第二章.线性回归以及非线性回归
2.9 特征缩放
1.数据归一化
1).作用:
把数据的取值范围处理为0-1或者-1-1
2).数据范围处理为0-1之间的方法:
-
newValue=(oldValue-min)/(max-min) - 例如:数组:(1,3,5),value1:(1-1)/(5-1)=0; value2:(3-1)/(5-1)=0.5; value3:(5-1)/(5-1)=1
3).数据范围处理为-1-1之间的方法:
-
newValue=((oldValue-min)/(max-min)-0.5)*2 - 例如:数组:(1,3,5),value1:((1-1)/(5-1)-0.5)*2=-1; value2:((3-1)/(5-1)-0.5)*2=0; value3:((5-1)/(5-1)-0.5)*2=1
2.均值标准化
1).方法:
-
newValue=((oldValue-u)/s[x:特征数据;u:数据的平均值;s:数据的方差] - 例如:x=(1,3,5,7,9)
①.u=(1+3+5+7+9)/5
②.s=((1-5)2+(3-5)2+(5-5)2+(7-5)2+(9-5)2)/5=8
③.(1-5)/8=-0.5
④.(3-5)/8=-0.25
⑤.(5-5)/8=0
⑥.(7-5)/8=0.25
⑦.(9-5)/8=0.5
2.10 交叉验证法:
1.交叉验证法是一种验证方法:
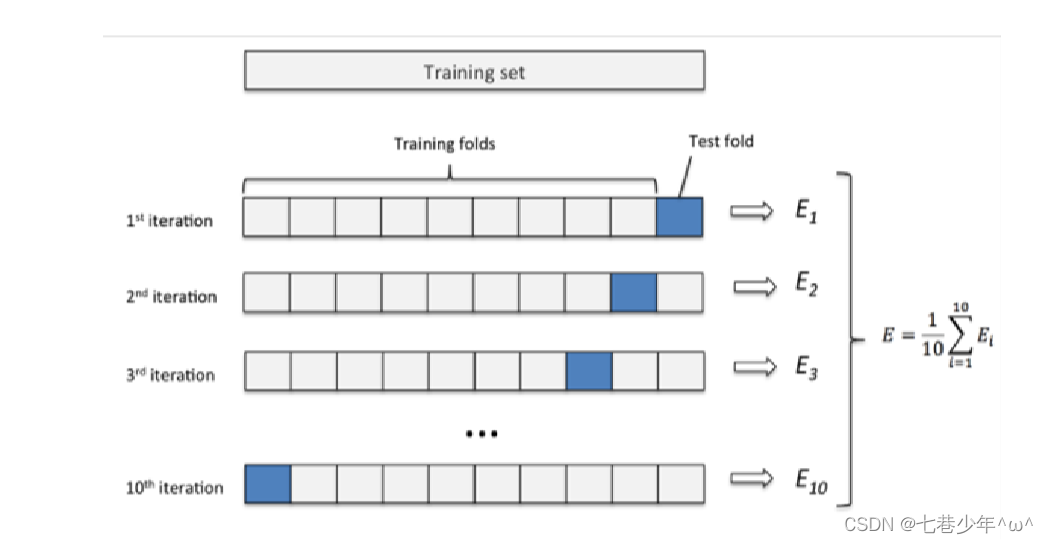
- 说明:白色的方框:代表训练集,蓝色方框:代表测试集.
- 模型用训练集训练,用测试集测试,会得到一个误差值E,迭代10次,每次用的测试集的位置是不同的,用的就是交叉验证的思想
2.11 过拟合:
1.回归描述:
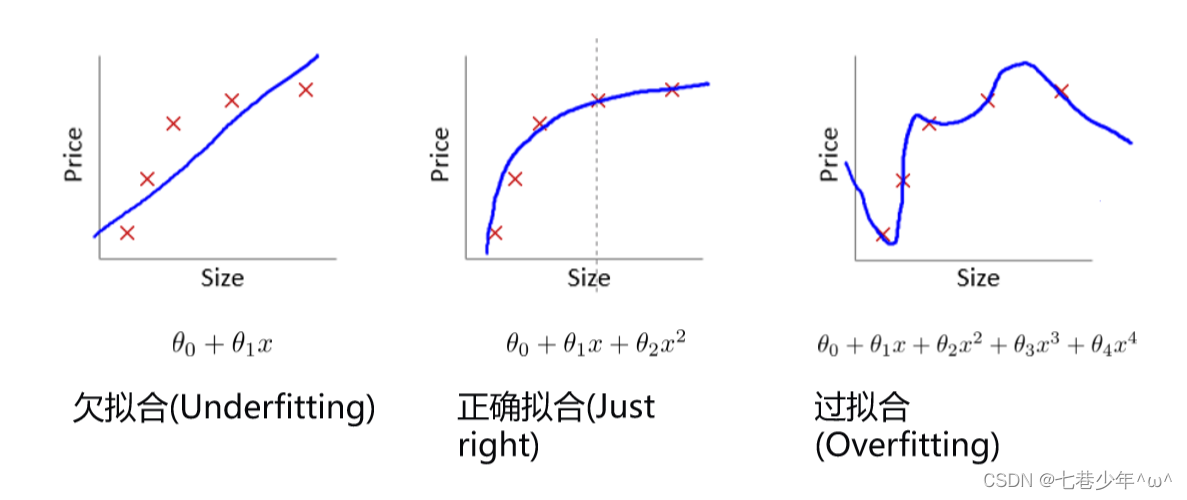
- 说明:
①.正确拟合:测试集和训练集表现的都比较好
①.过拟合:训练集表现比较好,测试集表现的比较差
2.分类描述:
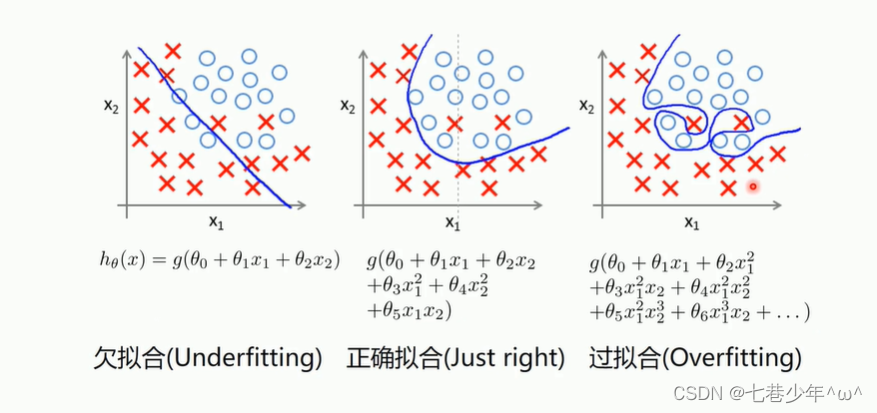
- 说明:
①.正确拟合:测试集和训练集表现的都比较好
①.过拟合:训练集表现比较好,测试集表现的比较差
3.防止过拟合的方法:
1).减少样本特征(有些数据的特征是干扰性)
2).增加数据量(基本上数据量越大,效果越好)
3).正则化(Regularized)
-
正则化的代价函数分为两种
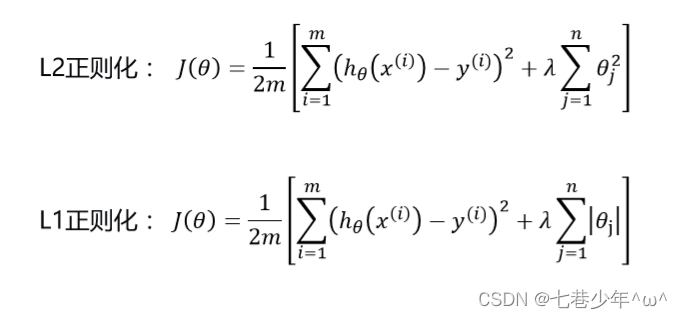
-
参数说明:
λ:正则项的系数