文章目录
- 一、selenium的使用
- selenium的安装
- 二、元素
- 1. 定位选择元素
- 1.id 定位
- 2. class_name 定位
- find_element 和 find_elements`的区别
- 3. TAG_NAME 定位
- 4. 超链接 定位
- 2. 操控元素
- 1. 查询内容
- 2. 获取元素文本内容
- 3. 获取元素属性
- 3. 浏览器常用操作API
- 4. 鼠标操作 - perform
- 5. 键盘操作 - keys
- 6. 元素等待
- 1. 隐式等待
- 2. 显示等待
- 7. 滚动条
- 8. iframe 切换
- 9. 不同窗口切换
- 10. 截屏
- 11. 验证码
- cookie
- 12. 选择框
- 1. radio 单选框
- 2. checkbox 复选框
- 3. select 下拉框
- 8.冻结界面(小技巧)
- 9. 弹出框
- 1. Alert 弹出框
- 2. Confirm 确认框
- 3. Prompt 输入框
- 4. 文件上传
- 封装相对路径
- 三、选择器
- 1. Css选择器
- 2. Xpath选择器
- 1.绝对路径选择
- 2.相对路径选择
- 1.通配符
- 2.根据属性选择
- 3. 按次序选择
- 4. 范围选择
- 5.多组节点选择
- 6. 选择父节点
- 7. 兄弟节点选择
- xpath 小坑
- selenium的案例练习
- 四、YAML文件 - - 实现接口自动化
- 1.数据组成
- 1.Map对象,键值对
- 2.数组(list)
- 2. 使用yaml
一、selenium的使用
基于 python 中使用。
通过pip包管理工具进行操作,pip是python中包管理工具(可以安装,卸载、查看python工具)
pip list:查看通过pip包管理工具安装的插件或工具
提示:
1.使用pip必须联网.
2.默认安装python3.5版本以上工具,自带pip包管理工具,默认会自动安装并且添加path环境变量
selenium的安装
(1).通过pip包管理工具 / pycharm去安装
安装: pip install selenium
安装指定版本pip install selenium==版本号 如: pip install selenium==2.48.0
查看: pip show selenium
卸载: pip uninstall selenium
(2).下载驱动器来辅助selenium
驱动安装,根据自己浏览器的版本来下载对应的驱动器(一定要对应版本的驱动器,如果不是,那么就会出现问题)
chrome驱动地址:https://getwebdriver.com/chromedriver
Firefox:https://github.com/mozilla/geckodriver/releases/
Edge: Microsoft Edge WebDriver - Microsoft Edge Developer
把下载的浏览器驱动器放在python解释器所在的文件夹,这样在后续编写Python代码时会方便特别多,可以cmd命令行输入:py -0p(会显示出python解释器所在文件夹)
Web 自动化测试原理:
1.怎么样控制浏览器(启动、关闭、刷新、跳转浏览器)
2.怎么样使用网页功能(输入、点击、拖动、选择)
3.从网页获取各项数据(标题、网址、数字、字符串)
搭建Web自动化测试环境:
pip install webdriver_helper
安装后的示例:
# 导包
from webdriver_helper import get_webdriver
driver = get_webdriver('chrome') # 启动浏览器
driver.get('https://www.baidu.com') # 页面的跳转
input('是否关闭浏览器')
driver.quit() # 关闭浏览器
二、元素
1. 定位选择元素
为什么要使用元素定位?
要使用web自动化操作元素,必须首先找到此元素。
定位元素时依赖于什么?
1.标签名 2.属性 3.层级 4.路径
八大定位方式
id- name
- class_name (使用元素的clas3属性定位)
- tag_name (标签名称<标签名…/>)
- link_text (定位超连接a标签)
- partial_link_text (定位超链接a标签模糊)
xpath(基于元素路径)- css (元素选择器)
汇总:
1.基于元素属性特有定位方式(id\name\class name)
2.基于元素标签名称定位:tag_name
3.定位超链接文本(link_text、 partial_link text)
4.基于元素路径定位(xpath)
5.基于选择器(css)
1.id 定位
通过元素的id属性定位,id一般情况下在当前页面是唯一。
方法:driver.find_element(By.ID,'id值')
# 导包
from selenium.webdriver.common.by import By
from webdriver_helper import get_webdriver
driver = get_webdriver('edge') # 启动浏览器
driver.get('https://www.baidu.com') # 页面的跳转
# 根据id选择元素,返回的就是该元素对应的WebElement对象
el = driver.find_element(By.ID,'kw') # 获取百度输入框id
# 通过该WebElement对象,就可以对页面元素进行操作了
el.send_keys('风景照片\n') # 输入字符串到这个输入框里
el.send_keys('风景照片')
el = el.find_element(By.ID,'su')
el.click() # 点击
input('是否关闭浏览器')
driver.quit() # 关闭浏览器
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Edge()
driver.maximize_window()
driver.get('http://www.baidu.com')
driver.find_element(By.ID,'kw').send_keys('selenium')
driver.find_element(By.ID,'su').click()
sleep(3)
driver.quit()
2. class_name 定位
方法:driver.find_element(By.CLASS_NAME,'id值') – 单个元素
driver.find_elements(By.CLASS_NAME,'id值') – 多个元素
find_element 和 find_elements`的区别
find_element 和 find_elements 的区别 :
使用find elements:选择的是符合条紧的所有元素,如果没有符合条件的元素,返回空列表。
使用find element:选择的是符合条件的第一个元素,如果没有符合条件的元素,抛出异常。
driver.get('http://www.xxx') # 页面的跳转
el = driver.find_elements(By.CLASS_NAME,'animal')
for item in el:
print(item.text) # 打印文本内容
3. TAG_NAME 定位
方法:el = driver.find_elements(By.CLASS_NAME,'container')
WebDriver 对象选择元素的范围是
整个web页面
WebElement 对象选择元素的范围是该元素的内部。
el = driver.find_elements(By.CLASS_NAME,'container')
# 限制:选择元素范围是 id 为 container 元素内部的元素
spans = el.find_elements(By.TAG_NAME,'span')
for item in spans:
print(item.text)
4. 超链接 定位
link_text 和 partial_link_text 只会定位可点击的超链接标签。
# 必须找到为 “新闻” 两个字
driver.find_element(By.LINK_TEXT,'新闻').click()
# 只要包含 “新闻” 两个字即可
driver.find_element(By.PARTIAL_LINK_TEXT,'新闻').click()
2. 操控元素
1). send_keys()_ 输入方法
2). click() 点击方法
3). clear() 清空
提示: 在输入方法之前一定要清空操作。
1. 查询内容
element.send_keys('xxx')
from selenium.webdriver.common.by import By
from webdriver_helper import get_webdriver
driver = get_webdriver('edge') # 启动浏览器
driver.implicitly_wait(10)
driver.get('https://www.baidu.com')
el = driver.find_element(By.ID,'kw')
el.send_keys('柯基\n')
el.clear() # 清除上一次输入框的内容
el = driver.find_element(By.ID,'kw')
el.send_keys('柴犬\n')
input('是否关闭浏览器')
driver.quit() # 关闭浏览器
2. 获取元素文本内容
element.text
el = driver.find_element(By.ID,'animal')
print(el.text)
3. 获取元素属性
获取元素属性值:element.get_attribute('class')
获取整个元素对应的HTML文本内容:element.get_attribute('outHTML')
获取某个元素内部的HTML文本内容:element.get_attribute('innerHTML')
获取输入框里面的文字:element.get_attribute('value')
3. 浏览器常用操作API
# 1)最大化浏览器
driver.maximize_window()
# 2)设置浏览器大小单位像素
driver.set_window_size(200,250)
# 3)设置浏览器位置
driver.set_window_position(100,120)
# 4)后退操作
driver.back()
# 5)前进操作
driver.forward()
# 6)刷新操作
driver.refresh()
# 7)关闭当前主窗口(主窗口:默认启动哪个界面,就是主窗口)
driver.close()
# 8)关闭由driver对象启动的所有窗口
driver.quit()
# 9)获取当前页面title信息
driver.title
# 10)获取当前页面url信息
driver.current_url
提示:
1.driver.title和driver.current_url没有括号,应用场景:一般为判断上步操作是否执行成功。
2.driver.maximize_window() 一 般为我的前置代码,在获取driver后,直接编写最大化浏览器
3.driver.refresh() 应用场景,在后面的cookie章节会使用到。
4. driver.close() 与driver.quit()区别:
close() :关闭当前主窗口
quit() :关闭由driver对象启动的所有窗口
提示: 如果当前只有1个窗口,close与quit没有 任何区别。
4. 鼠标操作 - perform
鼠标事件被封装在 ActionChains类中,需要导包
一定要加 perform 执行事件
提示: selenium框架中虽然提供了,右击鼠标方法,但是没有提供选择右击菜单方法,可以通过发送快捷键的方式解决(经测试,谷歌浏览器不支持)。
from selenium.webdriver import ActionChains
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Edge()
driver.get("http://sellshop.5istudy.online/sell/user/login_page")
# 实例化并获取 AActionChains
action = ActionChains(driver)
# 定位在username元素上,点击右键
action.context_click(driver.find_element(By.ID,'username')).perform()
# 双击
action.double_click(driver.find_element(By.ID,'username')).perform()
# 悬停
action.move_to_element(driver.find_element(By.ID,'username')).perform()
# 拖拽
source = driver.find_element(By.ID,'box1')
target = driver.find_element(By.ID,'box2')
action.drag_and_drop(source,target).perform()
# 通过坐标偏移量执行
action.drag_and_drop_by_offset(source,xoffset=200,yoffset=300).perform()
5. 键盘操作 - keys
键盘对应的方法在Keys类中,需要导包
常用的快捷键: CONTROL: Ctrl键
其他,请参考Keys底层定义的常量
from selenium.webdriver import Keys
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Edge()
driver.get("http://sellshop.5istudy.online/sell/user/login_page")
# 1.输入用户名admin1
username = driver.find_element(By.ID,'username')
username.send_keys('admin1')
# 2.删除1
username.send_keys(Keys.BACK_SPACE)
# 3.全选用户名"admin" Ctrl+a
username.send_keys(Keys.CONTROL,'a')
# 4.复制admin Ctrl+c
username.send_keys(Keys.CONTROL,'c')
# 5.粘贴将复制的admin粘贴到密码框 Ctrl+v
driver.find_element(By.ID,'password').send_keys(Keys.CONTROL,'v')
6. 元素等待
由于电脑配置或网络原因,在查找元素时,元素代码未在第一时间内 被加载出来,而抛出未找到元素异常。
什么是元素等待?
元素在第一次未找到时,元素等待设置的时长被激活,如果在设置的有效时长内找到元素,继续执行代码,如果超出设置的时长未找到元素,抛出未找到元素异常。
1. 隐式等待
针对所有元素生效。
一般情况 下为前置必写代码(1.获取浏览器驱动对象: 2.最大化浏览器: 3. 设置隐式等待)
隐式等待:driver.implicitly_wait(等待时长,s为单位)
后续所有的 find_element 或者find_elements 之类的方法调用都会采用上面的策略:
如果找不到元素,每隔半秒钟再去界面上查看一次, 直到找到该元素,或者过了设置秒数的最大时长。
from selenium.webdriver.common.by import By
from webdriver_helper import get_webdriver
driver = get_webdriver('edge') # 启动浏览器
driver.implicitly_wait(10) # 隐式等待,当后续find_elements找不到指定元素,等待10秒动态查找
driver.get('http://www.xxx') # 页面的跳转
el = driver.find_elements(By.ID,'kw')
el.send_keys('风景\n') # 查询请求服务器可能存在很慢的情况,导致下面查询报错
el = driver.find_element(By.ID,'1') # 选择 id=1 的第一个元素
print(el.text)
2. 显示等待
定位指定元素时,如果能定位到元素则直接返回该元素,不触发等待;如果不能定位到该元素,则间隔一段时间后再去定位元素:如果在达到最大时长时还没有找到指定元素,则抛出超
时异常TimeoutException 。
在Selenium中把 显式等待的相关方法封装在WebDriverWait类中:
# 参数:
# timeout: 超时时间
# poll_frequency: 访问频率,默认0.5秒找一 次元素
# x: x为driver, 它是WebDriverWait类将传入的driver赋值给类self. driver, unti1方法调用了se1f._driver;
WebDriverWait(driver,timeout=10,poll_frequency=0.5).until(lambda x:x.find_element(By.ID,"username")).send_keys("admin")
7. 滚动条
为什么要操作滚动条?
在web自动化中有些特殊场景,如:滚动条拉倒最底层,指定按钮才可用。
如何操作?
# 第一步:设置操作滚动条操作语句
js = "window. scrollTo(0, 10000)"
# 0:左边距 (水平滚动条)
# 10000:上边距 (垂直滚动条)
# 第二步:调用执行js方法,将设置js语句传入方法中
driver.execute_script(js)
在seleqium中没有直接提供定位滚动条组件方法,但是它提供了执行js语句方法,可以通过js语句来控制滚动条,此语句可以执行任何的js语句方法
8. iframe 切换
这个iframe元素非常的特殊,在html语法中, frame 元素或者iframe元素的内部会包含一个被嵌入的另一份html文档。
在我们使用selenium打开一个网页时,我们的操作范围缺省是当前的html,并不包含被嵌入的html文档里面的内容。
# 切换到frame里面去
driver.switch_to.frame('innerEle') # frame有id和name的情况下
driver.switch_to.frame(driver.find_element(By.CSS_SELECTOR,'[src="xxx.html"]'))# frame没有id和name的情况下
el = driver.find_element(By.CSS_SELECTOR,'.animal') # iframe 里面的animal元素
print(el.get_attribute('outHTML'))
# 退出iframe,切换到上一级
driver.switch_to.parent_frame()
# 切出frame到主界面
driver.switch_to.default_content()
el = driver.find_element(By.CSS_SELECTOR,'.animal') # 当前html中的animal元素
print(el.get_attribute('outHTML'))
9. 不同窗口切换
一般 a 链接点击会打开一个新的窗口
如果我们要到新的窗口里面操作,该怎么做呢?
可以使用Webdriver对象的switch_to属性的window方法: driver.switch_to.window(handle)
其中,参数handle需要传入什么呢?
WebDriver对象有window_handles 属性,这是一个列表对象,里面包括了当前浏览器里面所有的窗口句柄。(所谓句柄,大家可以想象成对应网页窗口的一个ID)
步骤:
1.切换到新窗口:我们依次获取driver.window_handles 里面的所有句柄对象,并且调用driver.switch_to.window(handle) 方法,切入到每个窗口,然后检查里面该窗口对象的属性(可以是标题栏,地址栏),判断是不是我们要操作的那个窗口,如果是,就跳出循环。
2.回到原来的窗口:我们可以仍然使用上面的方法,依次切入窗口,然后根据标题栏之类的属性值判断。
还有更省事的方法。因为我们一开始就在原来的窗口里面,我们知道进入新窗口操作完后,还要回来,可以事先保存该老窗口的句柄,使用如下方法
# mainWindow变量保存当前窗口的句柄
mainWindow = driver.current_window_handle
切换到新窗口操作完后,就可以直接像下面这样,将driver对应的对象返回到原来的窗口
#通过前面保存的老窗口的句柄,自己切换到老窗口
driver.switch_to.window( mainWindow )
具体使用:
# 点击跳转新窗口打开到新窗口的链接
link = driver.find_element(By.CLASS_NAME,'a').click() #
# 先保存当前窗口的句柄,方便切换
mainWindow = driver.current_window_handle
# 获取所有句柄
handles = driver.window_handles
for handle in handles:
if handle != mainWindow: # 判断是不是我们要操作的那个窗口
driver.switch_to.window(handle) # 先切换到该窗口
print(driver.title) # driver.title属性是当前窗口的标题栏文本
driver.find_element(By.CSS_SELECTOR,'.seacher').send_keys('查找文本内容')
# 切换到主窗口
driver.switch_to.window(mainWindow)
# ...主窗口的一系列操作
10. 截屏
应用场景:失败截图,让错误看的更直观
方法:
driver.get_screenshot_as_file (imgepath)
参数:
imagepath:为图片要保存的目录地址及文件名称
如:当前目录 ./test.png
上一级目录 ../test .png
扩展:
1.多条用例执行失败,会产生多张图片,可以采用时间戳的形式,进去区分。
time.strftime("%Y%m%d %H%M%S")
strftime :将时间转为字符串函数
# 存放当前目录
driver.get_screenshot_as_file("./demo.png")
# 存放指定目录
driver.get_screenshot_as_file("../images/demo.png")
# 动态获取保存截图名称 使用时间戳
driver.get_screenshot_as_file("../images/%s.jpg" %(time.strftime("%Y%m%d %H%M%S")))
11. 验证码
什么是验证码?
一种随机生成信息(文字、 数字、图片)
验证码作用: 防止恶意诸求
验证码处理方式:
1.去掉验证码(项目在测试环境、公司自己的项目)
2.设置万能验证码(测试环境或线上环境,公司自己项目)
3.使用验证码识别技术(由于现在的验证码千奇百怪,导致识别率太低)
4.使用cookie解决(推荐)
cookie
生成:由服务器生成
作用:标识一次对话的状态(登录的状态)
使用:浏览器自动记录cookie,在下一条请求时将cookis信息自动附加请求
方法:
1.driver.get_cookies() 获取所有的cookie
2.driver.add cookies({字典}) 设置cookie
# 1.打开百度url
driver.get('http://www.baidu.com')
# 2.设置cookie信息
# 注意:百度的BDUSS所需格式为百度网站特有,别的网站请自行查看
driver.add_cookie({"name":"BDUSS","value":"xxxxxxxx"})
# 3.暂停2秒以上
sleep(2)
# 4.刷新操作(一定要进行刷新操作!!!)
driver.refresh()
12. 选择框
1. radio 单选框
<div id='allFood'>
<input type='radio' name="food" value="西红柿" />西红柿<br/>
<input type='radio' name="food" value="青椒" />青椒<br/>
<input type='radio' name="food" value="土豆" checked='checked' />土豆<br/>
</div>
实现选中青椒
el = driver.find_element(By.CSS_SELECTOR,'#allFood input[checked="checked"]')
print("当前选中的是:" + el.get_attribute('value')) # 土豆
driver.find_element(By.CSS_SELECTOR,'#allFood input[value="青椒"]').click()
print("现在选中的是:" + el.get_attribute('value')) # 青椒
driver.get('http://iviewui.com/view-ui-plus/component/form/radio')
# 用下标定位元素
driver.find_elements(By.XPATH,'//input[@class="ivu-radio-input" and @type="radio"]')[1].click()
sleep(2)
driver.find_elements(By.XPATH,'//input[@class="ivu-radio-input" and @type="radio"]')[2].click()
sleep(2)
driver.find_elements(By.XPATH,'//input[@class="ivu-radio-input" and @type="radio"]')[3].click()
# 用文本定位元素
driver.find_element(By.XPATH,'//span[text()="Android"]/preceding-sibling::span/input').click()
sleep(2)
2. checkbox 复选框
对checkbox进行选择,也是直接用WebElement的click方法,模拟用户点击选择。
需要注意的是:要选中checkbox的一 个选项,必须先获取当前该复选框的状态, 如果该选项已经勾选了,就不能再
点击。否则反而会取消选择。
<div id='allFood'>
<input type='checkbox' name="food" value="西红柿" />西红柿<br/>
<input type='checkbox' name="food" value="青椒" />青椒<br/>
<input type='checkbox' name="food" value="土豆" checked='checked' />土豆<br/>
</div>
我们的思路可以是这样:
1.先把已经选中的选项全部点击一下 ,确保都是未选状态
2.再点击要选择的选项
els = driver.find_elements(By.CSS_SELECTOR,'#allFood input[checked="checked"]')
for item in els:
item.click() # 确保都没选中
driver.find_element(By.CSS_SELECTOR,'#allFood input[value="青椒"]').click()
driver.find_element(By.CSS_SELECTOR,'#allFood input[value="西红柿"]').click()
3. select 下拉框
- 单选
<select id='allFood'>
<option value="西红柿">西红柿</option>
<option value="青椒">青椒</option>
<option value="土豆" selected='selected'>土豆</option>
</select>
select.select_by_visible_text 使用文本选择:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select # 导入select类
# 创建Select对象
select = Select(driver.find_element(By.ID,'allFood'))
# 选择“青椒”
select.select_by_visible_text("青椒")
# 根据index下标获取,从0开始
select.select_by_index(0)
# 根据option的value进行选择
select.select_by_value("西红柿")
# 根据实际看到的内容进行选择
select.select_by_visible_text("土豆")
- 多选 multiple
对于select多选框,要选中某几个选项,要注意去掉原来已经选中的选项。
可以用select类的deselect_all方法,清除所有已经选中的选项。
然后再通过select _by_visible _text方法 选择要选择的选项。
<select id='allFood' multiple>
<option value="西红柿">西红柿</option>
<option value="青椒">青椒</option>
<option value="土豆" selected='selected'>土豆</option>
</select>
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select # 导入select类
# 创建Select对象
select = Select(driver.find_element(By.ID,'allFood'))
# 清除所有 已经选中 的选项
Select.deselect.all()
# 选择“青椒,西红柿”
select.select_by_visible_text("青椒")
select.select_by_visible_text("西红柿")
- 级联选择
driver.get('http://iviewui.com/view-ui-plus/component/form/cascader')
driver.find_element(By.XPATH,'//input[@class="ivu-input ivu-input-default"]').click()
driver.find_element(By.XPATH,'//li[contains(text(),"北京")]').click()
driver.find_element(By.XPATH,'//li[contains(text(),"故宫")]').click()
- 日期选择器
driver.get('http://iviewui.com/view-ui-plus/component/form/date-picker')
driver.find_element(By.XPATH,'//input[@class="ivu-input ivu-input-default ivu-input-with-suffix"]').send_keys("2024-05-31")
driver.find_elements(By.XPATH,'//input[@class="ivu-input ivu-input-default ivu-input-with-suffix"]')[1].send_keys("2024-05-22 - 2024-06-30")
8.冻结界面(小技巧)
在开发者工具栏console里面执行如下js代码
setTimeout(function(){debugger}, 5000)
这句代码什么意思呢?
表示在5000毫秒后,执行debugger命令
执行该命令会浏览器会进入debug状态。debug状态有个特性 界面被冻住,不管我们怎么点击界面都不会触发事件。
9. 弹出框
alert弹出框、confirm确认框、prompt输入框
注意:有些弹窗并非浏览器的alert窗口而是html元素 这种对话框,只需要通过之前介绍的选择器选中并进行相应的操作就可以了。
1. Alert 弹出框
Alert弹出框,目的就是显示通知信息,只需用户看完信息后,击OK (确定)就可以了。
那么,自动化的时候,代码怎么模拟用户点击OK按钮呢?
selenium提供如下方法进行操作
# alert.text 获取弹框文字
print(driver.switch_to.alert.text)
# 点击 "确定"
driver.switch_to.alert.accept()
2. Confirm 确认框
Confirm弹出框,主要是让用户确认是否要进行某个操作。
Confirm弹出框有两个选择供用户选择,分别是OK和Cancel,分别代表确定和取消操作。
那么,自动化的时候,代码怎么模拟用户点击OK或者Cancel按钮呢?
selenium提供如下方法进行操作
如果我们想点击OK按钮,还是用刚才的accept方法,如下
# alert.text 获取弹框文字
print(driver.switch_to.alert.text)
# 点击 "确定"
driver.switch_to.alert.accept()
# 点击 "取消"
driver.switch_to.alert.dismiss()
3. Prompt 输入框
出现Prompt弹出框是需要用户输入一些信息,提交上去。
获取弹出框调用 send_keys()
调用如下方法:
driver.switch_to.alert.send_keys("xxx")
4. 文件上传
# 获取文件上传的元素
upload = driver.find_elements(By.ID,'file')
# 把需要上传的文件的相对路径copy过来
upload.send_keys(r"/xx/xxx/xx...")
# 获取文件提价的元素
driver.find_element(By.ID,'button').click()
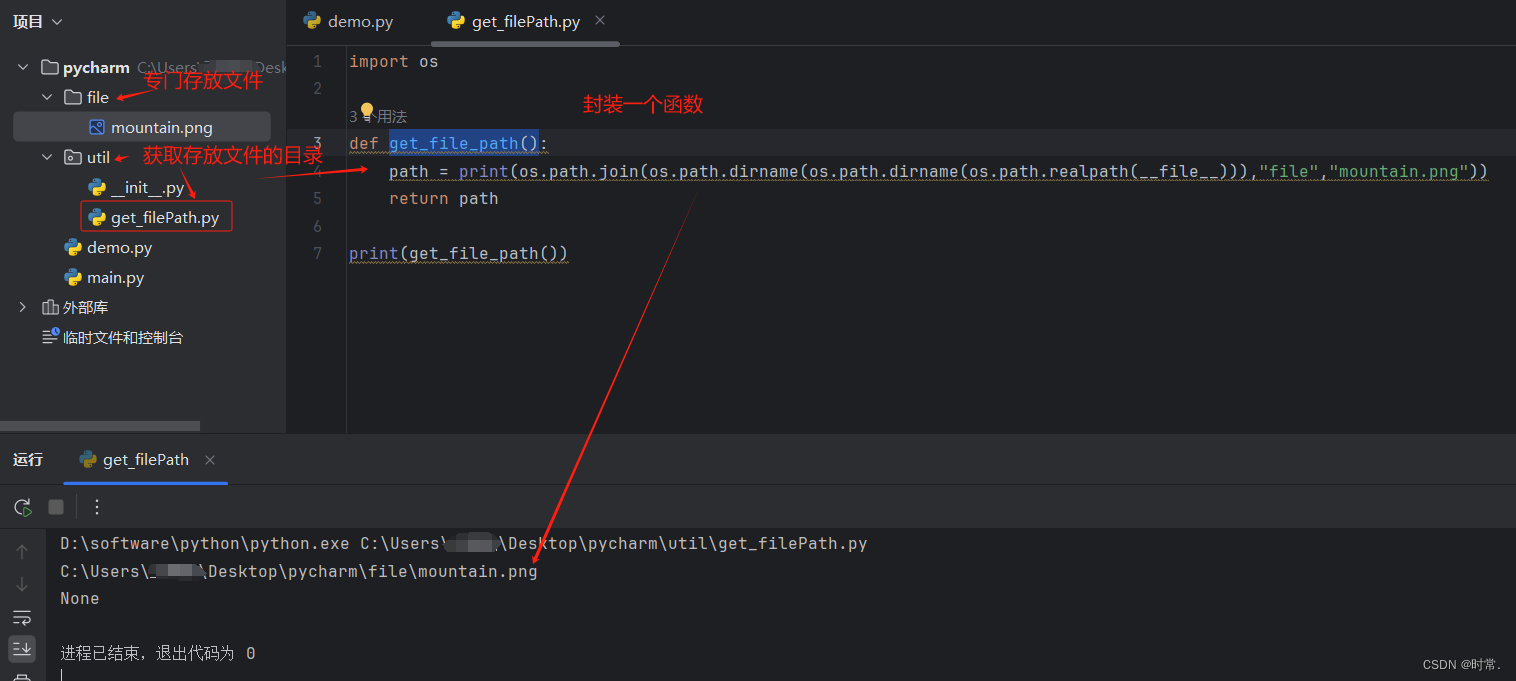
封装相对路径
import os
def get_file_path():
path = print(os.path.join(os.path.dirname(os.path.dirname(os.path.realpath(__file__))),"file","mountain.png"))
return path
print(get_file_path())
使用:
# 获取path路径
from util.get_filePath import get_file_path
path = get_file_path()
# 获取文件上传的元素
upload = driver.find_elements(By.ID,'file')
# 把需要上传的文件绝对路径copy进来
upload.send_keys(r"{}".format(path))
# 获取文件提价的元素
driver.find_element(By.ID,'button').click()
三、选择器
1. Css选择器
- 基本class选择器
el = driver.find_element(By.CSS_SELECTOR,'.animal') # class
el = driver.find_element(By.CSS_SELECTOR,'div') # tag_name
el = driver.find_element(By.CSS_SELECTOR,'#div') # id
- 多层次嵌套选择器
el = driver.find_element(By.CSS_SELECTOR,'.container > .item') # 选择直接子元素
el = driver.find_element(By.CSS_SELECTOR,'ul li') # 选择ul 后面所有的li元素
- 根据属性选择
注意:引用时外单内双、外双内单
el = driver.find_element(By.CSS_SELECTOR,'[href="xxx"]')
el = driver.find_element(By.CSS_SELECTOR,'.animal[name="dog"]')
- 选择限定 指定元素
el = driver.find_element(By.CSS_SELECTOR,'ul:nth-child(2)') # 选择第二个元素
el = driver.find_element(By.CSS_SELECTOR,'ul:nth-child(2n)') # 选择2倍的元素
el = driver.find_element(By.CSS_SELECTOR,'ul:nth-last-child(2)') # 倒数第二个元素
限制类型:nth-of-type()
el = driver.find_element(By.CSS_SELECTOR,'ul span:nth-of-type(2)') # 选择ul下第2个span元素
el = driver.find_element(By.CSS_SELECTOR,'ul span:nth-last-of-type(2)') # 倒数第二个span元素
- 兄弟节点选择
el = driver.find_element(By.CSS_SELECTOR,'ul + div') # 选择ul相邻的兄弟div元素
el = driver.find_element(By.CSS_SELECTOR,'ul ~ div') # 选择ul所有的兄弟div元素
2. Xpath选择器
xpath是什么? XPath 是一门在XML文档中查找信息的语言
xml是什么? XML (可扩展标记语言),主要用于传输数据。
为什么可以使用xpath定位html?
XPath (XML 路径语言)是一种用于在XML文档中定位元素的语言,它可以用于定位HTML 文档中的元素。
既然已经有了CSS,为什么还要学习Xpath呢?
因为有些场景用css选择web元素很麻烦,而xpath却比较方便。,另外Xpath还有其他领域会使用到,比如爬虫框架Scrapy,手机App框架Appium。
1.绝对路径选择
一般不用绝对路径定位。
xpath语法中,整个HTML文档根节点用/表示,如果我们想选择的是根节点下面的html节点,就是某元素的绝对路径,则可以在搜索框输入
/html
如果输入下面的表达式
/html/body/div
这个表达式表示选择html下面的body下面的div元素。( 等价于css表达式 html>body>div)
自动化程序要使用Xpath来选择web元素,应该调用WebDriver对象的方法
driver.find_elements(By.XPATH,'/html/body/div')
2.相对路径选择
有的时候,我们需要选择网页中某个元素,不管它在什么位置
比如,选择页面的所有标签名为div的元素,如果使用css表达式,直接写一个div就行了。
那xpath怎么实现同样的功能呢? xpath需要前面加 //,表示从当前节点往下寻找所有的后代元素,不管它在什么位置。
所以xpath表达式,应该这样写: //div/p
自动化程序要使用Xpath来选择web元素,应该调用WebDriver对象的方法
driver.find_elements(By.XPATH,'//div//p')
1.通配符
如果要选择所有div节点的所有直接子节点,可以使用表达式 //div/*
*是一个通配符,对应任意节点名的元素(等价于CSS选择器 div > *)
el = driver.find_elements(By.XPATH,'//div//p')
for item in el:
print(item.get_attribute('outerHTML'))
2.根据属性选择
根据属性来选择元素是通过这种格式来的[@属性名='属性值']
注意:
●属性名注意前面有个@
●属性值一定要用引号,可以是单引号,也可以是双引号
- 根据id属性选择
选择id为west的元素,可以这样//*[@id='west' ] - 根据class属性选择
选择所有div元素中class为plant的元素,可以样//div[@class='plant']
如果一个元素class 有多个,比如
<p id='xx' class='box demo'>xxx</p>
如果要选它,对应的xpath就应该是 //p[@class="box demo"]
注意:不能只写一个属性,像这样//p[@class="box"]则不行 !
- 根据其他属性
同样的道理,我们也可以利用其它的属性选择
比如选择具有multiple属性的所有页面元素,可以这样//* [@multiple] - 属性值包含字符串
要选择style属性值包含color 字符串的页面元素,可以这样//*[contains(@style,'color')]
要选择style属性值以color字符串开头的页面元素,可以这样//*[starts-with(@style, 'color)]
要选择style属性值以某个字符串结尾的页面元素,//*[ends-with(@style,'color')],但是,很遗憾,这是xpath 2.0的语法,目前浏览器都不支持。
3. 按次序选择
xpath也可以根据次序选择元素。语法比css更简洁, 直接在方括号中使用数字表示次序
比如
- 某类型第几个子元素
要选择p类型第2个的子元素,就是://p[2]
注意,选择的是 p类型第2个的子元素,不是第2个子元素,并且是p类型,注意体会区别。
再比如,要选取父元素为div中的p类型第2个元素://div/p[2] - 第几个子元素
也可以选择第2个子元素,不管是什么类型,采用通配符
比如选择父元素为di的第2个子元素,不管是什么类型://div/*[2] - 某类型倒数第几个子元素
当然也可以选取倒数第几个子元素
●选取p类型倒数第1个子元素://p[last()]
●选取p类型倒数第2个子元素://p[last()-1]
●选择父元素为div中p类型倒数第二个子元素://div/p[last()-2]
4. 范围选择
xpath还可以选择子元素的次序范围。
●选取option类型第1到2个子元素://option[position()<=2]或者//option[position()<3]
●选择class属性为choice的前3个子元素://*[@class='choice']/*[position()<=3]
●选择class属性为 choice的后3个子元素: //*[@class='choice']/*[position()>=last()-2]
为什么不是
last()-3呢?因为
last(本身代表最后一个元素
last()-1本身代表倒数第2个元素
last()-2本身代表倒数第3个元索
5.多组节点选择
组选择,可以同时使用多个表达式,多个表达式选择的结果都是要选择的元素:
css组选择,表达式之间用逗号隔开
xpath也有组选择,用竖线隔开多个表达式
比如,要选所有的option元素和所有的h4元素,可以使用 //option | h4 (等同于CSS选择器option,h4)
//*[@class='a'] | //*[@class='c'](等同于CSS选择器.a,.c)
# 多个属性标签精准选择
driver.find_element(By.CSS_SELECTOR,"//div[@class='s_ipt' and @name='wd']")
# 多组数据使用下标定位
driver.find_element(By.CSS_SELECTOR,"//ul[@id='demo']/a[4]")
6. 选择父节点
xpath可以选择父节点,这是css做不到的。
某个元索的父节点用/..表示
要选择id为china的节点的父节点,可以这样写//*[@id=' china']/..
当某个元素没有特征可以直接选择,但是它有子节点有特征,就可以采用这种方法,先选择子节点,再指向它的父节点。
还可以继续找上层父节点,比如://*[@id='china]/../../..
7. 兄弟节点选择
xpath也可以选择后续兄弟节点,用这样的语法 following-sibling::
要选择class为 choice 的元素的所有后续兄弟节点 //*[@class='choice']/following-sibling::*
如果,要选择后续节点中的div节点,就应该这样写 //*[@class='choice ]/following-sibling::div
xpath还可以选择前面的兄弟节点,用这样的语法preceding-sibling::
要选择class为choice 的元素的所有后续兄弟节点 //*[@class='choice']/preceding-sibling::*
(而CSS选择器目前还没有方法选择前面的兄弟节点)
xpath 小坑
我们的代码:
●先选择示例网页中,id是china的元素
●然后通过这个元素的WebElement对象,使用find_elements, 选择里面的p元素
# 先寻找id是china的元素
china = driver.find_element(By.ID,'china')
# 再选择该元素内部的p元素(一定要在前面加 .定位到china中查找)
els = china.find_elements(By.XPATH,'.//p')
# 打印结果
for item in els:
print(item.get_attribute('outerHTML'))
els = china.find_elements(By.XPATH,'//p')运行发现,打印的不仅仅是china内部的p元素,而是所有的p元素。
这个坑只有xpath中有,css没有此坑。
selenium的案例练习
网址:http://sellshop.5istudy.online/sell/user/login_page
增加商品练习:
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
driver = webdriver.Edge()
driver.get("http://sellshop.5istudy.online/sell/user/login_page")
# 输入账号
driver.find_element(By.ID,'username').send_keys('test13')
# 输入密码
driver.find_element(By.ID,'password').send_keys('123456')
# 点击 "登录"
driver.find_element(By.XPATH,'//*[@id="login"]/form/p[3]/input').click()
# 点击 "新增"
driver.find_element(By.CSS_SELECTOR,'a[href="/sell/seller/product/index"]').click()
# 输入名称
driver.find_element(By.NAME,'productName').send_keys('霸王茶姬')
# 输入价格
driver.find_element(By.NAME,'productPrice').send_keys('19.9')
# 输入库存
driver.find_element(By.NAME,'productStock').send_keys('2500')
# 输入描述
driver.find_element(By.NAME,'productDescription').send_keys('茶香回味浓郁')
# 输入图片地址
driver.find_element(By.NAME,'productIcon').send_keys("https://pic1.zhimg.com/v2-588bb7f75c0997f243982ffa407e047c_r.jpg")
# 选择 类目
select = Select(driver.find_element(By.NAME,'categoryType'))
select.select_by_value('33')
# 点击 "提交"
driver.find_element(By.XPATH,'//button[@type="submit"]').click()
sleep(3)
driver.quit()
四、YAML文件 - - 实现接口自动化
1.用于全局的配置文件ini、yaml
2.用于写测试用例(接口测试用例)
yam|简介:
yaml是一种数据格式,支持注释,换行,多行字符串,裸字符串(整形,字符串)。
语法规则:
1.区分大小写
2.使用缩进表示层级,不能使用tab键缩进,只能用空格(和python一样)
3.缩进没有数量的,只要前面是对齐的就行。
4.注释是 #
检查yaml语法格式:https://www.bejson.com/validators/yaml_editor/
1.数据组成
1.Map对象,键值对
键:(空格)值
# 多行写法
mario:
name:mario
age:20
# 一行写法
mario:{name:mario,age:20}
2.数组(list)
用一组横线开头
# 多行写法
-
mario:
- name:mario
- age:20
-
anna:
- name:anna
- age:22
# 一行写法
mario:[{name:mario},{age:20}]
2. 使用yaml
安装:pip install PyYAML
test_api.yaml
-
mario:
- name:mario
- age:20
-
anna:
- name:anna
- age:22
yaml_util.py
import yaml
class YamlUtil:
def __init__(self,yaml_file):
# 通过init方法把yaml文件传入到这个类中
self.yaml_file = yaml_file
# 读取yaml文件
def read_yaml(self):
with open(self.yaml_file,encoding='utf-8') as f:
# 读取yaml对yaml反序列化,就是把我们的yaml格式转换成dict格式。
value = yaml.load(f,Loader=yaml.FullLoader)
print(value)
if __name__ == '__main__':
YamlUtil('test_api.yaml').read_yaml()
[{'mario': ['name:mario', 'age:20']}, {'anna': ['name:anna', 'age:22']}]