目录
模型 API:LLM vs. ChatModel
OpenAI 模型封装
多轮对话 Session 封装
换个国产模型
模型的输入与输出
Prompt 模板封装
PromptTemplate
ChatPromptTemplate
MessagesPlaceholder
从文件加载 Prompt 模板
TXT模板
Yaml模板
Json模板
输出封装 OutputParser
编辑Pydantic (JSON) Parser
Auto-Fixing Parser
总结
关键点提取
使用感触
本文将继续延续Langchain专栏文章,本文将讲解Langchain的模型 I/O 封装。Langchain将不同的模型,统一封装成一个接口,方便更换模型而不用重构代码。
对Langchain能做什么暂时还不了解的话可以移步先看这篇文章
直通车:LangChain:大模型框架的深度解析与应用探索-CSDN博客
模型 API:LLM vs. ChatModel
pip install --upgrade langchain # 安装最新版本
pip install --upgrade langchain-openai # v0.1.0新增的底包OpenAI 模型封装
最基本的调度封装
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo") # 默认是gpt-3.5-turbo
response = llm.invoke("你是谁")
print(response.content)多轮对话 Session 封装
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
llm = ChatOpenAI() # 默认是gpt-3.5-turbo
from langchain.schema import (
AIMessage, #等价于OpenAI接口中的assistant role
HumanMessage, #等价于OpenAI接口中的user role
SystemMessage #等价于OpenAI接口中的system role
)
messages = [
SystemMessage(content="从现在开始你叫AI助手-小京。"),
HumanMessage(content="我是CSDN的一名博主,我叫Muller"),
AIMessage(content="欢迎!"),
HumanMessage(content="我是谁")
]
response = llm.invoke(messages)
print(response.content)通过模型封装,实现不同模型的统一接口调用
SystemMessage 描述你的大模型角色、功能、作用等等;
HumanMessage 用户输入的内容
AIMessage 大模型回答
通过这个Message数组就能表示一个摘要,原生的Openai通过一个json数组,每一轮都一个任务一个content来去表示一个对话上下文,那么在langchain的框架下,可以通过它定义的结构来去表示一个对话。然后呢,我们还是把这个对话通过invoke接口来传给大模型,就实现了这一种多轮对话的交互。
和Openai一样,对话历史还是需要我们自行进行管理的 ,具体langchain这个框架下需要如何管理对话历史后面再详细讲解。也就是说它不会自动帮我们填充里面的信息,例如你不附上content,它返回的实际上就是一个ai message ,如果你要维护这一个上下文的话,那你就需要将这个ai message填到数组里去发起下轮,就是这么一个逻辑。
换个国产模型
pip install qianfan# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 其它模型分装在 langchain_community 底包中
from langchain_community.chat_models import QianfanChatEndpoint
from langchain.schema import HumanMessage
import os
qianfan = QianfanChatEndpoint(
qianfan_ak=os.getenv('ERNIE_CLIENT_ID'),
qianfan_sk=os.getenv('ERNIE_CLIENT_SECRET')
)
messages = [
HumanMessage(content="你是谁")
]
response = qianfan.invoke(messages)
print(response.content)通过这么一个简单的例子就能体会到模型的封装的一个好处就是不同的模型我都用统一的接口去调用,如果都是openai我就不用管你是3.5还是4,我都统一用这个接口,甚至我换一个模型,还是这样一个结构去调用,我接口是不用变的。
模型的输入与输出
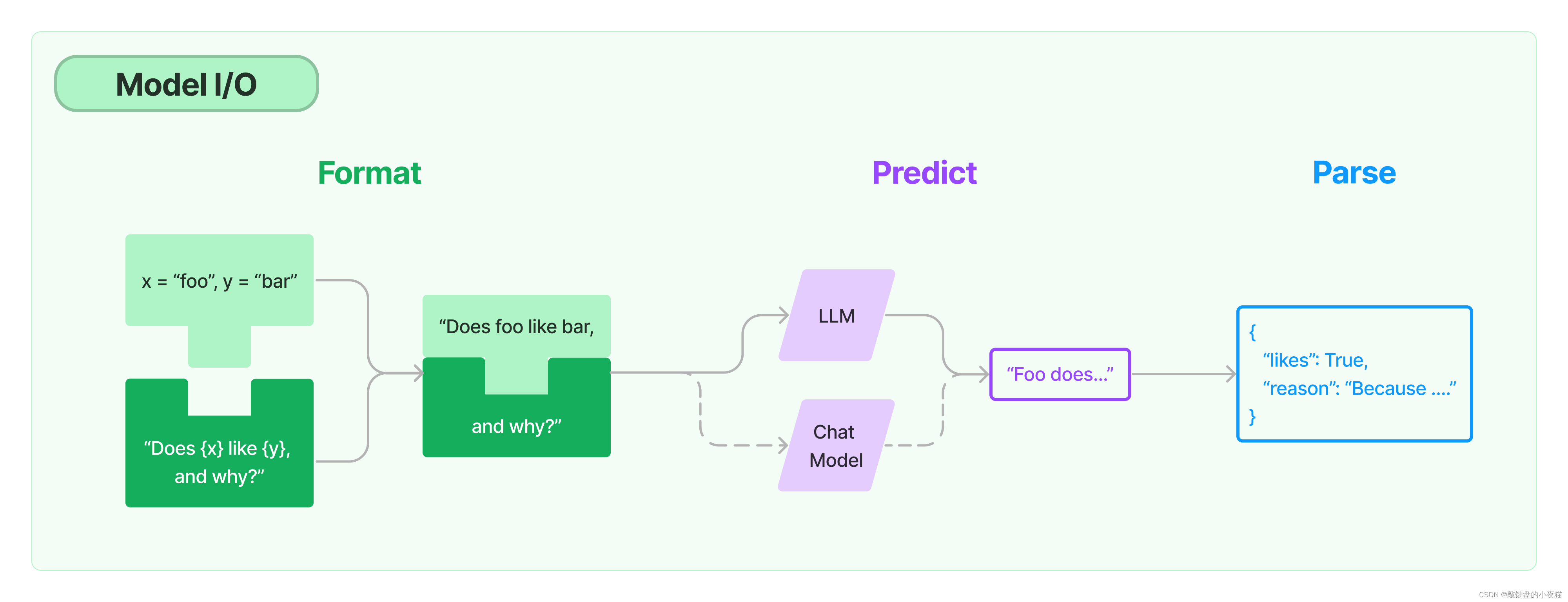
Prompt 模板封装
PromptTemplate
对一段文字生成了一个提示词模板。提供了一个函数将字符串转成一个模板。
from langchain.prompts import PromptTemplate
print("====模板====")
template = PromptTemplate.from_template("帮我解释一下这个成语:{idiom}")
print(template)
print("====提示词====")
print(template.format(idiom='繁花似锦'))模板包含两个元素,一个是模板内容,另一个是模板内代填的变量给提取出来。
====模板====
input_variables=['idiom'] template='帮我解释一下这个成语:{idiom}'
====提示词====
#帮我解释一下这个成语:繁花似锦
ChatPromptTemplate
提供了把一个多轮对话上下文整个变成一个多轮模板的形式,用模板表示的对话上下文。
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import SystemMessagePromptTemplate, HumanMessagePromptTemplate
from langchain_openai.chat_models import ChatOpenAI
# 定义聊天提示词
template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一名{subject}老师,你的名字叫{name}"),
HumanMessagePromptTemplate.from_template("{query}"),
]
)
llm = ChatOpenAI()
# 生成大模型输入
prompt = template.format_messages(
subject="语文",
name="muller",
query="告诉我你是谁,然后帮我解释一下这个成语:繁花似锦"
)
response = llm.invoke(prompt)
print(response.content)
#你好,我是一名语文老师,名叫Muller。
#繁花似锦是一个形容词成语,用来形容景色美丽、繁华盛开的样子。其中,“繁花”指的是许多花朵,而“似#锦”则表示美丽多彩、如锦绣般的样子。
#这个成语常用来形容春天或夏天花朵盛开的景象,也可以用来形容其他美丽的景色或事物。它表达了繁花##绚烂的美丽,给人以愉悦和喜悦的感觉。MessagesPlaceholder
通过MessagesPlaceholder把多轮对话整个变成模板,它的作用就是解决逐轮对话写入麻烦的问题,例如上述代码,需要不断在from_messages填充多个元素表示多轮对话,当历史对话发生变化需重新填充,因为对话历史本身就是一个Message List,那么就可以直接把message List填写到对话的中间,如下列代码MessagesPlaceholder(variable_name="历史对话") 留了一个多轮的占位符 ,给该占位符取了一个名字为:“历史对话”。
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
)
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain_openai.chat_models import ChatOpenAI
llm = ChatOpenAI()
# 定义一个用户对话模板
human_message_template = HumanMessagePromptTemplate.from_template("帮我解释一下这个成语: {idiom}.")
# 定义当前聊天提示词,传参 历史聊天记录和用户对话模板
chat_prompt = ChatPromptTemplate.from_messages(
# variable_name 是 message placeholder 在模板中的变量名
# 用于在赋值时使用
[MessagesPlaceholder(variable_name="历史对话"), human_message_template]
)
#定义大模型角色说明,AI、Human、System
from langchain_core.messages import AIMessage, HumanMessage,SystemMessage
#大模型角色说明
system_message = SystemMessage(content="你是一名语文老师,你的名字叫muller")
#用户对话1
human_message = HumanMessage(content="告诉我你是谁?")
#大模型回答1
ai_message = AIMessage(content="我是一名语文老师,名叫Muller")
# 生成大模型输入
messages = chat_prompt.format_prompt(
# 对 "conversation" 和 "language" 赋值
历史对话=[system_message,human_message, ai_message], idiom="繁花似锦"
)
print(messages.to_messages())
result = llm.invoke(messages)
print(result.content)
# 繁花似锦是一个形容词成语,用来形容景色美丽、繁华盛开的样子。其中,“繁花”指的是许多花朵,而# “似锦”则表示美丽多彩、如锦绣般的样子。
# 这个成语常用来形容春天或夏天花朵盛开的景象,也可以用来形容其他美丽的景色或事物。它表达了繁花# 绚烂的美丽,给人以愉悦和喜悦的感觉。从文件加载 Prompt 模板
我们在开发模式可以通过在代码中通过字符串定义模板,但实际生产中则需要将代码和prompt进行分离,这样便于整个项目的管理。Langchain也提供了像SK一样的能力,可以支持加载一个文件为Prompt模板,例如Txt加载方式是将字符串放到了txt文件中。
TXT模板
帮我解释一下这个成语:{idiom}from langchain.prompts import PromptTemplate
template = PromptTemplate.from_file("example_prompt_template.txt")
print("===Template===")
print(template)
print("===Prompt===")
print(template.format(topic='繁花似锦'))
# ===Template===
# input_variables=['idiom'] template='帮我解释一下这个成语:{idiom}'
#===Prompt===
# 帮我解释一下这个成语:繁花似锦Yaml模板
_type: prompt
input_variables:
["subject", "idiom"]
template:
你是一名{subject}老师,帮我解释一下这个成语:{idiom}from langchain.prompts import load_prompt
prompt = load_prompt("simple_prompt.yaml")
print(prompt.format(subject="语文", idiom="繁花似锦"))Json模板
{
"_type": "prompt",
"input_variables": ["idiom"],
"template": "帮我解释一下这个成语:{idiom}"
}from langchain.prompts import load_prompt
prompt = load_prompt("simple_prompt.json")
print(prompt.format(subject="语文", idiom="繁花似锦"))输出封装 OutputParser
自动把 LLM 输出的字符串按指定格式加载,如果通过规定格式输出,对程序解析有好处。
LangChain 内置的 OutputParser 包括但不仅限于:
- ListParser
- DatetimeParser
- EnumParser
- JsonOutputParser
- PydanticParser
- XMLParser
详细用例直通车:Output Parsers | 🦜️🔗 LangChain
 Pydantic (JSON) Parser
Pydantic (JSON) Parser
我们可以使用python的Pydantic类,去定义一个特定的结构,且这个结构是带含义描述的结构体,然后这个结构体我们可以从JSON结构中转换成它,也可以将它转换成JSON格式。而Langchain就是提供了解析Pydantic结构对象的能力。
打个比方有个日期类,日期有“年”、“月”、“日” 和 “公元前/公元后” 这四个字段组成。假设我们需要一个这个类的对象,那么我们就可以通过依据Pydantic类格式将它描述出来,然后用Langchain提供的Pydantic解析器让大模型按这个格式输出结果,然后用Parser从大模型的结果里去解析出这个对象来,后面就可以让依据程序逻辑使用这个结构化的结果了。
具体例子如下:一般描述类属性对象已具备基本能力,但如果你需要校验对象值的合法性,就需要用到Pydantic的能力,即@validator和@staticmethod的注解内容。
# 定义Pydantic结构
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from typing import List, Dict
# 定义你的输出对象
class Date(BaseModel):
year: int = Field(description="Year")
month: int = Field(description="Month")
day: int = Field(description="Day")
era: str = Field(description="BC or AD")
# ----- 可选机制 --------
# 你可以添加自定义的校验机制
@validator('month')
def valid_month(cls, field):
if field <= 0 or field > 12:
raise ValueError("月份必须在1-12之间")
return field
@validator('day')
def valid_day(cls, field):
if field <= 0 or field > 31:
raise ValueError("日期必须在1-31日之间")
return field
@validator('day', pre=True, always=True)
def valid_date(cls, day, values):
year = values.get('year')
month = values.get('month')
# 确保年份和月份都已经提供
if year is None or month is None:
return day # 无法验证日期,因为没有年份和月份
# 检查日期是否有效
if month == 2:
if cls.is_leap_year(year) and day > 29:
raise ValueError("闰年2月最多有29天")
elif not cls.is_leap_year(year) and day > 28:
raise ValueError("非闰年2月最多有28天")
elif month in [4, 6, 9, 11] and day > 30:
raise ValueError(f"{month}月最多有30天")
return day
@staticmethod
def is_leap_year(year):
if year % 400 == 0 or (year % 4 == 0 and year % 100 != 0):
return True
return False#使用Pydantic
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
model_name = 'gpt-3.5-turbo'
temperature = 0
model = ChatOpenAI(model_name=model_name, temperature=temperature)
# 根据Pydantic对象的定义,构造一个OutputParser
parser = PydanticOutputParser(pydantic_object=Date)
template = """提取用户输入中的日期。
{format_instructions}
用户输入:
{query}"""
prompt = PromptTemplate(
template=template,
input_variables=["query"],
# 直接从OutputParser中获取输出描述,并对模板的变量预先赋值
partial_variables={"format_instructions": parser.get_format_instructions()}
)
print("====Format Instruction=====")
print(parser.get_format_instructions())
query = "2024年五月1日即将实施的《非银行支付机构监督管理条例》,将非银行支付机构及其业务活动进一步纳入法治化轨道进行监管。"
model_input = prompt.format_prompt(query=query)
print("====Prompt=====")
print(model_input.to_string())
output = model(model_input.to_messages())
print("====模型原始输出=====")
print(output)
print("====Parse后的输出=====")
date = parser.parse(output.content)
print(date)====Format Instruction=====
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```
{"properties": {"year": {"title": "Year", "description": "Year", "type": "integer"}, "month": {"title": "Month", "description": "Month", "type": "integer"}, "day": {"title": "Day", "description": "Day", "type": "integer"}, "era": {"title": "Era", "description": "BC or AD", "type": "string"}}, "required": ["year", "month", "day", "era"]}
```
====Prompt=====
提取用户输入中的日期。
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```
{"properties": {"year": {"title": "Year", "description": "Year", "type": "integer"}, "month": {"title": "Month", "description": "Month", "type": "integer"}, "day": {"title": "Day", "description": "Day", "type": "integer"}, "era": {"title": "Era", "description": "BC or AD", "type": "string"}}, "required": ["year", "month", "day", "era"]}
```
用户输入:
2024年五月1日即将实施的《非银行支付机构监督管理条例》,将非银行支付机构及其业务活动进一步纳入法治化轨道进行监管。
====模型原始输出=====
content='{"year": 2024, "month": 5, "day": 1, "era": "AD"}'
====Parse后的输出=====
year=2024 month=5 day=1 era='AD'
Auto-Fixing Parser
Openai不一定保证百分之百每一次结果输出的格式你要的能一模一样,例如返回的内容都是中文或json格式错误等问题,所以大模型输出的结果本身存在一定的不确定性,那就导致如果格式错了,那么OutputParser解析会失败,为了失败了能够再次尝试去自动修复这个格式上的错误,重新解析,Langchain还提供了Auto-Fixing Paser。
核心它完成了大模型输出的结果是错的,导致解析失败时,它会尝试修改格式再做一次自动的解析。定义这块功能需要将原始的Parser给它,同时还需要给它大模型对象。
# 加载 .env 到环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_core.pydantic_v1 import BaseModel, Field, validator
# 定义你的输出对象
class Date(BaseModel):
year: int = Field(description="Year")
month: int = Field(description="Month")
day: int = Field(description="Day")
era: str = Field(description="BC or AD")
# ----- 可选机制 --------
# 你可以添加自定义的校验机制
@validator('month')
def valid_month(cls, field):
if field <= 0 or field > 12:
raise ValueError("月份必须在1-12之间")
return field
@validator('day')
def valid_day(cls, field):
if field <= 0 or field > 31:
raise ValueError("日期必须在1-31日之间")
return field
@validator('day', pre=True, always=True)
def valid_date(cls, day, values):
year = values.get('year')
month = values.get('month')
# 确保年份和月份都已经提供
if year is None or month is None:
return day # 无法验证日期,因为没有年份和月份
# 检查日期是否有效
if month == 2:
if cls.is_leap_year(year) and day > 29:
raise ValueError("闰年2月最多有29天")
elif not cls.is_leap_year(year) and day > 28:
raise ValueError("非闰年2月最多有28天")
elif month in [4, 6, 9, 11] and day > 30:
raise ValueError(f"{month}月最多有30天")
return day
@staticmethod
def is_leap_year(year):
if year % 400 == 0 or (year % 4 == 0 and year % 100 != 0):
return True
return False
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
model_name = 'gpt-3.5-turbo'
temperature = 0
model = ChatOpenAI(model_name=model_name, temperature=temperature)
# 根据Pydantic对象的定义,构造一个OutputParser
parser = PydanticOutputParser(pydantic_object=Date)
template = """提取用户输入中的日期。
{format_instructions}
用户输入:
{query}"""
prompt = PromptTemplate(
template=template,
input_variables=["query"],
# 直接从OutputParser中获取输出描述,并对模板的变量预先赋值
partial_variables={"format_instructions": parser.get_format_instructions()}
)
query = "2024年五月1日即将实施的《非银行支付机构监督管理条例》,将非银行支付机构及其业务活动进一步纳入法治化轨道进行监管。"
model_input = prompt.format_prompt(query=query)
output = model(model_input.to_messages())
# 解决output输出尽量可控
from langchain.output_parsers import OutputFixingParser
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI(model="gpt-3.5-turbo"))
# 因为这个例子比较简单,大模型比较难出错,这里手动替换成错误值
output = output.content.replace("5", "五月")
print("===格式错误的Output===")
print(output)
try:
date = parser.parse(output)
except Exception as e:
print("===出现异常===")
print(e)
# 用OutputFixingParser自动修复并解析
date = new_parser.parse(output)
print("===重新解析结果===")
print(date)===格式错误的Output===
{"year": 2024, "month": 五月, "day": 1, "era": "AD"}
===出现异常===
Failed to parse Date from completion {"year": 2024, "month": 五月, "day": 1, "era": "AD"}. Got: Expecting value: line 1 column 25 (char 24)
===重新解析结果===
year=2024 month=5 day=1 era='AD'
总结
关键点提取
本文关键内容提取:
1、LangChain 统一封装了各种模型的调用接口,包括补全型和对话型两种;
2、LangChain 提供了 PromptTemplate 类,可以自定义带变量的模板;
3、LangChain 提供了一些列输出解析器,用于将大模型的输出解析成结构化对象;额外带有自动修复功能;
4、模型属于 LangChain 中较为优秀的部分;美中不足的是 OutputParser 自身的 Prompt 维护在代码中,耦合度较高。
使用感触
从这段时间接触Langchain,从使用角度上感触如下:
- Langchain对大模型的封装是可用的。对此结论的评价标准是假设即使不用Langchian的情况下,自己去设计一套应用,同样对大模型调用接口上也进行一个类似抽象,自己是否能保证从chatgpt模型切到claude模型后不会造成代码大规模的调整,在这个尝试上我发现是Langchain可行的,并且所调整的代码极少。
- Langchain对于PromptTemplate的封装在早期的确实很粗糙,但现在的版本基本达到可用状态。不难看出从字符串加载、从文件加载,甚至嵌套方式加载目前都已具备了,所以PromptTemplate这个功能从个人而言并没有发现特别大的弊端导致不推荐的情况,因此可以认为它也是一个可用的模块,而且即使你不用Langchain来管理,你也可以来参考它这种模式,就是将Prompt和代码分开来管理,以完成填槽的逻辑。
- OutputParser情况却没有很理想,首先它是基本可用的,例如JsonParser这些基础解析是可用的,但Auto-Fixing Parser则需要注意的就是它自己内部是有Prompt模板的。它的Prompt模板写的如何,在你的这个业务中是否通用?是否未来对所有的模型都兼容?这些是需要酌情考虑使用的。在使用这些非代码的功能,即不确定的功能的时候,需要注意的是不能因为模型变化了结果却不是最优解的情况,例如当初是基于gpt4编写生产好用,而更换到gpt5了它的这个模板就不是最优解了,或导致该功能就失效了。这里我更推荐的一个做法就是使用这些内置Prompt模板功能或不确定的代码时候,强烈推荐能够单独将这部分Prompt抽出来管理,就是把Prompt抽出来去维护,哪怕真的要用它写的功能也要拷贝出来单独维护,这样的好处在于未来你的模型换了,出现非最优解时,你能知道改哪里,好导致你不用梳理整个逻辑改整块代码。
![[代码比较工具下载及使用]你真的需要一个代码比较工具](https://img-blog.csdnimg.cn/direct/023e6b1c7b534a2abed0bae1721cee78.gif)