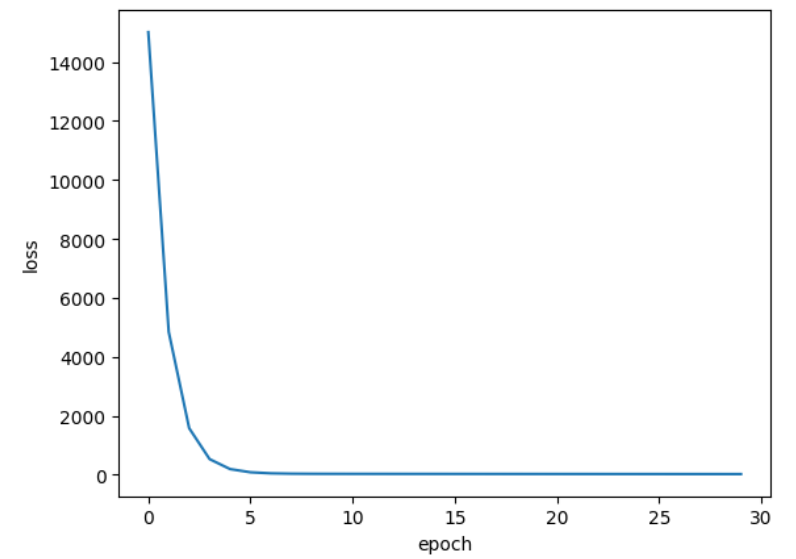
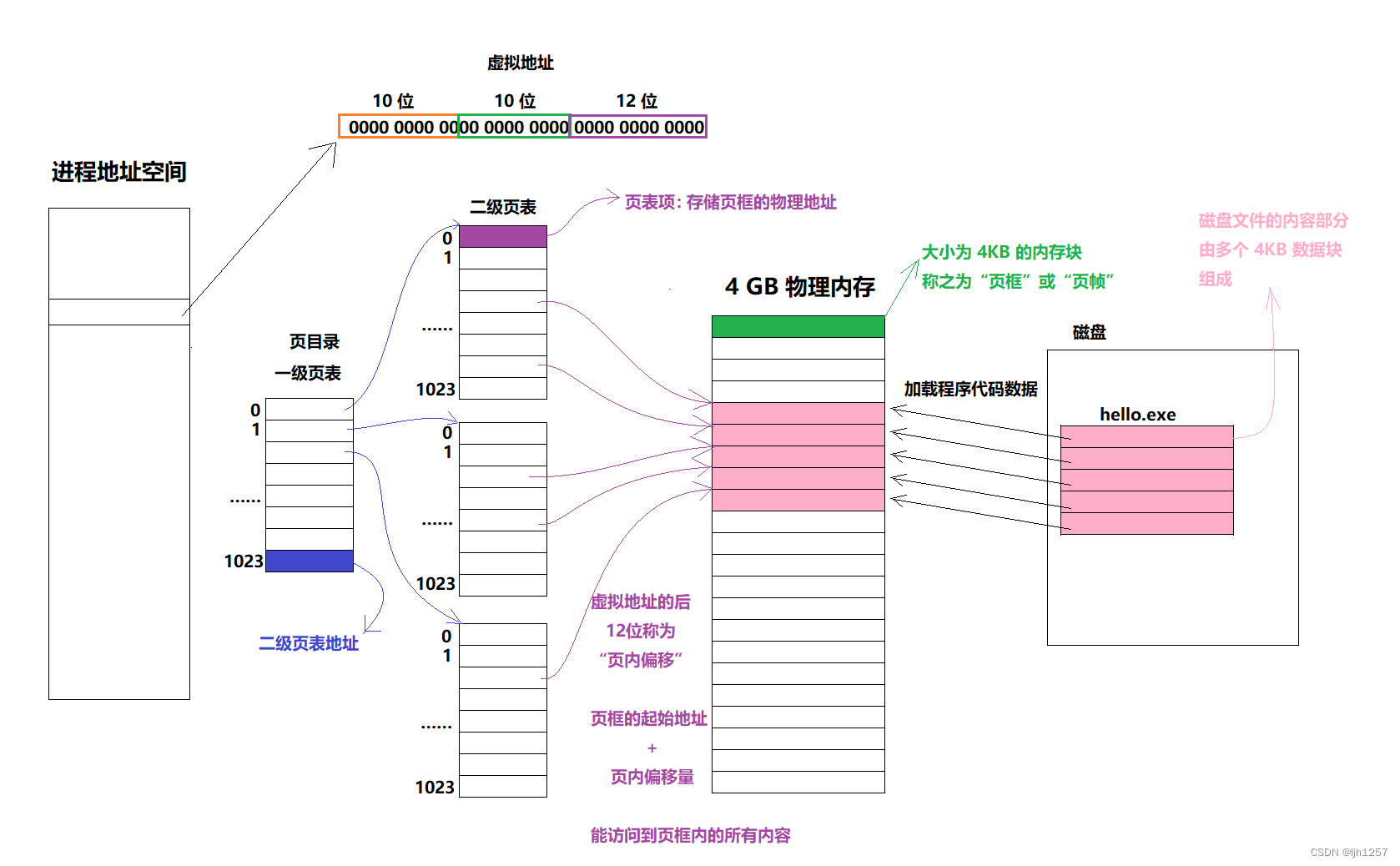
概述
在这篇文章中,我们将深入探讨如何利用Go语言这一强大的工具,结合代理IP技术和多线程技术,实现高效下载Amazon的商品信息。首先,让我们来看看为什么选择Go语言作为开发网络爬虫的首选语言。
Go语言在网络开发中的特点
- 简洁的语法和高效的编译速度: Go语言的语法简洁清晰,易于上手,而且编译速度非常快,这对于网络爬虫这种需要频繁编译和运行的任务来说尤为重要。
- 强大的并发支持: Go语言原生支持轻量级线程goroutine,以及基于通道的并发模型,能够轻松实现高效的并发任务,适合于网络爬虫这种需要同时处理大量请求的场景。
- 标准库丰富: Go语言标准库提供了丰富的网络相关功能,包括HTTP客户端、HTTP服务器等,大大简化了网络开发的复杂度。
- 跨平台支持: Go语言的编译器支持多种操作系统和硬件平台,可以轻松实现跨平台部署,适用于各种环境下的网络爬虫开发。
电商网站的发展趋势
- 个性化推荐和智能搜索: 随着人工智能和大数据技术的发展,电商网站越来越注重用户个性化推荐和智能搜索功能,通过分析用户行为和偏好,为用户提供更精准的商品推荐和搜索结果。
- 移动端的普及: 随着智能手机的普及,越来越多的用户选择在移动端进行网上购物,因此电商网站需要优化移动端用户体验,提供响应式设计和便捷的移动购物功能。
- 跨境电商的发展: 随着全球化进程的加速,跨境电商越来越受到重视,电商网站需要拓展海外市场,提供多语言、多货币、多种支付方式等功能,以满足不同国家和地区用户的需求。
- 社交电商的兴起: 社交电商模式逐渐兴起,通过社交媒体平台和社交化的购物体验,吸引用户进行购物分享和社交互动,增强用户粘性和购买欲望。
细节
步骤一:设置代理IP
为了避免被目标网站封锁IP,我们会使用爬虫代理服务。首先,需要在代码中配置代理服务器的域名、端口、用户名和密码。
步骤二:编写Go语言爬虫代码
接下来,我们将编写Go语言的爬虫代码。代码中将包含如何发送HTTP请求、处理响应以及解析HTML文档来提取所需的商品信息。
步骤三:实现多线程采集
最后,为了提高采集效率,我们将利用Go语言的goroutine来实现多线程采集。这将允许我们同时处理多个下载任务。
以下是Go语言的代码示例:
package main
import (
"fmt"
"net/http"
"net/url"
"sync"
)
// 亿牛云爬虫代理的配置信息
const (
proxyURL = "代理服务器地址" // 代理服务器地址www.16yun.cn
proxyPort = "代理服务器端口" // 代理服务器端口
username = "用户名" // 用户名
password = "密码" // 密码
)
// 商品信息结构体
type ProductInfo struct {
URL string
Category string
// 其他商品信息字段...
}
// downloadProductInfo 使用代理IP下载Amazon商品信息
func downloadProductInfo(productURL string, category string, ua string, cookie string, wg *sync.WaitGroup, ch chan<- ProductInfo) {
defer wg.Done()
// 配置代理IP
proxy := func(_ *http.Request) (*url.URL, error) {
return url.Parse(fmt.Sprintf("http://%s:%s@%s:%s", username, password, proxyURL, proxyPort))
}
transport := &http.Transport{Proxy: proxy}
client := &http.Client{Transport: transport}
// 创建请求
req, err := http.NewRequest("GET", productURL, nil)
if err != nil {
fmt.Println("创建请求失败:", err)
return
}
// 设置用户代理和Cookie
req.Header.Set("User-Agent", ua)
req.Header.Set("Cookie", cookie)
// 发送请求
resp, err := client.Do(req)
if err != nil {
fmt.Println("请求Amazon商品信息失败:", err)
return
}
defer resp.Body.Close()
// 处理响应...
// 解析HTML文档...
// 模拟商品信息解析后的结果
productInfo := ProductInfo{
URL: productURL,
Category: category,
// 其他商品信息字段...
}
// 将商品信息发送到通道
ch <- productInfo
}
func main() {
var wg sync.WaitGroup
// 商品URL列表和对应的分类
productURLs := map[string]string{
"Amazon商品页面URL1": "电子产品",
"Amazon商品页面URL2": "服装",
// 更多商品页面...
}
// 创建通道用于接收商品信息
productInfoCh := make(chan ProductInfo)
// 用户代理和Cookie
userAgent := "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"
cookie := "your_cookie_here"
// 使用多线程技术提高采集效率
for url, category := range productURLs {
wg.Add(1)
go downloadProductInfo(url, category, userAgent, cookie, &wg, productInfoCh)
}
// 启动一个goroutine用于接收商品信息并统计
go func() {
for productInfo := range productInfoCh {
// 统计商品信息,可以根据需要进行进一步处理,比如存储到数据库、输出到文件等
fmt.Printf("商品URL: %s, 分类: %s\n", productInfo.URL, productInfo.Category)
}
}()
wg.Wait()
fmt.Println("所有商品信息采集完毕")
// 关闭通道
close(productInfoCh)
}
请注意,上述代码仅为示例,您需要替换代理服务器地址、端口、用户名和密码为您的爬虫代理服务的实际配置信息。此外,您还需要填写实际的Amazon商品页面URL,并完成响应处理和HTML解析的相关代码。
希望这篇文章和代码示例能帮助您快速入门Go语言爬虫的开发,并有效地下载Amazon商品信息。


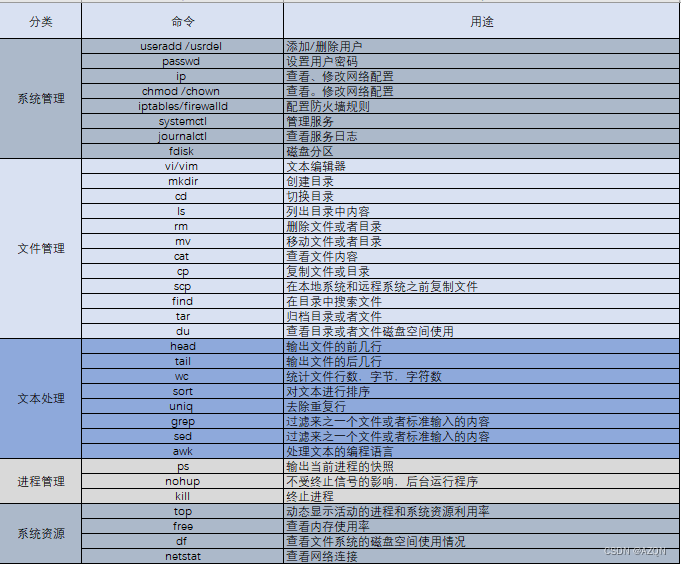







![[QT] 断点调试](https://img-blog.csdnimg.cn/direct/8d8ee75ee48c439c969fe83aba7c174c.png)