这个模块当中会考虑把数据做切片,分成一个个的数据块,然后用一种特定的数据结构把它组织起来,同时这个数据结构要有相对来说比较良好且较低的读写放大能力,以及它能够在磁盘的组织形式上对磁盘比较友好,然后是顺序读写。在数据存储时,我们选择使用二级缓存模式,先通过KV方式将数据写入到分布式缓存中,然后再持久化到ERM数据库中。
核心实现五:血缘关系图可视化处理
血缘关系图在完成数据存储引擎和数据检索引擎的模块建设后,最关键的一步就是要将数据以图形化的方式进行展示。图形化展示的几个基本要求:
1)以任何一个节点可以展开上下游的数据节点关联关系
2)界面图层渲染时,需要考虑到界面渲染性能
3)界面自动布局能力需考虑用户体验感知
在构建图形的时候,我们对节点的布局和边的样式经过特别的设计,同时引入了前端X6的引擎,并对X6的布局算法进行定制化改造和优化,从而保证图的可读性和美观性。
交互设计方面,我们对交互进行了自定义的设计,包括拖拽、放大缩小、节点折叠等功能的拓展和自定义。从而满足平台的复杂性和个性化需求。
主要实现内容如下:
1) 节点类型识别:为不同的节点定义类型,并为每种类型创建一个标识符。
2) 自定义节点样式:根据节点类型,使用 X6 提供的图形和样式定制功能来自定义节点的外观。
3) 定义连线逻辑:为不同类型的节点定义它们之间的连接方式。我们使用图形语法来定义节点之间的连线样式和路径。
4) 节点跳转逻辑:为节点定义交互逻辑,比如点击某个节点时触发的动作或跳转到另一个实体。通过事件处理器,为节点添加点击事件来实现跳转逻辑。
5) 动态数据绑定:实现一个机制,使得当增加新的节点类型时,只需添加相应的样式定义和跳转逻辑,而无需重写现有代码。
6) 性能优化:考虑到数据量大时的性能问题,我们采用虚拟滚动、节点懒加载等技术来优化用户体验。
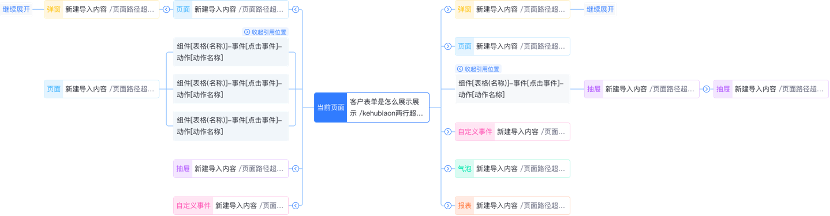
血缘关系图展示处理示意
04 应用成效和价值
实体血缘关系图的建设,不仅能够显著提升平台可管理性和透明度,还能给平台带来更多方面的长远价值:
增强系统的透明度和可追溯性:实体血缘关系图清晰展示了数据、服务、流程等实体间的依赖关系,使得专业开发和非专业开发人员都能快速理解系统的工作原理和数据流向。这对新员工培训和应用的后期运维都尤为重要,并且可以大幅减少沟通和协调成本,降低应用二次开发的成本。
优化故障排查和问题解决:当问题出现时,血缘关系图能够快速帮助定位问题根源。通过追踪受影响的实体上下游关系,迅速识别出问题所在环节或者服务,缩短排障时间。
优化设计与重构:血缘关系图揭示了系统的复杂度和潜在的瓶颈,为系统设计和重构提供可视化依据。在进行系统优化或迁移时,可以帮助团队识别冗余的组件、服务依赖,以及过度耦合的部分。