文章目录
- 一、什么是C++
- 二、C++的开发环境与相关工具
- 三、C++的编译/链接模型
一、什么是C++
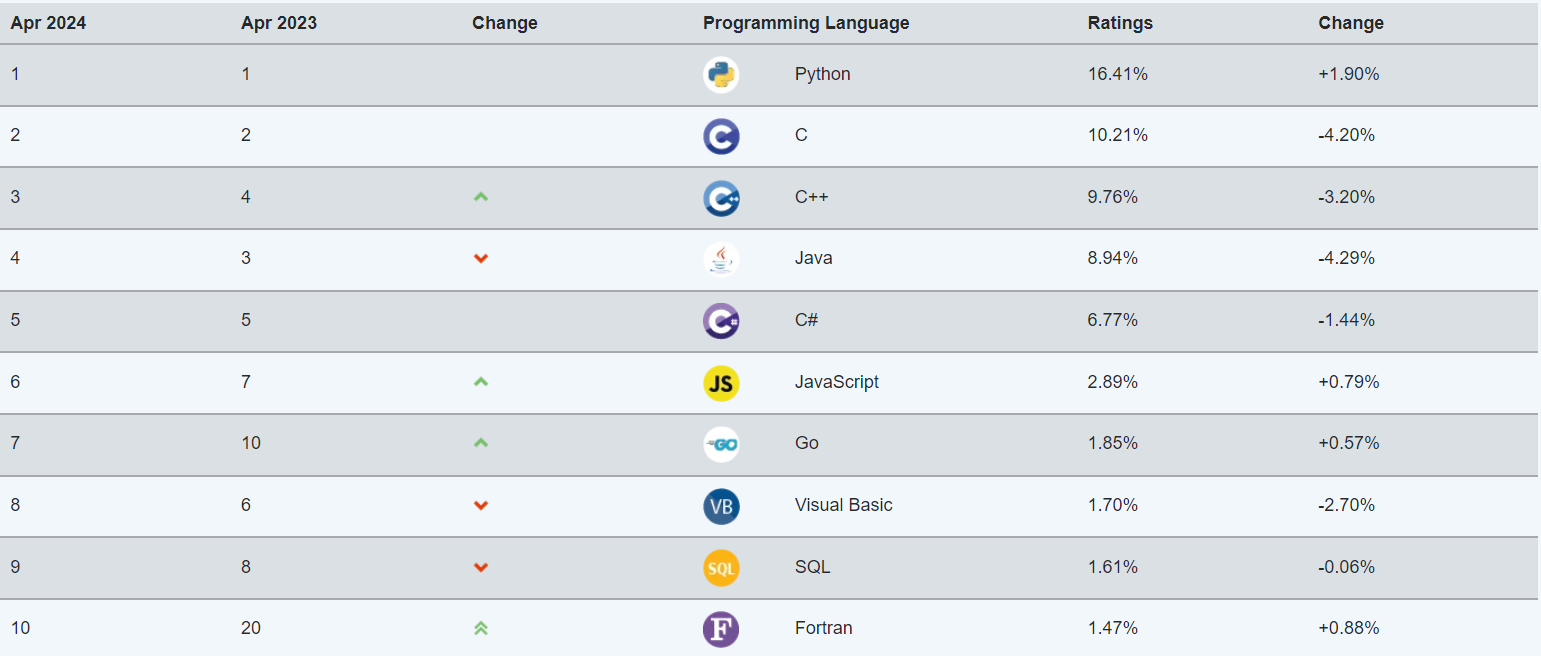
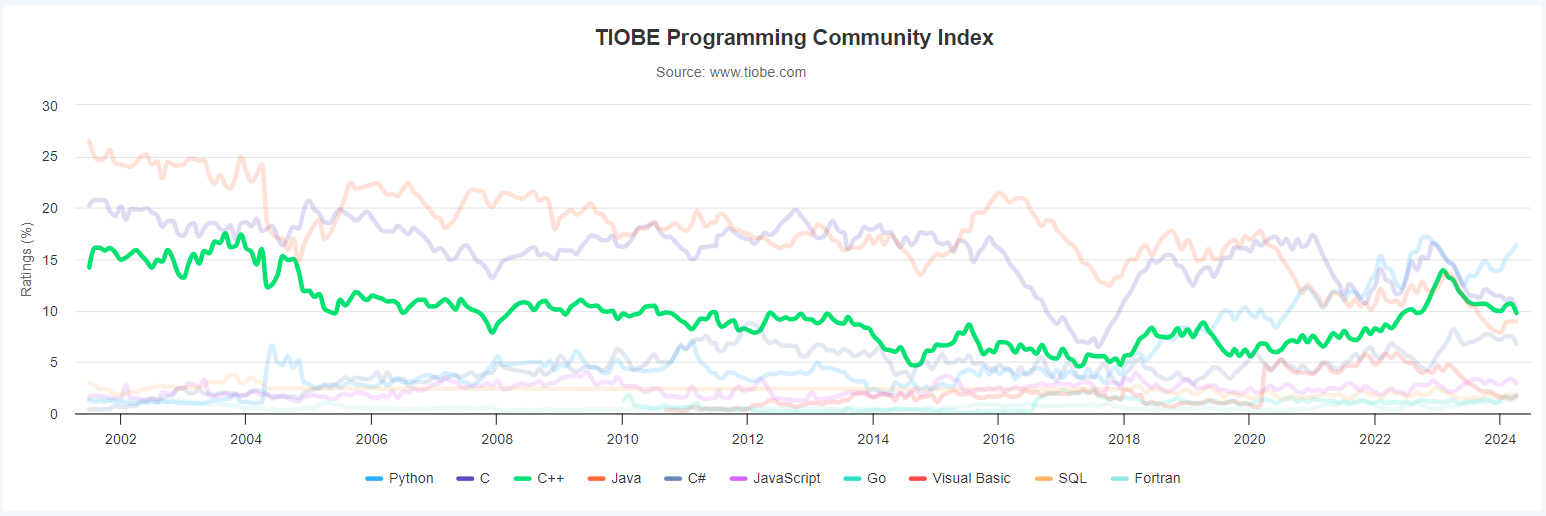
C++是一门比较流行的编程语言(高级语言),同时也是一门复杂的语言。从TIOBE 编程社区指数中可以看出:在2024.04中,其编程语言受欢迎程度指标排名前三。
C++语言是C语言的扩展,其继承了一些C++的特性。
-
关注性能
-
与底层硬件紧密结合
“大端序”与“小端序”是硬件的概念。不同的计算机架构可能采用不同的字节序。例如,x86架构的计算机通常使用小端序,而一些其他架构,如SPARC、PA-RISC、和很多网络协议,则使用大端序。在进行跨平台数据交换时,字节序是一个重要的考虑因素,因为不同的系统可能会以不同的顺序解释字节。为了解决这个问题,经常使用标准化的字节序表示,如网络字节序(大端序),来确保数据的一致性。
字节序有两种主要类型:
-
大端序Big-endian:在大端序系统中,字的高位存储在低字节地址中。这意味着如果你有一个32位的字(或整数),并且它的值是
0x12345678,那么在内存中,它会被存储为:地址 0x00: 0x12 地址 0x01: 0x34 地址 0x02: 0x56 地址 0x03: 0x78大端序是因为它用“大”的字节来表示“高”的位。
-
小端序Little-endian:在小端序系统中,字的高位存储在高字节地址中。这意味着如果你有一个32位的字(或整数),并且它的值是
0x12345678,那么在内存中,它会被存储为:地址 0x00: 0x78 地址 0x01: 0x56 地址 0x02: 0x34 地址 0x03: 0x12小端序是因为它用“小”的字节来表示“高”的位。
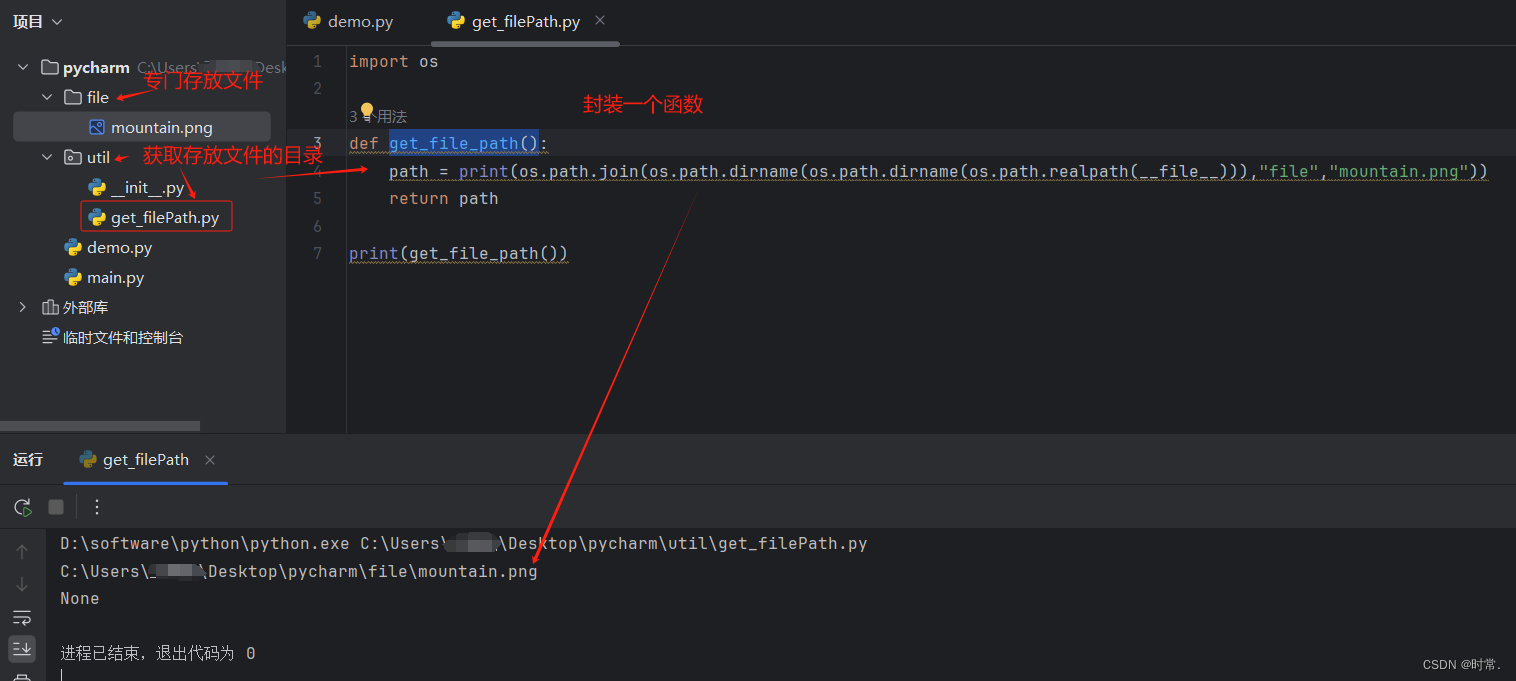
#include <stdio.h> void show_mem_rep(char *start, int n) { int i; for (i = 0; i < n; i++) printf(" %.2x", start[i]); printf("\n"); } int main() { int i = 0x01234567; show_mem_rep((char *)&i, sizeof(i)); }其输出为:(其输出形式即字节序与底层硬件或架构紧密结合)
67 45 23 01 //表明硬件或架构为小端 01 23 45 67 //表明硬件或架构为大端 -
-
对象生命周期的精确控制
举例:比较C#与C++两种高级语言的对象生命周期的精确控制,两种语言使用不同的设计方案,是在易用性与性能之间的取舍。
-
C# 使用垃圾回收机制(线程)来自动管理内存,不用关注对象的销毁过程(易用性,但损耗性能)
-
C++从构造对象开始、使用、销毁,所有的这些操作都是程序员显式控制的
-
-
“Zero-overhead abstraction” —零开销抽象,使用抽象而不会引入额外的性能开销
-
不需要为没有使用的语言特性付出成本
int fun1() { int* x = new int(3); //在堆上开辟内存,需要涉及到间接引用 return *x; } int fun2() { int x = 3; //在栈上开辟内存 return x; }其汇编语言的结果为:
fun1(): push rbp mov rbp, rsp sub rsp, 16 mov edi, 4 call operator new(unsigned long) mov DWORD PTR [rax], 3 mov QWORD PTR [rbp-8], rax mov rax, QWORD PTR [rbp-8] mov eax, DWORD PTR [rax] leave ret fun2(): push rbp mov rbp, rsp mov DWORD PTR [rbp-4], 3 mov eax, DWORD PTR [rbp-4] pop rbp ret总结来讲:如果不需要使用堆这个概念,就不需要付出额外的成本
-
使用一些语言特性不等于付出运行期成本(可能会被编译器所优化掉,进一步提升程序的性能)
consteval auto fun(unsigned input) { unsigned res = 0; for (unsigned i = 0; i < input; ++i) { res += i; } return res; } int main() { return fun(3); }其汇编语言结果为
main: push rbp mov rbp, rsp mov eax, 3 pop rbp retconsteval关键字是C++20的特性,表明函数只能在编译期运行,换句话说,在编译器中会执行函数逻辑,计算fun(3)的函数返回值。增加了编译期的负担,但编译期一般执行一次,换来运行期不会执行函数代码而直接获得结果。
-
-
-
引入大量特性,便于工程实践
- 三种编程范式:面向过程、面向对象、泛型编程与元编程
- 函数重载、异常处理、引用
C++是一系列不断衍进的标准集合,从C++98/03,C++11,C++14,C++17,C++20等不断衍进。涉及到
-
语言本身的改进
- Memory Model(内存模型)
- Lambda Expression(Lambda表达式)
-
标准库的改进
-
type_traits(泛型编程)、ranges(元编程) -
auto_ptr(智能指针)auto_ptr有一些限制和问题,例如它不满足某些标准容器和算法的要求,因为它的复制行为与其他标准容器和算法的预期行为不一致。此外,它也不支持多线程环境。在 C++11 中,auto_ptr被新的智能指针类std::unique_ptr所取代。std::unique_ptr提供了更好的异常安全性和更直观的所有权模型。std::unique_ptr同样用于自动管理动态分配的内存,但它不会导致自动转移所有权,而是提供了std::move操作来显式转移所有权。推荐使用std::unique_ptr或std::shared_ptr来管理动态内存,而不是使用auto_ptr。
-
C++标准的工业界实现,常见的编译器有MSVC/GCC/Clang…
-
每个编译器可能并不完全遵照标准
-
不同的实现存在差异
使用C++开发程序,一定要关注程序的性能,这是C++语言的优势。同时,也要关注C++的标准。比如:在C++98标准时,在标准层面并没有规定如何开发多线程的程序,此时,就不得不使用Windows的多线程库与Linux的多线程库来开发多线程程序,造成程序的移植问题(在Windows上开发的程序不能在Linux上编译与运行)。在C++11之后引入了多线程开发库,这个库纳入了C++11标准中去,我们就应该使用这些库进行开发,使用标准是在避免移植问题。尽量避免使用平台特定的相关工具语言来进行开发。
二、C++的开发环境与相关工具
-
编译环境
Visual C++ / GCC(G++)/ Clang(Clang++)…
-
集成开发环境
Visual Studio 、 CodeLite、Code::blocks、Eclipse、Qt
-
工具(主要是Linux上的)
-
/usr/bin/time用于测量程序执行时间的命令行工具。它可以用于获取程序运行时的资源使用情况,包括 CPU 时间、实际经过的时间、内存使用量等。这个工具对于性能分析和基准测试非常有用,因为它提供了关于程序执行效率的重要信息。常用的
/usr/bin/time选项:-p:打印所有可用的资源使用信息。-v:显示详细的资源使用信息。-o <file>:将资源使用信息输出到指定的文件中。-f <format>:指定输出的格式。
基本的使用方法如下:
/usr/bin/time [options] command例如,要测量运行某个程序
program的资源使用情况,可以使用:/usr/bin/time -p program这将输出程序的 CPU 时间(用户 CPU 时间和系统 CPU 时间)、实际经过的时间、平均内存使用量、最大内存使用量等信息。
如果你想要将这些信息保存到文件中,可以使用
-o选项:/usr/bin/time -o time_output.txt program这将把资源使用信息保存到
time_output.txt文件中。 -
valgrindValgrind 是一个开源的程序分析工具,它主要用于内存调试、内存泄漏检测、性能分析以及检测程序中其他的一些常见错误。Valgrind 通过模拟硬件来运行程序,这使得它能够在不修改程序的情况下检测到许多问题。
以下是 Valgrind 的一些主要工具和用途:
- Memcheck:这是 Valgrind 最常用的工具之一,用于检测内存泄漏和内存越界等错误。
- Cachegrind 和 Callgrind:这两个工具用于性能分析,它们可以帮助开发者了解程序的缓存使用情况和函数调用情况。
- Helgrind:用于检测多线程程序中的竞态条件和锁的使用问题。
- Massif:一个堆分析工具,用于检测程序的堆内存使用情况。
- Drmgrind:用于检测程序中的 DRM(数字版权管理)相关的问题。
- BBV:一个简单的二进制代码查看器。
- VGDB:允许开发者使用 GDB 调试器来调试正在 Valgrind 运行的程序。
- Exp-ptrcheck:一个实验性的指针检查工具。
使用 Valgrind 的基本命令格式如下:
valgrind [options] program [program_arguments]例如,使用 Memcheck 工具检测程序中的内存问题:
valgrind --leak-check=yes --show-leak-kinds=all --track-origins=yes program这个命令会启动 Memcheck 工具,检查所有类型的内存泄漏,并显示泄漏内存的来源。
在使用 Valgrind 之前,确保你的程序是编译时带有调试信息的,通常是使用
-g选项进行编译,这样 Valgrind 才能提供更详细的信息。同时,Valgrind 与优化过的代码配合使用时可能无法准确检测到所有问题,因此在调试时可能需要关闭或减少编译器的优化级别。 -
Cpp Reference–C++百科全书
C++ Reference 的网址是:https://en.cppreference.com/,它是 C++ 程序员日常开发中的重要参考资源之一。它提供了关于 C++ 标准库、关键字、运算符、概念(C++20引入)、类和函数等的详细信息。当程序员需要查找特定函数的用法、类成员的详细信息或者语言特性的时候是非常有用的。
C++ Reference 的网站内容通常包括:
- C++ 标准库:包括了所有标准库的容器、迭代器、算法、输入/输出库等的详细文档。
- 语言特性:涵盖了 C++ 的所有关键字、特殊成员函数、类型转换、模板等。
- C++11/14/17/20 新特性:对于每个新标准,C++ Reference 都提供了新特性的详细解释和用法示例。
- 示例代码:很多页面都包含示例代码,帮助读者更好地理解如何使用特定的语言特性或库功能。
- 兼容性信息:指出了不同 C++ 标准和编译器对特定特性的支持情况。
- 语法:提供了 C++ 语法的详细描述,包括表达式、语句和声明等。
- 概念(Concepts):C++20 引入的新特性,用于模板编程中对类型进行约束。
- 工具和技巧:提供了一些编程技巧和最佳实践。
- 搜索功能:允许用户快速搜索 C++ 特性和库组件。
-
Compiler explorer–在线编译器和代码分析工具
Compiler Explorer 是一个功能强大的在线编译器和代码分析工具,它允许开发者查看不同编译器的编译结果,包括汇编语言输出。它通过可视化的方式展示了代码编译的细节,有助于提升编程技能和理解底层硬件的工作原理。
使用 Compiler Explorer 的基本步骤通常包括:
- 打开 Compiler Explorer 网站(如 https://godbolt.org/)。
- 在左侧的编辑器中编写或粘贴代码。
- 选择适当的语言和编译器版本。
- 根据需要调整编译选项。
- 查看右侧的汇编输出或执行结果。
Compiler Explorer 的一些主要特点:
- 多语言支持:支持 C++、Rust、Go、Java 等多种编程语言的编译。
- 编译器版本:提供了不同编译器及其版本的选择,包括 GCC、Clang、MSVC 等。
- 汇编代码查看:可以查看源代码对应的汇编指令,有助于理解编译器如何将高级语言翻译成机器可以执行的指令。
- 性能分析:支持使用 LLVM-mca 工具进行静态性能分析。
- 代码分享:可以生成分享链接,让他人查看你的编译结果和汇编代码。
- 插件和集成:存在如 VSCode 插件等第三方工具集成 Compiler Explorer 的功能,提高开发效率。
- 开源项目:Compiler Explorer 是一个开源项目,可以在 GitHub 上找到其源代码和贡献指南。
- 实时编译:提供实时的、交互式的编译体验,可以即时看到更改代码后的影响。
- 编译选项:允许用户尝试不同的编译器选项,观察对源代码编译结果的影响。
- 多文件编译:支持 CMake 等工具进行多文件项目的编译
-
C++ insights
要使用 C++ Insights,你可以直接访问它的网站(例如 https://cppinsights.io/)并在提供的编辑器中输入 C++ 代码,或者在安装了相应扩展的 VSCode 中使用它。
C++ Insights 是一个基于 Clang 的工具,旨在帮助开发者更深入地理解 C++ 代码在编译时的内部工作机制。它通过展示编译器看到的 C++ 源码细节,揭示了模板、自动类型推导(
auto)、decltype等语言特性背后的实现。C++ Insights 可以作为一个网页工具使用,也可以集成到 Visual Studio Code(VSCode)中作为一个扩展。C++ Insights 的一些关键特性:
- 源码到源码的转换:C++ Insights 可以将 C++ 代码的复杂特性转换成等价的、更易理解的 C++ 代码形式。
- 编译器内部视角:它提供了一个窗口,让开发者能够看到编译器是如何解释 C++ 代码的。
- 模板推导:C++ Insights 可以展示模板参数推导的结果,帮助开发者理解模板元编程。
- 自动类型推导:对于
auto关键字,C++ Insights 可以展示编译器推导出的具体类型。 - 声明和定义的展开:它能够展示由编译器生成的隐式声明和定义,例如,从
decltype表达式中生成的类型声明。 - Visual Studio Code 扩展:C++ Insights 提供了一个 VSCode 扩展,允许在编辑器内部直接查看编译器的视角。
- 代码差异:C++ Insights 允许你比较原始源码和转换后的代码,从而更清楚地理解编译器做了哪些更改。
- 开源项目:C++ Insights 是一个开源项目,其代码库托管在 GitHub 上,社区成员可以查看源码、报告问题或贡献代码
-
三、C++的编译/链接模型
最初,用到的是简单的加工模型
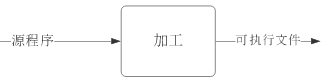
简单加工模型的问题:无法处理大型程序
- 加工耗时较长
- 即使少量修改,也需要全部重新加工
为了解决上述问题,提出解决方案:C++的编译/链接模型(分块处理)
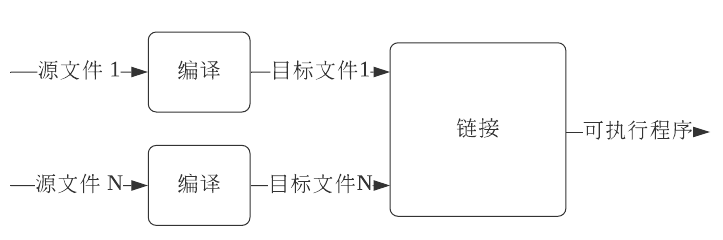
分块处理的优点:
-
编译耗资源但一次处理输入较少,可以很快完成编译
-
链接输入较多(N个目标文件)但处理速度较快
-
便于程序修改升级
由“分块处理”衍生出的概念
-
定义 / 声明
-
头文件 / 源文件
-
翻译单元(编译时预处理阶段会将源程序变成翻译单元)
源文件 + 相关头文件(直接/间接) - 应忽略的预处理语句
-
一处定义原则
- 程序级别:一般函数遵循一处定义原则
- 翻译单元级别:内联函数、类、函数模板遵循一处定义原则
C++的编译/链接模型对于源程序是如何操作的?

-
预处理
-
将源文件转换为翻译单元的过程,会将源文件中的头文件进行展开
-
防止头文件被循环展开
在C或C++编程中,头文件的循环展开(也称为循环包含)是一个常见的问题,它发生在一个头文件被另一个头文件多次包含时。这可能导致编译错误,因为代码被重复定义。为了解决这个问题,有两种常用的方法:
#ifdef解决方案和#pragma once解决方案-
#ifdef 解决方案
这是一种传统的防止头文件循环展开的方法。它依赖于宏定义来检查头文件是否已经被包含过。
基本的步骤如下:
- 在头文件的开始处,定义一个唯一的宏,通常是头文件名的全大写形式。
- 检查这个宏是否已经定义。如果没有定义,定义它,并包含头文件的内容。
- 在头文件的末尾,取消定义这个宏。
// example.h #ifndef EXAMPLE_H #define EXAMPLE_H // 头文件内容 #endif // EXAMPLE_H -
#pragma once 解决方案(新的C++标准)
#pragma once是一种更现代的、更简洁的方法,它告诉编译器这个头文件应该只被包含一次。它被大多数现代编译器支持,并且不需要像#ifdef那样做宏的检查和取消定义。// example.h #pragma once // 头文件内容
比较:
- 简洁性:
#pragma once更简洁,不需要像#ifdef那样编写额外的代码。 - 兼容性:虽然
#pragma once被广泛支持,但不是所有的编译器都支持它。#ifdef是一种更通用的方法,几乎所有的编译器都支持。 - 可读性:使用
#ifdef可以更清楚地看到头文件的保护机制,而#pragma once则简洁到几乎不可见。
在实际开发中,可以根据项目的需求和编译器的支持情况来选择使用哪种方法。如果项目需要高度的可移植性,或者使用旧的编译器,可能会倾向于使用
#ifdef。如果追求代码的简洁性,并且使用的是支持#pragma once的现代编译器,那么#pragma once是一个很好的选择。 -
-
-
编译
-
将翻译单元转换为相应的汇编语言表示
-
可能涉及到编译优化。编译优化的好处:提升执行速度,但不利于调试;反之,利于调试,但执行速度变慢。开发过程中会使用到Debug编译(引入优化较少),开发结束后会使用release编译(引入优化较多)重新进行编译。
举例:
int main() { int res = 0; for (int i = 0; i < 1000; ++i) { res += i; } return res; }O0编译后结果为:main: push rbp mov rbp, rsp mov DWORD PTR [rbp-4], 0 mov DWORD PTR [rbp-8], 0 .L3: cmp DWORD PTR [rbp-8], 999 jg .L2 mov eax, DWORD PTR [rbp-8] add DWORD PTR [rbp-4], eax add DWORD PTR [rbp-8], 1 jmp .L3 .L2: mov eax, DWORD PTR [rbp-4] pop rbp retO1编译优化结果为:main: mov eax, 1000 .L2: sub eax, 1 jne .L2 mov eax, 499500 retO2编译优化结果为:main: mov eax, 499500 ret -
增量编译与全量编译
-
全量编译
全量编译,也称为完整编译,是指每次构建项目时,无论源代码文件是否发生变化,都重新编译所有源代码文件的过程。这种编译方式适用于:
- 小型项目:当项目较小,源文件数量不多时,全量编译的开销相对较小。
- 初始开发阶段:在项目开发的早期阶段,频繁的全量编译有助于发现潜在的问题。
- 确保一致性:全量编译可以确保生成的可执行文件是完全一致的,没有遗漏任何源文件的更改。
然而,全量编译的缺点是:
- 时间消耗:对于大型项目,全量编译可能需要较长的时间,因为编译器需要处理大量的源文件。
- 资源消耗:全量编译会占用更多的CPU和内存资源
-
增量编译
增量编译是一种更高效的编译策略,它只重新编译自上次编译以来已经更改过的源文件,以及依赖于这些更改的文件。增量编译适用于:
- 大型项目:在大型项目中,增量编译可以显著减少编译时间。
- 频繁的构建:当开发过程中需要频繁构建时,增量编译可以提高开发效率。
- 持续集成(CI):在持续集成环境中,增量编译可以快速地提供反馈。
增量编译的优点包括:
- 节省时间:只编译更改的部分,从而缩短构建时间。
- 资源优化:减少对系统资源的需求。
但是,增量编译也有其局限性:
- 复杂性:需要编译器支持增量编译功能,并且可能需要额外的配置。
- 依赖关系:如果项目的依赖关系复杂,增量编译可能需要更多的时间来确定哪些文件需要重新编译。
- 潜在问题:有时候,一些间接依赖 或全局状态的改变可能不会被增量编译检测到,导致构建的可执行文件不是最新的。
-
-
-
汇编
汇编阶段是将编译器生成的中间代码(通常是汇编语言)转换成可执行机器代码的过程。
-
链接
- 合并多个目标文件,关联声明与定义
- 连接( Linkage )种类:内部连接、外部连接、无连接
- 链接常见错误:找不到定义
注意:
C++ 源程序转换成可执行文件是相对复杂的过程,主要包含预处理、编译、链接等阶段,每一阶段都可能引入错误。
- C++ 的编译 / 链接过程是复杂的,预处理、编译与链接都可能出错
- 编译可能产生警告、错误,都要重视






![[数据集][目标检测]电力场景安全帽检测数据集VOC+YOLO格式295张2类别](https://img-blog.csdnimg.cn/direct/1244eacb37c9405cb0bd3a3dc4baa332.png)