写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除!
文章目录
- 前言
- 快速开始
- 安装依赖
- 权重下载及复原
- 训练网络
- 数据集
- 训练脚本
- 代码详解
- 训练
- BaseOptions
- TrainOptions
- 模型
- 解析网络
- 判别器网络
- 生成器网络
- BaseModel
- EnhanceModel
- PSFRGenerator
- 谱归一化
- 模型修改(三步走)
- 第一步:修改网络结构
- 第二步:修改网络定义
- 第三步:修改退化类型
- 恢复效果
- 致谢
- 参考
前言
PSFR-GAN是一个基于深度学习的开源项目,其主要目标是实现高质量的人脸图像盲复原。PSFR-GAN的核心是生成对抗网络,包括两个部分:生成器和判别器。生成器负责从低分辨率图像生成高分辨率图像,而判别器则试图区分真实高分辨率图像与生成器产生的图像。在训练过程中,这两个网络相互竞争并共同提升,直至生成器可以产出难以被判别器识破的高分辨率图像。
PSFR-GAN在图像超分辨率重建方面有以下特点:
-
结合了几何先验,能够生成具有清晰面部形状和逼真面部细节的图像。
-
引入了语义感知风格损失算法,该算法分别计算每个语义区域的特征风格损失,有助于提高不同语义区域的纹理恢复,减少伪影的发生。
-
充分利用了不同尺度输入对的语义(解析图)和像素(LQ图像)空间信息,通过FPN为LQ输入生成解析映射,以多尺度LQ图像和解析图为输入,通过语义感知风格变换,逐步恢复高质量的人脸细节。
此外,PSFR-GAN还对人脸解析网络进行了预训练,可以生成来自真实世界的LQ人脸图像的解析图。
PSFR-GAN的源代码已在 Github(PSFRGAN) || Gitee(PSFRGAN)上公开发布,为图像复原领域的研究提供了借鉴和参考。相关论文阅读可移步PSFR-GAN:一种结合几何先验的渐进式复原网络。
快速开始
安装依赖
此处以Gitee(PSFRGAN)为例说明,因为其提供了中文的readme。
- CUDA 10.1
- 克隆仓库
git clone https://gitee.com/qianxdong/PSFRGAN.git cd PSFR-GAN - Python 3.7, 运行
pip install -r requirements.txt以安装依赖
权重下载及复原
从以下链接下载经过预训练的模型,并将其放到 ./pretrain_models
- Github
- BaiduNetDisk, 提取码:
gj2r
运行以下脚本以增强单个输入中的人脸,更多用法参考readme。
python test_enhance_single_unalign.py --test_img_path ./test_dir/test_hzgg.jpg --results_dir test_hzgg_results --gpus 1
参数详解:
- 裁剪并对齐输入图像中的所有面,存储在
results_dir/LQ_faces - 人脸解析图和复原图像,分别存储在
results_dir/ParseMapsandresults_dir/HQ - 将复原后的人脸粘贴回原始图像
results_dir/hq_final.jpg - 设置
--gpusto 指定GPU的数量,<=0则意味着在CPU上进行测试. 该程序将使用具有最多可用内存的GPU。如果不希望自动选择GPU,请设置CUDA_VISIBLE_DEVICE以指定GPU。
训练网络
数据集
- 下载 FFHQ 并将其放入
../datasets/FFHQ/imgs1024 - 下载 人脸解析图 (
512x512) HERE 并将其放入../datasets/FFHQ/masks512.
注意:可以更改/datasets/FFHQ到自己的路径。但图像和掩码必须分别存储在your_own_path/imgs1024和your_oown_path/masks512下
训练脚本
以下是PSFRGAN的训练脚本示例:
python train.py --gpus 2 --model enhance --name PSFRGAN_v001 \
--g_lr 0.0001 --d_lr 0.0004 --beta1 0.5 \
--gan_mode 'hinge' --lambda_pix 10 --lambda_fm 10 --lambda_ss 1000 \
--Dinput_nc 22 --D_num 3 --n_layers_D 4 \
--batch_size 2 --dataset ffhq --dataroot ../datasets/FFHQ \
--visual_freq 100 --print_freq 10 #--continue_train
- 请更改不同实验的
--name选项。具有相同名称的Tensorboard记录将被移动到check_points/log_archive,权重目录将只存储具有相同名称最新实验的权重历史。 --gpus指定用于训练的GPU的数量。脚本将首先使用具有更多可用内存的GPU。要指定GPU索引,请在脚本前使用export CUDA_VISIBLE_DEVICES=your_GPU_ids。- 取消注释
--continue_train以恢复训练 当前代码不会恢复优化器状态。 - batch_size=1 至少需要 8GB 内存才能进行训练。
代码详解
训练
from utils.timer import Timer
from utils.logger import Logger
from options.train_options import TrainOptions
from data import create_dataset
from models import create_model
def train(opt):
dataset = create_dataset(opt) # create a dataset given opt.dataset_mode and other options
dataset_size = len(dataset) # get the number of images in the dataset.
print('The number of training images = %d' % dataset_size)
model = create_model(opt)
model.setup(opt)
logger = Logger(opt)
timer = Timer()
single_epoch_iters = (dataset_size // opt.batch_size)
total_iters = opt.total_epochs * single_epoch_iters
cur_iters = opt.resume_iter + opt.resume_epoch * single_epoch_iters
start_iter = opt.resume_iter
print('Start training from epoch: {:05d}; iter: {:07d}'.format(opt.resume_epoch, opt.resume_iter))
for epoch in range(opt.resume_epoch, opt.total_epochs + 1):
for i, data in enumerate(dataset, start=start_iter):
cur_iters += 1
logger.set_current_iter(cur_iters)
# =================== load data ===============
略
# =================== model train ===============
略
# =================== save model and visualize ===============
略
logger.close()
if __name__ == '__main__':
opt = TrainOptions().parse()
train(opt)
总体就是获取训练参数以及训练,其中TrainOptions继承于BaseOptions,其中主要包含了生成器和判别器的训练参数以及可视化的参数。
BaseOptions
class BaseOptions():
def __init__(self):
"""Reset the class; indicates the class hasn't been initailized"""
self.initialized = False
def initialize(self, parser):
"""Define the common options that are used in both training and test."""
# basic parameters
parser.add_argument('--dataroot', required=False, help='path to images')
parser.add_argument('--name', type=str, default='experiment_name', help='name of the experiment. It decides where to store samples and models')
parser.add_argument('--gpus', type=int, default=1, help='how many gpus to use')
parser.add_argument('--seed', type=int, default=123, help='Random seed for training')
parser.add_argument('--checkpoints_dir', type=str, default='./check_points', help='models are saved here')
# model parameters
parser.add_argument('--model', type=str, default='enhance', help='chooses which model to train [parse|enhance]')
parser.add_argument('--input_nc', type=int, default=3, help='# of input image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--Dinput_nc', type=int, default=3, help='# of input image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--output_nc', type=int, default=3, help='# of output image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in the last conv layer')
parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in the first conv layer')
parser.add_argument('--n_layers_D', type=int, default=4, help='downsampling layers in discriminator')
parser.add_argument('--D_num', type=int, default=3, help='numbers of discriminators')
parser.add_argument('--Pnorm', type=str, default='bn', help='parsing net norm [in | bn| none]')
parser.add_argument('--Gnorm', type=str, default='spade', help='generator norm [in | bn | none]')
parser.add_argument('--Dnorm', type=str, default='in', help='discriminator norm [in | bn | none]')
parser.add_argument('--init_type', type=str, default='normal', help='network initialization [normal | xavier | kaiming | orthogonal]')
parser.add_argument('--init_gain', type=float, default=0.02, help='scaling factor for normal, xavier and orthogonal.')
# dataset parameters
parser.add_argument('--dataset_name', type=str, default='single', help='dataset name')
parser.add_argument('--Pimg_size', type=int, default='512', help='image size for face parse net')
parser.add_argument('--Gin_size', type=int, default='512', help='image size for face parse net')
parser.add_argument('--Gout_size', type=int, default='512', help='image size for face parse net')
parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
parser.add_argument('--num_threads', default=8, type=int, help='# threads for loading data')
parser.add_argument('--batch_size', type=int, default=16, help='input batch size')
parser.add_argument('--load_size', type=int, default=512, help='scale images to this size')
parser.add_argument('--crop_size', type=int, default=256, help='then crop to this size')
parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
parser.add_argument('--preprocess', type=str, default='none', help='scaling and cropping of images at load time [resize_and_crop | crop | scale_width | scale_width_and_crop | none]')
parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data augmentation')
# additional parameters
parser.add_argument('--epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
parser.add_argument('--load_iter', type=int, default='0', help='which iteration to load? if load_iter > 0, the code will load models by iter_[load_iter]; otherwise, the code will load models by [epoch]')
parser.add_argument('--verbose', action='store_true', help='if specified, print more debugging information')
parser.add_argument('--suffix', default='', type=str, help='customized suffix: opt.name = opt.name + suffix: e.g., {model}_{netG}_size{load_size}')
parser.add_argument('--debug', action='store_true', help='if specified, set to debug mode')
self.initialized = True
return parser
其中需要注意:
- 随机种子:是保证复现的关键,默认123
- batch_size:默认16,显存不够可减少
- 调试:可使用 --debug
TrainOptions
- 注意:打印输出、可视化、保存文件等频率不能太高,即print_freq、visual_freq、save_iter_freq、save_epoch_freq等,否则GPU和CPU之间切换频繁,不利于训练。
- 通常来说鉴别器的学习率小于生成器,因为鉴别器的任务更见简单,很容易导致鉴别器的能力由于生成器,因此需要让鉴别器步子小一点。
- 对抗损失也选择,不同的损失函数有不一样的效果
class TrainOptions(BaseOptions):
def initialize(self, parser):
parser = BaseOptions.initialize(self, parser)
# visdom and HTML visualization parameters
parser.add_argument('--visual_freq', type=int, default=400, help='frequency of show training images in tensorboard')
parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')
# network saving and loading parameters
parser.add_argument('--save_iter_freq', type=int, default=5000, help='frequency of saving the models')
parser.add_argument('--save_latest_freq', type=int, default=500, help='save latest freq')
parser.add_argument('--save_epoch_freq', type=int, default=5, help='frequency of saving checkpoints at the end of epochs')
parser.add_argument('--save_by_iter', action='store_true', help='whether saves model by iteration')
parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
parser.add_argument('--no_strict_load', action='store_true', help='set strict load to false')
parser.add_argument('--epoch_count', type=int, default=1, help='the starting epoch count, we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>, ...')
parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
# training parameters
parser.add_argument('--resume_epoch', type=int, default=0, help='training resume epoch')
parser.add_argument('--resume_iter', type=int, default=0, help='training resume iter')
parser.add_argument('--total_epochs', type=int, default=50, help='# of epochs to train')
parser.add_argument('--n_epochs', type=int, default=100, help='number of epochs with the initial learning rate')
parser.add_argument('--n_epochs_decay', type=int, default=100, help='number of epochs to linearly decay learning rate to zero')
parser.add_argument('--niter_decay', type=int, default=100, help='# of iter to linearly decay learning rate to zero')
parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
parser.add_argument('--g_lr', type=float, default=0.0001, help='generator learning rate')
parser.add_argument('--d_lr', type=float, default=0.0004, help='discriminator learning rate')
parser.add_argument('--gan_mode', type=str, default='hinge', help='the type of GAN objective. [vanilla| lsgan | wgangp]. vanilla GAN loss is the cross-entropy objective used in the original GAN paper.')
parser.add_argument('--lr_policy', type=str, default='step', help='learning rate policy. [linear | step | plateau | cosine]')
parser.add_argument('--lr_decay_iters', type=int, default=50, help='multiply by a gamma every lr_decay_iters iterations')
parser.add_argument('--lr_decay_gamma', type=float, default=1, help='multiply by a gamma every lr_decay_iters iterations')
self.isTrain = True
return parser
模型
模型的包含了生成器和判别器,这里额外包含了一个解析网络。
解析网络
解析网络总体是以编码-解码的形式,parsing_ch=19,这是人脸面部成分数量,即眼镜、鼻子嘴巴等等。这个是预训练好的基本上不需要自行训练。
class ParseNet(nn.Module):
def __init__(self,
in_size=128,
out_size=128,
min_feat_size=32,
base_ch=64,
parsing_ch=19,
res_depth=10,
relu_type='prelu',
norm_type='bn',
ch_range=[32, 512],
):
super().__init__()
self.res_depth = res_depth
act_args = {'norm_type': norm_type, 'relu_type': relu_type}
min_ch, max_ch = ch_range
ch_clip = lambda x: max(min_ch, min(x, max_ch))
min_feat_size = min(in_size, min_feat_size)
down_steps = int(np.log2(in_size//min_feat_size))
up_steps = int(np.log2(out_size//min_feat_size))
# =============== define encoder-body-decoder ====================
self.encoder = []
self.encoder.append(ConvLayer(3, base_ch, 3, 1))
head_ch = base_ch
for i in range(down_steps):
cin, cout = ch_clip(head_ch), ch_clip(head_ch * 2)
self.encoder.append(ResidualBlock(cin, cout, scale='down', **act_args))
head_ch = head_ch * 2
self.body = []
for i in range(res_depth):
self.body.append(ResidualBlock(ch_clip(head_ch), ch_clip(head_ch), **act_args))
self.decoder = []
for i in range(up_steps):
cin, cout = ch_clip(head_ch), ch_clip(head_ch // 2)
self.decoder.append(ResidualBlock(cin, cout, scale='up', **act_args))
head_ch = head_ch // 2
self.encoder = nn.Sequential(*self.encoder)
self.body = nn.Sequential(*self.body)
self.decoder = nn.Sequential(*self.decoder)
self.out_img_conv = ConvLayer(ch_clip(head_ch), 3)
self.out_mask_conv = ConvLayer(ch_clip(head_ch), parsing_ch)
def forward(self, x):
feat = self.encoder(x)
x = feat + self.body(feat)
x = self.decoder(x)
out_img = self.out_img_conv(x)
out_mask = self.out_mask_conv(x)
return out_mask, out_img
判别器网络
此处是使用了多尺度判别器,即需要在几个尺度对输入判别器的输出特征计算损失以判断输入图像的真假。此外还可选择是否返回所有中间层的特征。下列参数可决定判别器的个数、判别器的层数以及通道数以控制判别器的复杂程度。
parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in the first conv layer')
parser.add_argument('--n_layers_D', type=int, default=4, help='downsampling layers in discriminator')
parser.add_argument('--D_num', type=int, default=3, help='numbers of discriminators')
-
MultiScaleDiscriminator类包含了一个由多个NLayerDiscriminator组成的列表(D_pool),每个NLayerDiscriminator都在不同的尺度上操作输入图像。在forward方法中,输入图像input被传递给每个判别器,并且在每次传递后,输入图像都会通过平均池化层(downsample)进行下采样,以便在下一个判别器中使用较小的尺度。最后,返回每个判别器的输出。 -
NLayerDiscriminator类定义了一个多层的判别器网络。网络由一系列卷积层组成。网络的深度由depth参数控制,每一层的输入和输出通道数逐渐增加,但不超过max_ch。在网络的最后,有一个额外的ConvLayer来输出最终的判别分数。
class MultiScaleDiscriminator(nn.Module):
def __init__(self, input_ch, base_ch=64, n_layers=3, norm_type='none', relu_type='LeakyReLU', num_D=4):
super().__init__()
self.D_pool = nn.ModuleList()
for i in range(num_D):
netD = NLayerDiscriminator(input_ch, base_ch, depth=n_layers, norm_type=norm_type, relu_type=relu_type)
self.D_pool.append(netD)
self.downsample = nn.AvgPool2d(3, stride=2, padding=[1, 1], count_include_pad=False)
def forward(self, input, return_feat=False):
results = []
for netd in self.D_pool:
output = netd(input, return_feat)
results.append(output)
# Downsample input
input = self.downsample(input)
return results
class NLayerDiscriminator(nn.Module):
def __init__(self,
input_ch = 3,
base_ch = 64,
max_ch = 1024,
depth = 4,
norm_type = 'none',
relu_type = 'LeakyReLU',
):
super().__init__()
nargs = {'norm_type': norm_type, 'relu_type': relu_type}
self.norm_type = norm_type
self.input_ch = input_ch
self.model = []
self.model.append(ConvLayer(input_ch, base_ch, norm_type='none', relu_type=relu_type))
for i in range(depth):
cin = min(base_ch * 2**(i), max_ch)
cout = min(base_ch * 2**(i+1), max_ch)
self.model.append(ConvLayer(cin, cout, scale='down_avg', **nargs))
self.model = nn.Sequential(*self.model)
self.score_out = ConvLayer(cout, 1, use_pad=False)
def forward(self, x, return_feat=False):
ret_feats = []
for idx, m in enumerate(self.model):
x = m(x)
ret_feats.append(x)
x = self.score_out(x)
if return_feat:
return x, ret_feats
else:
return x
生成器网络
生成器网络继承于BaseModel,主要是通过装饰器来实现静态方法(@staticmethod )和抽象方法(@abstractmethod)。即面向对象编程,前者用于封装与类相关但不需要访问类实例状态的功能。后者任何继承自抽象基类的子类都必须实现抽象基类中的所有抽象方法,类似于C++中的纯虚函数,基类不定义任何实现,但是继承该类后需要重写该虚函数。
- 静态方法不需要类实例即可调用,并且它们不会隐式地接收类实例(
self)或类本身(cls)作为第一个参数。这意味着它们基本上只是附加到类上的普通函数,但在调用时可以通过类名或实例来访问。 @abstractmethod通常与abc(抽象基类)模块一起使用。它表示一个方法是抽象的,意味着它必须在任何继承自该类的子类中被覆盖(即实现)。如果子类没有实现该方法,那么在实例化子类时将会引发TypeError。
BaseModel
BaseModel中抽象方法声明了modify_commandline_options、set_input、forward、optimize_parameters方法,在继承时需要进行定义。
import os
import torch
from collections import OrderedDict
from abc import ABC, abstractmethod
from . import networks
class BaseModel(ABC):
def __init__(self, opt):
略
@staticmethod
def modify_commandline_options(parser, is_train):
return parser
@abstractmethod
def set_input(self, input):
pass
@abstractmethod
def forward(self):
pass
@abstractmethod
def optimize_parameters(self):
pass
EnhanceModel
一方面重写了上述的抽象函数,进一步定义了解析网络、生成器和判别器,以及众多损失的使用和网络更新等功能。
modify_commandline_options函数主要用于添加损失函数的权重set_input函数:定义传入网络的数据,包括退化图像、人脸解析图和高质量图像。forward函数:主要是生成人脸解析图,并将输入数据传入生成器、判别器和感知网络,用于后续计算损失。optimize_parameters函数:优化生成器和判别器的参数。- 需要注意:默认是先更新生成器再是判别器,需要保证后者更新时也有梯度,因此在在前向传播多次使用detach()从计算图中分离张量,使得该张量在后续的计算中不会计算梯度以确保反向传播正确。
class EnhanceModel(BaseModel):
# 重写该抽象函数
def modify_commandline_options(parser, is_train):
if is_train:
parser.add_argument('--parse_net_weight', type=str, default='./pretrain_models/parse_multi_iter_90000.pth', help='parse model path')
parser.add_argument('--lambda_pix', type=float, default=10.0, help='weight for parsing map')
parser.add_argument('--lambda_pcp', type=float, default=0.0, help='weight for vgg perceptual loss')
parser.add_argument('--lambda_fm', type=float, default=10.0, help='weight for sr')
parser.add_argument('--lambda_g', type=float, default=1.0, help='weight for sr')
parser.add_argument('--lambda_ss', type=float, default=1000., help='weight for global style')
return parser
def __init__(self, opt):
BaseModel.__init__(self, opt)
self.netP = networks.define_P(opt, weight_path=opt.parse_net_weight)
self.netG = networks.define_G(opt, use_norm='spectral_norm')
if self.isTrain:
self.netD = networks.define_D(opt, opt.Dinput_nc, use_norm='spectral_norm')
self.vgg_model = loss.PCPFeat(weight_path='./pretrain_models/vgg19-dcbb9e9d.pth').to(opt.device)
if len(opt.gpu_ids) > 0:
self.vgg_model = torch.nn.DataParallel(self.vgg_model, opt.gpu_ids, output_device=opt.device)
self.model_names = ['G']
self.loss_names = ['Pix', 'PCP', 'G', 'FM', 'D', 'SS'] # Generator loss, fm loss, parsing loss, discriminator loss
self.visual_names = ['img_LR', 'img_HR', 'img_SR', 'ref_Parse', 'hr_mask']
self.fm_weights = [1**x for x in range(opt.D_num)]
if self.isTrain:
self.model_names = ['G', 'D']
self.load_model_names = ['G', 'D']
self.criterionParse = torch.nn.CrossEntropyLoss().to(opt.device)
self.criterionFM = loss.FMLoss().to(opt.device)
self.criterionGAN = loss.GANLoss(opt.gan_mode).to(opt.device)
self.criterionPCP = loss.PCPLoss(opt)
self.criterionPix= nn.L1Loss()
self.criterionRS = loss.RegionStyleLoss()
self.optimizer_G = optim.Adam([p for p in self.netG.parameters() if p.requires_grad], lr=opt.g_lr, betas=(opt.beta1, 0.999))
self.optimizer_D = optim.Adam([p for p in self.netD.parameters() if p.requires_grad], lr=opt.d_lr, betas=(opt.beta1, 0.999))
self.optimizers = [self.optimizer_G, self.optimizer_D]
def eval(self):
self.netG.eval()
self.netP.eval()
def load_pretrain_models(self,):
self.netP.eval()
print('Loading pretrained LQ face parsing network from', self.opt.parse_net_weight)
if len(self.opt.gpu_ids) > 0:
self.netP.module.load_state_dict(torch.load(self.opt.parse_net_weight))
else:
self.netP.load_state_dict(torch.load(self.opt.parse_net_weight))
self.netG.eval()
print('Loading pretrained PSFRGAN from', self.opt.psfr_net_weight)
if len(self.opt.gpu_ids) > 0:
self.netG.module.load_state_dict(torch.load(self.opt.psfr_net_weight), strict=False)
else:
self.netG.load_state_dict(torch.load(self.opt.psfr_net_weight), strict=False)
def set_input(self, input, cur_iters=None):
self.cur_iters = cur_iters
self.img_LR = input['LR'].to(self.opt.device)
self.img_HR = input['HR'].to(self.opt.device)
self.hr_mask = input['Mask'].to(self.opt.device)
if self.opt.debug:
print('SRNet input shape:', self.img_LR.shape, self.img_HR.shape)
def forward(self):
with torch.no_grad():
ref_mask, _ = self.netP(self.img_LR)
self.ref_mask_onehot = (ref_mask == ref_mask.max(dim=1, keepdim=True)[0]).float().detach()
if self.opt.debug:
print('SRNet reference mask shape:', self.ref_mask_onehot.shape)
self.img_SR = self.netG(self.img_LR, self.ref_mask_onehot)
self.real_D_results = self.netD(torch.cat((self.img_HR, self.hr_mask), dim=1), return_feat=True)
self.fake_D_results = self.netD(torch.cat((self.img_SR.detach(), self.hr_mask), dim=1), return_feat=False)
self.fake_G_results = self.netD(torch.cat((self.img_SR, self.hr_mask), dim=1), return_feat=True)
self.img_SR_feats = self.vgg_model(self.img_SR)
self.img_HR_feats = self.vgg_model(self.img_HR)
def backward_G(self):
# Pix Loss
self.loss_Pix = self.criterionPix(self.img_SR, self.img_HR) * self.opt.lambda_pix
# semantic style loss
self.loss_SS = self.criterionRS(self.img_SR_feats, self.img_HR_feats, self.hr_mask) * self.opt.lambda_ss
# perceptual loss
self.loss_PCP = self.criterionPCP(self.img_SR_feats, self.img_HR_feats) * self.opt.lambda_pcp
# Feature matching loss
tmp_loss = 0
for i, w in zip(range(self.opt.D_num), self.fm_weights):
tmp_loss = tmp_loss + self.criterionFM(self.fake_G_results[i][1], self.real_D_results[i][1]) * w
self.loss_FM = tmp_loss * self.opt.lambda_fm / self.opt.D_num
# Generator loss
tmp_loss = 0
for i in range(self.opt.D_num):
tmp_loss = tmp_loss + self.criterionGAN(self.fake_G_results[i][0], True, for_discriminator=False)
self.loss_G = tmp_loss * self.opt.lambda_g / self.opt.D_num
total_loss = self.loss_Pix + self.loss_PCP + self.loss_FM + self.loss_G + self.loss_SS
total_loss.backward()
def backward_D(self, ):
self.loss_D = 0
for i in range(self.opt.D_num):
self.loss_D += 0.5 * (self.criterionGAN(self.fake_D_results[i], False) + self.criterionGAN(self.real_D_results[i][0], True))
self.loss_D /= self.opt.D_num
self.loss_D.backward()
def optimize_parameters(self, ):
# ---- Update G ------------
self.optimizer_G.zero_grad()
self.backward_G()
self.optimizer_G.step()
# ---- Update D ------------
self.optimizer_D.zero_grad()
self.backward_D()
self.optimizer_D.step()
PSFRGenerator
该类使用 SPADE(Spatially-Adaptive (DE)normalization)归一化层和 SPADE 残差块(SPADEResBlock)来根据参考图(ref)动态地调整归一化参数。
其中通过计算了网络中的上采样步骤数(up_steps),确定从最小特征图大小到输出大小所需的上采样次数。网络从一个可学习的常量输入(self.const_input),它将被用作网络生成过程的开始。构建了网络的“头部”(head)和“主体”(body)。最后,定义了一个输出卷积层(self.img_out)来将最终的特征图转换为所需的输出通道数。
代码如下:
class PSFRGenerator(nn.Module):
def __init__(self, input_nc, output_nc, in_size=512, out_size=512, min_feat_size=16, ngf=64, n_blocks=9, parse_ch=19, relu_type='relu',
ch_range=[32, 1024], norm_type='spade'):
super().__init__()
min_ch, max_ch = ch_range
ch_clip = lambda x: max(min_ch, min(x, max_ch))
get_ch = lambda size: ch_clip(1024*16//size)
self.const_input = nn.Parameter(torch.randn(1, get_ch(min_feat_size), min_feat_size, min_feat_size))
up_steps = int(np.log2(out_size//min_feat_size))
self.up_steps = up_steps
ref_ch = 19+3
head_ch = get_ch(min_feat_size)
head = [
nn.Conv2d(head_ch, head_ch, kernel_size=3, padding=1),
SPADEResBlock(head_ch, head_ch, ref_ch, relu_type, norm_type),
]
body = []
for i in range(up_steps):
cin, cout = ch_clip(head_ch), ch_clip(head_ch // 2)
body += [
nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(cin, cout, kernel_size=3, padding=1),
SPADEResBlock(cout, cout, ref_ch, relu_type, norm_type)
)
]
head_ch = head_ch // 2
self.img_out = nn.Conv2d(ch_clip(head_ch), output_nc, kernel_size=3, padding=1)
self.head = nn.Sequential(*head)
self.body = nn.Sequential(*body)
self.upsample = nn.Upsample(scale_factor=2)
def forward_spade(self, net, x, ref):
for m in net:
x = self.forward_spade_m(m, x, ref)
return x
def forward_spade_m(self, m, x, ref):
if isinstance(m, SPADENorm) or isinstance(m, SPADEResBlock):
x = m(x, ref)
else:
x = m(x)
return x
def forward(self, x, ref):
b, c, h, w = x.shape
const_input = self.const_input.repeat(b, 1, 1, 1)
ref_input = torch.cat((x, ref), dim=1)
feat = self.forward_spade(self.head, const_input, ref_input)
for idx, m in enumerate(self.body):
feat = self.forward_spade(m, feat, ref_input)
out_img = self.img_out(feat)
return out_img
SPADENorm类结合了空间自适应归一化(Spatially-Adaptive (DE)normalization, SPADE)和实例归一化(Instance Normalization, IN)。主要目的是根据输入的“参考”特征图(ref)来动态地调整归一化参数(gamma和beta)。
如果输入x和ref的空间维度不匹配,那么使用双三次插值(bicubic interpolation)来调整ref的大小以匹配x。根据归一化类型norm_type,执行以下操作:
norm_type='spade',则使用get_gamma_beta方法从ref中提取gamma和beta,并将它们应用于归一化后的输入。norm_type='in',则直接返回归一化后的输入(即不进行任何进一步的调整)。
代码如下:
class SPADENorm(nn.Module):
def __init__(self, norm_nc, ref_nc, norm_type='spade', ksz=3):
super().__init__()
self.param_free_norm = nn.InstanceNorm2d(norm_nc, affine=False)
mid_c = 64
self.norm_type = norm_type
if norm_type == 'spade':
self.conv1 = nn.Sequential(
nn.Conv2d(ref_nc, mid_c, ksz, 1, ksz//2),
nn.LeakyReLU(0.2, True),
)
self.gamma_conv = nn.Conv2d(mid_c, norm_nc, ksz, 1, ksz//2)
self.beta_conv = nn.Conv2d(mid_c, norm_nc, ksz, 1, ksz//2)
def get_gamma_beta(self, x, conv, gamma_conv, beta_conv):
act = conv(x)
gamma = gamma_conv(act)
beta = beta_conv(act)
return gamma, beta
def forward(self, x, ref):
normalized_input = self.param_free_norm(x)
if x.shape[-1] != ref.shape[-1]:
ref = nn.functional.interpolate(ref, x.shape[2:], mode='bicubic', align_corners=False)
if self.norm_type == 'spade':
gamma, beta = self.get_gamma_beta(ref, self.conv1, self.gamma_conv, self.beta_conv)
return normalized_input * gamma + beta
elif self.norm_type == 'in':
return normalized_input
SPADEResBlock 类定义了一个带有 SPADE(Spatially-Adaptive (DE)normalization)归一化层的残差块(Residual Block)。该残差块接收两个输入:特征图 x 和参考图 ref。由两次的卷积+归一化+激活函数构成。
该残差块结构允许网络学习恒等映射(identity mapping)作为特殊情况,有助于防止梯度消失和性能退化。此外,SPADE 归一化层允许网络根据参考图动态地调整归一化参数,可以使生成的特征图在空间和语义上与参考图对齐。
代码如下:
class SPADEResBlock(nn.Module):
def __init__(self, fin, fout, ref_nc, relu_type, norm_type='spade'):
super().__init__()
fmiddle = min(fin, fout)
self.conv_0 = nn.Conv2d(fin, fmiddle, kernel_size=3, padding=1)
self.conv_1 = nn.Conv2d(fmiddle, fout, kernel_size=3, padding=1)
# define normalization layers
self.norm_0 = SPADENorm(fmiddle, ref_nc, norm_type)
self.norm_1 = SPADENorm(fmiddle, ref_nc, norm_type)
self.relu = ReluLayer(fmiddle, relu_type)
def forward(self, x, ref):
res = self.conv_0(self.relu(self.norm_0(x, ref)))
res = self.conv_1(self.relu(self.norm_1(res, ref)))
out = x + res
return out
谱归一化
GAN的目标是让生成器和判别器之间进行对抗训练,以生成与真实数据尽可能相似的假数据。
然而,在训练过程中,如果判别器过于强大,它可能会迅速收敛到某个局部最优解,导致生成器的梯度消失,从而难以继续优化。而谱归一化则是一种限制网络变化剧烈程度的方法。
在 GAN 中,如果判别器是 M-Lipschitz 连续的,那么对图像空间中的任意
x
x
x和
x
′
x ^ {\prime }
x′有:
∣
∣
f
(
x
)
−
f
(
x
′
)
∣
∣
/
∣
∣
x
−
x
′
∣
∣
≤
M
| | f ( x ) - f ( x ^ { \prime } ) | | / | | x - x ^ { \prime } | | \leq M
∣∣f(x)−f(x′)∣∣/∣∣x−x′∣∣≤M
M-Lipschitz 连续的条件限制了函数变化的剧烈程度,即函数的梯度,简言之让鉴别器优化的步子放缓。典型代表有W-GAN 和W-GAN GP,前者分别采用了 权重裁剪实现Lipschitz限制。后者使用梯度惩罚来约束判别器参数以满足 1-Lipschitz 连续。旨在解决WGAN在处理Lipschitz限制条件时直接采用权重裁剪导致的梯度消失和梯度爆炸问题。
谱归一化的基本思想 : 对于神经网络中的每一层,特别是权重矩阵 W,计算其谱范数(即最大奇异值或L2范数),然后将其权重除以该谱范数,从而限制权重矩阵的“谱半径”为1。这有助于防止权重矩阵在训练过程中变得过大,从而有助于稳定训练过程。
通常它会涉及以下步骤:
- 计算权重矩阵 W 的谱范数(通常使用幂迭代方法)。
- 将权重矩阵 W 除以其谱范数,得到归一化后的权重矩阵。
- 在前向传播和反向传播中使用归一化后的权重矩阵。
代码如下:
def apply_norm(net, weight_norm_type):
for m in net.modules():
if isinstance(m, nn.Conv2d):
if weight_norm_type.lower() == 'spectral_norm':
tutils.spectral_norm(m)
elif weight_norm_type.lower() == 'weight_norm':
tutils.weight_norm(m)
else:
pass
-
优点:
- 训练稳定性:谱归一化通过限制权重矩阵的谱范数,可防止神经网络在训练过程中变得过于复杂或不稳定。有助于减少梯度消失或爆炸的问题,使得训练过程更加稳定。
- 防止过拟合:谱归一化可以限制网络的复杂性,从而在一定程度上防止过拟合。通过限制权重矩阵的谱范数,可以防止网络学习到过于复杂的模式,从而提高其泛化能力。
- 通过将鉴别器中的权重矩阵进行谱归一化,可以限制鉴别器的判别能力,防止其变得过于强大而导致训练不稳定。这有助于生成器在训练过程中保持一定的多样性,从而生成更多样化的样本。
-
缺点:
- 计算成本:谱归一化的计算成本相对较高。为了计算权重矩阵的谱范数,需要进行矩阵的特征值分解或迭代方法,会增加训练时间和计算资源的需求。
- 模型性能:谱归一化可以提高训练稳定性和泛化能力,但过度限制权重矩阵的谱范数也可能会对模型的性能产生负面影响。在某些情况下,较小的谱范数可能导致网络无法学习到足够的特征表示,从而影响其预测或生成能力。
- 依赖于初始化:谱归一化的效果可能受到网络初始化方式的影响。不同的初始化方法可能导致不同的谱范数范围,从而影响谱归一化的效果。
模型修改(三步走)
第一步:修改网络结构
修改psfrnet.py中的网络结构,具体修改还看自己的想法。
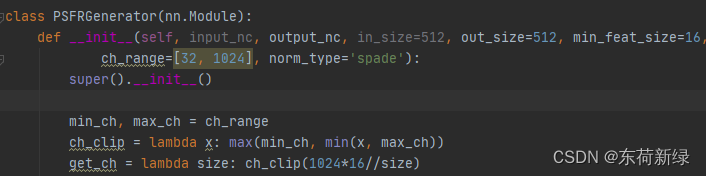
第二步:修改网络定义
修改network.py的网络定义,选择上述修改的类名并设置参数,需要因地制宜。

第三步:修改退化类型
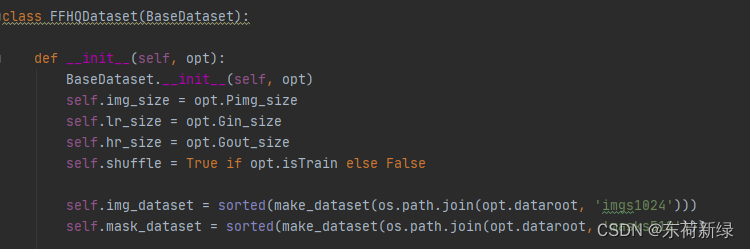
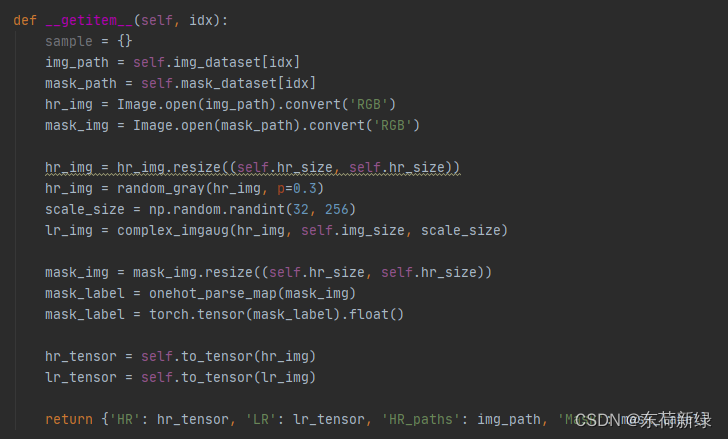
修改ffhq_dataset.py中FFHQDataset的图像路径与退化方式。
基本上根据这三步走,只要能正确修改,就可以开始玄学炼丹了。
恢复效果
| 还珠格格 | |
|---|---|
| 复原前 |  |
| 复原后 |  |
致谢
欲尽善本文,因所视短浅,怎奈所书皆是瞽言蒭议。行文至此,诚向予助与余者致以谢意。
参考
- https://github.com/chaofengc/PSFRGAN
- https://gitee.com/qianxdong/PSFRGAN






![[Linux][网络][协议技术][DNS][ICMP][ping][traceroute][NAT]详细讲解](https://img-blog.csdnimg.cn/direct/868c6a49c3df45b1b5dc8f7d7a68a193.png)