效率最好的方式是:批量插入 + 开启事务。
1、数据批量插入相比数据逐条插入的运行效率得到极大提升;
## 批量插入
INSERT INTO `table` (`field1`, `field12`,...) VALUES ('valuea1', 'valuea2',...), ('valueb1', 'valueb2',...),...;
当数据逐条插入时,每条插入操作都需要进行一次数据库连接和一次磁盘写入操作,这会导致频繁的网络通信和磁盘 I/O 开销。如果有大量的数据需要插入,这些额外的开销会导致插入速度变慢,降低整体的运行效率。
相比之下,批量插入将多条数据合并为一个批次进行插入。通过一次数据库连接和一次磁盘写入操作,可以将多条数据一次性插入到数据库中。这样可以减少网络通信次数和磁盘 I/O 操作次数,大大提高了数据插入的效率。
批量插入的效率提升主要有以下几个方面的原因:
- 减少网络通信开销:批量插入可以通过一次数据库连接和一次传输操作将多条数据发送给数据库,减少了网络通信的次数和开销。
- 减少磁盘 I/O 操作:批量插入将多条数据合并为一个写入操作,减少了磁盘的读写次数,降低了磁盘 I/O 的开销。
- 优化事务管理:批量插入可以将多条插入操作合并为一个事务,减少了事务的开启和提交次数,提高了事务管理的效率。
2、数据逐条插入时,显示开启事务相比无事务的运行效率得到极大提升;
MySQL 每条插入操作,都会在内部建立一个隐式事务,在这个事务内进行真正的插入操作,所以逐条插入需要不停的创建事务和提交事务,造成较大的开销;显示开启事务,将多条插入操作放在同一个事务内,等都执行完再提交事务,可以减少创建和提交事务的次数,从而降低消耗。
## 没有开启事务
INSERT INTO `table` (`field1`, `field12`,...) VALUES ('value1', 'value2',...);
INSERT INTO `table` (`field1`, `field12`,...) VALUES ('value1', 'value2',...);
## 开启事务
START TRANSACTION;
INSERT INTO `table` (`field1`, `field12`,...) VALUES ('value1', 'value2',...);
INSERT INTO `table` (`field1`, `field12`,...) VALUES ('value1', 'value2',...);
COMMIT;
当数据逐条插入时,使用事务可以显著提升运行效率。这是因为事务的特性可以减少磁盘 I/O 操作,从而减少数据库引擎与磁盘之间的交互次数,提高数据插入的性能。
在无事务的情况下,每次插入一条数据都会立即写入磁盘,这导致了频繁的磁盘 I/O 操作。每次写入磁盘都包括了寻址、数据传输和磁盘写入等操作,这些操作的开销很大,会显著降低数据插入的速度。
而在开启事务的情况下,可以将多条插入操作打包成一个事务,然后一次性提交到数据库。这样可以将多个插入操作合并为一个写入磁盘的过程,减少了磁盘 I/O 操作的次数。数据库引擎可以优化事务的提交过程,将数据缓存在内存中并批量写入磁盘,从而减少了磁盘访问的次数,提高了插入操作的效率。
因此,对于大量逐条插入数据的场景,使用事务可以极大地提升运行效率,减少磁盘 I/O 操作,加快数据的插入速度。
3、INSERT 操作涉及磁盘 I/O 操作的原因主要有两个方面:
数据持久化:INSERT 操作的目的是将新的数据插入到数据库中,以保持数据的持久性。为了实现持久化,数据库引擎需要将插入的数据写入磁盘,将其保存在物理存储介质上(如硬盘或固态硬盘)。这涉及到将数据从内存中的缓冲区或日志文件写入到磁盘的过程,即磁盘 I/O 操作。
索引更新:如果表中定义了索引,那么在执行 INSERT 操作时,数据库引擎还需要相应地更新索引数据结构。索引是用于提高数据库查询性能的数据结构,它们存储在磁盘上并与表的数据分开存储。当插入新的数据时,数据库引擎需要更新索引,以确保索引的正确性和查询的准确性。这也涉及到磁盘 I/O 操作。
4、在MySQL中,默认情况下,每个SQL语句都自动开启一个事务
在MySQL中,默认情况下,每个 SQL 语句被视为一个单独的事务,即每个 SQL 语句都会自动开启事务并在执行完成后立即提交。这种自动提交模式是MySQL的默认模式,也称为自动提交模式。当自动提交模式开启时,每个 SQL 语句都会被视为一个独立的事务,并且在执行后立即提交,使得更改立即持久化到数据库中。
自动提交模式可以通过设置来控制。默认情况下,MySQL 的自动提交模式是开启的,即每个 SQL 语句都自动成为一个事务。可以使用 SET AUTOCOMMIT=0 命令来关闭自动提交模式。如果要将多个 SQL 语句组合在一个显式的事务中执行,需要在组合语句之前显示使用START TRANSACTION或BEGIN语句,然后在所有语句都执行完毕后显示执行COMMIT或ROLLBACK语句提交或回滚事务。
当自动提交模式关闭时,需要手动控制事务的边界,并显式地进行事务的提交或回滚,以确保数据的一致性和原子性。
批量插入需要考虑限制 sql 语句的长度,不能超过 MySQL 对 SQL 语句的长度限制
max_allowed_packet 是一个MySQL服务器参数,用于控制单个网络数据包的最大大小。它指定了MySQL服务器接收或发送的最大数据包大小限制,以字节为单位。
该参数对于处理大型查询或传输大量数据非常重要。如果试图发送一个超过 max_allowed_packet 大小限制的数据包,MySQL服务器将会拒绝该数据包,并且可能会导致通信错误或截断数据。
使用 show VARIABLES like ‘%max_allowed_packet%’; 可以查看网络包大小限制:
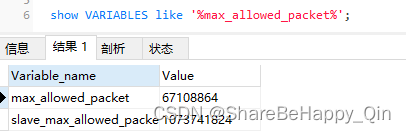
使用事务可以提高数据的插入效率,但事务需要控制大小,事务太大可能也会影响执行的效率。
innodb_log_buffer_size 是用于配置 InnoDB 存储引擎的日志缓冲区大小的变量。它指定了用于存储事务日志的内存缓冲区的大小。
InnoDB 存储引擎使用事务日志(也称为 redo log)来确保事务的持久性和恢复能力。在事务提交之前,相关的修改操作被写入到日志缓冲区中,而不是直接写入到磁盘上的数据文件,然后再由后台线程将日志刷新到磁盘上的 InnoDB 日志文件中。这样可以提高事务的性能,因为写入内存比写入磁盘要快得多。
事务需要控制大小,若事务大小超过上限设置,Innodb 会把数据刷到磁盘中,这时会降低效率。
较大的缓冲区可以容纳更多的日志记录,从而减少了频繁的磁盘写入操作,提高了事务的性能。然而,如果设置过大,可能会占用过多的内存资源。需要在性能和内存消耗之间进行权衡,以获得最佳的事务处理性能。
事务日志被刷新到磁盘上的日志文件,并不代表该事务已经提交,只是为了确保事务的持久性和恢复能力。即使发生故障或异常情况,数据库系统也可以通过事务日志进行恢复和回滚操作。
事务的提交是一个独立的操作,它将会持久化事务对数据库的修改,并使这些修改对其他会话可见。如果在事务日志刷盘后没有执行提交操作,那么这个事务的修改将不会被持久化到数据文件中,也不会对其他会话可见。在数据库系统的崩溃或重启情况下,这个事务的修改将会被回滚或者丢失。
使用 show variables like ‘%innodb_log_buffer_size%’; 可以查看日志缓存大小:
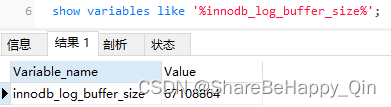
5、批量插入的优势
MySQL插入动作,主要有连接,传输,执行,提交/回滚等的动作
- 网络传输空间,每个插入操作都需要发送一个独立的网络请求,在请求中包含数据的内容和相关的协议头信息。批量插入多条数据,减少了请求头部的重复发送和处理,从而节省了网络带宽和传输时间。
- 网络连接,批量插入使用一个连接,减少网络连接次数,从而减少连接建立和断开开销。
- 通过合并SQL语句,减少SQL语句解析的次数;合并后的 SQL 语句可以共享解析结果和执行计划,避免了重复的解析过程;合并的 SQL 语句也需要考虑查询的并发性、锁的粒度等因素,以避免潜在的并发冲突或性能问题。
- 事务方面,逐条插入每次都会新建一个事务,批量插入只会使用一个事务。批量插入可以减少事务的启动和提交次数,降低开销。
- 磁盘IO操作,合并插入可以减少事务日志的数量,降低事务日志的总量,减少了对磁盘的写入操作,降低日志刷盘的数据量和频率,从而提高效率。(对于插入操作而言,每次逐条插入都会生成一条日志记录,包括事务开始、插入语句执行和事务提交等信息)
mybatis-plus 的 saveBatch 方法源码分析
进入 mybatis-plus 的 saveBatch 方法,可以看到是由 ServiceImpl 实现的,进入核心方法:
@Transactional(
rollbackFor = {Exception.class}
)
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = this.getSqlStatement(SqlMethod.INSERT_ONE);
return this.executeBatch(entityList, batchSize, (sqlSession, entity) -> {
sqlSession.insert(sqlStatement, entity);
});
}
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one", new Object[0]);
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, (sqlSession) -> {
int size = list.size();
int i = 1;
for(Iterator var6 = list.iterator(); var6.hasNext(); ++i) {
E element = var6.next();
consumer.accept(sqlSession, element);
if (i % batchSize == 0 || i == size) {
sqlSession.flushStatements();
}
}
});
}
分析这段代码,executeBatch 方法种的 consumer.accept(sqlSession, element) 执行的就是 saveBatch 的 sqlSession.insert(sqlStatement, entity),可以看到确实是 for 循环一条一条执行 insert 操作。在 executeBatch 使用了 @Transactional 开启了事务,在循环插入后再提交事务。
mybatis plus 使用了开启事务的方式提升插入效率,是否还会使用批量插入来提升效率。继续点进代码看,一直到 MySQL 驱动(mysql-connector-java:8)
protected long[] executeBatchInternal() throws SQLException {
synchronized(this.checkClosed().getConnectionMutex()) {
if (this.connection.isReadOnly()) {
throw new SQLException(Messages.getString("PreparedStatement.25") + Messages.getString("PreparedStatement.26"), "S1009");
} else if (this.query.getBatchedArgs() != null && this.query.getBatchedArgs().size() != 0) {
int batchTimeout = this.getTimeoutInMillis();
this.setTimeoutInMillis(0);
this.resetCancelledState();
try {
this.statementBegins();
this.clearWarnings();
long[] var3;
if (!this.batchHasPlainStatements && (Boolean)this.rewriteBatchedStatements.getValue()) {
// 启用 rewriteBatchedStatements = true,使用多值语句进行重写,拼接 sql 批量插入数据。
// INSERT INTO `table` (`field1`, `field12`,...) VALUES ('valuea1', 'valuea2',...), ('valueb1', 'valueb2',...),...; 方式;
if (this.getQueryInfo().isRewritableWithMultiValuesClause()) {
var3 = this.executeBatchWithMultiValuesClause(batchTimeout);
return var3;
}
// 如果批处理中包含多个非简单语句,并且批量参数个数大于3,则使用该方法执行批处理。
// INSERT INTO `table` (`field1`, `field12`,...) VALUES ('value1', 'value2',...);
// UPDATE my_table SET field1= ?, field12= ?, field13= ?, ... WHERE field14= ?";
if (!this.batchHasPlainStatements && this.query.getBatchedArgs() != null && this.query.getBatchedArgs().size() > 3) {
var3 = this.executePreparedBatchAsMultiStatement(batchTimeout);
return var3;
}
}
// 否则,使用该方法按顺序执行处理每条sql语句。简单语句或参数个数不超过3个。
var3 = this.executeBatchSerially(batchTimeout);
return var3;
} finally {
this.query.getStatementExecuting().set(false);
this.clearBatch();
}
} else {
return new long[0];
}
}
}
需要在 MySQL 的 jdbcUrl 中设置 rewriteBatchedStatements = true:
jdbc:mysql://localhost:3306?rewriteBatchedStatements=true
executeBatchWithMultiValuesClause(batchTimeout) 方法:
- 该方法用于执行批处理操作,并且支持使用多值语句进行批量插入。
- 如果查询可以使用多值语句进行重写,且启用了 rewriteBatchedStatements,则会选择该方法来执行批处理。
- 多值语句是将多个值组合在一条 SQL 语句中,用于一次性插入多个记录,可以提高插入性能。
executePreparedBatchAsMultiStatement(batchTimeout) 方法:
- 该方法用于执行包含多个非简单语句的批处理操作。
- 如果批处理中的参数个数大于 3,且满足其他条件,该方法会被选择来执行批处理。
executeBatchSerially(batchTimeout) 方法:
- 该方法用于按顺序逐个执行批处理中的每个语句。
- 该方法通常在批处理中只包含简单语句(没有参数)或参数个数较少的情况下使用。